






学习内容
正则化

数据增强,参数范数惩罚,Dropout,提前终止,随机池化
欠拟合与过拟合

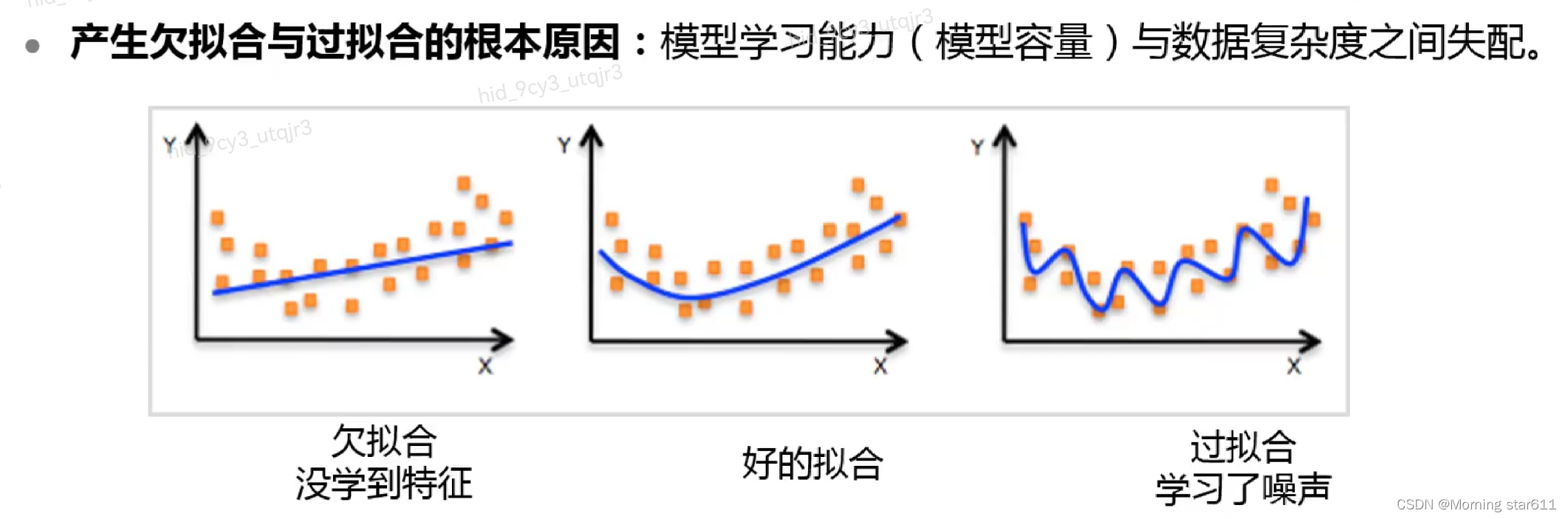 过拟合和欠拟合的应对方法
过拟合和欠拟合的应对方法
数据增强
数据增强即增加数据样本。防止过拟合的最有效方法是增加数据样本。
噪声注入可以在网络的不同位置加入噪声:输入层(数据集增强),隐藏层(Dropout),输出层(标签平滑)
L1,L2正则
其均是通过增加范数惩罚项来防止过拟合
L1可以在参数w较小的时候缩减至0,从而起到特征选择的作用
范数约束相当于对参数添加先验分布,L2范数相当于参数服从高斯先验分布,L1范数相当于拉普拉斯分布
Dropout
Dropout是一种集成方法,通过随机丢弃得到子网络,并将子网络结果合并。
其作用有取平均值,减少神经元之间复杂的共适应关系,类似于性别在生物进化中的作用
提前终止
在训练过程中,插入对验证集数据的测试,当发现验证集数据的LOSS上升时,提前终止训练。
随机池化
随机池化即按一定概率,随机选取一个元素,介于平均池化和最大池化之间,有更好的正则化效果。
优化器
优化器有全局梯度下降,随机梯度下降,小批量梯度下降,Momentum,Adam,Adagrad,Adadelta,RMSprop
Adadelta是Adagard的扩展,RMSprop是Adadelta的特例,这两种优化器都是为应对Adagrad学习率急剧下载问题。
Adam是带动量的RMSprop,其优点是偏置校正后,每个迭代学习率都有确定范围,参数较平稳。
选择优化器
数据稀疏:自适应(Adagrad,Adadelta,RMSprop,Adam)
梯度稀疏:Adam比RMSprop效果更好
总的来说,Adam会有更好的效果。
心得
正则化的最终目的是为了减小训练误差和泛化误差,训练误差过大即为欠拟合,会有较大的偏差,泛化误差过大即为过拟合,会有较大的方差。而导致这些误差过大的根本原因是模型学习能力与数据复杂度之间的失配。
正则化的手段方法存在多种,不同的方法会产生不同的效果。其中最有效的方式是增加数据样本,但这种方法的效率较低,在实际操作中较难实现,且实现成本较高。相应的其他正则化的方法也是各有优缺,例如L1可以在参数w较小的时候起到特征选择的作用。在实际的操作过程中,要根据模型的要求,选择合适的正则化方法,达到高效解决问题的目的。
优化器在不断地优化,好的优化器结合多种优化器,从而达到更好的优化效果,总的来说,Adam相对其他优化器会有更好的效果。
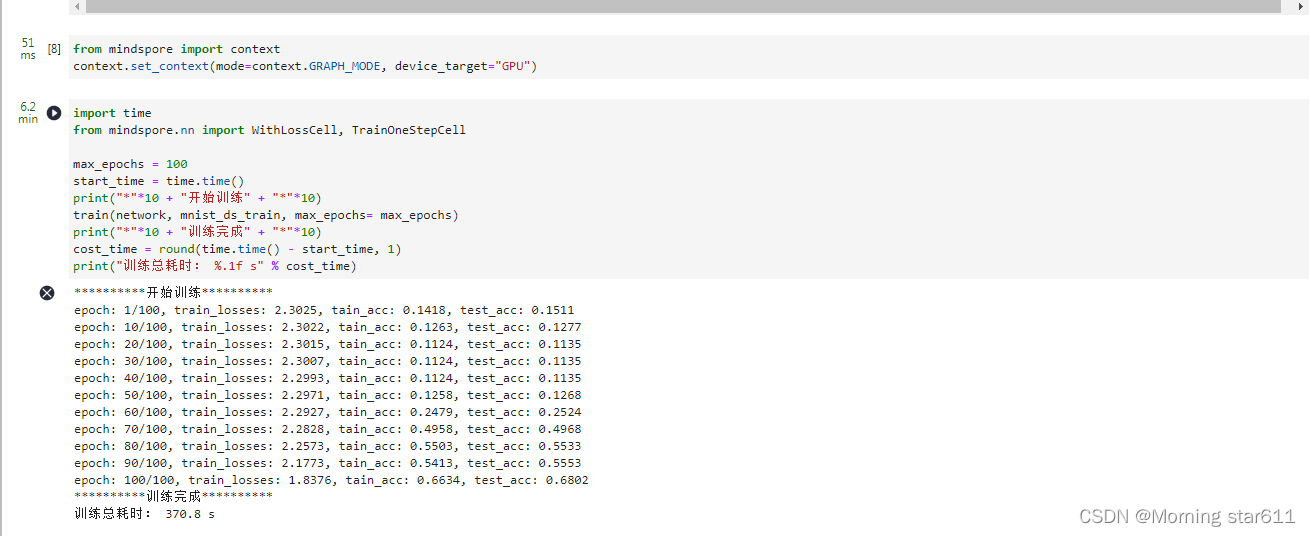
实践案例















 2256
2256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









