






 本文介绍了如何在PyTorch框架下构建一个卷积神经网络模型,对MNIST数据集进行手写数字识别,实验结果显示模型具有高精度,验证了其在实际应用中的可行性。
本文介绍了如何在PyTorch框架下构建一个卷积神经网络模型,对MNIST数据集进行手写数字识别,实验结果显示模型具有高精度,验证了其在实际应用中的可行性。
1. 简介
手写数字识别是计算机视觉领域的经典问题之一。MNIST 数据集是一个包含了 0 到 9 的手写数字图片的数据集,每张图片大小为 28x28 像素。本实验旨在使用 PyTorch 框架搭建神经网络模型,对 MNIST 数据集进行训练,并评估模型的性能。
2. 实验步骤
2.1 数据集加载
在加载之前需确保已经安装好各种库
import torch
import torchvision
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import warnings
warnings.filterwarnings('ignore')
# 判断是否有可用的 GPU,选择运行设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 下载训练集和测试集,并将数据转换为张量形式
dataset_train = torchvision.datasets.MNIST(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataset_test = torchvision.datasets.MNIST(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=False)
# 创建训练集和测试集的 DataLoader 对象,用于批次加载数据
data_loader_train = torch.utils.data.DataLoader(dataset=dataset_train, batch_size=100, shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=100, shuffle=False)
2.2 搭建神经网络模型
包含两个卷积层两个池化层以及三个全连接层
from torch import nn
class CNN(nn.Module):#定义卷积神经网络
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(#卷积
nn.Conv2d(1, 25, kernel_size=3),#输入通道,输出通道,卷积核
nn.BatchNorm2d(25),#参数为输出通道数
nn.ReLU(inplace=True)#线性整流
)
self.layer2 = nn.Sequential(#池化
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(#卷积
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(#池化
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(50 * 5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
2.3 训练模型与模型评估
#模型训练,作用为下载MNIST数据集(放入同目录下的data文件夹),使用数据集训练网络并将训练好的模型保存为同目录下的CNN_for_MNIST.pth
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import cv2
import cnn
batch_size = 64 #分批参数
learning_rate = 0.02 #学习率
# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
# transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
# transforms.Compose()函数将各种预处理的操作组合到了一起
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 数据集的下载器,下载数据集放入data文件夹
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True) #训练集数据
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf) #测试集数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 选择模型
model = cnn.CNN()
if torch.cuda.is_available():
model = model.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()#常用于多分类问题的交叉熵
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
epoch = 0
# 从训练集读取数据,开始迭代
for data in train_loader:
img, label = data
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label) #计算损失函数值
print_loss = loss.data.item()
optimizer.zero_grad() #将梯度归零
loss.backward() #反向传播计算得到每个参数的梯度值
optimizer.step() #通过梯度下降执行一步参数更新
epoch+=1
if epoch%50 == 0: #输出进度
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
# 保存和加载整个模型
torch.save(model, 'CNN_for_MNIST.pth')
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = Variable(img)
if torch.cuda.is_available(): #CPU or GPU
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1) #pred为一个tensor,里面是一组预测可能性最大的数,实际为下标,但在这里下标刚好与数匹配
num_correct = (pred == label).sum() #按理说bool型不能接sum,但当pred和label是tensor格式时会得到一个tensor且只有一个值为前两者相等的值得个数,刚好统计了正确的预测数
print('pred',pred)
print('label',label)
#print(type(num_correct))
#print(num_correct)
#print((pred == label).sum())
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format( #输出模型评估参数总损失和正确率
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
2.4 手写数字输入识别
import torch
import torchvision.transforms as transforms
from torch.autograd import Variable
# from torch.utils.data import DataLoader
# from torchvision import datasets
import cv2
import numpy as np
import cnn
clean = 0
board = 200
WINDOWNAME = 'Win'
line = 10
#鼠标划线函数
def draw_line(event, x, y, flags, param):
global ix, iy
if event == cv2.EVENT_LBUTTONDOWN:
ix, iy = x, y
elif (event == cv2.EVENT_MOUSEMOVE) & (flags == cv2.EVENT_FLAG_LBUTTON):
cv2.line(img, (ix, iy), (x, y), 255, line)#黑线,粗细为line像素
ix, iy = x, y
img = np.zeros((board, board, 1), np.uint8)
cv2.namedWindow(WINDOWNAME)
cv2.setMouseCallback(WINDOWNAME, draw_line)
transf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
while True:
cv2.imshow(WINDOWNAME, img)#展示写入窗口,输入就是使用鼠标在其上写数字从0到9,写完后按下空格进行识别,再按一下清空窗口,写好后再按再次检测,往复;按esc退出
key = cv2.waitKey(20)
if key == 32:
if clean:#重新初始化画板
img = np.zeros((board, board, 1), np.uint8)
cv2.imshow(WINDOWNAME, img)
else:
# 把图片resize成MNIST数据集的标准尺寸28*28
resized_img = cv2.resize(img, (28, 28), cv2.INTER_CUBIC)
im = transf(resized_img)
im = torch.unsqueeze(im, dim=0) # 对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
if torch.cuda.is_available():#GPU是否可以使用
im = im.cuda()
else:
im = Variable(im)
model = torch.load('CNN_for_MNIST.pth')
out = model(im)
c = out.tolist()[0]
print(c)
print(c.index(max(c)))
clean = not clean
elif key == 27:
break
cv2.destroyAllWindows()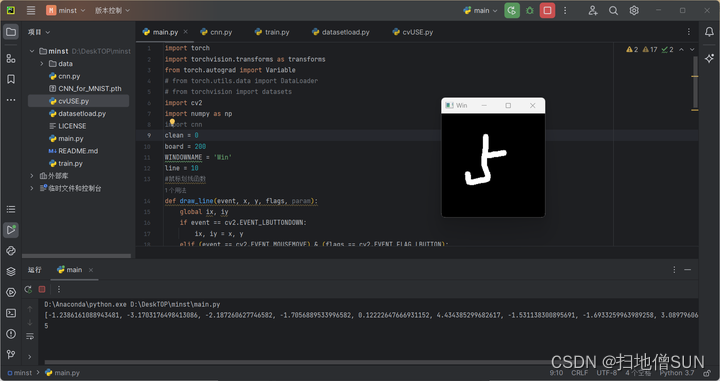
3. 实验结果
预测准确率达到了0.9748 损失为0.081368
4. 结论
本实验使用 PyTorch 框架成功搭建了一个简单的卷积神经网络模型,对 MNIST 手写数字数据集进行了训练和评估。实验结果表明,所构建的模型具有较高的准确率,可用于实际的手写数字识别任务中。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









