







STP
STP(spanning-tree protocol)生成树协议
思科的STP是基于IEEE的802.1D,华为的STP是基于IEEE的802.1T,区别就是默认的带宽cost不同
生成树的选举过程
Ⅰ 选举根交换机(根桥)
网桥ID(BID最小者当选)
先比较优先级的大小,后比较MAC地址的大小
根桥是进行发送BPDU的一方,BPDU会全网泛洪的发送,每个加电的接口都发送,只能传给相邻的设备之间
根交换机上面的所有端口都叫指派端口(指定端口),这些端口是不会阻塞掉的,一直都会处于转发状态
Ⅱ 选举根端口
非根桥连接根桥最优的链路叫做根端口,根端口用于接收交换机发来的BPDU或转发流量
根桥通过发送BPDU来选举根端口(这个BPDU称为配置BPDU),发送的BPDU会累加经过设备的cost开销值来进行选举(累加BPDU发送方向的in口cost值)
链路带宽和路径成本值得对应关系
| 链路带宽 | 成本值 |
|---|---|
| 4mb/s | 250 |
| 10mb/s | 100 |
| 16mb/s | 62 |
| 100mb/s | 19 |
| 1Gb/s | 4 |
| 10Gb/s | 2 |
| 总而言之,链路带宽越大,成本值越小 |
注意:选举是通过网络中交换机中相互发送生成树协议专用的数据帧BPDU来实现的。(这些帧以组播地址01-80-l2-00-00-00为目的地址)
Ⅲ 选举指派端口并阻塞非指派端口
每个网段只能选出一个指定端口(DP),指定端口是用来转发BPDU和普通流量
生成树的端口状态和端口角色
端口状态
它们都是发送,接受BPDU来保持端口的角色
只要交换机的接口加电,从Disable到Listening的过程是一瞬间的,但是Listening到Forwarding总共需要30s的时间,早期交换机刚插电开机的时候,接口都是橘黄色的(因为有30s收敛时间),收敛完成之后,接口变为绿色进入转发状态
这30s的收敛时间,交换机在侦听环路,侦听BPDU,学习MAC地址等,总的来说就是交换机检查下面的设备连接的是交换机还是PC
| 状态 | 描述 |
|---|---|
| Blocking | 只能接收BPDU,不能接收或者传输数据,不能把MAC地址加入地址表 |
| Listening | 可以接受和发送BPDU,不能接收或传输数据,不能把MAC地址加入地址表 |
| Learining | 可以发送和接收BPDU,可以学习MAC地址,不能传输数据 |
| Forwarding | 可以发送和接收数据,可以学习MAC地址,发送和接受BPDU |
一旦接受到DPDU优先级高的,比它更优的,他都会进入阻塞状态
端口角色
- 根端口(RP)
- 指派端口(DP)
- 非指派端口(NDP)
PVST
PVST(pre-vlan spanning-tree)基于每个vlan的生成树
思科交换机默认开启PVST状态,这个是思科私有的协议,基于每个VLAN生成一棵树,独立选择哪个口转发,哪个口阻塞,有效实现一个负载均衡的作用
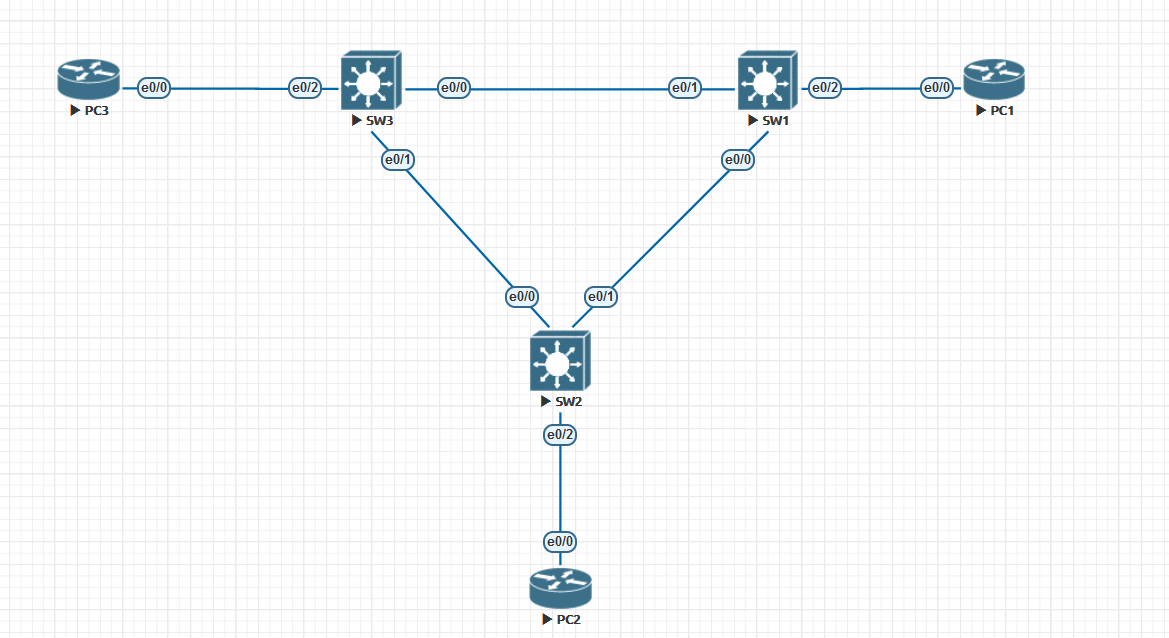
配置案例
VLAN1的生成树
交换机都运行PVST,整个拓扑线路带宽都是一样的,并在每个交换机创建vlan10 和vlan 20, 让PC2去往VLAN10的数据走SW2(e0/1)-SW1(e0/0),PC2去往VLAN20的数据走SW2(e0/0)-SW3(e0/1)来实现一个负载均衡
因为思科设备默认开启的就是基于PVST的生成树协议,所以不需要多做配置,只需要把连接交换机的端口打上trunk
查看生成树
//SW1
show spanning-tree
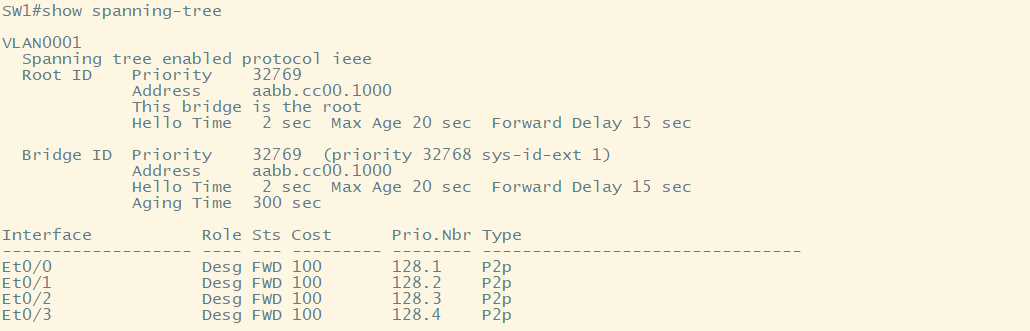
Bridge ID 表示网桥id的参数
Priority表示优先级,vlan1的桥ID优先级为32769是因为PVST的优先级累加会基于32768加上vlan编号,这边vlan编号为1,默认优先级为32768,两者加在一起就是32769
Address表示就是交换机的基MAC
Root ID表示的是根桥的参数,如果桥ID的参数和根桥ID的参数一样,证明我就是根桥,这边看出SW1就是根桥
查看交换机生成树使用的模式
//SW1
show spanning-tree summary
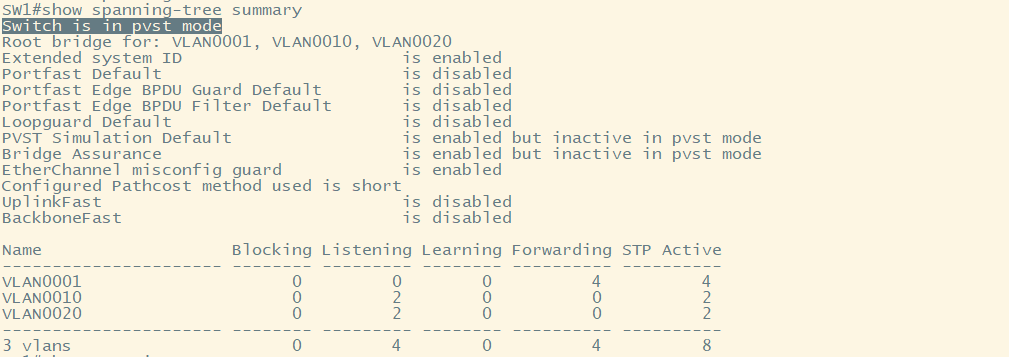
发现默认使用的是PVST协议
根据查看的消息我们绘制出每个交换机端口的角色

VLAN10,20的生成树
按道理来说,我们不应该看VLAN1的生成树,因为这是PVST,一个vlan一棵树,应该看VLAN10和VLAN20的生成树
//SW3
show spanning-tree

此时我们发现它们的阻塞通行的接口都和VLAN1的生成树相同,因为我们没有自己去手动配置它的参数
现在我们开始配置题目要求,我们需要修改让SW2的VLAN20的e0/1阻塞,e0/0口转发。要实现这个就需要让SW3作为VLAN20的根桥
VLAN20生成树的端口角色

en
conf ter
//把自己设置为首选根,但是show run查看时还是有一个优先级(24576),对比默认的32768优先
spanning-tree vlan 20 root primary
//把自己设置为备选根
spanning-tree vlan 20 secondary primary,但是show run查看时还是有一个优先级(28672)
//也可以手动配置优先级
spanning-tree vlan 20 priority 0
end
查看验证
//SW2
show spanning-tree
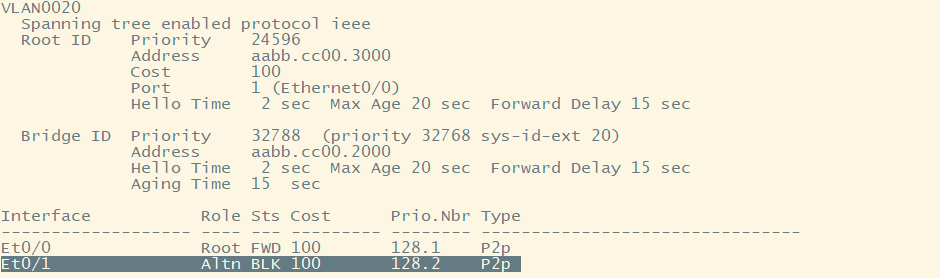
此时这种情况正好实现负载均衡,这个就是PVST核心的作用
扩展配置
除了上述我们修改设备优先级来进行选路负载均衡以外,我们还可以修改设备接口的cost值
在没有任何配置的情况下,阻塞的SW3的e0/1接口

此时我们只需要修改基于VLAN20生成树的SW2的e0/1接口cost改成>200,假设为201
en
conf ter
int e0/1
spanning-tree vlan 20 cost 201
end
//SW2
show spanning-tree

PVST+
PVST+(Per VLAN Spanning Tree Plus)增强型的按VLAN生成树
PVST+是在PVST的基础上增加扩展属性
PVST+增加的三大属性
Portfast功能
问题引入
Portfast称为快速端口,也叫做边缘端口,它能够跨过Listening到Forwarding状态的30s时间,直接进入到转发状态。不用让交换机继续去侦听,告诉交换机接入的就是PC,让接口不需要去收发BPDU,侦听BPDU
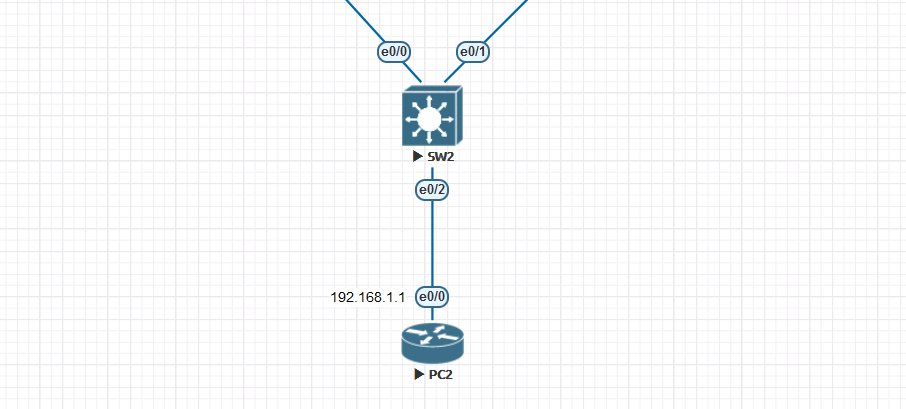
配置案例:把交换机SW2的e0/2接口配置为快速接口
关闭开启SW2的e0/2接口查看接口收敛的状态
功能引用
在实验的过程中,会发现交换机的e0/2接口收敛的速度很慢,这时我们开启快速端口
en
conf ter
int e0/2
spanning-tree portfast //配置为快速端口
end
`
//SW2
show spanning-tree

Edge:此时会发现配置之后的端口后面有个Edge的参数,这表示是边缘端口
配置完成之后我们再次把接口关闭开启,会发现e0/2接口瞬间切换成转发状态
在现时环境中,交换机连接PC的端口有很多,方便配置我们只需要添加一个default参数
en
conf ter
spanning-tree portfast default //交换机上所有的access接口都会变成快速端口,除了trunk接口以外
//另外一个版本命令
spanning-tree portfast edge default //交换机版本不一样,命名可能会有所差别
end
快速端口针对trunk接口是无法生效的,因为trunk口是连接交换机的,在工作岗位上,连接PC的接口都要设置为portfast,让其连接PC的接口不参与STP的运算当中
Uplinkfast功能
问题引入

此时PC3pingPC1去往的肯定是走的SW3(e0/0)-SW1(e0/1)这跳路,但是当我们把SW3的e0/0接口down掉之后,这时还是会等待30s之后PC3才能ping通PC1,相当于断网30s。当重新开启e0/0口的时候,还是会等待30s。只要发生了交换机和交换机的线路中断,至少会带来一分钟的等待时间
功能应用
如果要实现快速切换链路,需要在被阻塞的非根桥设备上开启这个功能。启动之后当我的根端口down掉了,会直接把被阻塞的端口变为Forwarding状态,而且就算原来的接口恢复了也不会等待30s
en
conf ter
spanning-tree uplinkfast
//关闭SW3的e0/0口
int e0/0
shutdown
end
//使用debug查看生成树的状态
debug spanning-tree events
看实验现象,确实是一瞬间转发的

总结:Uplinkfast的根本作用是帮助非根桥的设备(被阻塞的那台非根桥)实现一个根端口故障的快速切换(被阻塞的端口瞬间切换到转发状态)
注意:当设备开启uplinkfast之后默认使用计算cost值的标准是802.1T
Backbonefast功能
Backbonefast快速切换
BackboneFast是对UplinkFast的一种补充,UplinkFast能够检测直连链路的失效,BackboneFast是用来检测间接链路的失效。当启用了BackboneFast的交换机检测到间接链路失效之后,会马上使阻塞的端口进入监听状态,少了20S的老化时间。
问题引入
Uplinkfast运用的环境我们假设的是被阻塞的非根桥的设备(SW3),Backbonefast运用的环境我们要假设没有被阻塞的非根桥的设备(SW2)
如果SW2的e0/1口断了,那么SW2就收不到SW1发来的BPDU消息了,SW2就会开始发送自己的BPDU消息,SW3会同时收到来自SW1和SW2发来的BPDU消息,并且比较它俩发来的BPDU谁优先,对比完之后发现还是SW1的BPDU消息更加优先。SW3会等待20s的老化时间之后就会把自己阻塞的端口e0/1转换成转发状态,需要30s。但阻塞端口转换成转发状态之后,SW2就能通过SW2(e0/0)-SW3(e0/0)-SW1(e0/1)这条线路收到SW1发送来的BPDU消息了,所以一共需要50s的收敛时间
老化时间的解释:SW3原来是能通过SW3(e0/1)-SW2(e0/0)-SW1(e0/0)这条线路接收到SW1发来的BPDU消息的(阻塞端口只能监听BPDU,不能发送BPDU),现在当SW2的e0/1口断掉之后,只能从SW3(e0/0)-SW1(e0/1)这条链路收到SW1的BPDU了,此时SW3就会等待20s看看看SW1的BPDU消息还会不会发送过来,如果20s之后还没有接收到SW1从这个方向发来的BPDU,也就意味着这个接口真的收不到SW1的BPDU消息了(BPDU两秒发送一次)
功能应用
整个网路的每台设备都需要开启这个功能才会生效
启动了这个功能之后,当SW2的的e0/1口down掉了,SW3同时收到了来自SW1和SW2发来的BPDU消息时,此时SW3不会等待20s的老化时间,并且会给SW1发送一个消息,SW1收到消息会瞬间回复给SW3,让SW3不需要进行20s的老化时间,SW3直接让e0/1这个接口瞬间变成转发状态(但是端口状态转换的30s时间还是需要等待),因此节省了20s的时间
en
conf ter
spanning-tree backbonefast
end
总结:Backbonefast根本作用是帮助非根桥设备被阻塞的那台非根桥设备实现一个快速切换,节省老化时间。但是要求down掉的接口不是自己,而是另外一个没有被阻塞的非根桥的根端口
RSTP
RSTP(Rapid spanning tree protocol)快速生成树
RSTP使用的IEEE标准是802.1W,主要的优点就是速度快,但是只能作用于一颗生成树,不能做负载均衡
RSTP会运用设备内部的P/A运算机制(提议协议机制),实现一个交换机和交换机之间的接口快速实现进入forwarding状态
RSTP当中,连接PC的接口还是叫做边缘端口,依然需要配置成边缘端口(edge port),交换机和交换机之间的端口叫做非边缘端口(non-edge port)
非边缘端口有两种链路类型
-
Share类型:交换机和交换机之间连接了一个傻瓜交换机(例如Hub),就会协商成share模型。主要是根据接口双工状态来进行协商的,现在的设备都是全双工的状态,如果连接Hub就是半双工的状态
-
P2P类型:但是这个链路类型还是根据协商有关系(具体两台设备之间的协商数据),如果交换机还是连接的傻瓜交换机,本质上这个交换机接口还是会协商成全双工,如果协商成全双工默认就是P2P类型(点对点状态)
在点对点的环境下,才能够运行P/A机制运算机制
问题引入
当三个交换机打开之后,三个地方的PC不能马上相互之间发送数据。因为交换机启动会经过两个阶段,第二个阶段尤其消耗时间
- 选举根桥,非根桥,指派端口,根端口,非指派端口
- 当每个端口角色选举出来,端口会有一个收敛时间(端口的五个状态转换需要时间),尤其是当接口出现闪断的情况又要经过30s
之前学到的portfast边缘端口只能做在连接终端设备的接口,让边缘端口不再参与STP的运算当中,但是不能在连接交换机的接口上做portfast,于是就有了RSTP
RSTP的端口状态和端口角色
端口状态
RSTP中把原来的五个接口状态浓缩成了三个接口状态,但是端口从Blocking状态切换到Forwarding还是需要30s的时间
注意:在思科设备上依然看到的是Blocking状态,但是在华为设备中看到的是Discarding状态
| 状态 | 描述 |
|---|---|
| Blocking/Discarding | 丢弃状态 |
| Learining | 学习状态 |
| Forwarding | 转发状态 |
端口角色
- 根端口(RP)
- 指派端口(DP)
- 替代端口(AP)也相当于传统STP的非指派端口
- 备份端口(BP)默认是Discarding状态的
介绍备份端口
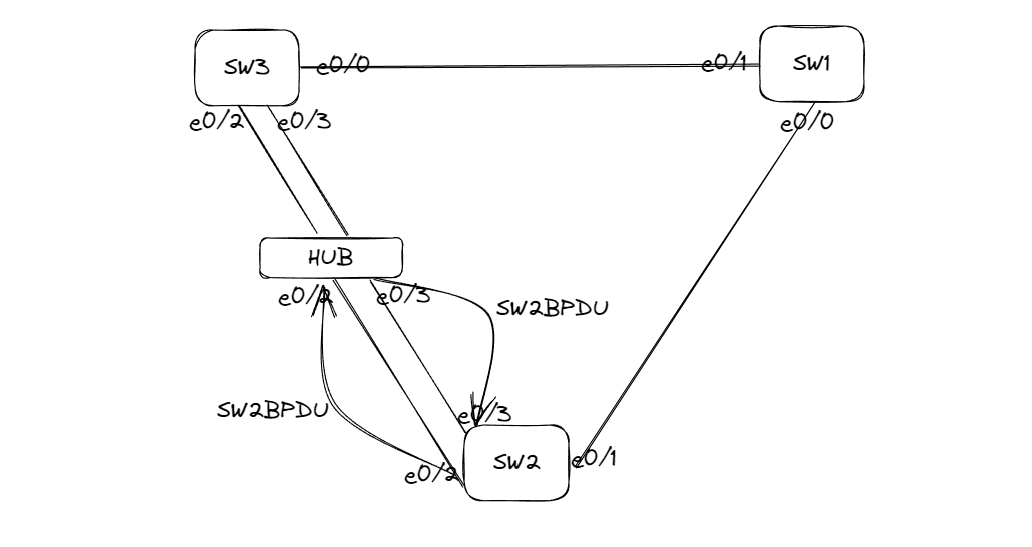
在交换机最开始的阶段,每台交换机都给给相邻的设备发送BPDU,SW2从e0/2接口发送BPDU到HUB,HUB会进行泛洪从e0/3接口又把SW2的BPDU发送到SW2的e0/3接口,SW2此时就检查到当前的网络环境下有环路,此时SW2会把e0/3接口作为备份接口(BP),一旦SW2的e0/2接口down掉了,e0/3接口就回来接替它,但是这个过程不是瞬间切换,中间的过程需要50s的时间(20sBPDU老化时间+30s接口转换成Forwarding的时间),因为这个链路类型为shar类型,不会运行P/A机制
但是如果SW2和SW3之间没有连接HUB,链路类型就是P2P类型,那么SW2的e0/2和e0/3接口角色都是替换接口(AP)
功能应用
RSPT自带Uplinkfast和backbonefast功能,RSTP从逻辑来看不是这么说,但功能基本一致
比如说当SW3的e0/0接口down掉了,按理来说e0/1接口从Blocking变为Forwarding状态需要30s。但是RSTP可以实现接口定向一对一的备份,也就是说当SW3的根端口e0/0断掉了,我可以针对SW3的Discarding e0/1接口直接以面向SW3的根端口e0/0实现一个一对一的保障备份关系,这是自动实现的。等于当SW3的e0/0口断了,SW3的e0/1接口瞬间从Discarding变为Forwarding状态(1s),这个功能相当于uplinkfast的功能,只不过是RSTP对这个功能做了一个集成化,实现了一个备份功能
rapid-pvst
rapid-pvst(支持VLAN的快速生成树)
思科私有的协议,在RSTP的基础上弥补了不能支持多生成树的缺点
问题引入
RSTP并没有被广泛的使用,早期的思科设备默认生成树是PVST,现在近期的思科默认生成树是RSTP(但是并不是标准的RSTP而是rapid-pvst)
en
conf ter
spanning-tree mode rapid-pvst
end
//SW
show spanning-tree summary
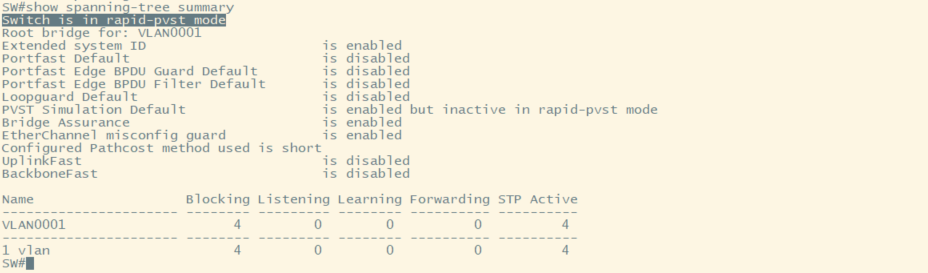
show spanning-tree

此时我们发现虽然使用的rapid-pvst,但是显示的却是rstp
思科的rapid-pvst就是混改版本的RSTP,它既支持PVST,支持RSTP。基于RSTP一颗生成树的缺陷加入PVST做基于VLAN的负载均衡,也支持RSTP的快速收敛情况下+负载均衡
功能应用
更改端口在生成树下的类型,交换机之间会自动协商
en
conf ter
int e0/0
spanning-tree link-typ point-to-point
end
rapid-pvst配置基于每个vlan的生成树的命令和PVST的配置命令都是一致的,配置边缘端口的命令也一样
MSTP
MSTP(Multiple Spanning Tree Algorithm and Protocol)多实例生成树
MSTP的根本内部机制原理可以完全等同于RSTP,MSTP就是RSTP的升级版本,这个是公有协议。MSTP理解成RSTP混改版本(MSTP同样也支持在快速收敛的情况下,也同时支持负载均衡)
MSTP是基于PVST的基础上演变过来的,华为交换机默认是mstp状态。它也是有RSTP的P/A机制,端口状态也和RSTP一样。依然是自带uplinkfast和backbonefast
问题引入
MSTP的诞生,首先是看到RSTP的P/A机制很快,也可以使用边缘端口。但是针对于rapid-pvst基于的是每个vlan,每个vlan一棵树,但是当有一条线路出现故障线路切换的时候,基于每个vlan都得重新计算一次引起了大范围的计算,这样消耗了设备的硬件资源
MSTP多实例生成树,是直接建立实例(模板),可以提前把不同的vlan放入到不同的模板内,例如假设有10个vlan
- 模板1命名为cisco,里面包含了VLAN 1 2 3 4 5,假设模板1的e0/1口forwarding,e0/2口Discarding
- 模板2命名为huawei,里面包含了VLAN 6 7 8 9 10,假设模板2的e0/1Discarding,e0/2口forwarding
实现一个基于模板化的负载均衡,当出现了接口链路故障,只需要计算单独计算模板即可,而不需要单独的计算每个vlan,从而减少了硬件的资源消耗
但是这个基于vlan的生成树和基于实例的生成树基本上没啥区别,vlan一般用在企业网里面,企业网最多100多个vlan不可能计算不过来的,这种方法跟BGP里面的对等体组差不多,没有什么新的特性属于是硬抄
功能应用
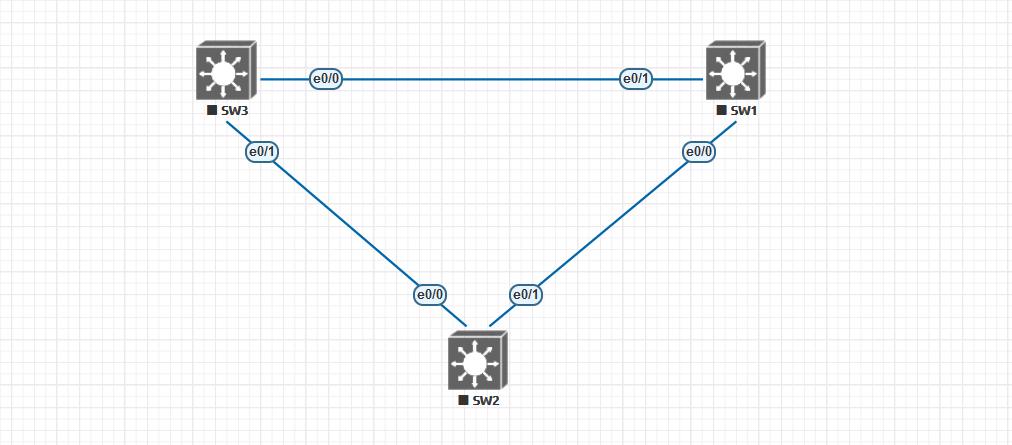
配置案例
开启三台交换机配置mstp并创建vlan10 vlan20,默认SW1为根桥
en
conf ter
vlan 10
vlan 20
exit
spanning-tree mode mst //启用mstp
end
查看使用的生成树
//SW1
show spanning-tree summary

//SW1
show spanning-tree

虽然我们创建了很多vlan,但是瞬间变成了一棵树
MST0表示是实例0,它是MSTP默认的一颗树,系统自带的并且所有的vlan默认都在实例0里面
配置多实例,针对vlan10和vlan20各一颗树
en
conf ter
spanning-tree mst configuration //进入MSTP的配置模板
name CCIE //创建MSTP的域表示符(MSTP的标识),也可以理解为自治系统号,如果想要多台设备在一个域内跑mst,这个名字必须是一样的才行,每个设备都得配置
revision 1 //配置版本修订号(默认为0,范围0-65535),不同厂商的设备revision有可能不相同,必须要相同
//把VLAN10加入到实例1里面,VLAN20加入到实例2里面
instance 1 vlan 10 //定义实例,实例0也可以修改但是一般不修改,一般从1开始
instance 2 vlan 20
end
查看实例1
//SW1
show spanning-tree mst 1

此时发现vlan10确实在实例1里面,cost值这么大是因为运用的是802.1T的标注,但是比较的规则还是一样的,只是默认的接口带宽对应的cost值不一样而已
现在我们只是创建了实例,把vlan添加到了实例里面并没有做多余的配置,所以他们运用的都是同一颗树,通过查看发现都是阻塞的SW3的e0/1接口
现在我们配置负载均衡,把SW2作为实例2的根桥
en
conf ter
spanning-tree mst 2 root primary
end
//SW3
show spanning-tree mst 1
show spanning-tree mst 1

此时发现针对实例1阻塞的是SW3的e0/1接口,实例2阻塞的是SW3的e0/0接口,vlan10走e0/0口,vlan20走e0/1口,实现了负载均衡
当然也可以修改接口的cost来改变根端口来实现链路的负载均衡
en
conf ter
int e0/1
spanning-tree mst 2 cost 4000001
end
//SW3
show spanning-tree mst 2

此时基于实例1来说阻塞的SW3的e0/1接口,基于实例2来说阻塞的SW3的e0/0接口,实现的负载均衡
生成树总结
现在主流环境下:思科(Rapid-pvst),华为(MST),RSTP是垫背的,PVST早期思科默认使用(现在思科使用的Rapid-pvst会与它兼容),思科华为重组Rapid-pvst和VBST默认结合
现在实际环境中:企业网最多两个交换机(没有涉及分层)之间连接很多根线路,使用EC聚合来代替STP;企业网如果有分层,那么就聚合+堆叠来代替STP

















 2408
2408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











