







交通环境复杂多变,不同驾驶场景涉及特定驾驶任务,如遇红灯停车、礼让行人等。多数模型仅依靠骨干网络提取的 “自下而上” 图像信息预测驾驶员注意力,难以充分考虑不同驾驶场景中的特定任务需求。而 “自上而下” 的场景信息(如驾驶任务相关的语义信息)对于准确识别驾驶员注意力分配至关重要。但文本数据(包含语义信息)与图像数据在特征空间中难以匹配和对齐,存在维度差异,这为利用语义信息指导驾驶场景信息带来挑战,因此需要一种有效的机制解决该问题,CMA 正是基于此需求而提出。
上面是原模型,下面是改进模型
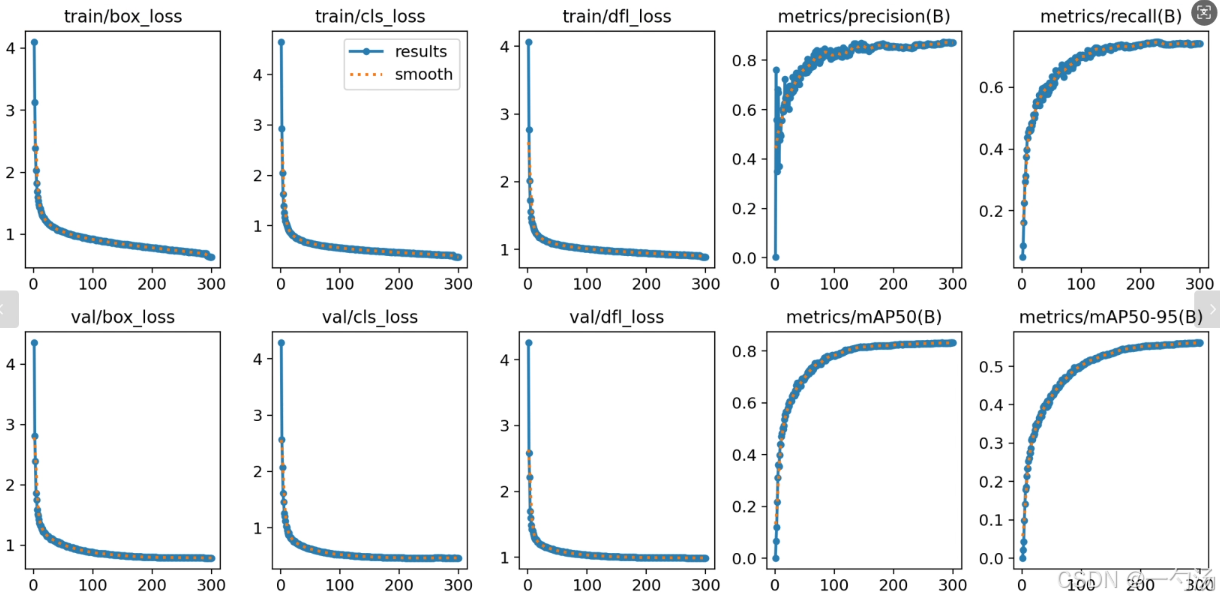
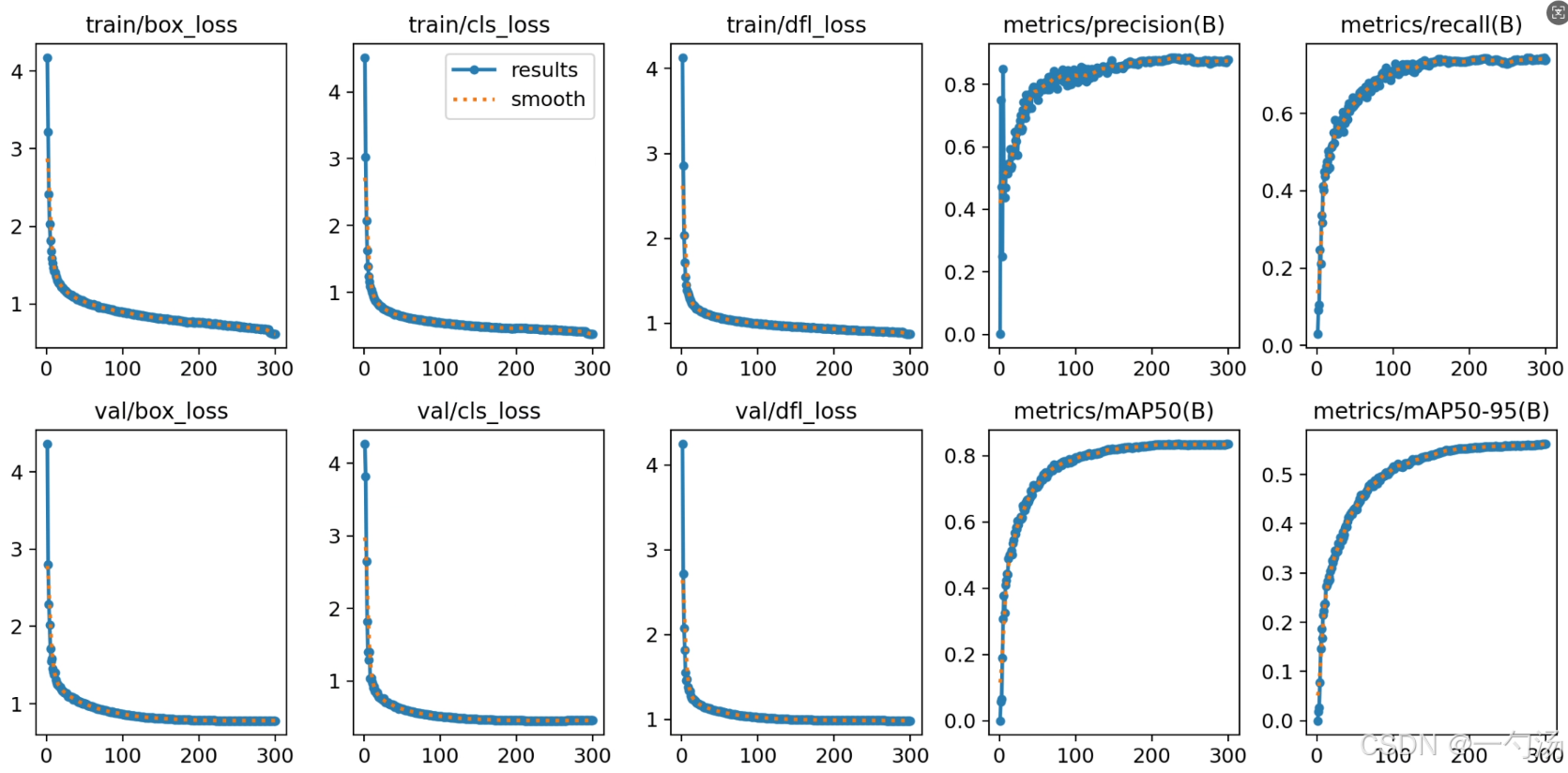

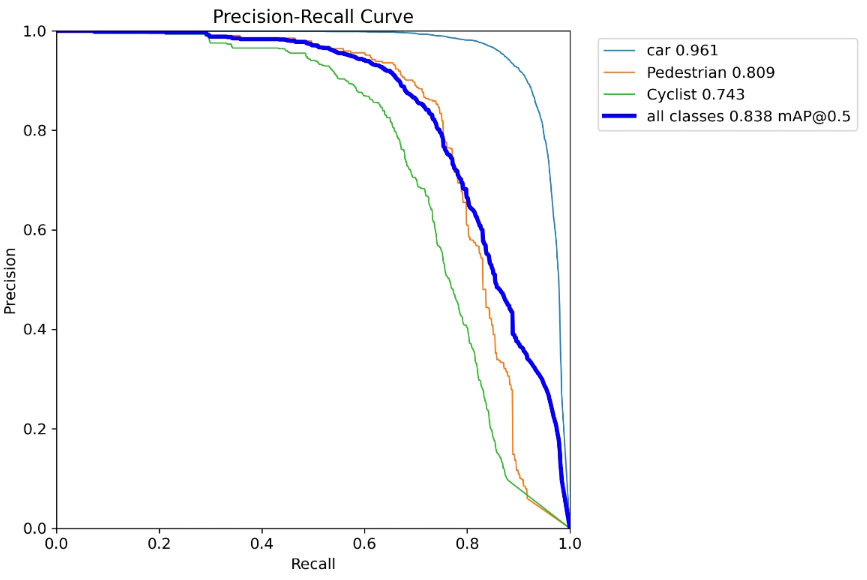
1. 跨模态注意力机制CMA介绍
CMA 基于注意力机制理论,通过对不同模态信息进行交互和融合,使模型能够聚焦于与当前任务相关的关键信息。在驾驶场景中,利用 CLIP 模型提取的语义信息和骨干网络提取的图像信息,计算不同通道之间的注意力权重,以此衡量不同信息对最终结果的影响程度,从而实现跨模态信息的有效融合,更好地指导驾驶员注意力的预测。例如,当行人准备过马路时,模型能依据语义信息将注意力分配到行人身上,提高对潜在危险的感知能力。
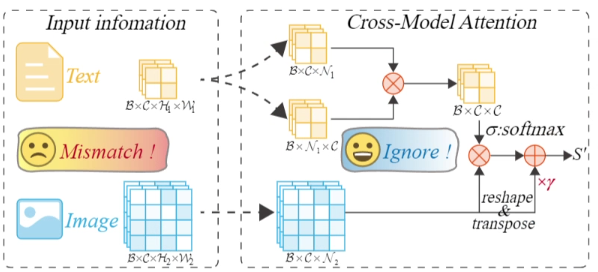
从提供的图片来看,CMA模块主要包含以下几个部分:
CMA 模块以 CLIP 提取的语义信息 Info_text 和骨干网络提取的图像信息 Info_image 作为输入。由于二者特征维度不同,首先将语义信息投影到与图像信息相同的特征通道空间,使用通道注意力模块的简单结构实现跨模态信息融合。具体操作中,先将语义信息重塑为 Query(Q),将图像信息转置为 Key(K),二者进行矩阵乘法后通过 softmax 操作得到显著性语义表示 S,该表示衡量了不同通道间的影响。同时,将最深层的图像信息重塑为 Value(V),S 与 V 进行矩阵乘法,再经过重塑、与缩放参数 γ 相乘并与原图像特征信息相加,得到最终的跨模态融合信息 S',完成对不同模态信息的融合处理,为后续驾驶员注意力预测提供更丰富、准确的信息。
2. YOLOv11与跨模态注意力机制CMA的结合
TCMA 替换 YOLO11 的 concat,能打破简单拼接带来的局限。它能通过挖掘不同语义特征之间的深层联系,提升目标检测的准确性,同时避免维度不匹配问题,使融合更高效合理。
3. 跨模态注意力机制CMA代码部分
视频讲解:
YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve · GitHub
用一篇论文教您如何使用YOLOv11改进模块写一篇1、2区论文_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
YOLOv11全部代码,现有几十种改进机制。
4. 跨模态注意力机制CMA引入到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
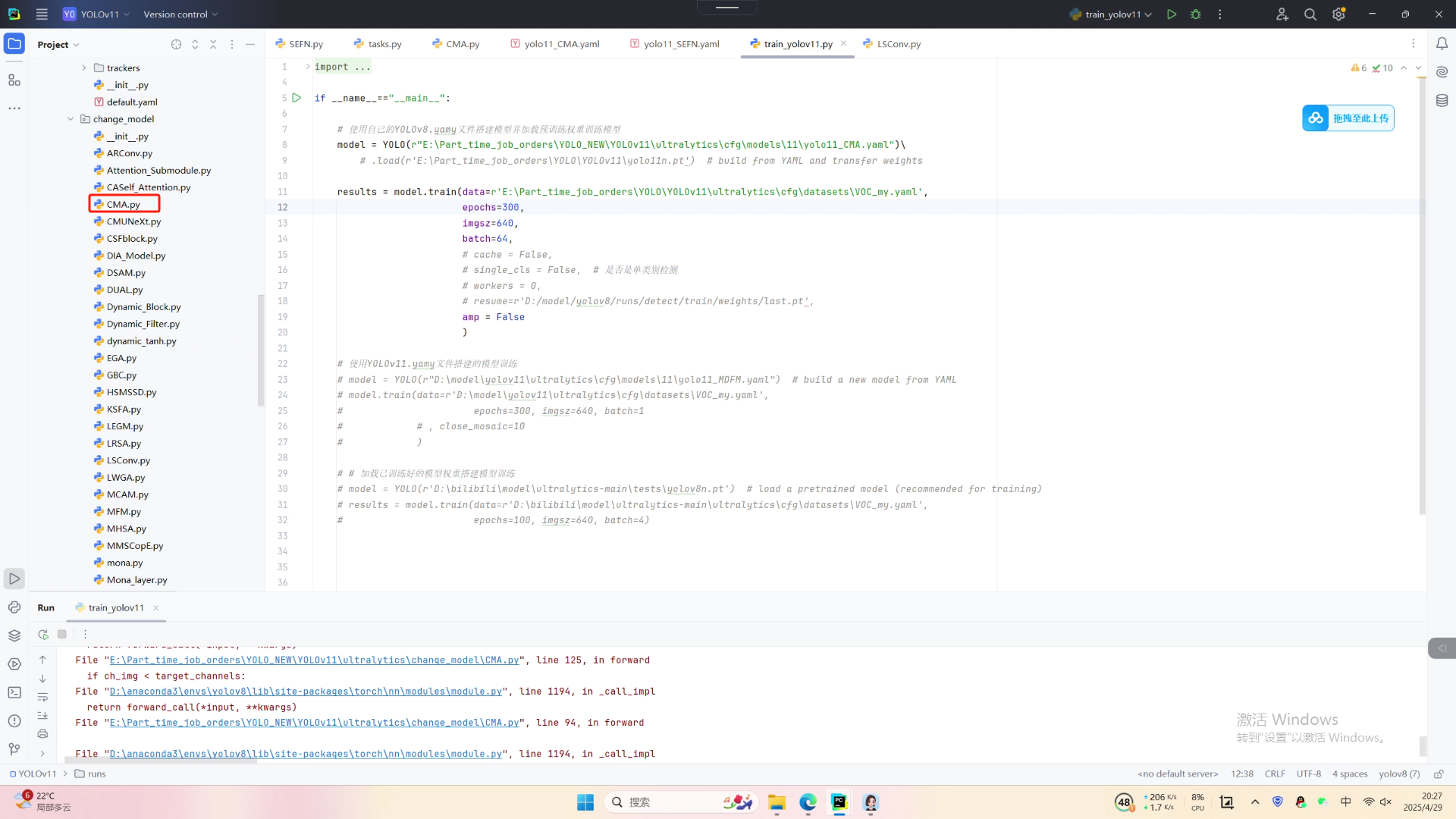
第二:在task.py中导入包
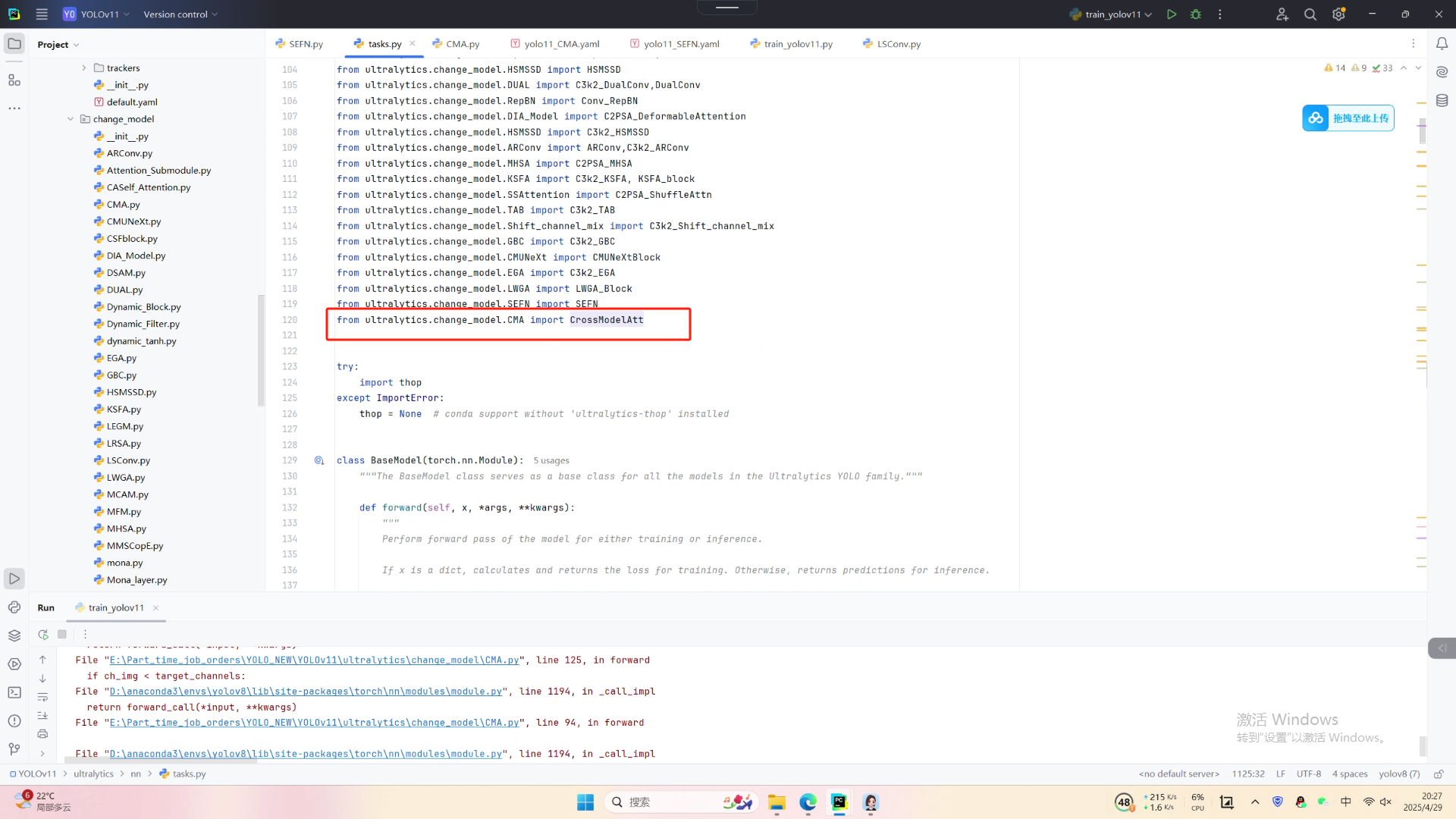
第三:在YOLOv11\ultralytics\nn\tasks.py中的模型配置部分下面代码
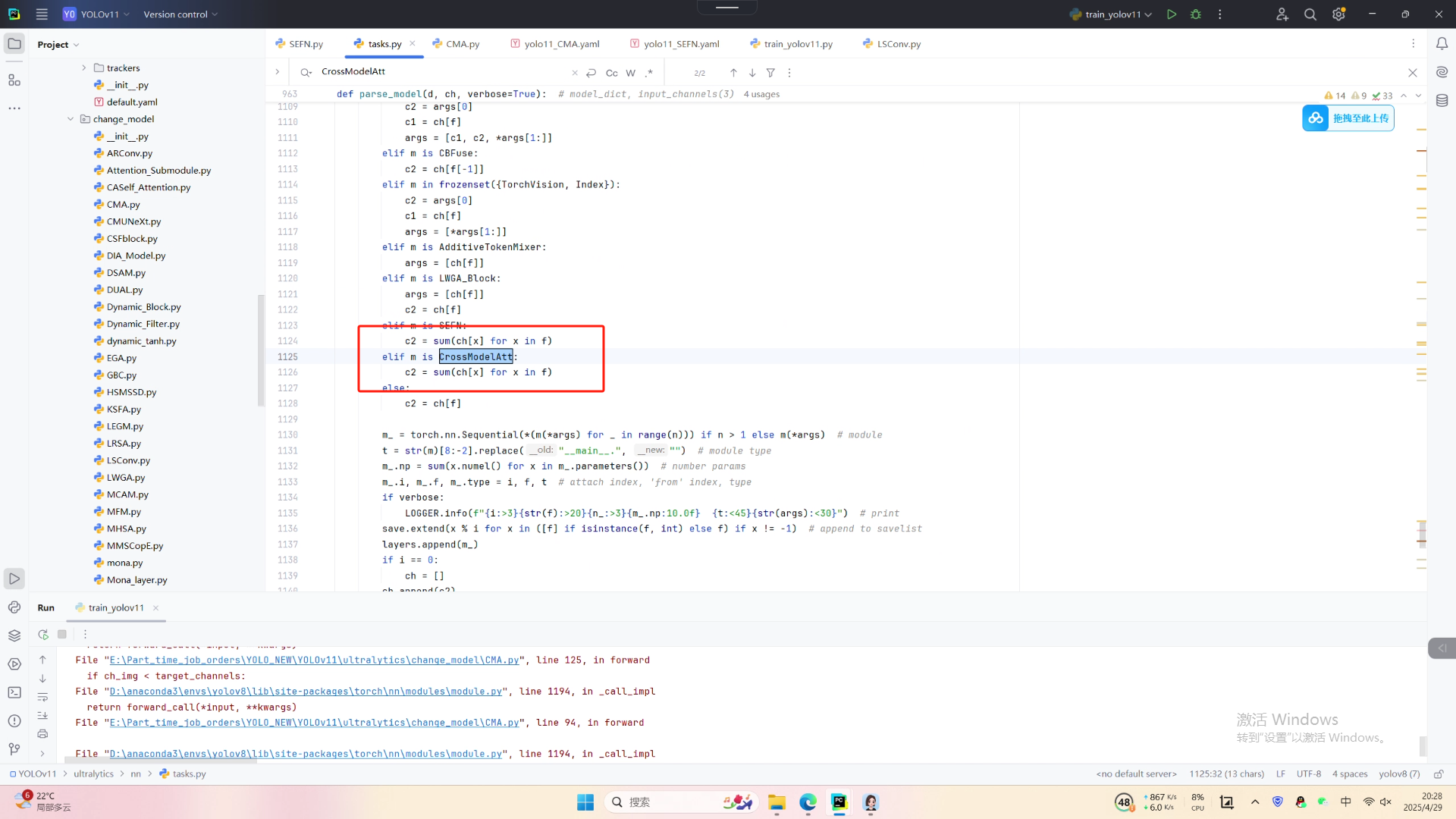
第四:将模型配置文件复制到YOLOV11.YAMY文件中
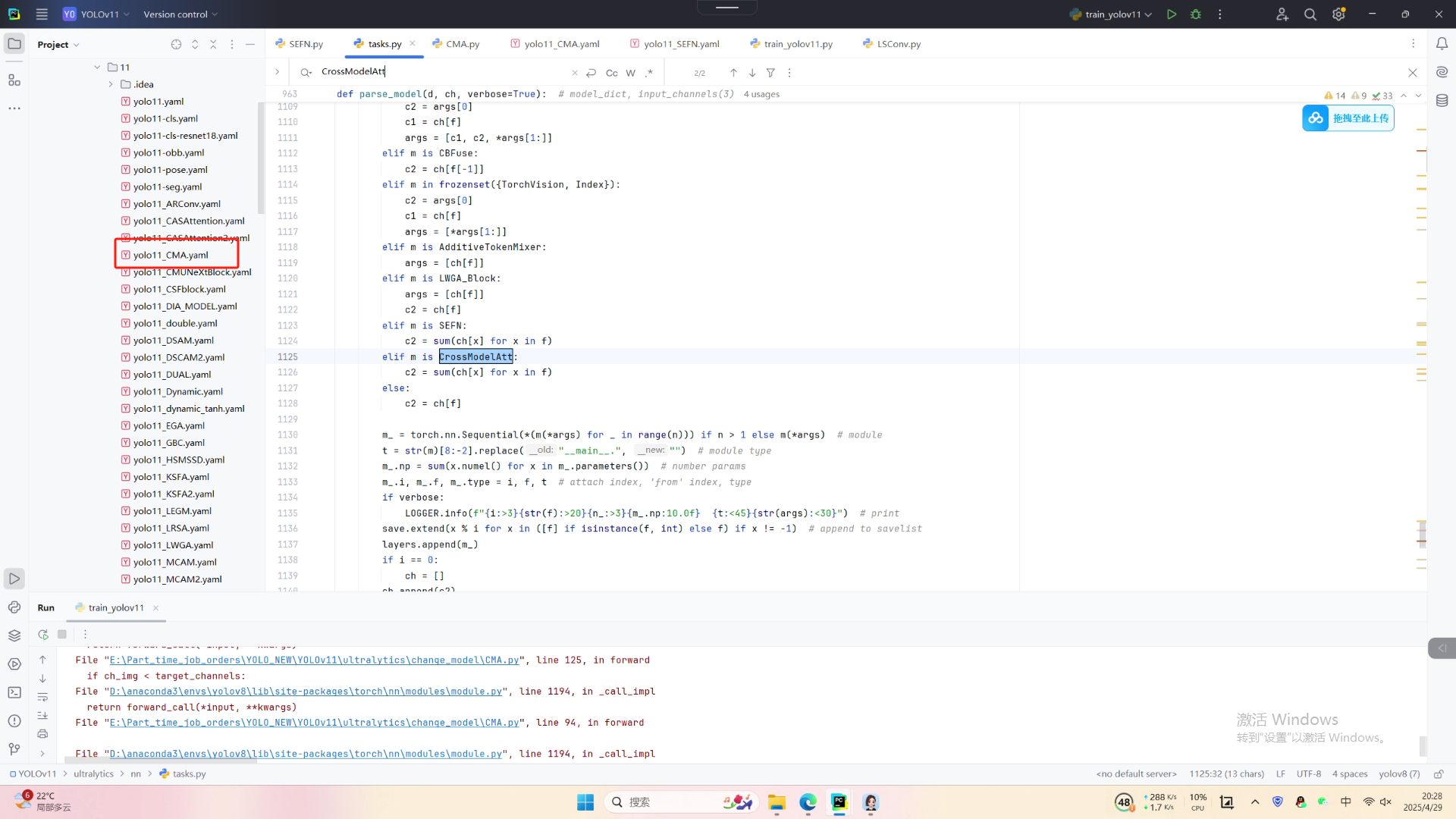
第五:运行成功
from sympy import false
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"E:\Part_time_job_orders\YOLO\YOLOv11\ultralytics\cfg\models\11\yolo11_CMA.yamy")\
.load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv11\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









