







感觉大家对原理性的东西不太感兴趣,那我就直接举例提供代码,以及详细的注释,大家自己对照改代码应用于你自己建立的模型吧。
完整代码关注博客底部微信公众号获得!
这些代码全部是我自己做数模竞赛时候自己用的代码。可以直接运行,记得修改文件路径。
一、安装所需的python 包
pip install scikit-learn
pip install numpy
pip install pandas
二、采用DBSCAN算法判断异常值
**注意:**我以2016年电工杯的负荷数据为例进行处理,这个DBSCAN算法非常适用于数据量大的赛题,如负荷预测,货物流量预测等等之类的。
注意代码需要把自己的数据文件格式转换为CSV文件,并且把路径修改为自己文件所在的路径,不会转换的参考我此教程文件格式转换:EXCEL和CSV文件格式互相转换。
我知道大家对原理性的东西不感兴趣,我把他的原理介绍放在文末,需要写论文的同学自己拿去用,记得修改,否则查重率过不去。
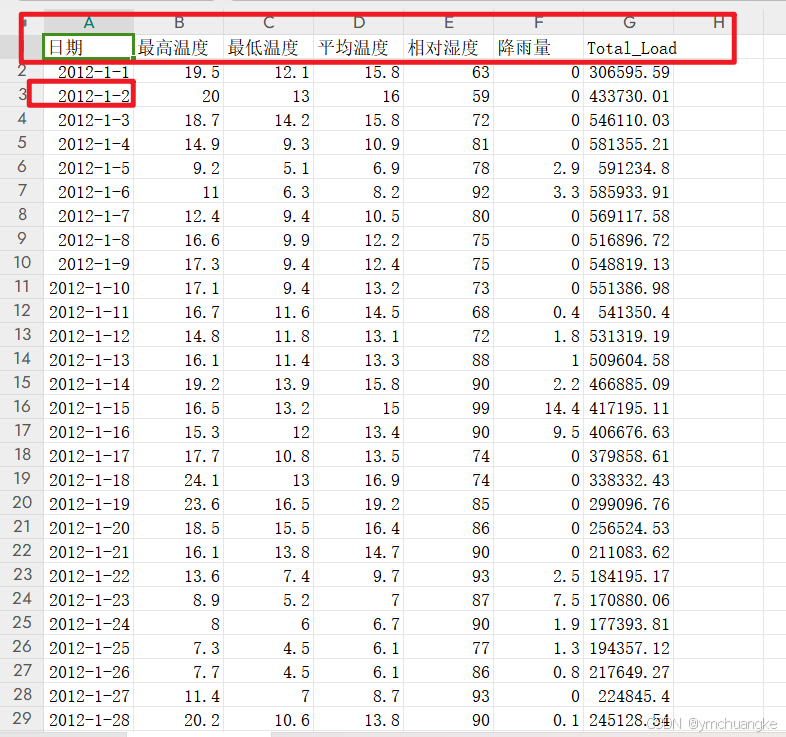
2.1 数据格式如下:
为了保证大家代码能够直接运行,我建议你们将日期修改为我下图的这种格式。
2.2代码(完整代码关注底部微信公众号获得)
注意:大家必须用我的这篇博客中的excel转csv,将你的excel文件转化为csv文件进行操作,否则会报错编码错误。
2.2.1 双变量
注意:双变量提供了可视化二维图像,确定x轴y轴变量,同时也会输出异常值
import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 尝试不同的编码读取CSV文件
try:
data = pd.read_csv('fuhe_load_total.csv', encoding='gbk')
except UnicodeDecodeError:
data = pd.read_csv('fuhe_load_total.csv', encoding='utf-8')
# 可视化结果
plt.scatter(X['最高温度'], X['最低温度'], c=clusters, cmap='Paired', label='Clusters' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











