






一、目标
理解 RDD 的算子分类, 以及其特性
理解常见算子的使用
二、分类
RDD 中的算子从功能上分为两大类
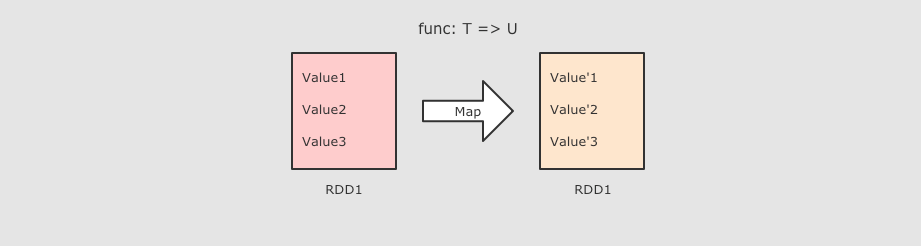
Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
针对基础类型(例如 String)处理的普通算子
针对
Key-Value数据处理的byKey算子针对数字类型数据处理的计算算子
三、特点
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
四、常见的Transformations 算子
| Transformation function | 解释 |
|---|---|
|
|
作用
签名
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
|
|
| RDD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换 |
|
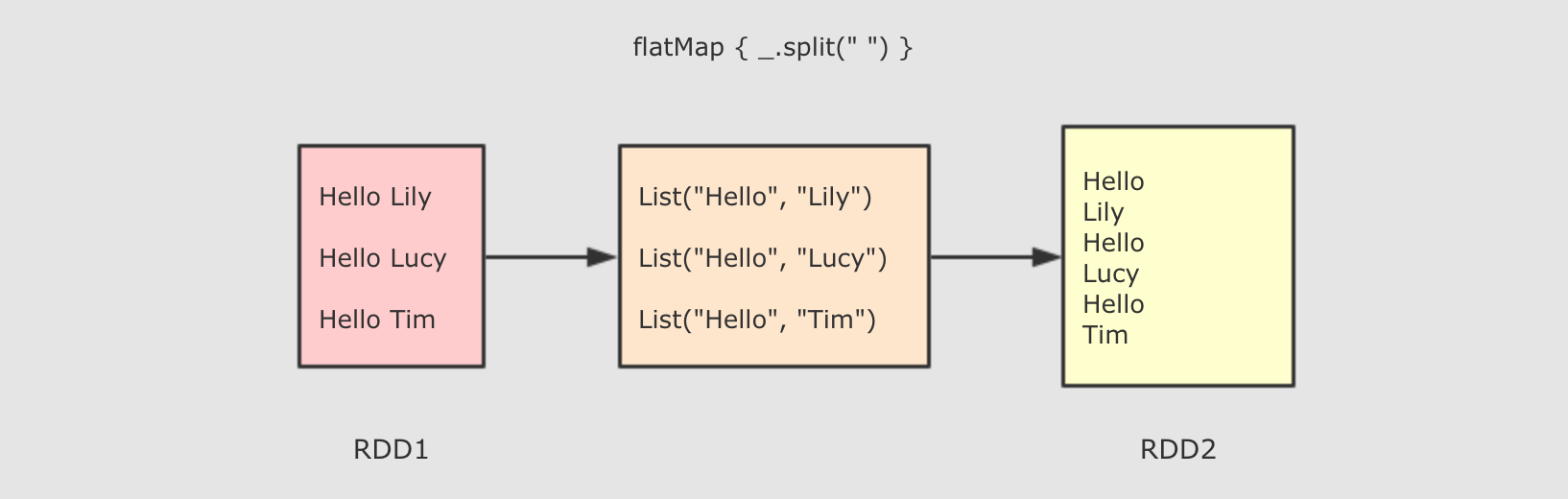
| 和 mapPartitions 类似, 只是在函数中增加了分区的 Index |
|
|
作用
|
|
|
作用
参数
|
|
|
|
|
|
作用
|
|
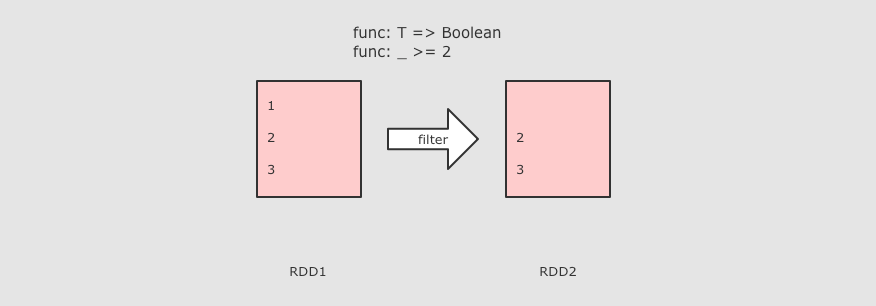
| (RDD[T], RDD[T]) ⇒ RDD[T] 差集, 可以设置分区数 |
|
|
作用
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
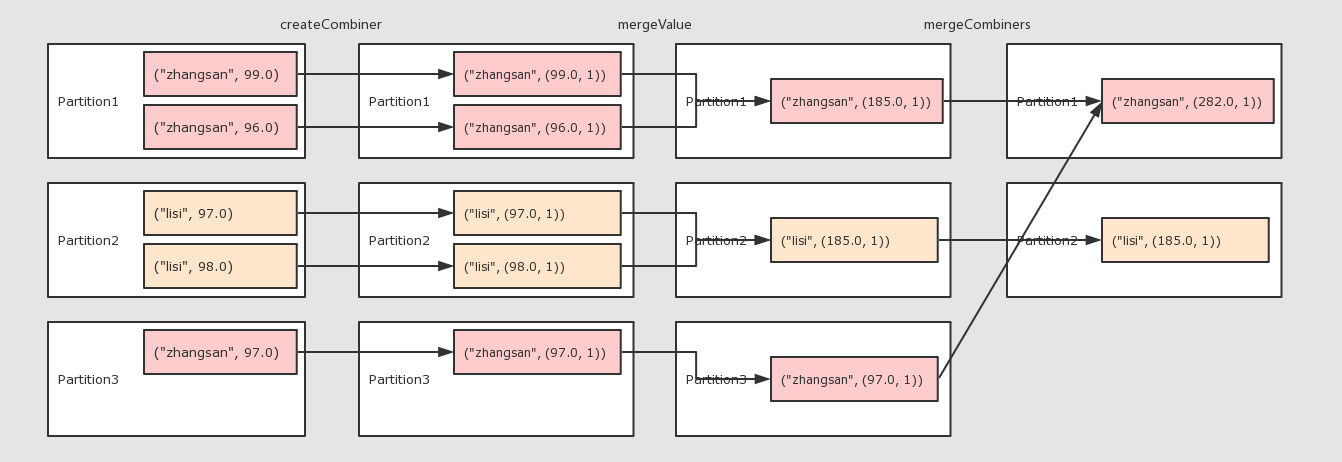
注意点 * 为什么需要两个函数? aggregateByKey 运行将一个
|
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
| (RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成两个 RDD 的笛卡尔积 |
|
| 作用
调用
参数
注意点
|
|
| 使用用传入的 partitioner 重新分区, 如果和当前分区函数相同, 则忽略操作 |
|
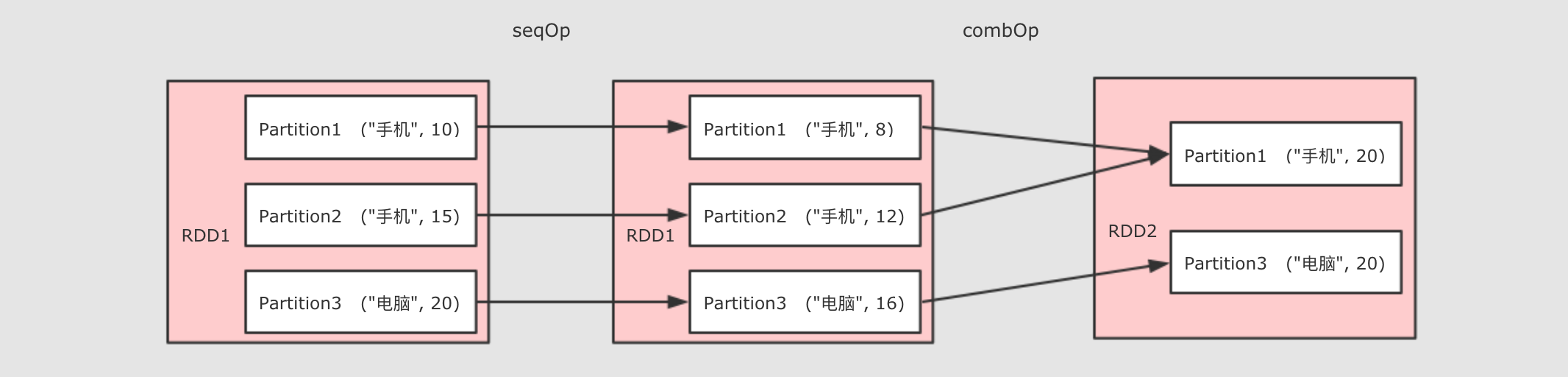
| 减少分区数 作用
调用
参数
注意点
|
|
| 重新分区 |
|
| 重新分区的同时升序排序, 在 |





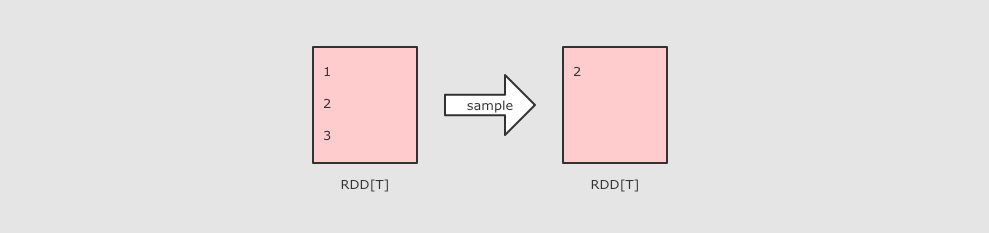

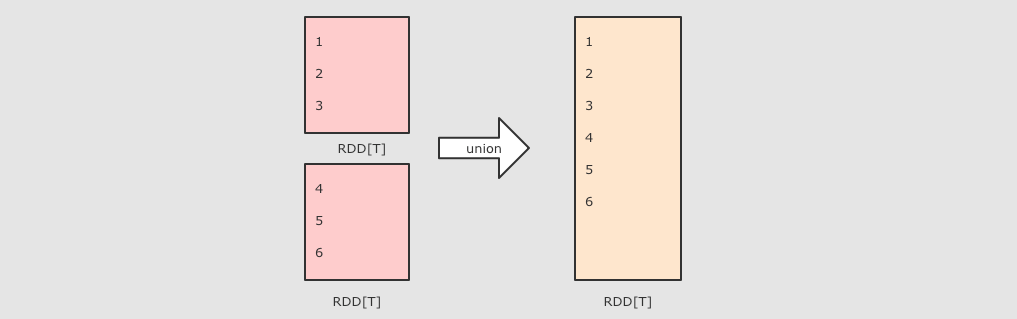
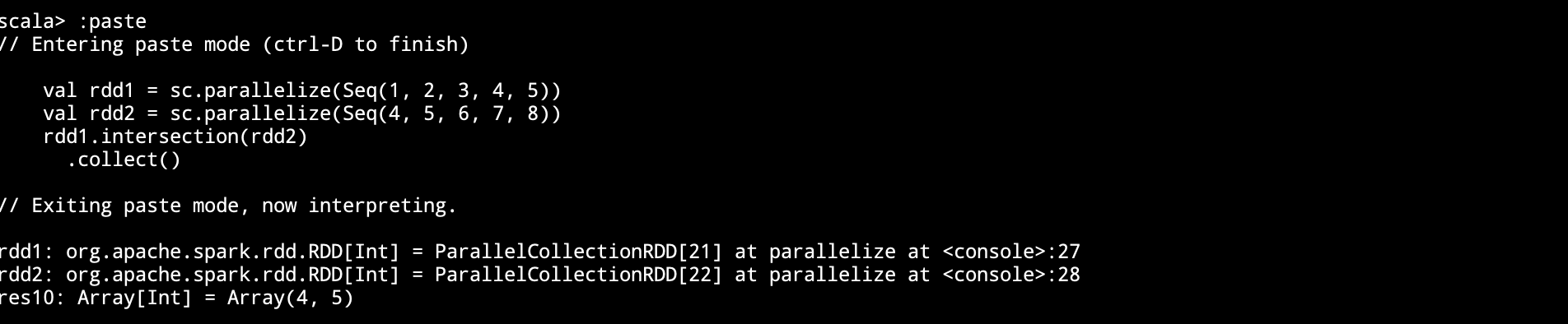
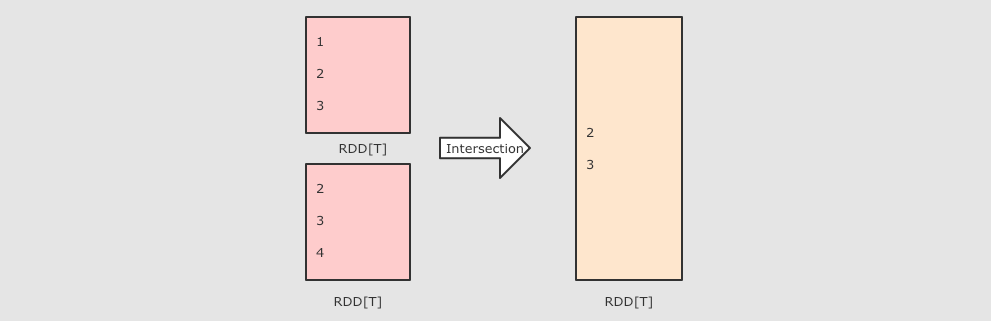





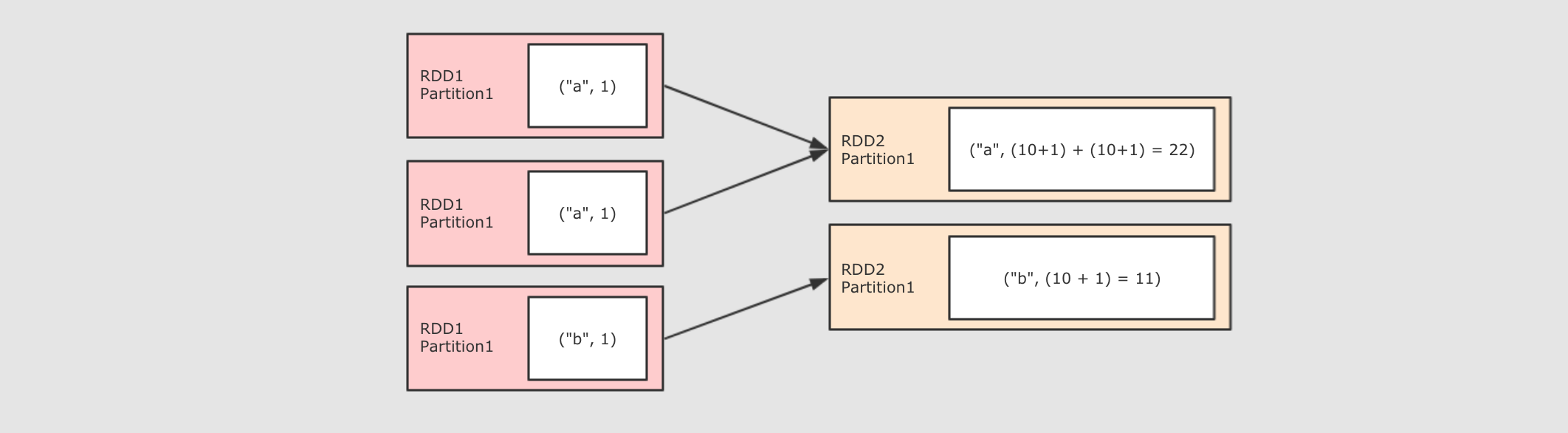
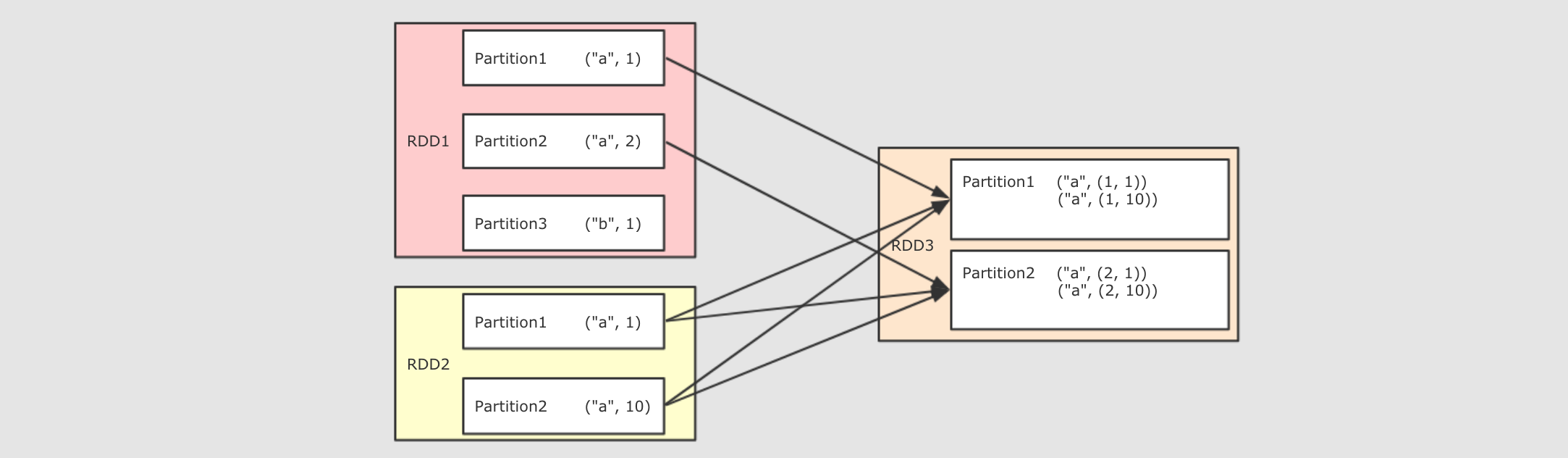
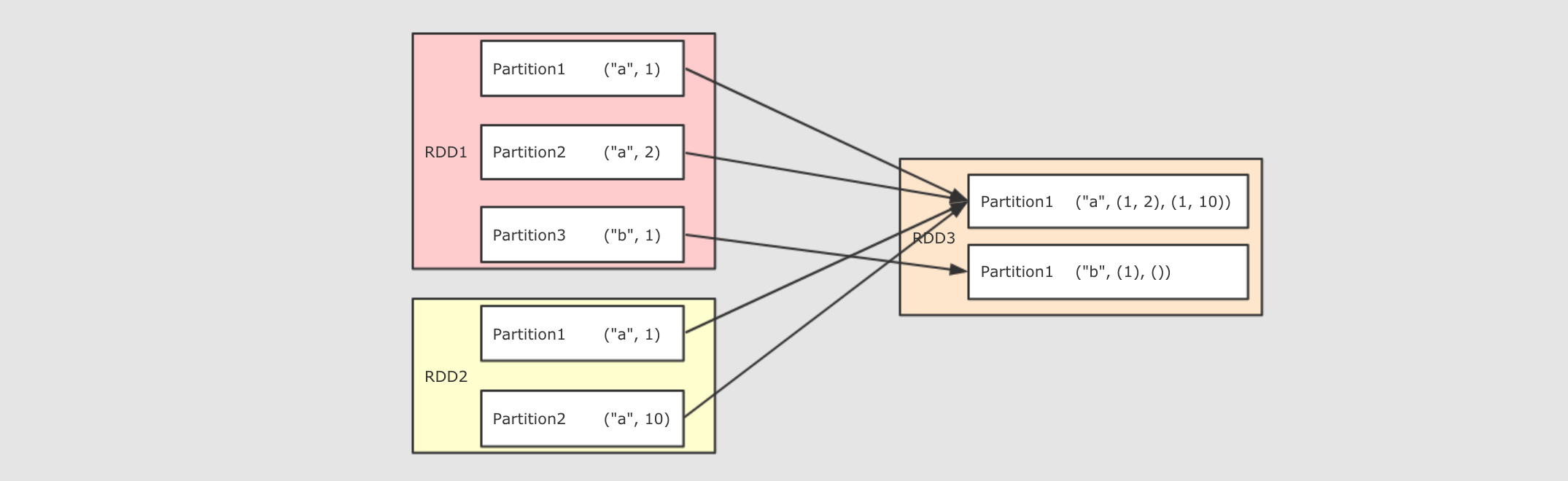
五、常用Action算子
| Action function | 解释 |
|---|---|
|
| 作用
调用
注意点
|
|
| 以数组的形式返回数据集中所有元素 |
|
| 返回元素个数 |
|
| 返回第一个元素 |
|
| 返回前 N 个元素 |
|
| 类似于 sample, 区别在这是一个Action, 直接返回结果 |
|
| 指定初始值和计算函数, 折叠聚合整个数据集 |
|
| 将结果存入 path 对应的文件中 |
|
| 将结果存入 path 对应的 Sequence 文件中 |
|
| 作用
注意点
|
|
| 遍历每一个元素 |
应用
```scala
val rdd = sc.parallelize(Seq(("手机", 10.0), ("手机", 15.0), ("电脑", 20.0)))
// 结果: Array((手机,10.0), (手机,15.0), (电脑,20.0))
println(rdd.collect())
// 结果: Array((手机,10.0), (手机,15.0))
println(rdd.take(2))
// 结果: (手机,10.0)
println(rdd.first())
```总结
RDD 的算子大部分都会生成一些专用的 RDD
map,flatMap,filter等算子会生成MapPartitionsRDD
coalesce,repartition等算子会生成CoalescedRDD
常见的 RDD 有两种类型
转换型的 RDD, Transformation
动作型的 RDD, Action
常见的 Transformation 类型的 RDD
map
flatMap
filter
groupBy
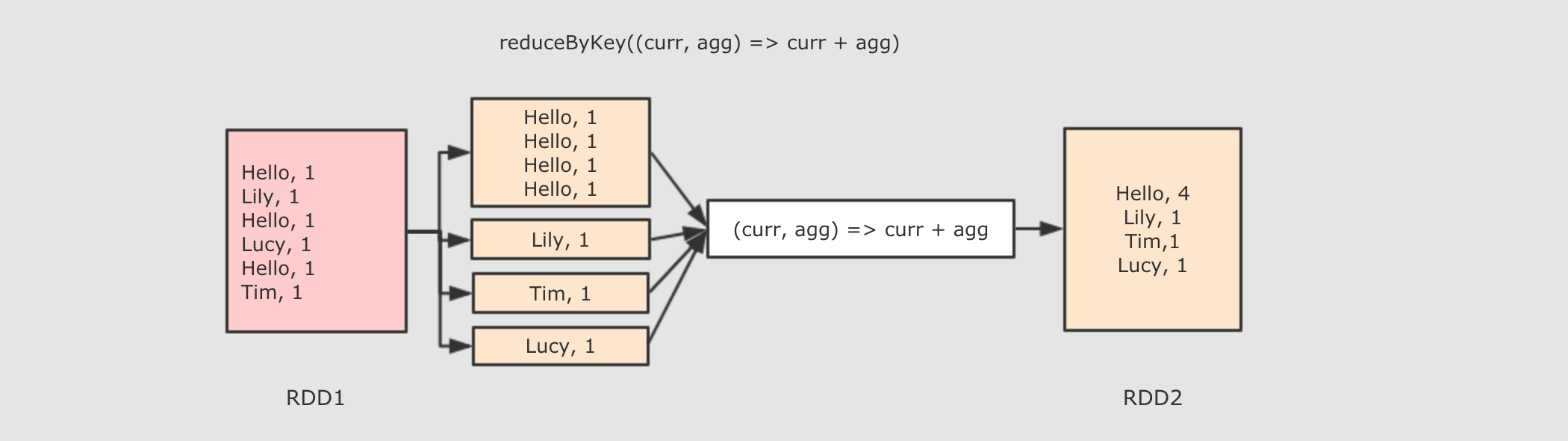
reduceByKey
常见的 Action 类型的 RDD
collect
countByKey
reduce
六、RDD 对不同类型数据的支持
目标
理解 RDD 对 Key-Value 类型的数据是有专门支持的
理解 RDD 对数字类型也有专门的支持
一般情况下 RDD 要处理的数据有三类
字符串
键值对
数字型
RDD 的算子设计对这三类不同的数据分别都有支持
对于以字符串为代表的基本数据类型是比较基础的一些的操作, 诸如 map, flatMap, filter 等基础的算子
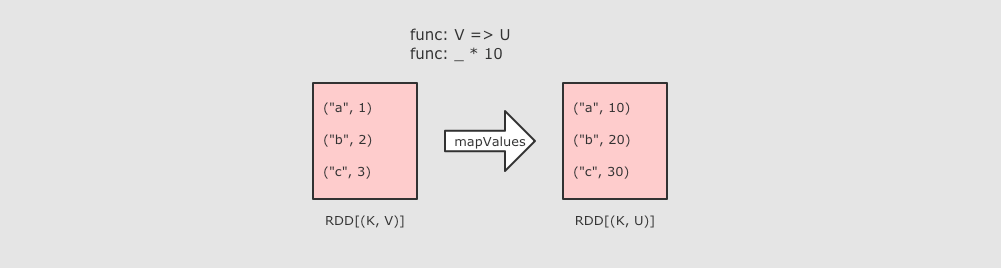
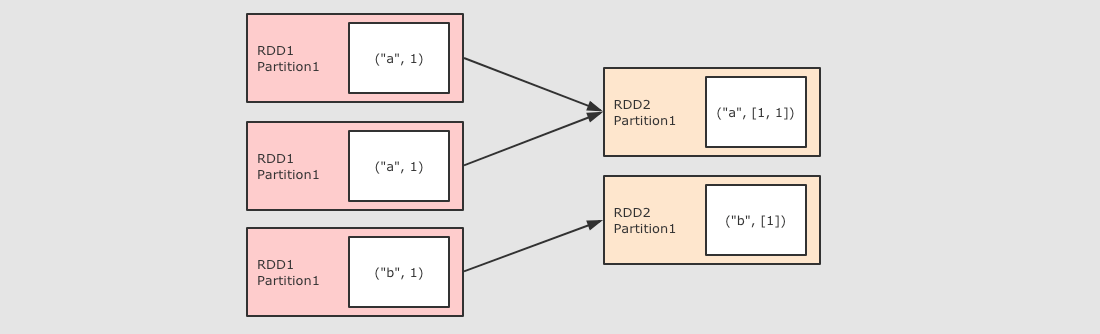
对于键值对类型的数据, 有额外的支持, 诸如 reduceByKey, groupByKey 等 byKey 的算子
同样对于数字型的数据也有额外的支持, 诸如 max, min 等
RDD 对键值对数据的额外支持
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为 RDD[(K, V)]
RDD 对键值对的额外支持是通过隐式支持来完成的, 一个 RDD[(K, V)], 可以被隐式转换为一个 PairRDDFunctions 对象, 从而调用其中的方法.

既然对键值对的支持是通过 PairRDDFunctions 提供的, 那么从 PairRDDFunctions 中就可以看到这些支持有什么
| 类别 | 算子 |
|---|---|
| 聚合操作 |
|
|
| |
|
| |
| 分组操作 |
|
|
| |
| 连接操作 |
|
|
| |
|
| |
| 排序操作 |
|
|
| |
| Action |
|
|
| |
|
|
RDD 对数字型数据的额外支持
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作
| 算子 | 含义 |
|---|---|
|
| 个数 |
|
| 均值 |
|
| 求和 |
|
| 最大值 |
|
| 最小值 |
|
| 方差 |
|
| 从采样中计算方差 |
|
| 标准差 |
|
| 采样的标准差 |
val rdd = sc.parallelize(Seq(1, 2, 3))
// 结果: 3
println(rdd.max())七、阶段练习和总结
导读
-
通过本节, 希望大家能够理解 RDD 的一般使用步骤
// 1. 创建 SparkContext
// 创建一个 SparkConf 对象,并设置主节点为本地模式,使用 6 个核心,应用名称为 "stage_practice1"
val conf = new SparkConf().setMaster("local[6]").setAppName("stage_practice1")
// 使用创建的 SparkConf 对象创建 SparkContext
val sc = new SparkContext(conf)
// 2. 创建 RDD
// 从指定的文件路径读取数据创建一个文本类型的 RDD
val rdd1 = sc.textFile("dataset/BeijingPM20100101_20151231_noheader.csv")
// 3. 处理 RDD
// 对 rdd1 中的每个元素进行处理,将其按逗号分割,然后构建键值对
val rdd2 = rdd1.map { item =>
val fields = item.split(",")
((fields(1), fields(2)), fields(6))
}
// 过滤出值不为 "NA" 的键值对
val rdd3 = rdd2.filter { item =>!item._2.equalsIgnoreCase("NA") }
// 将值转换为整数类型
val rdd4 = rdd3.map { item => (item._1, item._2.toInt) }
// 按照键进行规约,将相同键的值相加
val rdd5 = rdd4.reduceByKey { (curr, agg) => curr + agg }
// 按照键降序排序
val rdd6 = rdd5.sortByKey(ascending = false)
// 4. 行动, 得到结果
// 打印出排序后的第一个元素
println(rdd6.first()) 通过上述代码可以看到, 其实 RDD 的整体使用步骤如下
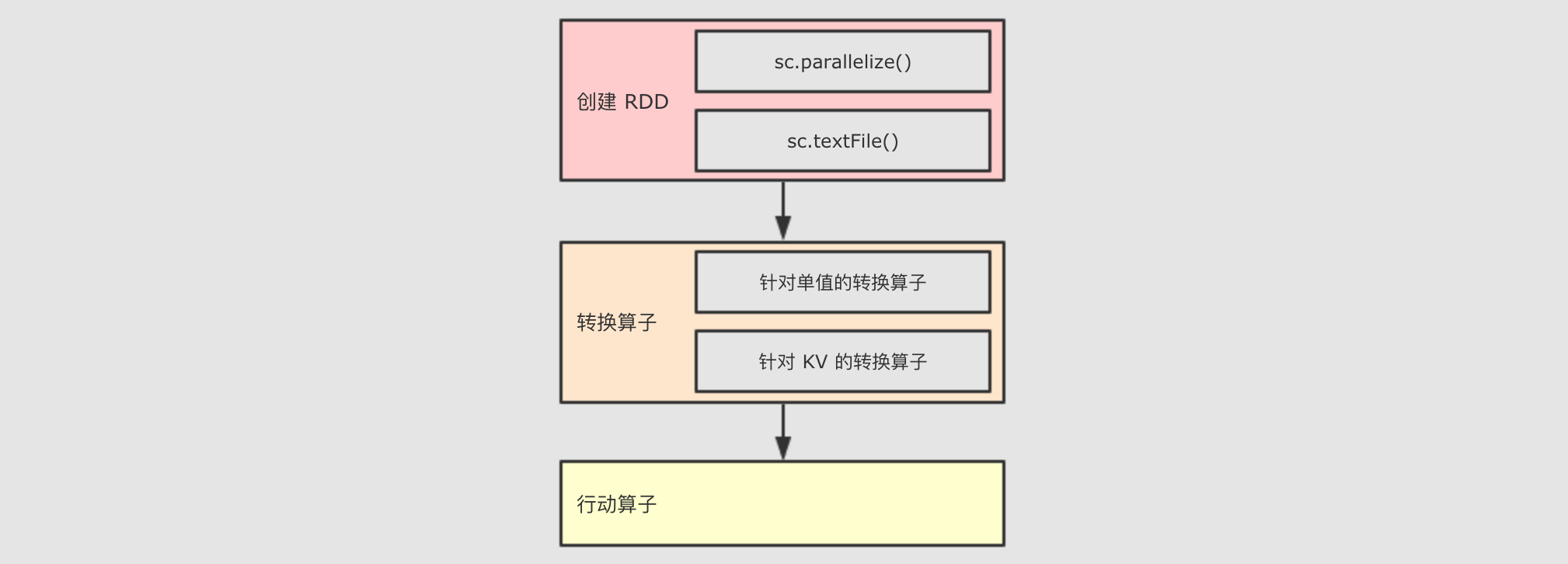















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









