







文章目录
一. scrapy框架简介
scrapy是一个专门用python实现爬取网页数据,提取结构性数据的框架,它相对requests请求库,selenium等抓取方式相比,scrapy可以更加高效快速的抓取到数据,尽管scrapy是设计来web网络抓取的,但是它也可以用来访问API来提取数据
二.scrapy的安装
你首先要检查一下自己的python解释器是不是3.9版本或者3.9之后的版本,因为在windows操作系统下面去安装时,就是需要3.9版本后的解释器才有可能会安装成功,否则就会报错,但如果你的`电脑时mac或者Linux版本的话就可以不用考虑python解释器的版本,因为这个scrapy框架的底层使用的时twisted异步包
检查好解释器版本后就直接在cmd终端输入 pip install scrapy
如果出现了报错,就使用pip镜像源进行加速安装
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
如果报了一个关于twisted的错误就进入以下网页进行安装一个twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
根据自己电脑和python对应的版本进行twisted的下载
如果还是不能正常安装,就使用下面的最终方案
下载一个anacode软件包
anacode的安装教程以及虚拟环境的配置 https://blog.csdn.net/qq_45344586/article/details/124028689
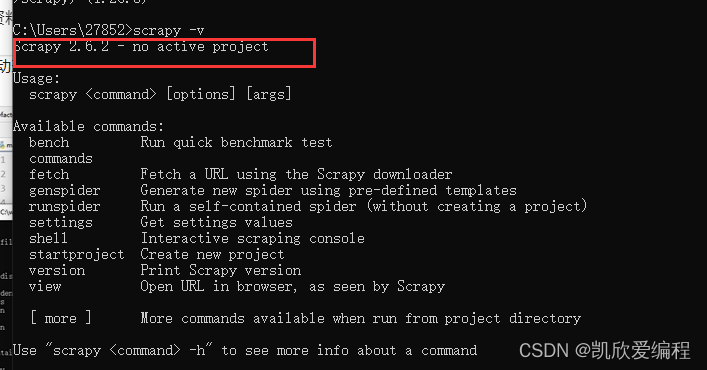
在cmd终端输入scrapy -v命令如果可以看到版本号说明已经安装成功了
三.scrapy的基本使用
创建一个scrapy项目
输入 scrapy startproject 项目名
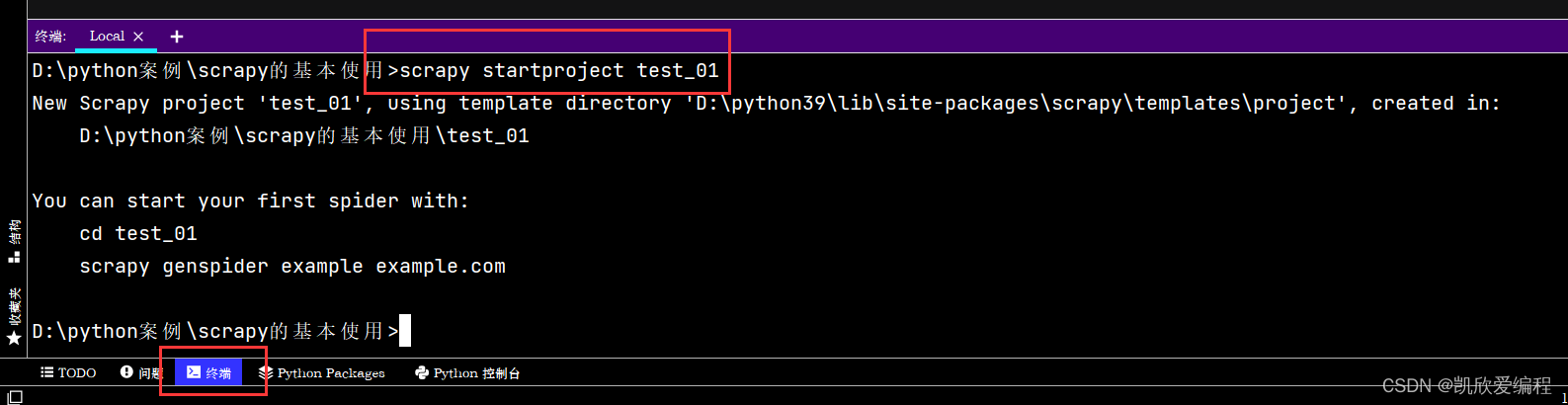
创建项目后,会有这些文件,里面每个文件都会有自己在scrapy框架中的功能

test_01是项目的文件名
spiders下面的__init__.py是一个初始化文件,此外spiders文件夹下面会存放我们爬虫过程中创建的所有爬虫文件
scrapy.cfg是项目文件夹的一个配置选项,没有太大的用处,基本可以忽略
item.py顾名思义可以看出它是一个创建数据结构的文件,就是创建你爬取数据时数据的字段
middlewares.py它是一个中间件,主要功能是做IP代理池,拦截响应等等
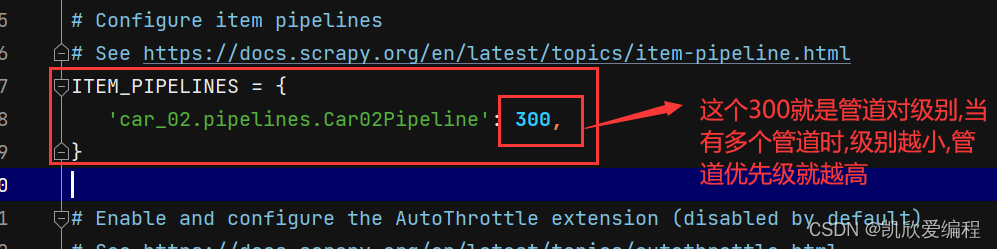
pipelines.py 它是一个管道文件,主要用来对抓取下来的数据进行持久化存储,并且在里面可以开辟多个管道进行数据下载,但管道会讲究一个优先级队列,值越小,优先就越高
settings.py 它可以用来开启和关闭管道文件,下载中间件,还有一些配置选项,比如日志文件,robots协议,请求头等等
创建一个爬虫文件
输入scrapy genspider + 爬虫文件名 + url的域名
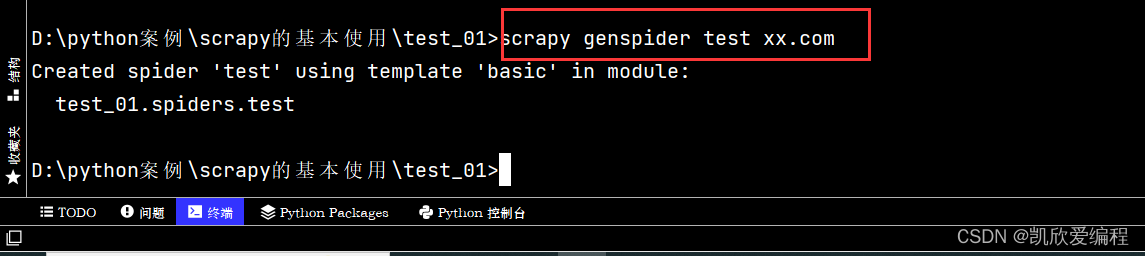
这就是我们创建的爬虫文件
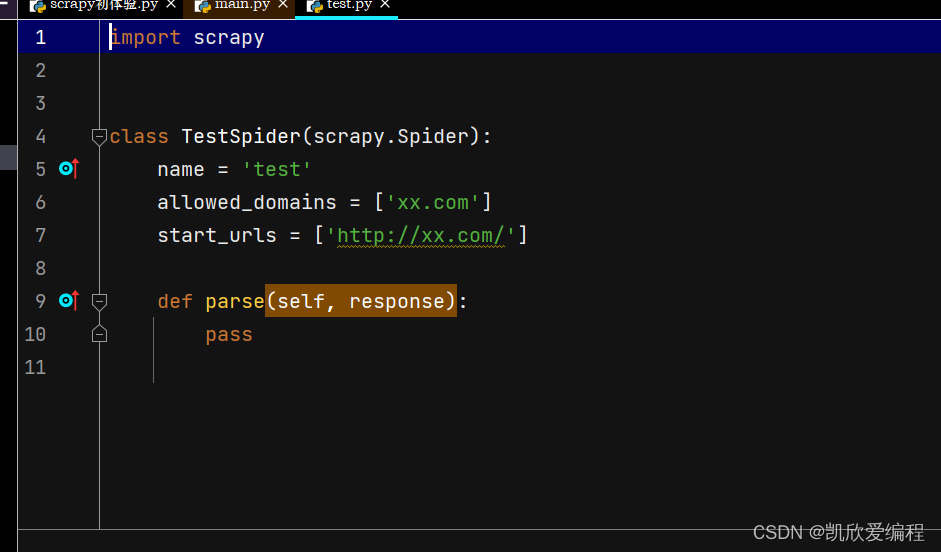
name 爬虫名称,主要是运行爬虫项目的使用
allowed_domains 这个是允许抓取的域名,就是如果你只想抓取某一个域名的网站,就可以使用这个去过滤掉那些不是你想要抓取的域名
start_urls 是scrapy发起请求的网址,他里面可以是一个url也可以是多个,当然我们大部分都是只写一个
parse 函数里面是scrapy向url发起请求获取到的响应结果的回调函数,就是在里面进行一系列的数据抓取过程
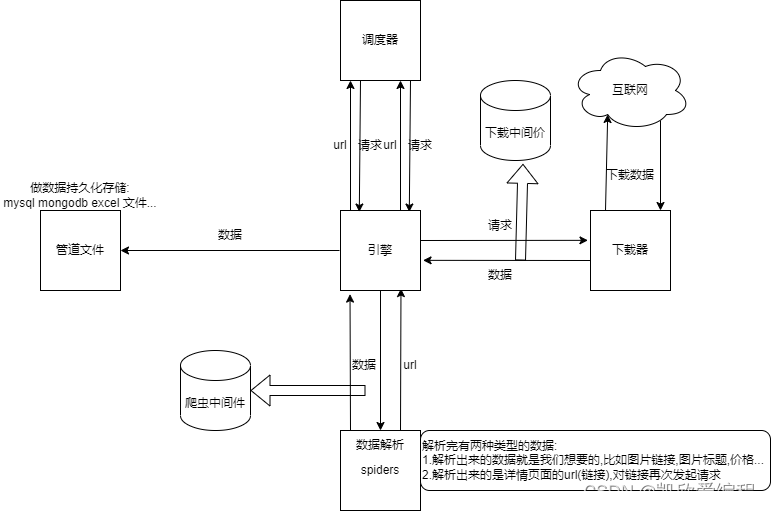
四. scrapy架构流程图
五.汽车之家案例抓取
首先我们需要创建一个scrapy项目
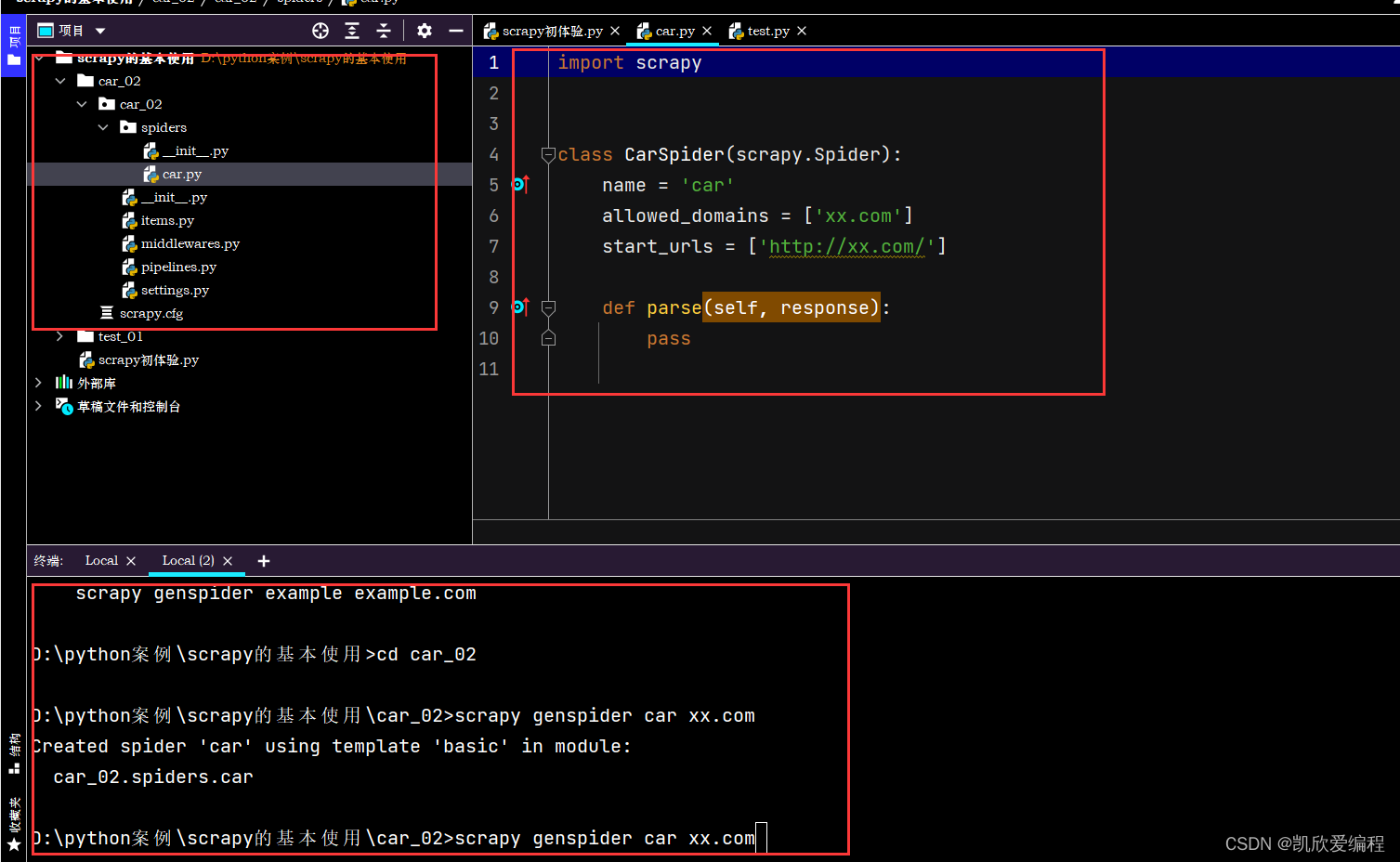
找到页面链接

将网页链接填入scrapy的url_start处,并进行检测scrapy是否运行成功
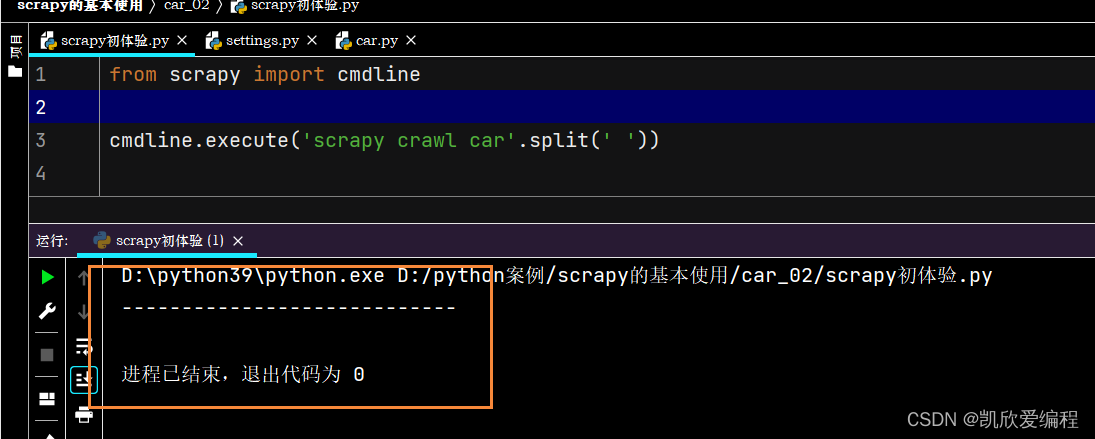
为了可以直接右击运行scrapy项目文件,可以直接创建这个文件进行运行,当然你也可以直接在python的终端输入scrapy crawl + 爬虫文件名称 就可以了
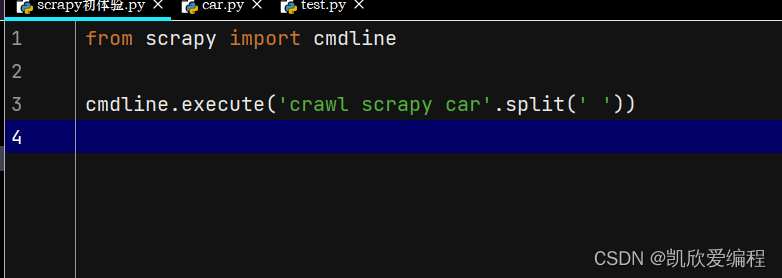
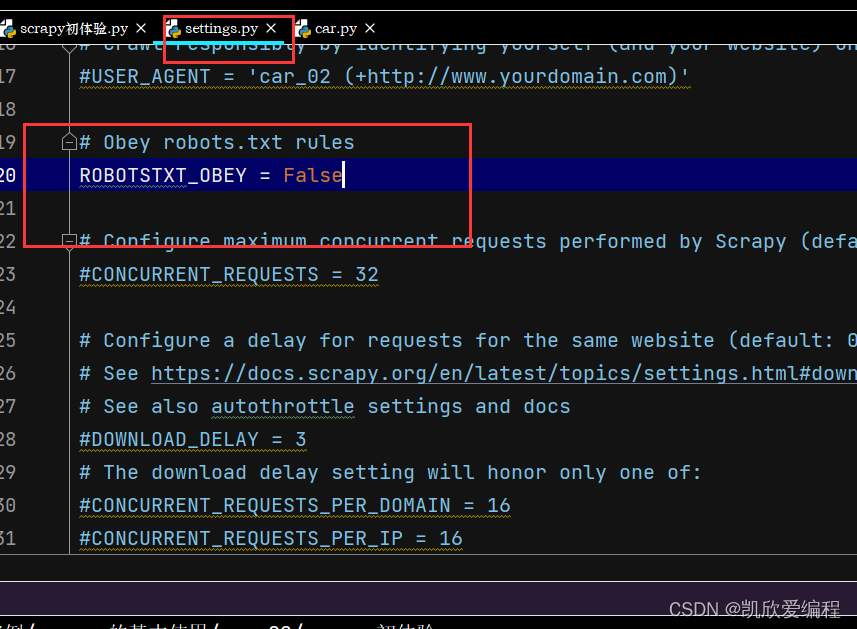
运行之前需要把settings.py中的robots协议改成False
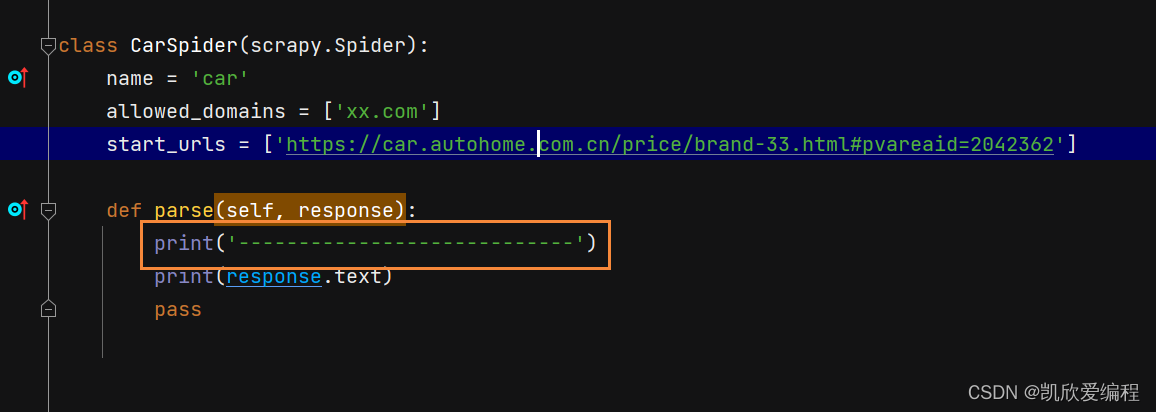
启动项目后如果可以看到打印输出"-----------------------------"说明启动成功
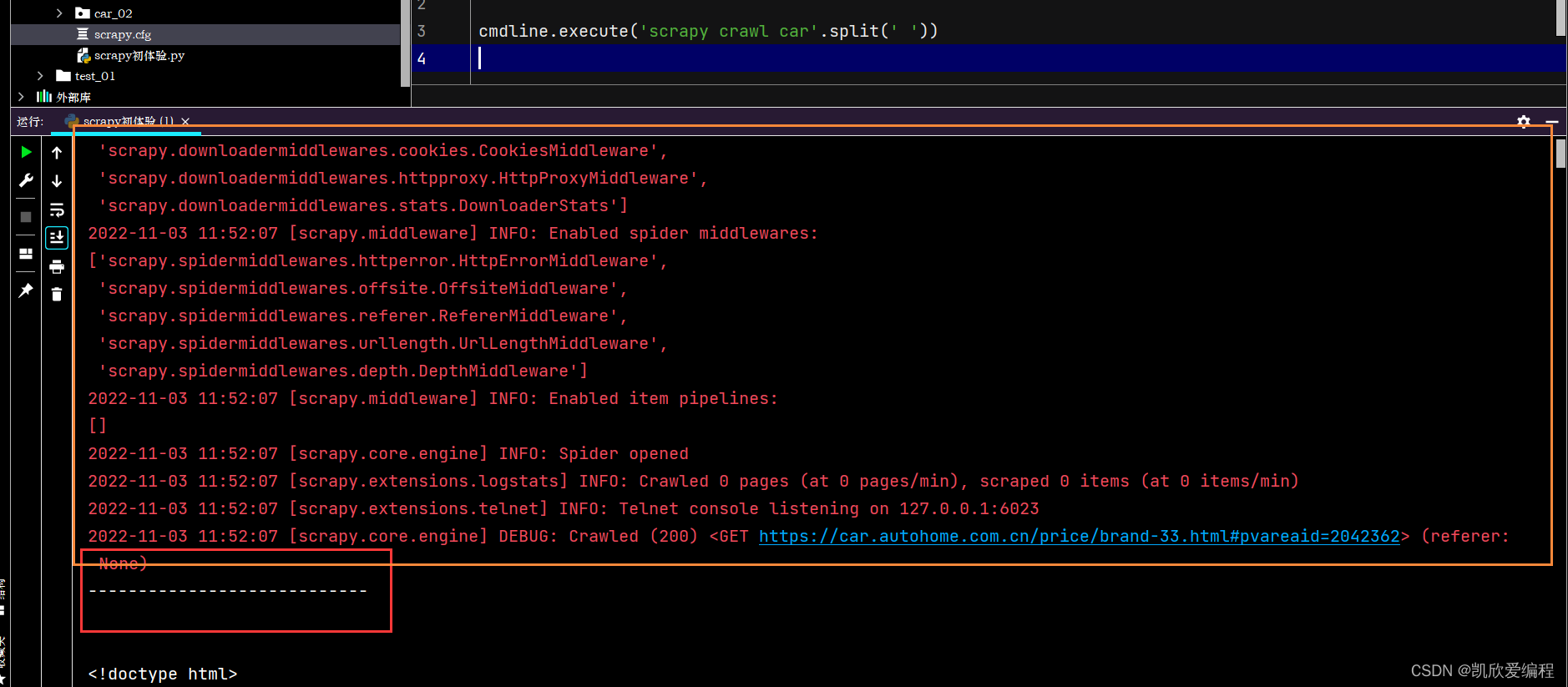
从这里可以看出这个scrapy项目已经成功启动了,但是有一些日志级别的报错,如果想让日志级别的报错不显示可以在settings.py配置选项文件中去设置日志级别
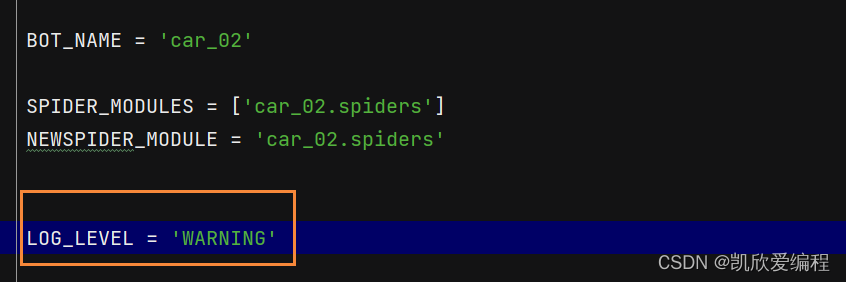
这个配置选项就是只显示有关警告的日志级别,当然你也可以将这些日志级别的报错创建一个文件保存下来(在配置选项中输入LOG_FILE=“file.log”)
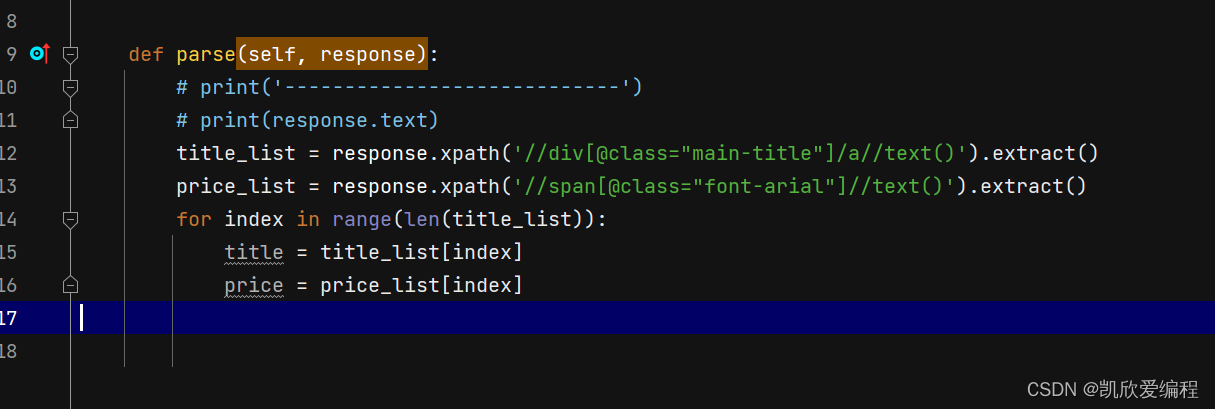
在spiders里的爬虫文件做好数据解析
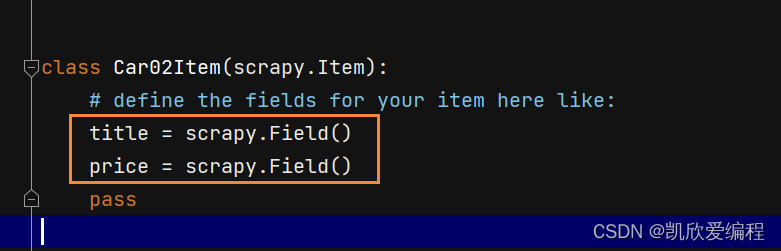
去item.py文件中创建数据结构
将创建的数结构的类导入到爬虫文件中,并且提交要保存的数据
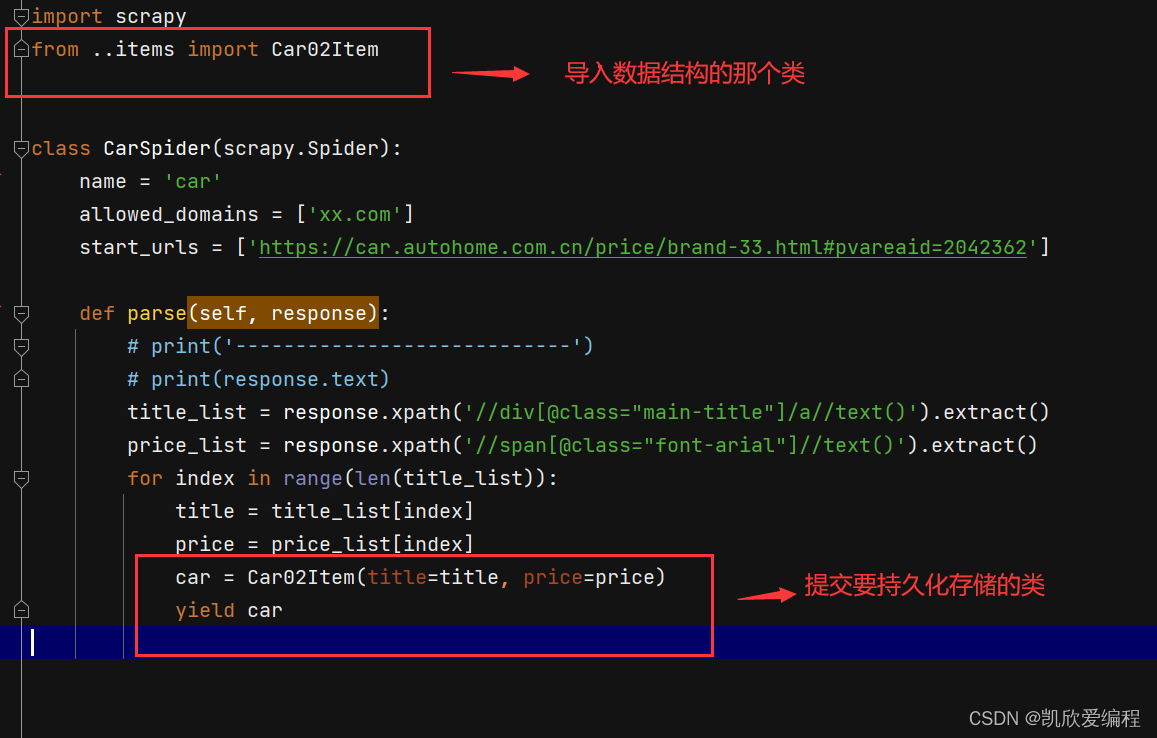
在settings.py文件中打开我们的管道,进行保存数据
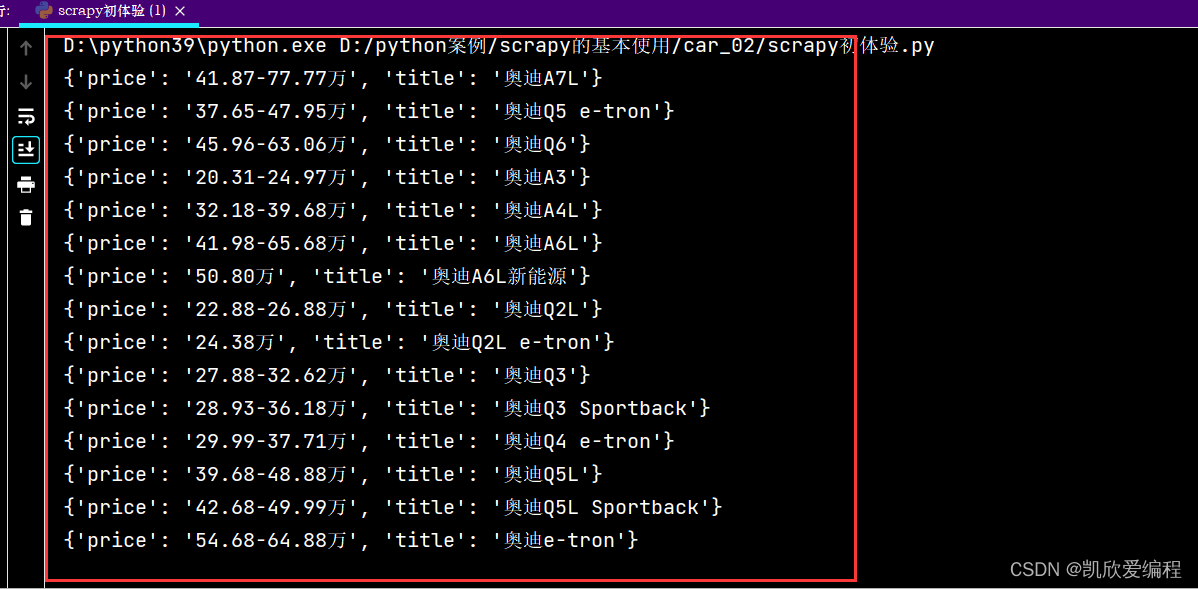
打开pipelines.py管道文件进行一个数据输出,检验数据是否已经存储了
六extract()和extract_first()区别和用法
extract()就是获取selector对象中的data属性值,因为scrapy中用到的xpath解析库有点结合了我们的parsel解析库的selector对象,但是parsel是用get()和getall(),这里的extract()就相当于parsel中的getall()方法
extract_first()就是获取selector()对象列表中的第一个data属性值,相当于parsel解析库中的get()方法
七.当当网数据抓取(scrapy的分页抓案例)

抓取到这个图片链接,你可以看到除了第一张图片其他的都是一些none的png,这种情况就是存在懒加载(我们可以看到第二张图片有一个data-original的属性里面就是图片懒加载的链接)
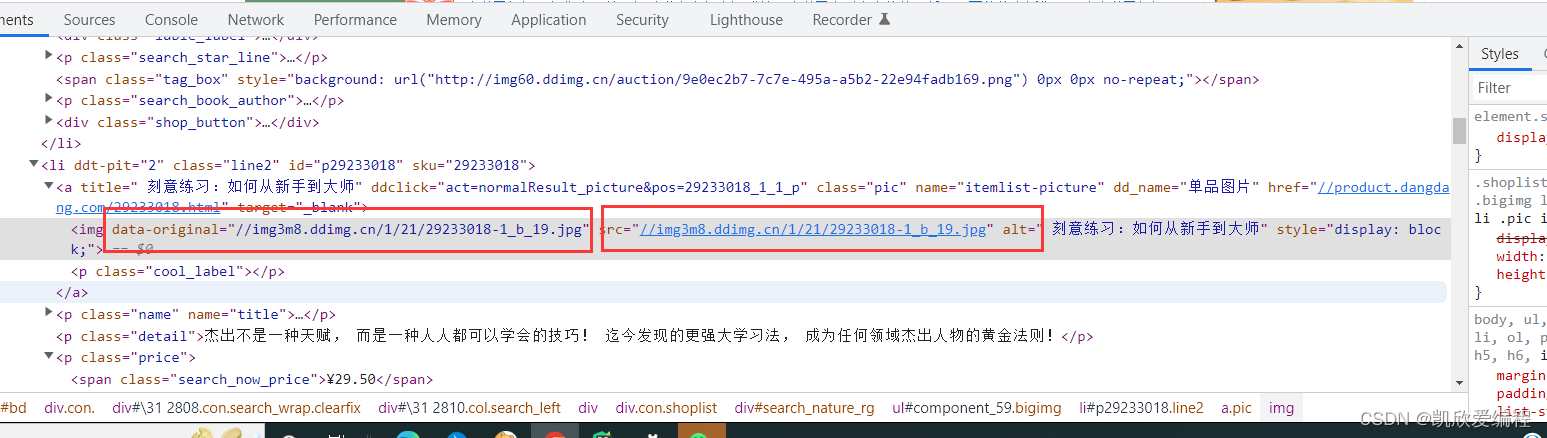
所以要用到分支语句进行一个判断从而获取图片链接
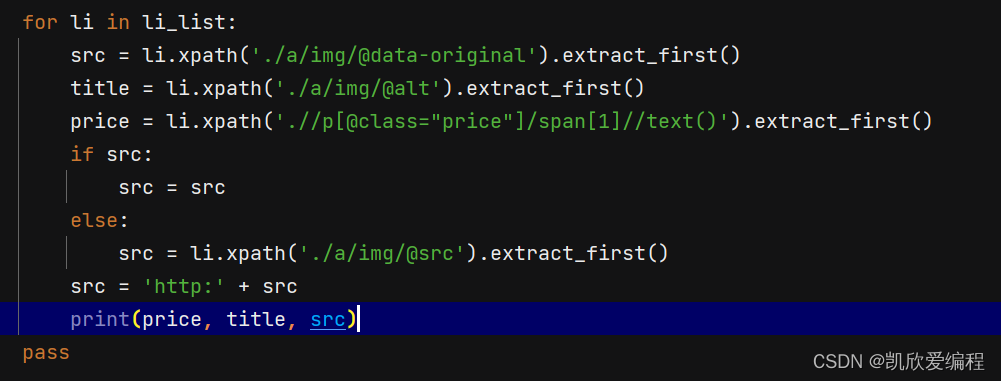
在item.py创建数据结构
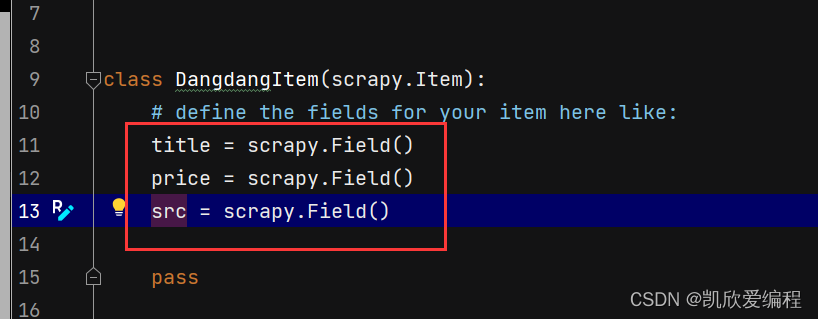
把item的class类导入到爬虫文件中,把抓取的数据提交到item中去


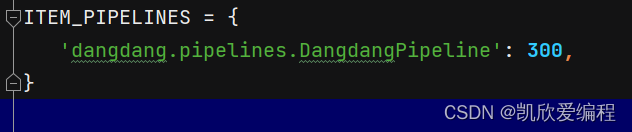
在settings.py中开启管道文件
在pipelines.py文件中保存数据
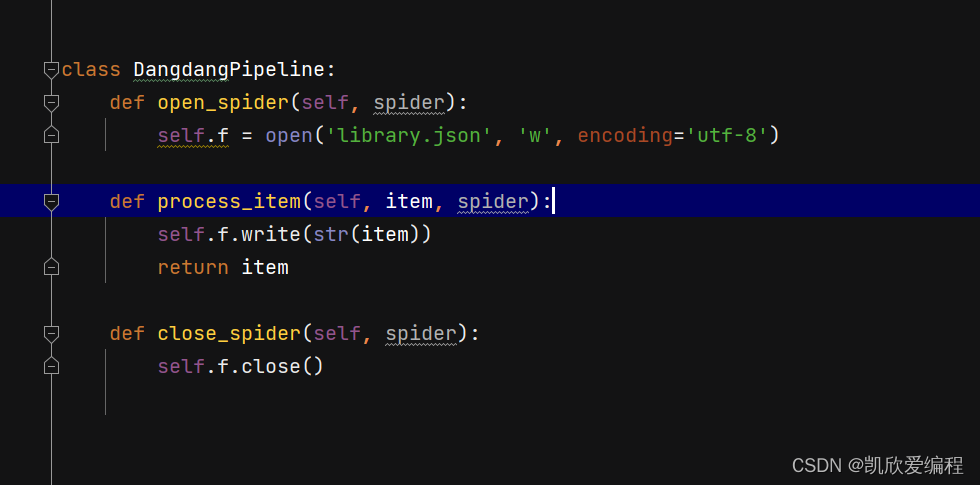
可能大家会疑惑我为什么要这样分成三个函数去写,而不是直接使用with open(‘library.json’,‘a’,encoding=‘utf-8’),因为我们spider文件中的数据是一条一条提交的,如果使用with open 就会每次都会打开关闭文件,这样会非常耗费性能,所以就专门创建一个函数,只打开和关闭一次json文件
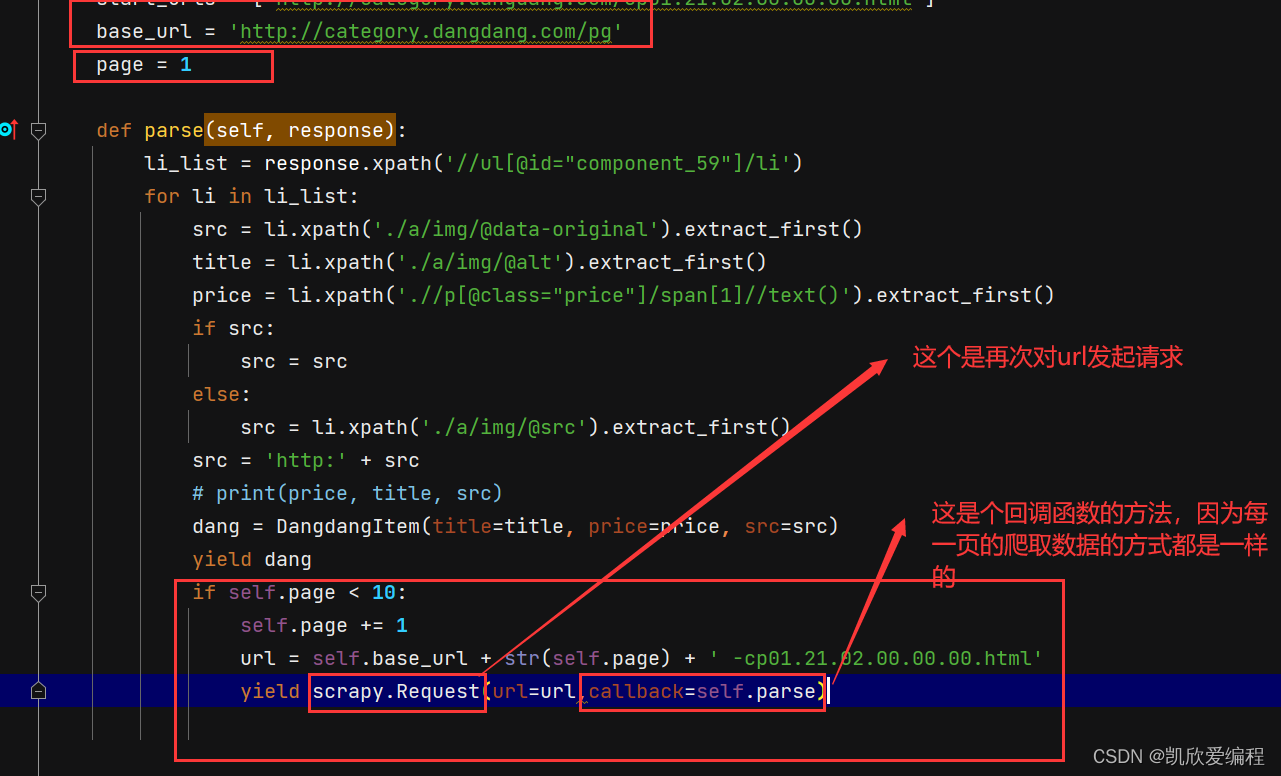
分页操作
首先观察每一页url之间的关系然后进行分页(可以发现就一个pg1,pg2,pg3的规律)

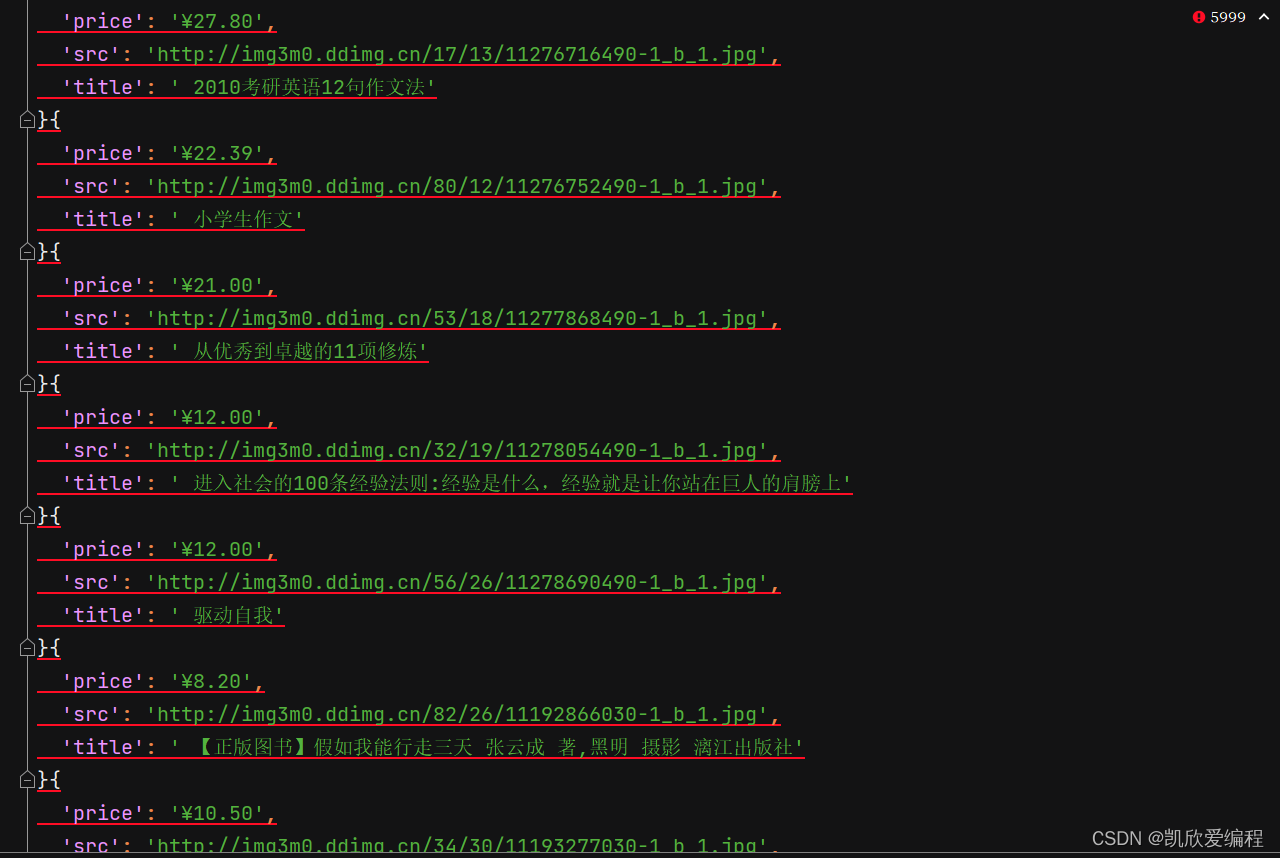
几千条数据几秒钟就可以下载完成,体现出scrapy快速高效的特点
八.总结
本章主要是讲解scrapy的安装与基本使用,讲解scrapy的实现基本流程,以及如何使用scrapy进行分页抓取数据















 6680
6680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











