







 本文介绍了Java中的ForkJoinPool线程池如何实现任务分而治之,包括其工作原理、RecursiveTask和RecursiveAction的区别,以及Future和CompletableFuture在异步计算中的应用。
本文介绍了Java中的ForkJoinPool线程池如何实现任务分而治之,包括其工作原理、RecursiveTask和RecursiveAction的区别,以及Future和CompletableFuture在异步计算中的应用。
ForkJoinPool
ForkJoinPool可以给我们提供
分⽽治之
的功能,当我们有⼤量任务需要处理的时候,我们可以将其分为N个批次,然后每个批次开启⼦线程去并发执⾏,当⼦线程都执⾏完毕后,再对结果进⾏汇总计算。这种思想就类似于Hadoop的MapReduce⽅式。其中,fork表示开启⼀个执⾏分⽀,即:
创建⼦线程去执⾏某些任务。⽽join我们在前⾯也介绍过,它具有等待的含义,也就是使⽤fork()后系统多了⼀个执⾏分⽀或执⾏线程,所以需要等待这个分⽀执⾏完毕,才能进⾏最后结果汇总的计算。如下图所示:
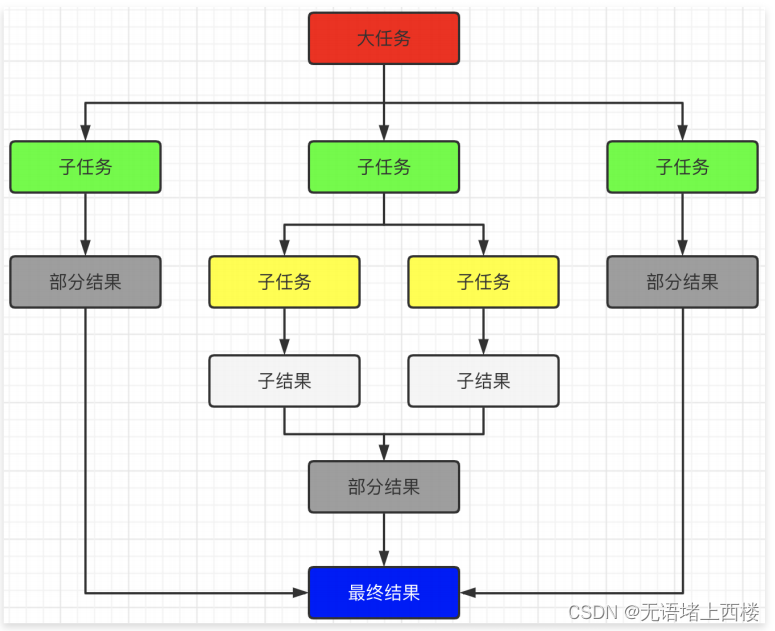
如果我们随意的去fork线程,那么就会导致系统开启了很多⼦线程⽽造成系统开销过⼤,从⽽影响系统的性能。所以,JDK为我们提供了ForkJoinPool线程池⽤来解决这个问题。它采⽤对于fork()⽅法并不着急开启线程,⽽是提交给ForkJoinPool线程池去进⾏处理,从⽽节省系统开⽀。由于线程池的优化,提交的任务和线程数量并不是⼀对⼀的关系。在绝⼤多数情况下,⼀个物理线程实际上是需要处理多个逻辑任务的。因此,每个线程必然需要拥有⼀个任务队列。 因此,在实际执⾏过程中,可能過到这么⼀种情况:线程A已经把⾃⼰的任务都执⾏完成了, ⽽线程B还有⼀堆任务等着处理,此时,线程A就会“帮助”线程 B,从线程B的任务队列中拿⼀个任务过来处理,尽可能地达到平街。从⽽显示了这种互相帮助的精神。但是,其中⼀个值得注意的地⽅是,当线程试图帮助别⼈时,总是从任务队列的
底部
开始拿数据,⽽线程试因执⾏⾃⼰的任务时,则是从相反的
顶部
开始拿。因此这种⾏为也⼗分有利于避免数据竞争。如下图所示:

RecursiveTask
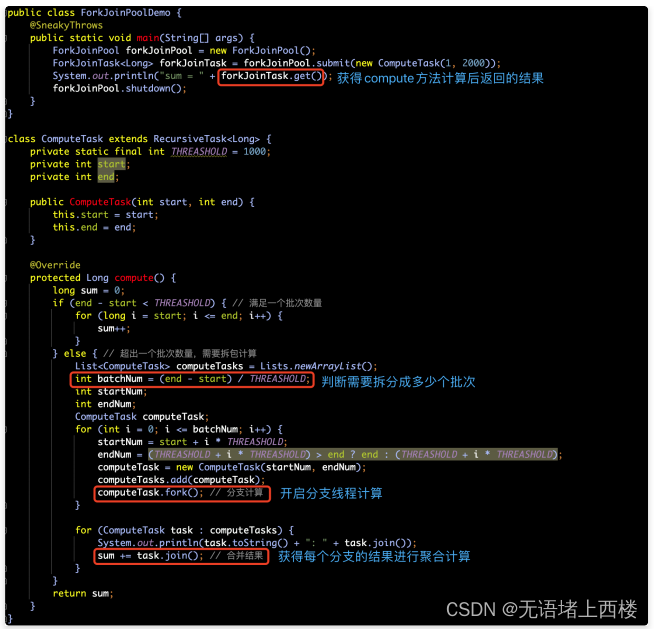
RecursiveTask执⾏有返回值任务,通过
RecursiveTask
的⼦类,实现带返回值的计算

RecursiveAction
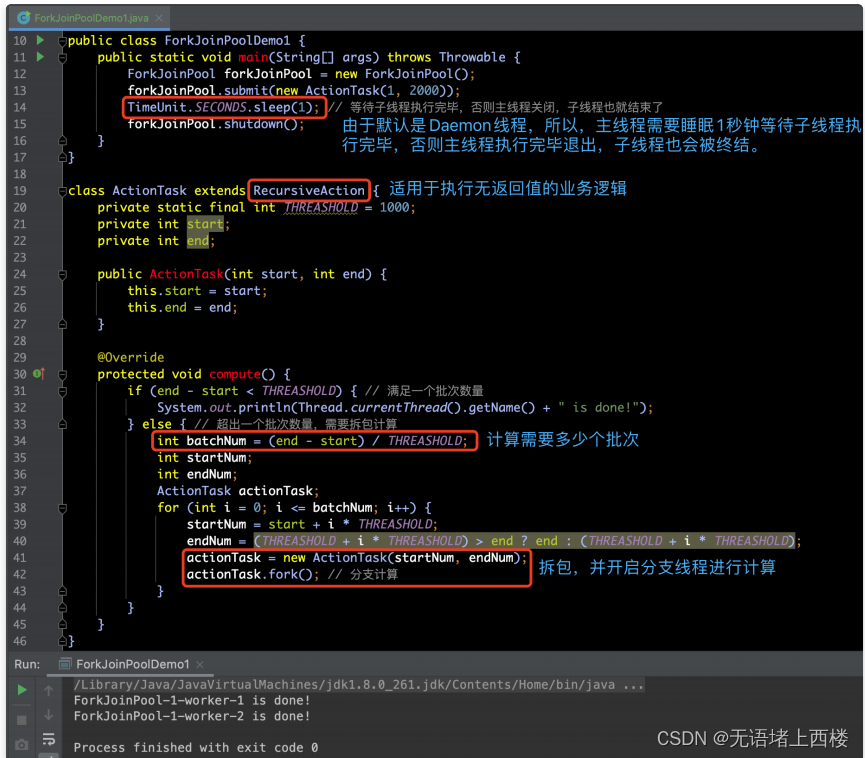
RecursiveAction执⾏⽆返回值任务 ,通过RecursiveAction的⼦类,实现不带返回值的计算
Future
JDK内置的Future模式
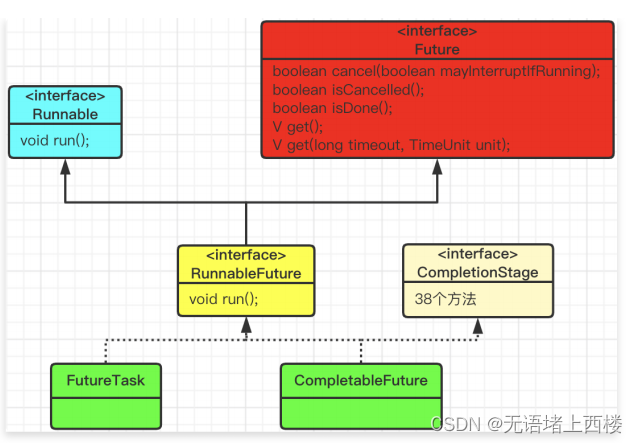
可以通过调⽤线程池的submit⽅法,返回Future,然后调⽤get⽅法来获得⼦线程计算的结果值,如下所示:
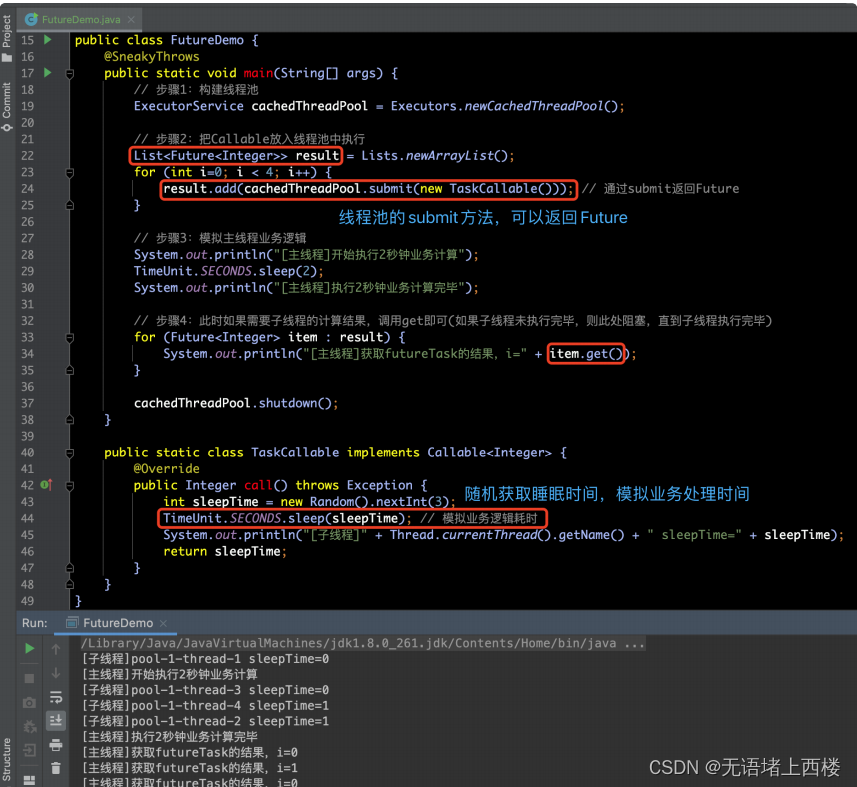
FutureTask
- FutureTask是RunnableFuture的⼀个具体实现,它内部有⼀个内部类Sync,它赋值内部逻辑的实现。⽽Sync会最终调⽤Callable接⼝,完成实际数据的组装⼯作。
- Callable接⼝有⼀个call()⽅法,通过⽅法内部的计算,可以将结果返回出来。这个Callable接⼝也是这个Future框架和应⽤程序直接的重要桥梁。我们可以将需要实现的逻辑在call()⽅法中实现。通常,我们会使⽤Callable实例构造⼀个FutureTask实例,并将它提交给线程池。
- 下⾯是具体实现的例⼦:
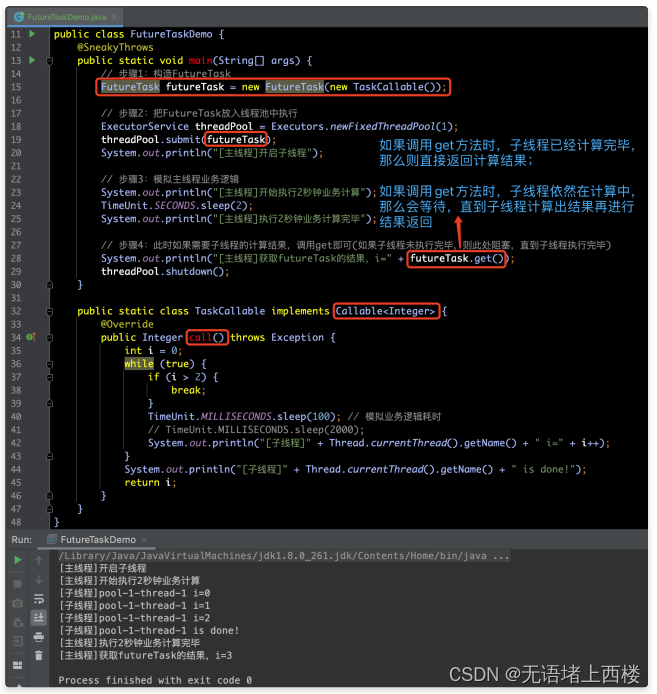
- 我们把需要实现的逻辑在Callable接⼝的call⽅法中实现。
- 当构造FutureTask时,将Callable实例传给它,告诉FutureTask去做什么事情可以有返回值。
- 然后,我们将FutureTask提交(submit)给线程池。显然,作为⼀个简单的任务提交,这⾥必然是⽴即返回的,因此程序不会阻塞。
- 接下来,我们不⽤关系数据是如何计算和产⽣的,我们放⼿去做其他事情(例如:上⾯例⼦中Sleep了2秒钟),然后,当我们需要计算的结果时,调⽤FutureTask的get()⽅法获得计算结果。
CompletableFuture
在Java
8
中,新增了CompletableFuture类作为Future的增强类。它实现了CompletionStage接⼝,该接⼝有38
个⽅法,是为了函数式编程中的流式调⽤准备的。
执⾏通知
如果需要向CompletableFuture请求⼀个数据,但是需要数据准备好才能发起这个请求,那么此时,我们就可以利⽤⼿动设置CompletableFuture的完成状态。下⾯例⼦中,我们获取并打印被通知的值:
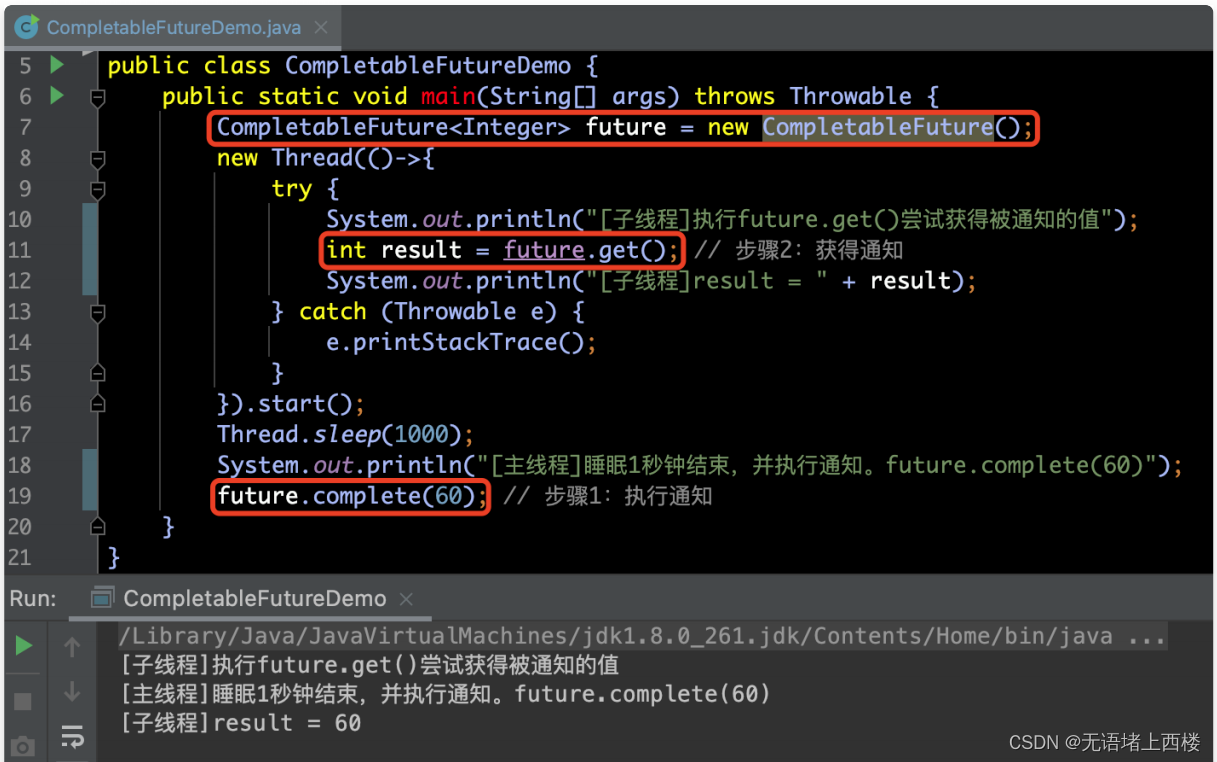
执⾏异步任务
可以通过supplyAsync和runAsync来执⾏异步任务,具体⽅法如下所示:


- supplyAsync()⽅法⽤于那些需要有返回值的场景;
- runAsync()⽅法⽤于没有返回值的场景;
- 在这两个⽅法中,都分别有⼀个⽅法可以接收⼀个Executor参数。这就使我们可以让
- Supplier<U>或者Runnable在指定的线程池中⼯作。如果不确定,则在默认的系统公共的ForkJoinPool.common线程池中执⾏。
- 在Java 8中,新增了ForkJoinPool.commonPool()⽅法。它可以获得⼀个公共的ForkJoin线程池。这个公共线程池中的所有线程都是Daemon线程。这意味着如果主线程退出,这些线程⽆论是否执⾏完毕,都会退出系统。
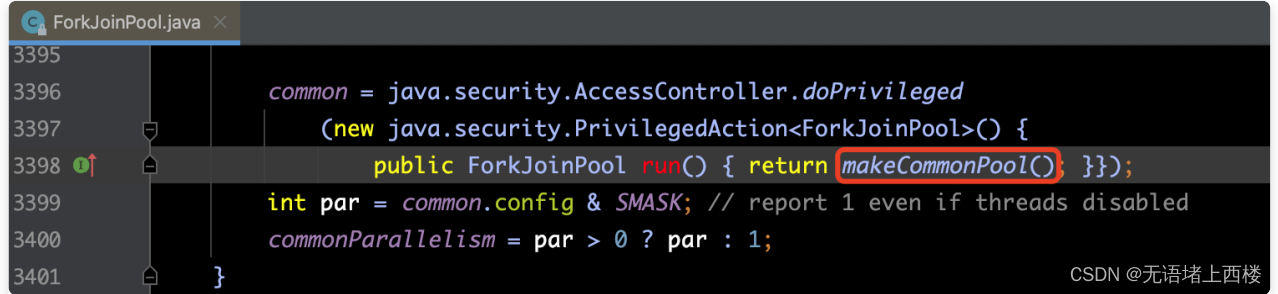
 下⾯是异步任务的例⼦:
下⾯是异步任务的例⼦:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









