







8.1 数学函数
exp() #e为底的指数函数
log() #e为底的对数函数
log10() #以10为底的对数函数
sqrt() #平方根
abs() #绝对值
sin(), cos()等 #三角函数
min(), max() #向量的最(小)大值
which.min(), which.max() #返回一个向量中最小(大)元素的位置索引
pmin(), pmax() #多个等长度的向量按元素逐个对比,返回所有向量的第k元素中最小(大)的值
sum(), prod() #向量所有元素累积求和(求积)
cumsum(), cumprod() #向量前k的元素累积求和(求积)
round(), floor(), ceiling() #四舍五入取整,向下取整,向上取整
factorial() #阶乘
8.1.1 计算概率
(1)prod()连乘函数
设有n个独立事件,其中第i个事件的发生概率为 p ,恰好有一个事件发生的概率则为:

#可用连乘函数prod()计算此概率值:
exactlyone <- function(p){ #p为第i个元素为p_i的向量
notp <- 1-p
tot <- 0.0
for(i in 1:length(p))
tot <- tot +p[i] * prod(notp[-i])
return(tot)}
exactlyone(c(0.1,0.2,0.3))注意P是一个 所有的参数在一起,输入的是一个向量。
8.1.2 累积和与累积乘积
x <- c(12,5,13)
cumsum(x) #累积和
cumprod(x) #累积乘
8.1.3 最小值和最大值
min() : 把所有元素组成一个向量,返回最小值
pmin() :把多个向量的元素按照位置进行对应比较,返回每个位置的最小值
z <- matrix(c(1,5,6,2,3,2),3,2)
min(z[,1],z[,2])
pmin(z[,1],z[,2])
pmin(z[`,],z[2,],z[3,])
案例:用nlm()和optim()求函数的最小值
nlm(function(x) return(x^2-sin(x)),8) #用牛顿法求解最小值
optim(1,function(x) return(x^2-sin(x)),method = "CG") #用CG方法求解最优值
8.1.4 微积分
求导和数值积分
D(expression(exp(x^2)),"x") #求导
integrate(function(x) x^2,0,1) #数值积分
8.2 统计分布函数
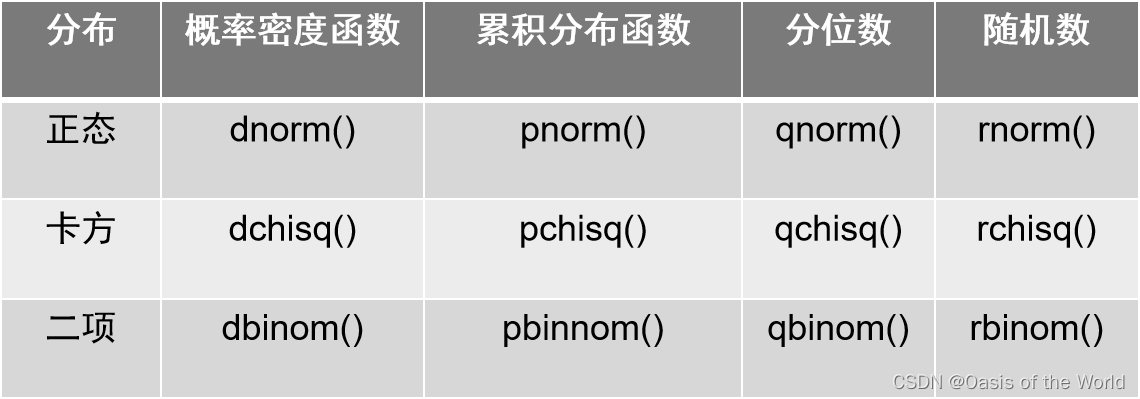
mean(rchisq(1000,df=2)) #生成1000个服从卡方分布的随机数,df为自由度,并求均值
qchisq(0.95,2) #求自由度为2的卡方分布的0.95分位数
概率密度函数、累积分布函数、分位数的第一个参数都可以是向量,故可以批量进行求值。
8.3 排序
8.3.1 sort()排序,order()返回索引
x <- c(13,5,12,5)
sort(x) #对x进行排序
x
order(x) #返回排序后的顺序在原向量中的索引
8.3.2 数据框中按照特定列进行排序
y <- data.frame(V1 = c("def","ab","zzzz"),V2 = c(2,5,1))
r <- order(y$V2)
print(r)
z <- y[r,] #对数据框y按照列V2进行排序,将对应行的一个一个拿出来,r相当于是一个向量
z
z<- y[c(1,2),]
z8.4 向量和矩阵的线性代数运算
y <- c(1,3,4,10)
2*y #向量的数乘
crossprod(1:3,c(5,12,13)) #计算向量的内积
a <- matrix(c(1,3,2,4),2)
b <- matrix(c(1,0,-1,1),2)
a %*% b #计算矩阵的积
a <- matrix(c(1,-1,1,1),2)
b <- c(2,4)
solve(a,b) #求解线性方程组 a*x = b
solve(a) #计算矩阵a的逆
其他常用函数:t(), qr(), chol(), det(), eigen()
m <- matrix(c(1,7,2,8),2)
dm <- diag(m) #提取对角阵,存储为向量
diag(dm) #将向量转化为对角阵
diag(3) #输入向量长度为1,创建大小为3的单位阵8.4.1 向量的外积
外积:的意思是 求出与输入的两个向量垂直的向量

#可以通过计算矩阵的子行列式得到:
xprod <- function(x,y){
m <- rbind(rep(NA,3),x,y)
xp <- vector(length=3)
for (i in 1:3)
xp[i] <- -(-1)^i*det(m[2:3,-i])
return(xp)
}
8.4.2 计算马尔科夫链的平稳分布
8.6 用R进行模拟
掷硬币游戏:连续三次为正则赢。
状态:每个时间点连续掷出正面的次数,即0,1,2三种(等于三则归零)
关注的问题:长期状态下赢的比例,也就是问题的平稳状态分布 问题可转化为求解方程组:
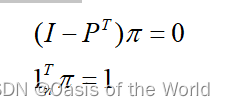
findpi1 <- function(p){
n <- nrow(p)
imp <- diag(n)- t(p) #
imp[n,] <-rep(1,n)
rhs <- c(rep(0,n-1),1)
pivec <- solve(imp,rhs)
return(pivec)
}
p <- matrix(c(.5,.5,1,.5,0,0,0,.5,0),3)
findpi1(p)
findpi2 <- function(p){
n <- nrow(p)
pivec <- eigen(t(p))$vectors[,1]
if (pivec[1]<0) pivec <- -pivec
pivec <- pivec/sum(pivec)
return(pivec)
}
p <- matrix(c(.5,.5,1,.5,0,0,0,.5,0),3)
findpi1(p)
8.5 集合运算
union(x,y) #集合x和y的并
intersect(x,y) #交集
setdiff(x,y) #差集(属于x但不属于y的元素构成的集合)
setequal(x,y) #判断集合是否相等
c %in% y #判断c是否属于y
choose(n,k) #从含有n个元素集合中选取k个元素的子集的数目案例1:计算两个集合的对称差
symdiff <- function(x,y){
sdfxy <- setdiff(x,y)
sdfyx <- setdiff(y,x)
return(union(sdfxy,sdfyx))}
symdiff(x,y)
案例2:用二元运算符判断一个集合是否是另一个集合的子集
"%subsetof%" <- function(u,v){
return(setequal(intersect(u,v),u))}
c(3,8) %subsetof% 1:10
c(3,8) %subsetof% 5:10
案例3: combn():生成集合元素的子集
c32 <- combn(1:3,2) #生成{1,2,3}的所有含有2个元素的子集
class(c32)
combn(1:3,2,sum) #生成所有子集后再分别进行求和8.6 数值模拟
rnorm() #正态分布
rexp() #指数分布
runif() #均匀分布
rgamma() #伽马分布
rpois() #泊松分布
8.6.1 随机变量发生器
概率模拟:
x <- rbinom(10,5,0.5)
print(x)
mean(x>=4)期望估计:
求解两个服从标准正态分布的两个变量X和Y的最大值的期望值
sum <- 0
nreps <- 100
for (i in 1:nreps){
xy <- rnorm(2)
sum <- sum+max(xy)
}
print(sum/nreps)生成100对服从标准正态分布,找到每一对的最大值,然后求均值最后就会得到平均值。
因为这个代码里有一个循环,所以效率比较低,可以进行简化:
8.6.2 重复运行时获得相同的随机数流
R程序中随机数生成器是使用32位的整型变量作为种子,相同的初始种子生成的随机数流也是相同的。在程序调试时经常需要每次生词的随机数流是相同的,可通过以下调用实现:
set.seed(8888)
rnorm(3)
set.seed(8888)
rnorm(3)
8.6.3 组合的模拟
从20个人中选出人数为3、4、5的三个委员会。A和B被选入同一个委员会的概率为多大?(每个人只能被选入一个委员会)
方法:将选举的过程重复多次,统计AB出现在同一委员会的选举结果的次数(用频率近似概率)
choosecomm <- function(comdat,comsize){
commitee <- sample(comdat$whosleft,comsize)
comdat$numabchosen <- length(intersect(1:2,commitee)) #和AB这个集合做交集后取长度!
if (comdat$numabchosen == 2)
comdat$countabsamecomm <- comdat$countabsamecomm +1
comdat$whosleft <- setdiff(comdat$whosleft,commitee)
return(comdat)
}
sim(1000)
sample函数:
sample(抽样的集合,抽样的次数),默认是无放回的抽样。
sim <- function(nreps){
commdata <- list() #存储三个委员会的所有信息
commdata$countabsamecomm <- 0
for (rep in 1:nreps){
commdata$whosleft <- 1:20 #还剩下哪些人员可供选择
commdata$numabchosen <- 0 #A,B目前被选择的次数
commdata <- choosecomm(commdata,5) #选出委员会1,判断A,B是否都被选中
#若AB都被选中,则不再需要判断其他委员会
if (commdata$numabchosen>0) next#选出委员会2,判断A,B是否都被选中
commdata <- choosecomm(commdata,4)
if (commdata$numabchosen>0) next #选出委员会3,判断A,B是否都被选中
commdata <- choosecomm(commdata,3)}
print(commdata$countabsamecomm/nreps)}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









