






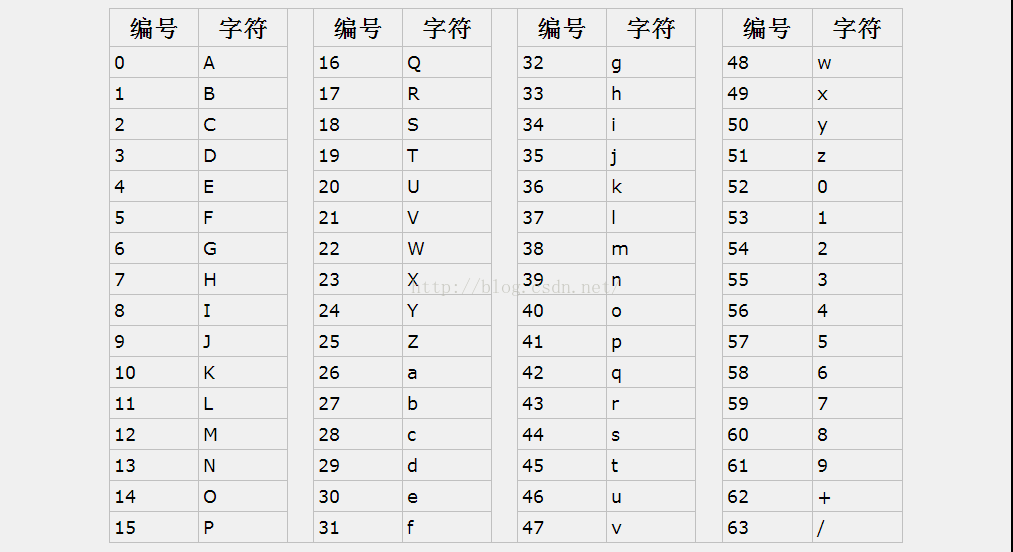
其实base64加密原理很简单它是用64个可打印字符表示二进制所有数据方法。由于2的6次方等于64,所以可以用每6个位元为一个单元,对应某个可打印字符。我们知道三个字节有24个位元,就可以刚好对应于4个Base64单元,即3个字节需要用4个Base64的可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中一般有所不同。但是,我们经常所说的Base64另外2个字符是:“+/”。这64个字符,所对应表如下。
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,于缓冲区中剩下的bit用0补足。然后,每次取出6个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。所以加密后的数据量是原来的4/3
这样说,仔细思考一下,你会很快发现,一个问题,就是每次转换的字节数不一定就是24的整数倍,会出现有多余不足六位的情况,在base64中处理的方法是加零凑够六位,但是这样一来在解码的时候就会出现多余的位 这该怎么办呢? 不用担心,base64想到了一个很好的解决办法。
这个办法就是在 base64凑零的同时,还要满足凑出来的位数是8的倍数,不然就加一个或者两个特殊的六位 = 符号。为什么是一个或者两个=符号呢? 因为多个8位转为6位 只会出现 剩余 2位,4位的情况,剩余2位 只需要一个 表示六位的 = 便可变为8的整数;而剩余4位 需要两个表示6位的 = 便可以变成16 是8的整数。然后在解密的时候不解析 =即可。
之所以位的总数需要凑成8的倍数,是因为base64主要用于加密后的数据传送,而在传送机制中都认为传送的最小单位是按照字节算的,所以不能出现不是位总数不是8的倍数的情况,在接收到数据后,按顺序将6位的base64直接按照顺序解密成字节就完成解密了。
接下来通过几张图为大家进行详细的解释:
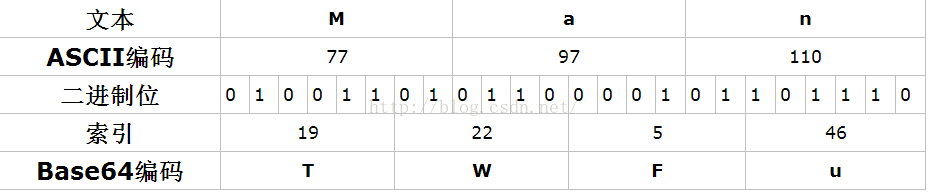
这是恰好三个字节转为base64
这是字节的位总数不是6的倍数的情况,当剩下4位时,我们需要补2个 = 凑齐8的倍数;当剩下的是2位时,我们需要补齐1个 = 抽泣8的倍数。

大概就是这个理我也不过多介绍看代码有具体解释
#include<stdio.h>
#include <string.h>
char base64[100];
char base[]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int main()
{
int i=0;
int q=0;
int len;
int ascii = 0;
char str[100];
printf("需要加密的字符串:\n");
gets(str);
len = strlen(str);//输入字符串的长度
for(i=0;i<len;i++){
ascii += str[i];
}
printf("你的ASCII码的值为%d\n",ascii);
if(ascii <= 1000)
{
for(i=0;i<len;i++)
{
str[i]=str[i]^base[i];
}
printf("base64加密表进行异或后的值为:%s",str);
}
else
{
//对该字符串进行base64加密输出
//由于base加密后会会扩大三分之一左右且三个字符(3*8=24)而base一个字符六位(4*6=24)
//即每次处理文本三个字符,base 4个字符.
if(len%3 == 0)
{
for(i=0,q=0;i<=len-3;i+=3,q+=4){
base64[q]=base[str[i]>>2]; //排除str第一个字符二进制中的后两位 0101 1101>>2 0001 0111 -> 23 ->base[23] ->X
base64[q+1]=base[(str[i]<<4|str[i+1]>>4) & 0x3f];//只要第一个字符的后两位和第二个字符的前四位 一 1010 0101<<4 0101 0000
//二 0101 0011>>4 0000 0101 通过| 运算再与3f (0011 1111) &&运算获取第一字符前两位第二字符前四位
base64[q+2]=base[(str[i+1]<<2|str[i+2]>>6)& 0x3f]; //str[i+1]<<2 实际是四位只不过后面&会时另外两位为0
base64[q+3]=base[(str[i+2]&0x3f)];}
}
else if(len%3 == 1)//与前面原理一样只需更改最后的结尾
{
for(i=0,q=0;i<=len-3;i+=3,q+=4)
{
base64[q]=base[str[i]>>2];
base64[q+1]=base[(str[i]<<4|str[i+1]>>4) & 0x3f];
base64[q+2]=base[(str[i+1]<<2|str[i+2]>>6)& 0x3f];
base64[q+3]=base[(str[i+2]&0x3f)];
}
base64[q]=base[str[len-1]>>2];
base64[q+1]=base[str[len-1]<<4 & 0x3f];
base64[q+2]='=';
base64[q+3]='=';
}
else if(len%3 == 2)
{
for(i=0,q=0;i<=len-3;i+=3,q+=4)
{
base64[q]=base[str[i]>>2];
base64[q+1]=base[(str[i]<<4|str[i+1]>>4) & 0x3f];
base64[q+2]=base[(str[i+1]<<2|str[i+2]>>6)& 0x3f];
base64[q+3]=base[str[i+2]&0x3f];
}
base64[q]=base[str[len-2]>>2];
base64[q+1]=base[(str[len-2]<<4|str[len-1]>>4) & 0x3f];
base64[q+2]=base[(str[len-1]<<2) & 0x3f];
base64[q+3]='=';
}
//printf("base64加密表进行加密后:%s",base64);
puts(base64);
}
return 0;
}
主要代码块解释
{
//对该字符串进行base64加密输出
//由于base加密后会会扩大三分之一左右且三个字符(3*8=24)而base一个字符六位(4*6=24)
//即每次处理文本三个字符,base 4个字符.
if(len%3 == 0)
{
for(i=0,q=0;i<=len-3;i+=3,q+=4){
base64[q]=base[str[i]>>2];
//排除str第一个字符二进制中的后两位
0101 1101>>2 0001 0111 -> 23 ->base[23] ->X
base64[q+1]=base[(str[i]<<4|str[i+1]>>4) & 0x3f];
//只要第一个字符的后两位和第二个字符的前四位 一 1010 0101<<4 0101 0000
//二 0101 0011>>4 0000 0101 通过| 运算再与3f (0011 1111)
&&运算获取第一字符前两位第二字符前四位
base64[q+2]=base[(str[i+1]<<2|str[i+2]>>6)& 0x3f];
//str[i+1]<<2 实际是四位只不过后面&会时另外两位为0
base64[q+3]=base[(str[i+2]&0x3f)];}
}













 2394
2394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









