




 本文详细介绍了X-AnyLabeling的安装过程,包括从GitHub克隆源码、设置环境依赖,以及如何通过命令行和exe文件启动。教程还涵盖了更换语言、选择模型(如YOLO和SAM-HQ)以及进行点标注的步骤,以及自动标注功能的使用方法。
本文详细介绍了X-AnyLabeling的安装过程,包括从GitHub克隆源码、设置环境依赖,以及如何通过命令行和exe文件启动。教程还涵盖了更换语言、选择模型(如YOLO和SAM-HQ)以及进行点标注的步骤,以及自动标注功能的使用方法。
目录
软件安装教程——X-AnyLabeling 安装与自动标注
- 【GitHub 源码地址】:GitHub - CVHub520/X-AnyLabeling
安装
clone 源码
- 链接:https://pan.baidu.com/s/1RCpE81VCyKgtj8lwFjB55Q?pwd=54ji
提取码:54ji
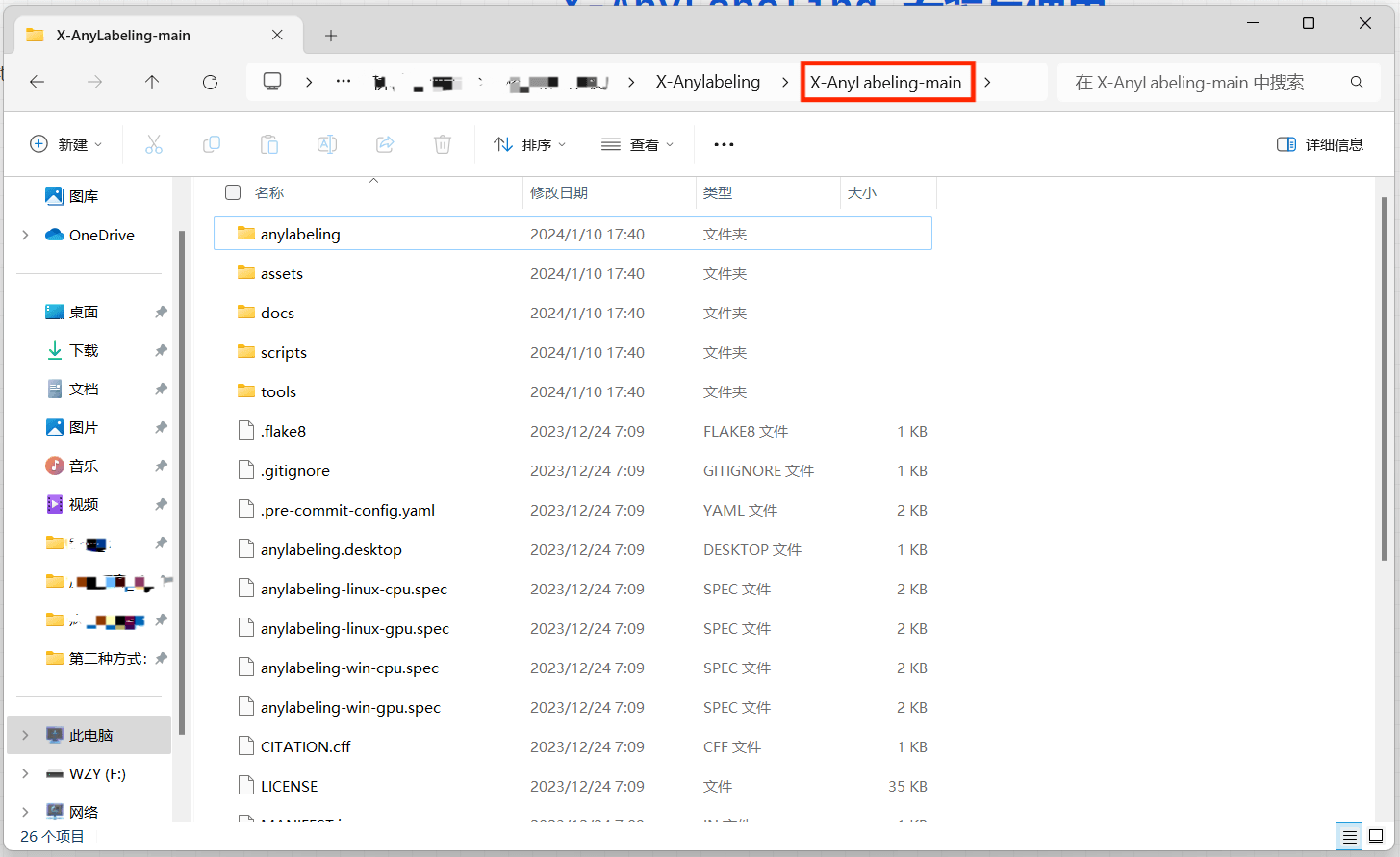
安装所需的环境依赖
- cmd 打开 虚拟环境 并进入 源码所在文件夹 后,输入以下命令安装所需的环境依赖:
pip install -r requirements.txt
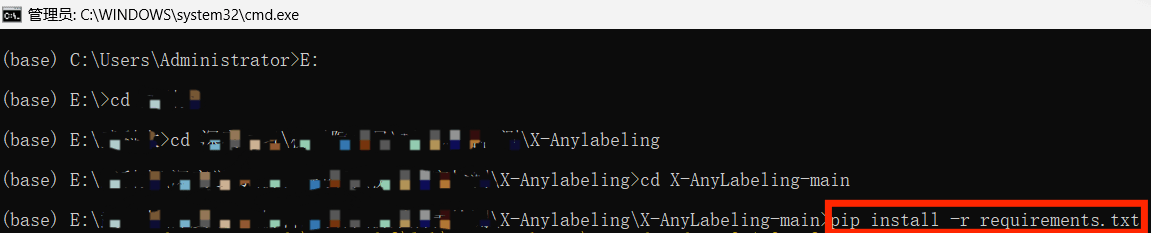
- 安装过程中可能会碰到以下错误:
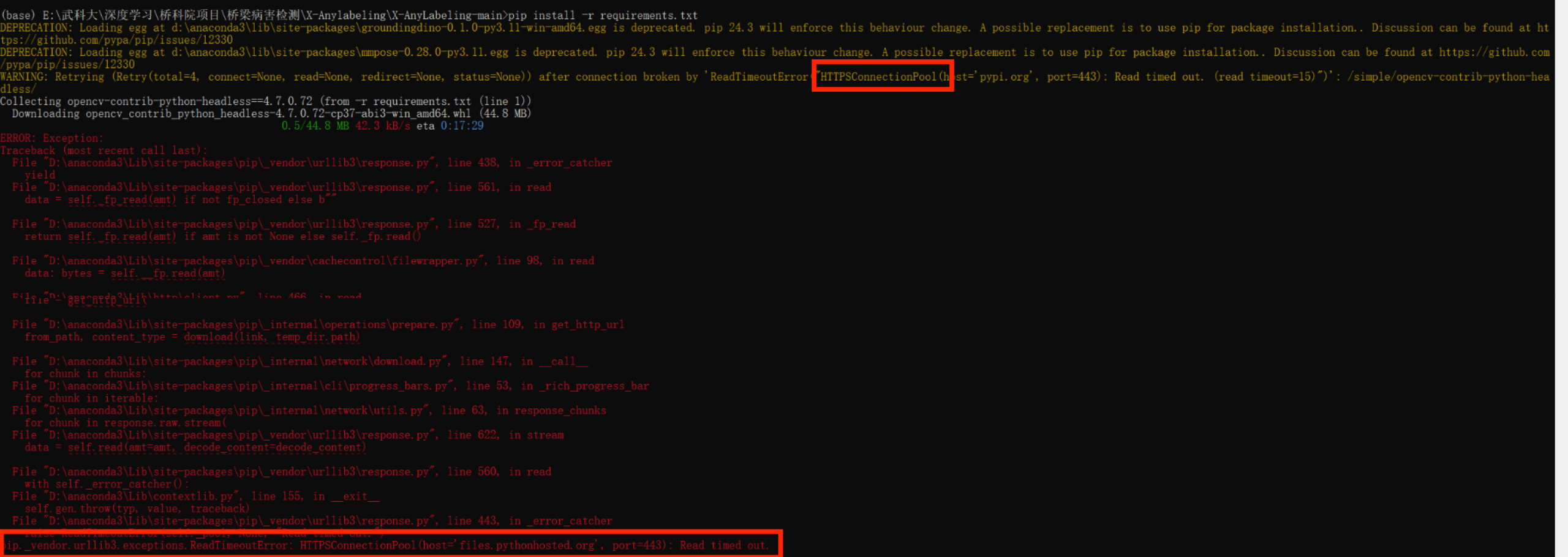
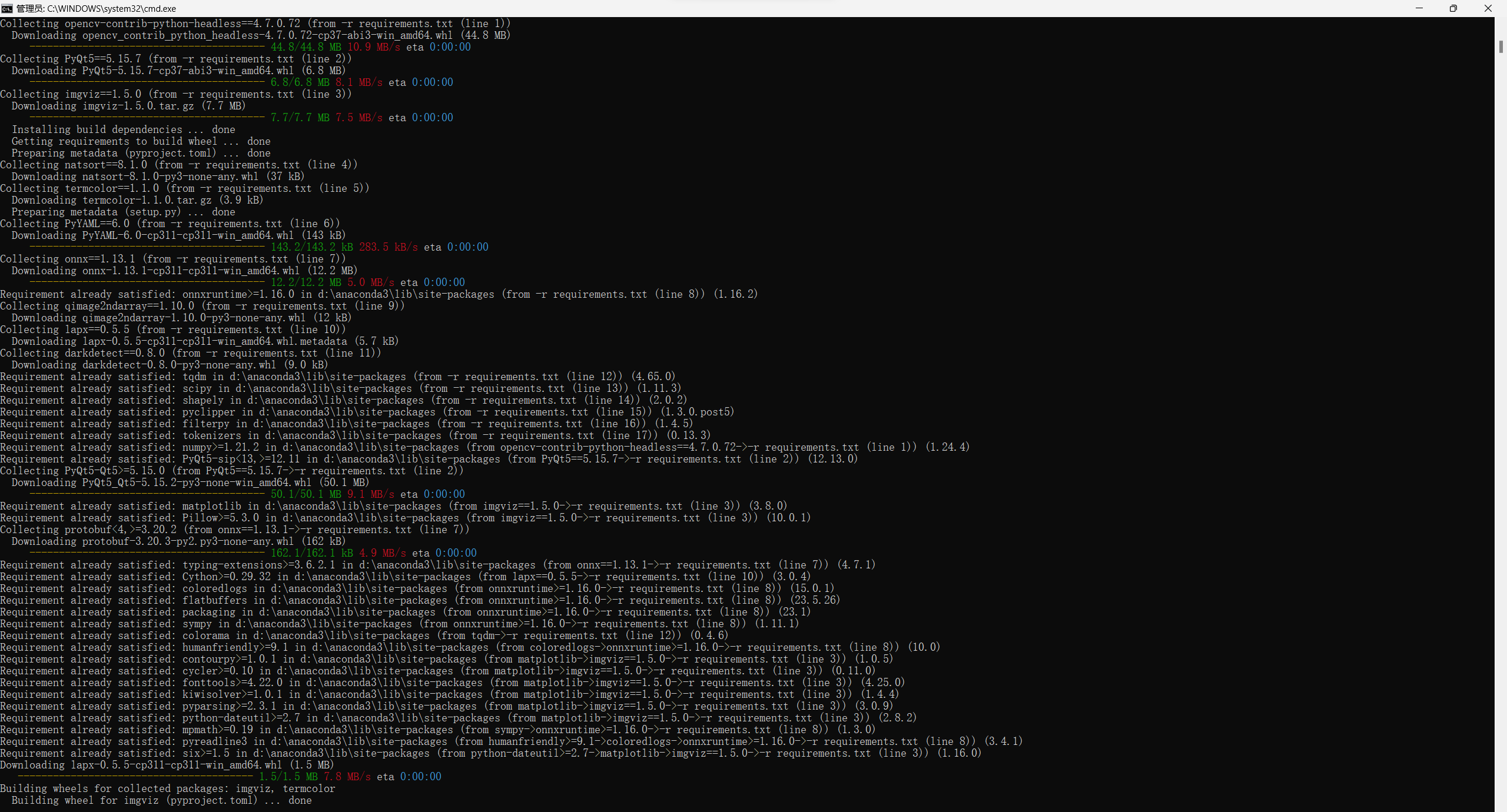
- 科学上网即可解决:
启动
命令行启动
- 继续输入命令:
python anylabeling/app.py

- 会直接自动打开 X-AnyLabeling:
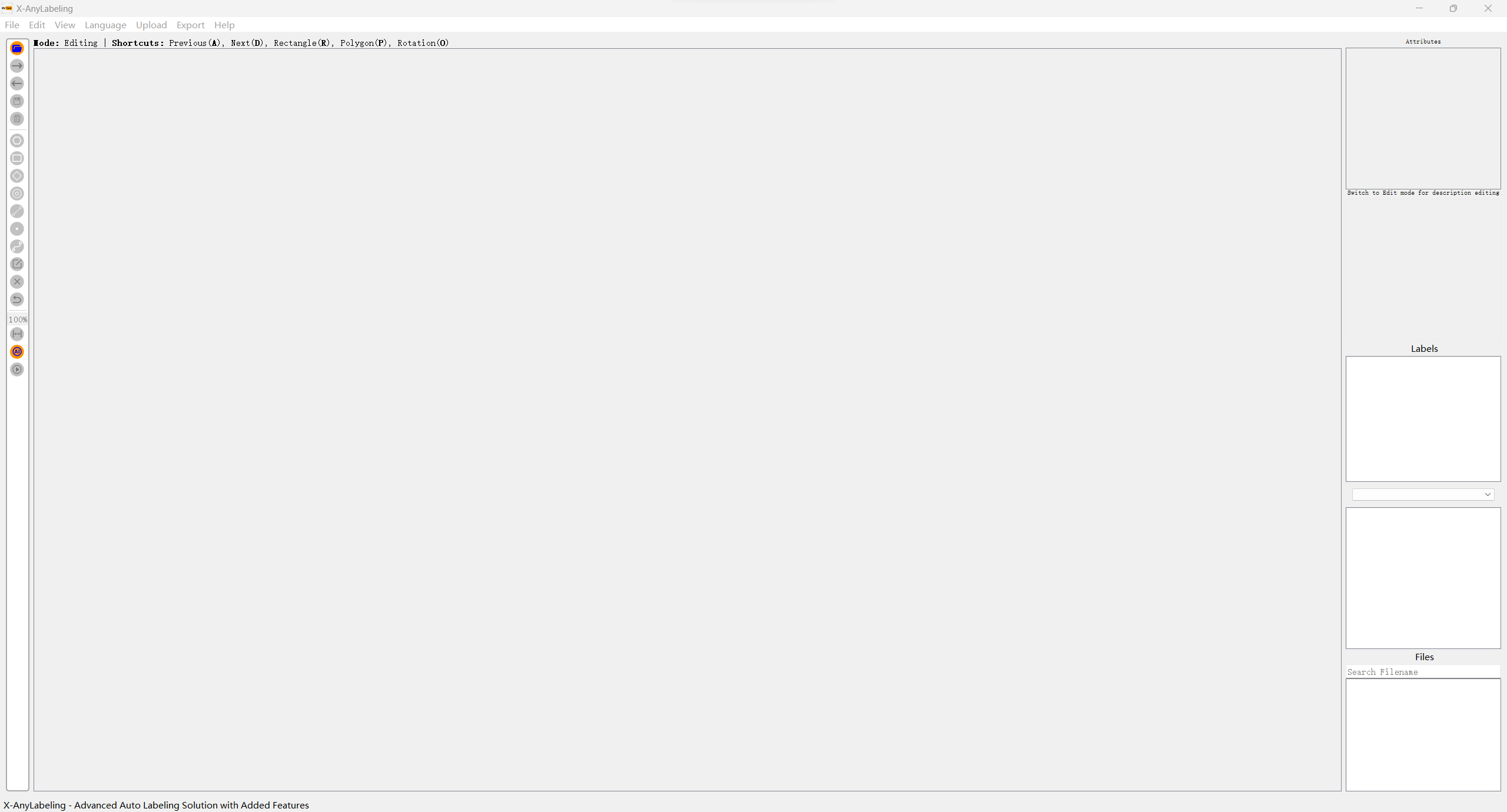
exe 文件启动
注:每次需要通过命令行启动些许麻烦,命令行启动一次之后,后续可以通过下载的 exe 文件双击直接启动.
-
这里作者提供【X-AnyLabeling-CPU.exe】:
-
链接:https://pan.baidu.com/s/1P5Z3eOrTYQxZ_8M18xiXOw?pwd=tgix
提取码:tgix
使用
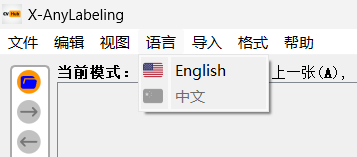
更换语言
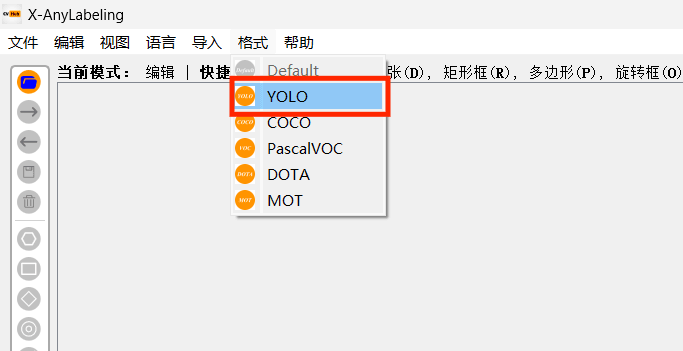
选择格式
- 这里以 YOLO 为例:
- 需要classes.txt文件:
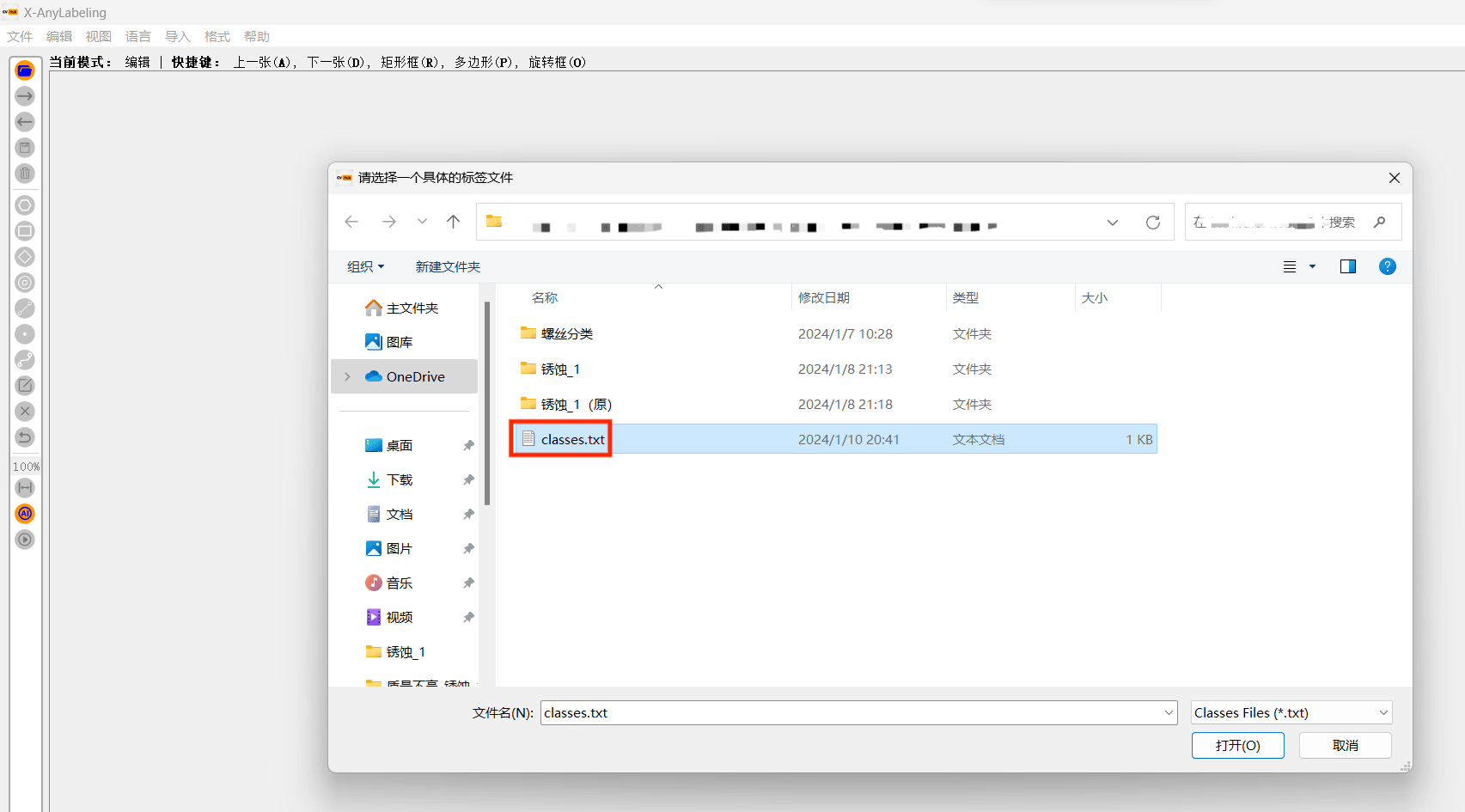
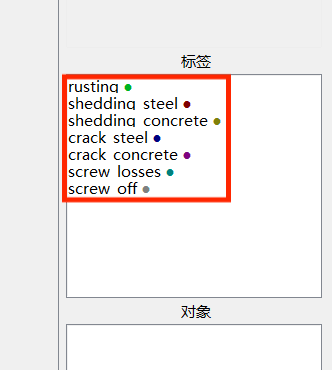
- 选择之后,右边中间 会显示类别:
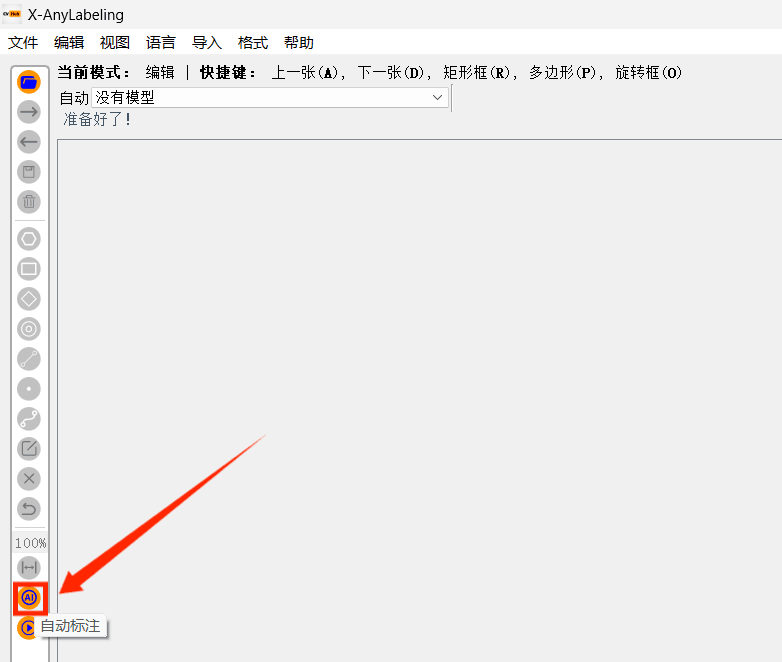
自动标注
- 开启 【自动标注模式】:
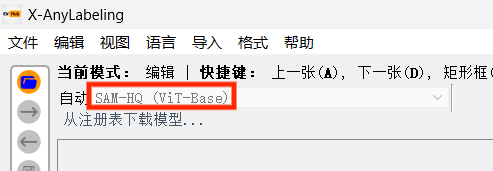
- 【选择模型】,以 SAM-HQ(Vit-Base)为例(需要 科学上网):
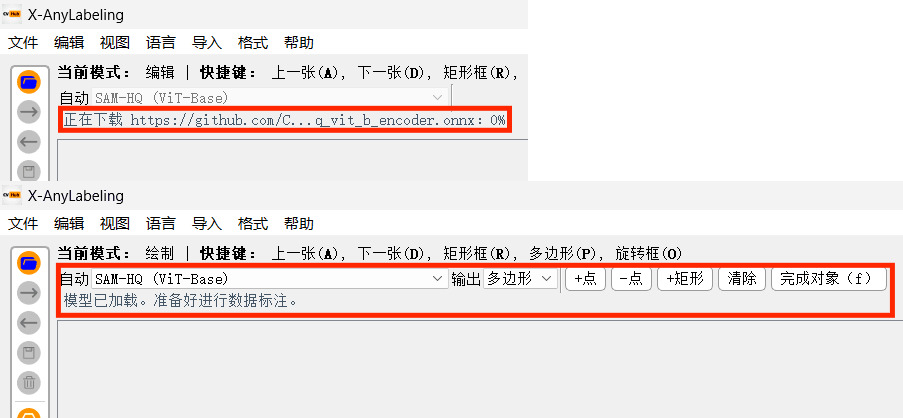
- 【自动下载的模型路径】:C:\Users\用户名\anylabeling_data\models
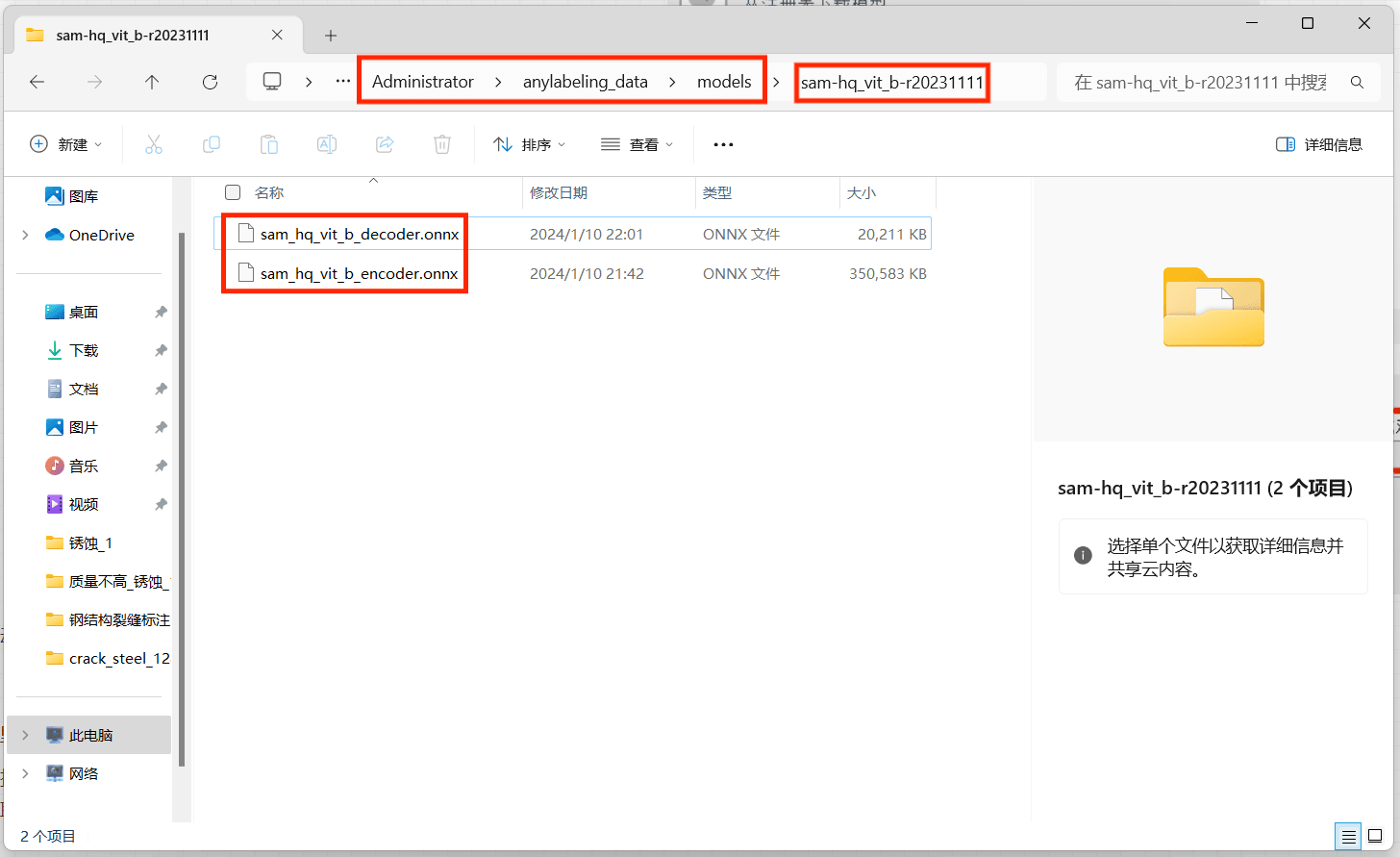
-
这里作者提供【 SAM-HQ(ViT-Base) 模型】:
-
链接:https://pan.baidu.com/s/1YClr_qqcV4ekzh4igKFMvg?pwd=fec7
提取码:fec7
标注
- 以 点标注 为例:
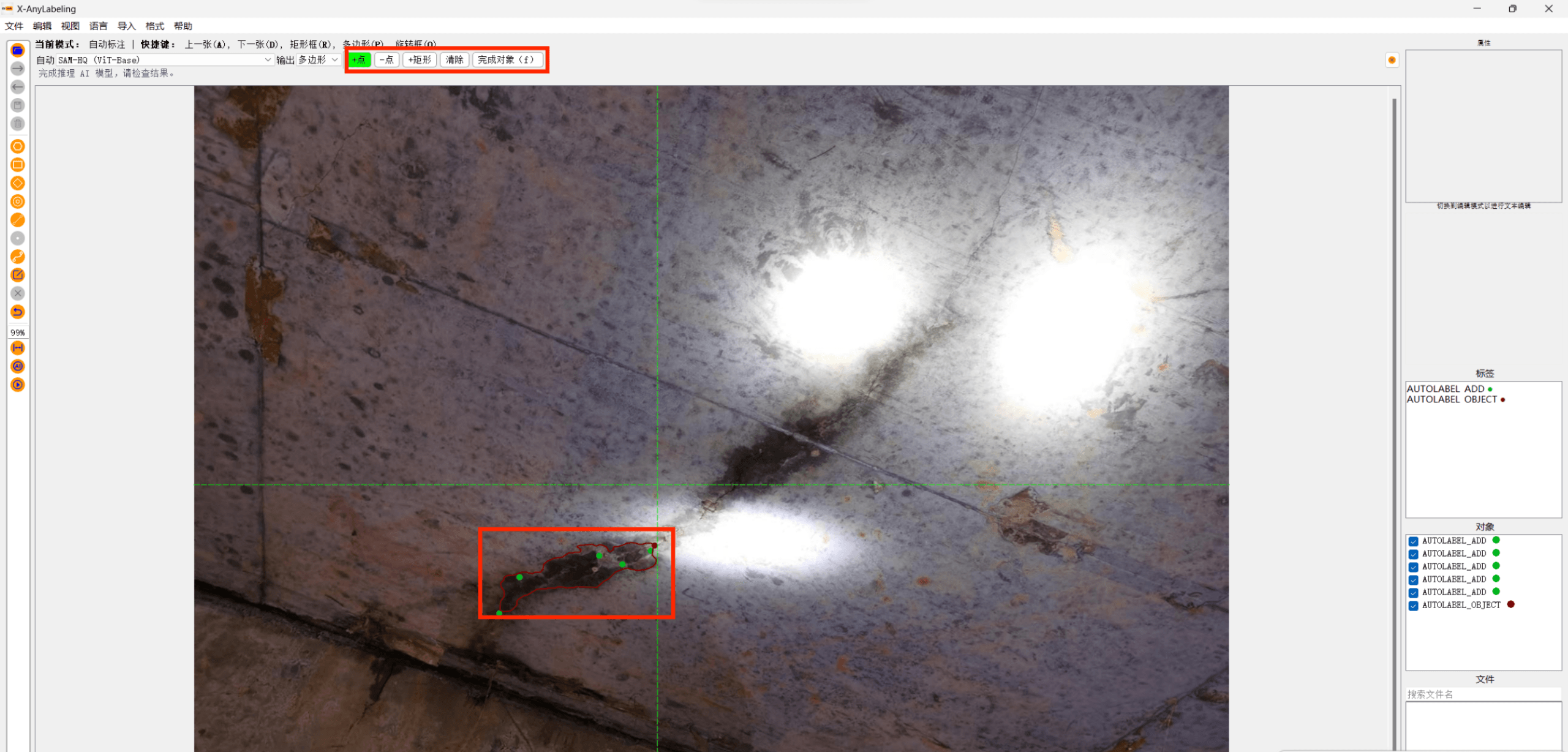
- 标注完会自动生成labels 文件夹和图片同名的json 文件:
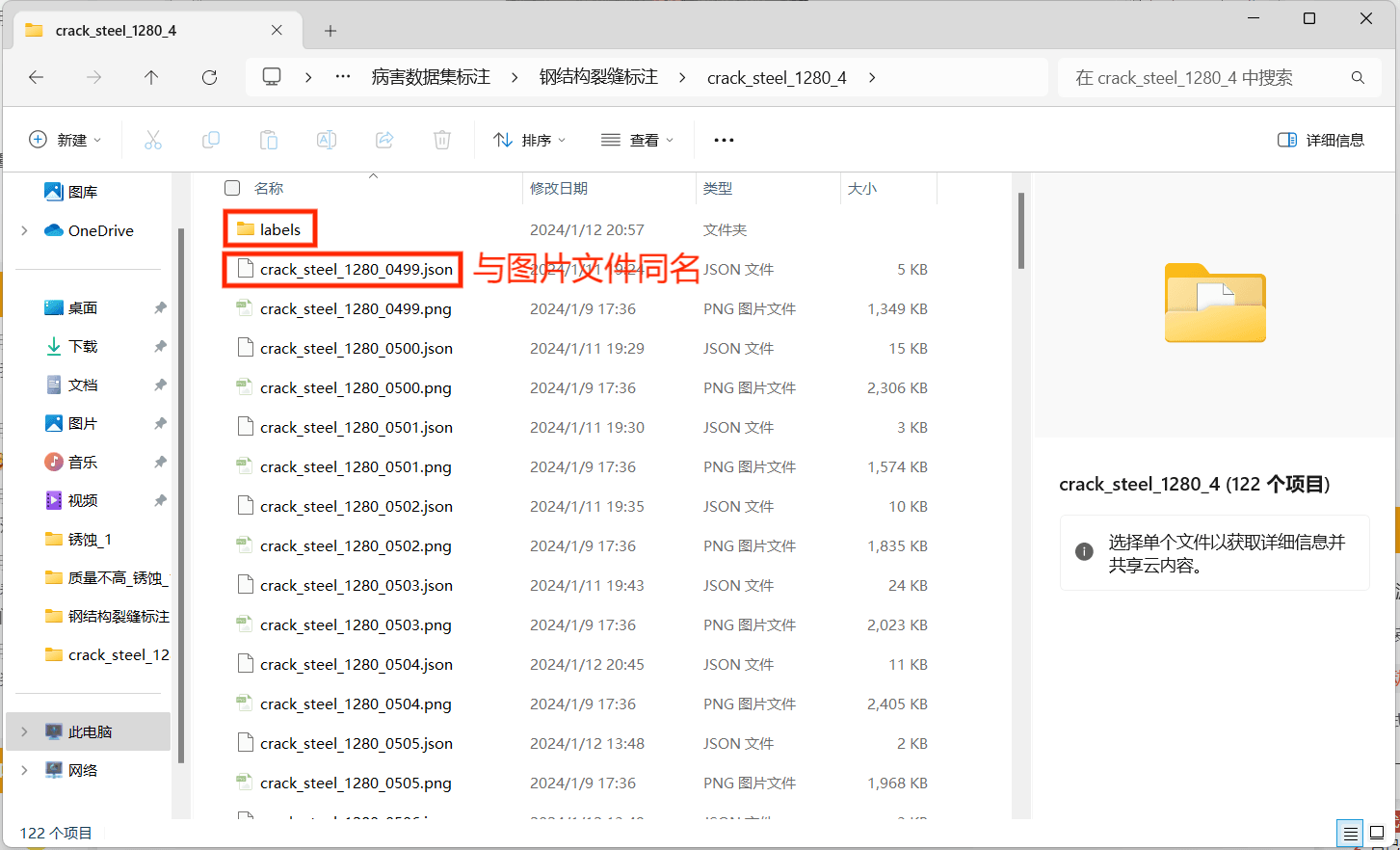

















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









