






大型语言模型(LLM),如DeepSeek,无疑是人工智能领域的璀璨明星。它们学识渊博,能应对五花八门的通用任务,从写诗作赋到答疑解惑,几乎无所不能。然而,当我们期待这位“全能学霸”在特定垂直领域,比如法律、医疗或金融行业,展现出同样专业的深度时,往往会发现它显露出一些“水土不服”的迹象。
例如:
在微调前:
提问“合同违约金的上限是多少”
回答:“合同违约金的上限一般根据合同金额和具体情况来确定,不同国家和地区的法律规定可能有所不同。”
这种回答没有给出具体的法律依据和明确的数值范围,对于需要准确法律建议的用户来说帮助不大。
在微调后:经过在法律领域语料库上微调后
提问:“合同违约金的上限是多少”
回答:“根据我国《民法典》第五百八十五条的规定,当事人可以约定一方违约时应当根据违约情况向对方支付一定数额的违约金,也可以约定因违约产生的损失赔偿额的计算方法。约定的违约金过分高于造成的损失的,人民法院或者仲裁机构可以根据当事人的请求予以适当减少。一般情况下,违约金的上限不得超过因违约造成的损失的30%。”
微调后的回答不仅引用了具体的法律条文,还给出了明确的计算标准,能够更好地满足用户对法律问题的咨询需求。
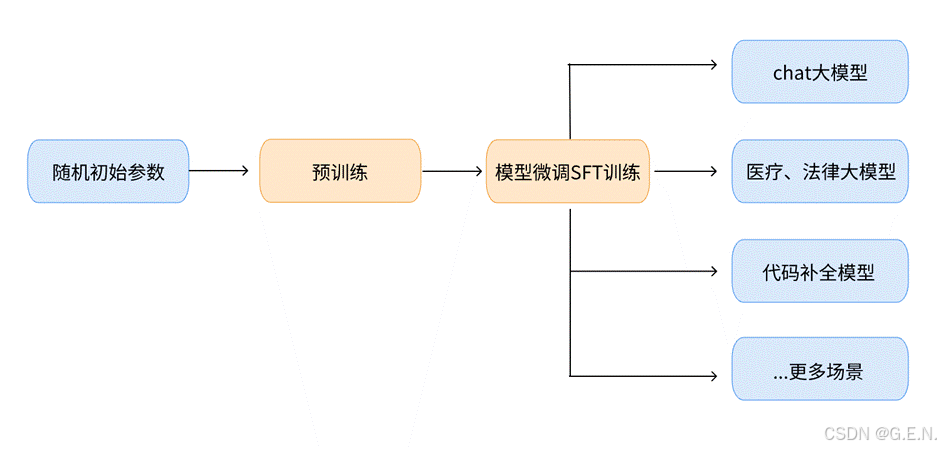
微调:让通用模型变“专业”
那么,如何让这位潜力无限的“通才”快速成长为特定领域的“专家”呢?答案就藏在模型微调(Fine-tuning)这一关键技术中。
微调,可以形象地理解为给已经训练好的通用大模型进行一次“专业深造”。它利用特定领域的数据,对模型的参数进行精细的调整和优化。这个过程就好比为那位全能学霸量身定制了一套“专家速成课程”,让它在保留原有广博知识和通用能力的基础上,迅速习得特定领域的专业知识、行话习惯以及独特的思考方式。
微调的技术细节
微调涉及几个关键步骤。
- 微调的始于精心准备数据。这是整个过程的基石,需要收集大量与目标任务高度相关的、高质量的样本。例如,若想打造一个法律问答助手,就需要准备海量的法律问题及其对应的专业、准确的答案;若目标是生成规范的医疗报告,则需要收集足够多符合标准的报告范例。数据的质与量,直接关系到微调能否成功孕育出真正的“专家”。
- 数据就位后,接下来需要明智地选择微调策略。是选择对模型的所有参数进行调整的全参数微调,还是采用更轻量化的参数高效微调(PEFT)方法?全参数微调潜力巨大,但如同对整个大脑进行重塑,计算成本高昂,耗时费力。而PEFT,尤其是近年来备受瞩目的LoRA技术,则提供了一条更为经济高效的路径,仅需调整模型的一小部分参数或增加少量额外参数即可。选择哪种策略,需要根据任务的复杂度和可用的计算资源来权衡。
- 选定策略之后,便进入了关键的训练与调优阶段。这涉及到设置一系列超参数,如学习率(决定模型学习的速度)、批量大小(每次“喂”给模型多少数据)以及训练轮数(整个数据集需要反复学习多少遍)。这些参数如同烹饪时的火候与调料,对最终成品的“风味”——也就是微调效果——有着至关重要的影响,往往需要通过反复实验来找到最佳组合。
- 最后是评估,微调后的模型需要在验证集或测试集上进行性能评估,以确保其达到了预期目标。
深入探索:LoRA技术
在众多参数高效微调技术中,LoRA(Low-Rank Adaptation) 以其独特的魅力和显著的优势,成为了当前的主流选择之一。
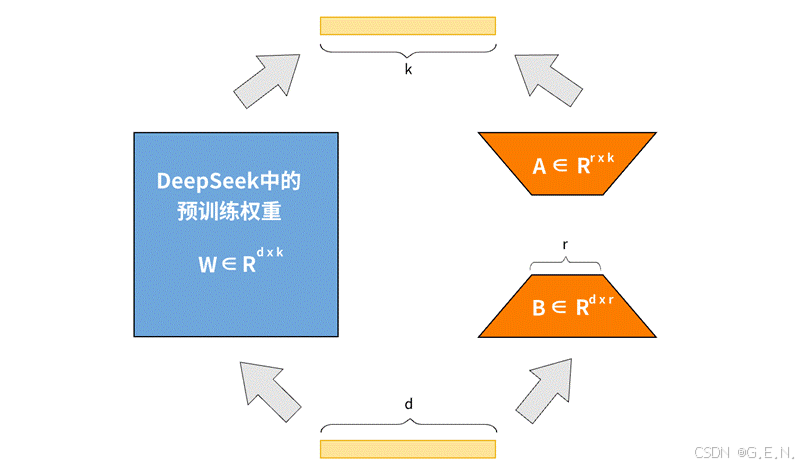
那么,LoRA究竟有何奥妙?想象一下大型语言模型内部庞大如星海的参数(权重),它们构成了模型知识与能力的基础。全参数微调试图调整这亿万连接,工程量可想而知。LoRA则提供了一种更为巧妙的思路:我们无需大动干戈地修改模型原有的复杂结构,只需在关键节点“附加”一些轻巧的“调整模块”即可。
LoRA的核心假设是,模型为了适应新任务所需要的改变,可以用一种更简洁、数学上称为“低秩”(Low-Rank)的方式来高效表示。它并不直接改动原始模型巨大的权重矩阵(W₀),而是引入两个规模小得多的矩阵(A和B),通过它们的乘积(ΔW = BA)来学习并代表这种适应性调整。最终,模型的行为就由原始能力(W₀)加上这个新增的“适应模块”(ΔW)共同决定,即 W = W₀ + ΔW。
打个比方,LoRA就像是为基础模型(W₀)配备了一个个可插拔的“专业技能插件”(ΔW)。这些插件体积小巧,训练起来快速便捷,并且可以针对不同任务灵活更换。在训练过程中,我们“冻结”模型原有的庞大参数主体,只专注于训练这些新增的小插件(即A和B矩阵),极大地提高了效率。
LoRA之所以能脱颖而出,其魅力在于多方面的优势。
- 它带来了极高的效率。由于训练的参数量大幅减少(新增的A、B矩阵参数远少于原始模型),LoRA显著降低了对计算资源(尤其是显存)的需求和训练时间,使得在相对有限的硬件条件下微调大模型成为现实。
- LoRA在提升专业性的同时,有助于保持模型的通用性。因为它不直接修改原始参数,模型在学习新技能时不易“忘记”原有的知识,有效缓解了所谓的“灾难性遗忘”问题。这意味着经过LoRA微调的模型,既能在特定任务上表现出色,又能继续处理其他多样化的问题,实现了一举两得。
- LoRA的效果非常显著。尽管看似只是“小修小补”,但大量实践证明,设计得当的LoRA微调往往能在特定任务上取得与资源密集型全参数微调相媲美,甚至更优异的结果。无论是回答问题的精准度,还是生成内容的专业度,都能带来令人眼前一亮的提升。
- LoRA适配器(训练好的A、B矩阵)具有出色的模块化与可移植性。它们通常体积很小,便于存储、分享和部署。开发者可以为同一个基础模型训练多个针对不同任务或风格的LoRA适配器,根据需要灵活加载,实现快速的能力切换。
让我们再次回到文章开头的那个法律问题。当模型经过针对法律领域语料库的LoRA微调之后,面对同样的提问:“合同违约金的上限是多少?”
它的回答可能会是这样的:“根据我国《民法典》第五百八十五条的规定,当事人可以约定一方违约时应当根据违约情况向对方支付一定数额的违约金……如果约定的违约金过分高于造成的损失,人民法院或者仲裁机构可以根据当事人的请求予以适当减少。在司法实践中,通常认为违约金不宜超过实际损失的30%。”(请注意:具体的司法实践标准可能存在变动,此处仅为示例说明微调效果。)
对比可见,微调后的回答不仅精准引用了相关的法律条文,还给出了更具实践指导意义的参考标准。这种专业性和实用性的提升,正是微调技术价值的直观体现。
结束语
模型微调技术,特别是以LoRA为代表的高效微调方法,为像DeepSeek这样的通用大模型开辟了通往深度专业化的广阔道路。它不仅让AI在特定领域内能够展现出令人信服的专业能力,更为企业和开发者提供了一种高效、经济的AI定制化解决方案。随着这项技术的不断成熟和普及,微调必将成为推动人工智能从实验室走向广泛应用,让个性化、专业化AI服务惠及更多人的重要引擎。它让我们有理由相信,一个AI能真正“懂你”的时代,正加速到来。



















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











