







1. 使用背景
在我们的项目里面,模拟面试功能使用到了用户上传的简历,我们需要提取出用户的项目经历,个人经历等信息。
很多时候,简历都是PDF格式的,并且有一些PDF是不能复制文字的,这时候就需要用到OCR技术,提取出PDF中的文字,找到我们需要的信息。
2. OCR概念
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提升识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也随之产生。
3. 理论知识
典型的OCR技术路线如下图所示:

其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。
3. 传统方法
1、水平投影垂直投影
2、模板匹配
3、查找轮廓findcontours
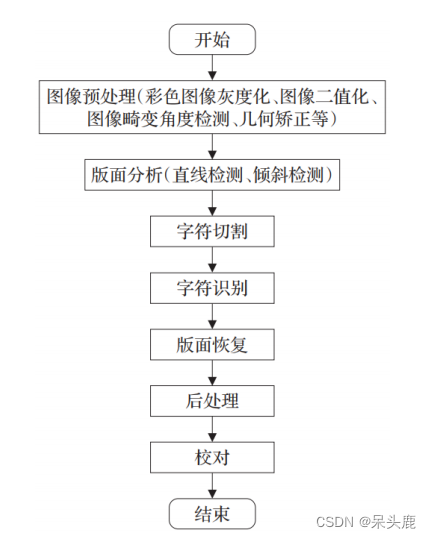
传统的光学字符识别过程为:图像预处理(彩色图像灰度化、二值化处理、图像变化角度检测、矫正处理等)、版面划分(直线检测、倾斜检测)、字符定位切分、字符识别、版面恢复、后处理、校对等。
4. 深度学习
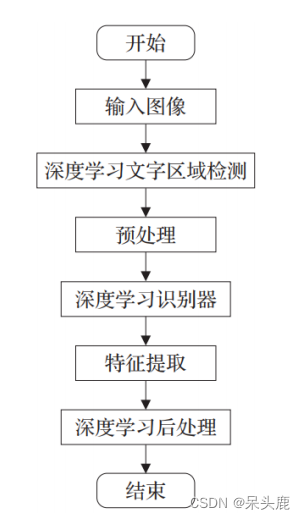
深度学习图像文字识别流程包括:输入图像、深度学习文字区域检测、预处理、特征提取、深度学习识别器、深度学习后处理等。
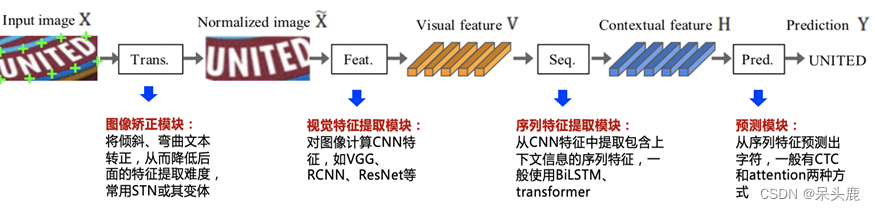
现有多数深度学习识别算法具体流程包括图像校正、特征提取、序列预测等模块,流程如图所示:
5. 常用框架
1. Tesseract OCR
- 由 Google 开发的开源 OCR 引擎,是目前应用最广泛的 OCR 框架之一。
- 支持多种语言,包括中文、日文、韩文等。
- 可以集成到各种编程语言中,如 Python、C++、Java 等。
2. PyTesseract
- 是 Tesseract OCR 引擎的 Python 接口,方便在 Python 中使用 Tesseract。
- 与 Tesseract 相比,PyTesseract 提供了更简单的 API,使用更加方便。
3. Easyocr
- 由 Chinese University of Hong Kong 开发的开源 OCR 库,支持多种语言,包括中文、日文、韩文等。
- 基于深度学习技术,识别准确率较高,并且支持实时识别。
- 提供简单易用的 Python API。
4. Paddle OCR
- 由百度研发的开源 OCR 框架,基于 PaddlePaddle 深度学习框架。
- 支持多种场景的文字识别,如场景文字、表格文字、handwritten 等。
- 可以部署到 Web、移动端、服务器等多种环境中。
5. Microsoft Computer Vision API
- 微软提供的商业 OCR 服务,可以通过 REST API 使用。
- 支持多种语言,包括中文、英文等,并且可以识别手写文字。
- 提供图像分析、对象检测等功能。
参考文章















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









