







最近Remini黏土特效非常火,我也是无意花点时间玩了玩这个东西,你有没有在算法层面思考过它是怎么实现的呢?
我经常被前辈诟病看东西不看实质,这里我将做出一些改变,就从研究最简单的应用开始吧。我感觉我被拷问的时候,很多细节我都看不到,我也不知道怎么去看到。真的算法面试问的太细了。。很难为本宝宝。先从这篇开始,工作上也做个有心人!
我这里将详细展开,尽量做到深入浅出去讲解粘土特效的技术原理。
简要介绍pipeline
总体为以下5个流程:
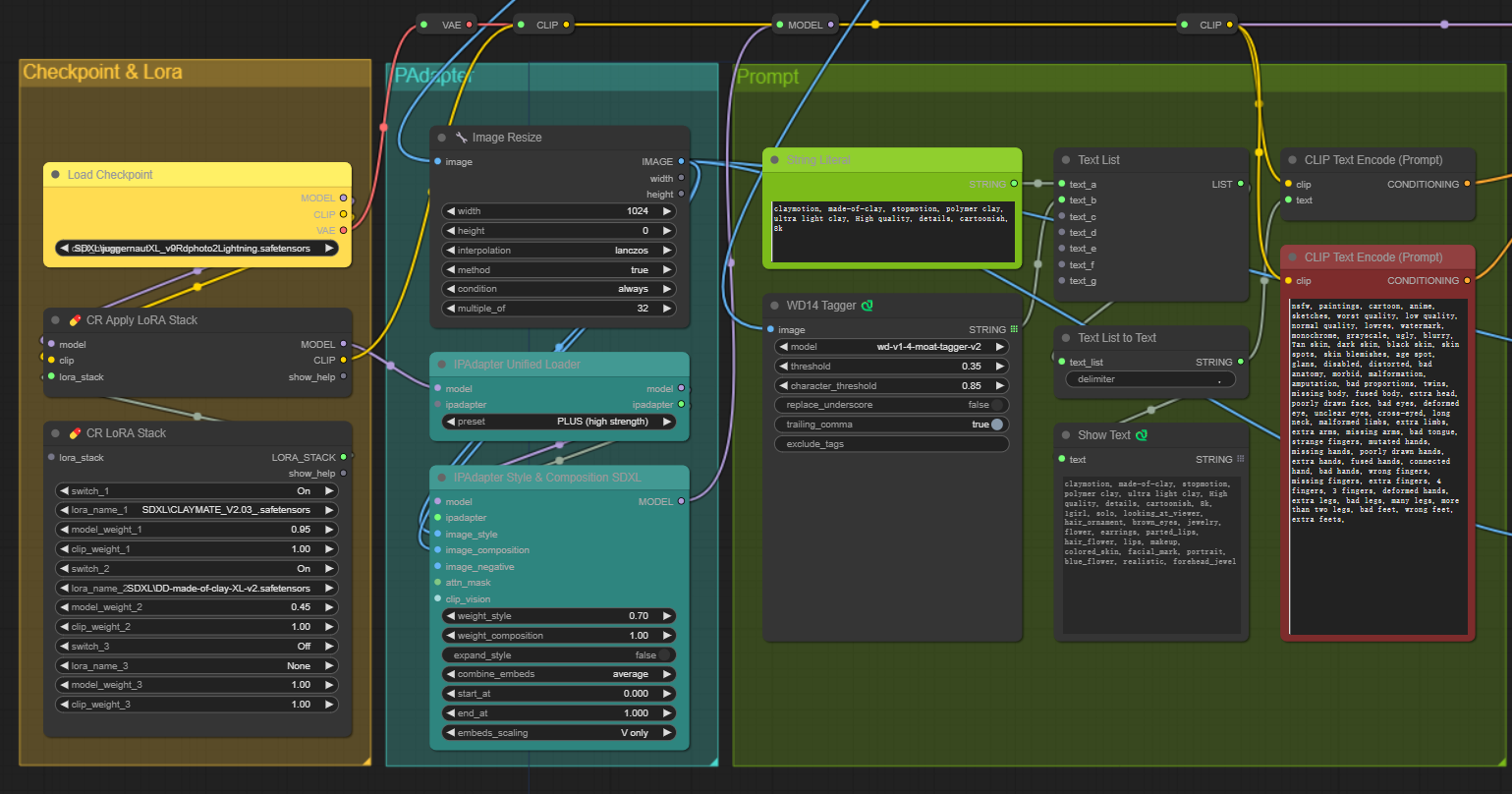
Load checkpoints and lora
IP Adapter
Prompts
ControlNet
KSampler
Load checkpoints and lora
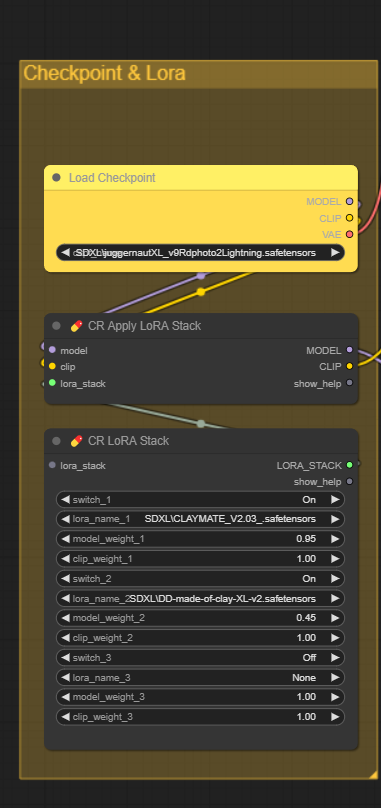
这一步在加载checkpoint模型和lora模型。
Checkpoint模型这里是
Juggernaut_X_RunDiffusion_Hyper.safetensors
它是sdxl模型。这个模型有自带的clip和vae。可以自选。只要是sdxl就可以。
点1:SDXL模型的情况概览
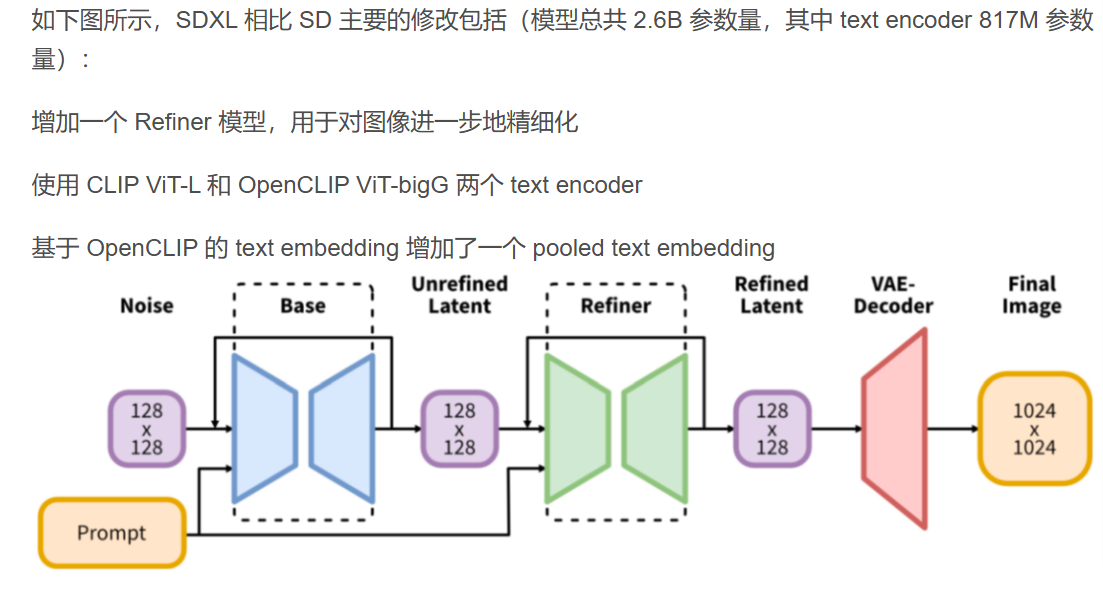
由于在下游用到的逐渐去噪的过程里用到vae和model,在对于prompt的处理时用到clip,这里要配对,所以这个图里面上面长长的胳膊寄存model clip vae就是拿来传送这些东西的。
Lora模型这里是
LoRA1:CLAYMATE - Claymation Style for SDXL;LoRA2:Doctor Diffusion's Claymation Style LoRA。
Lora stack就是把多种不同的lora模型做整合,提供clip和lora model weight的权重信息。就是融合多种不同的风格用的。详情lora具体在模型层面的应用请看往期https://mp.weixin.qq.com/s/t6ZHyjO65x1hWTmUyBWhoQ。
第一个模块 有3个元件。Load checkpoint(存放ckpt模型)、Apply LoRA Stack(用于整合ckpt和lora的关系)和Lora Stack(存放lora模型)。
IPAapter
这一步主要是对图片做处理以及对ip adapter model做初步处理。
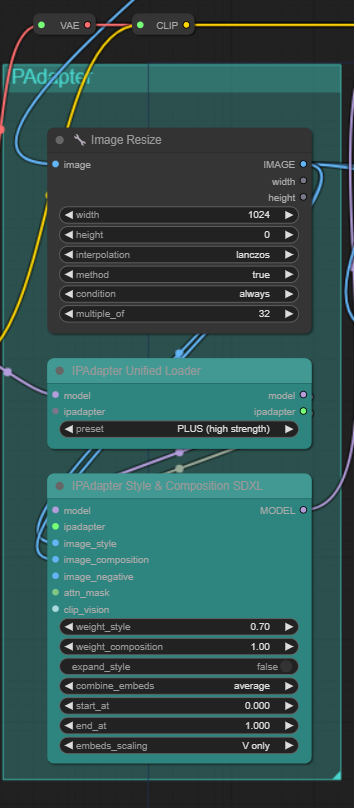
读入输入的图片,做resize处理。
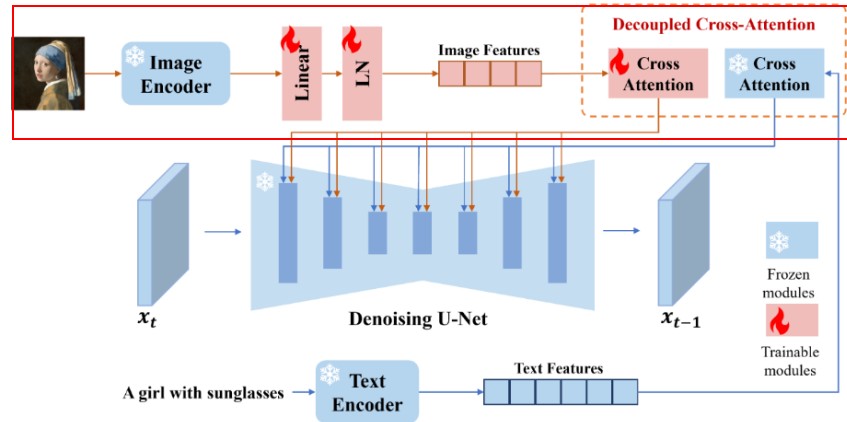
下面两个元件将第一个模块的总体得到的model 与 预训练的IPAdapter做强度控制和融合。具体model,与IPAdapter的模型参数都会被传进来,根据用户的选项进行transformer模块的替换,这里IPAdapter包括一个图像编码器和包含解耦交叉注意力机制的适配器。这里IPAdapterUnifiedLoader 节点负责加载预训练的 IPAdapter 模型。这个节点提供了一个统一的接口来加载不同的 IPAdapter 模型,包括基本模型、加强模型、面部模型等。通过这个节点,用户可以轻松地选择和加载所需的模型,而无需手动下载和配置文件。这里对输入model里的attention部分做权重组合,然后输入图片一支的image encoder确定(一般是clip的图像块嵌入部分),暂时可以计算用于训练attention参数的image feature。就是下图钟上面那个分支会在这里被定义和被执行。
这里输入的图片决定是否构图迁移 composition ,风格迁移 style 这里可以是多种图片。这里两个工作都做。
我查看代码 发现这两个工作的实现是通过替换model的不同attention层的权重的比重来完成。就是a*weight(某个atten)这个a被定义 。代码库为comfyui_IPAdapter_plus。
总的来说,IP-Adapter通过图像编码器,文本提示和图像特征通过适配模块与预训练的文本到图像模型进行交互,根据文本和图像提示生成的图片。
Prompt
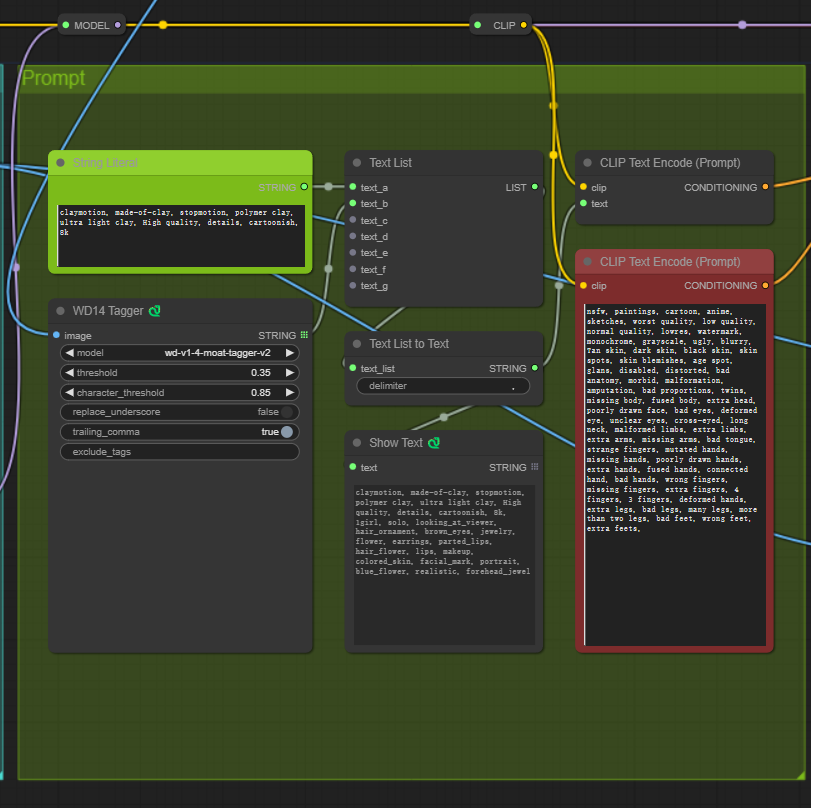
WD14 tagger元件里实现image to text。一般模型用moat为backbone训练,或者vit等等。输入得到生成图片中的出现的物体词语,本质是一个图片的多分类问题。这里选用的是wd14 tagger moat。
点1:介绍moat。谷歌2022年10月:【MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models】
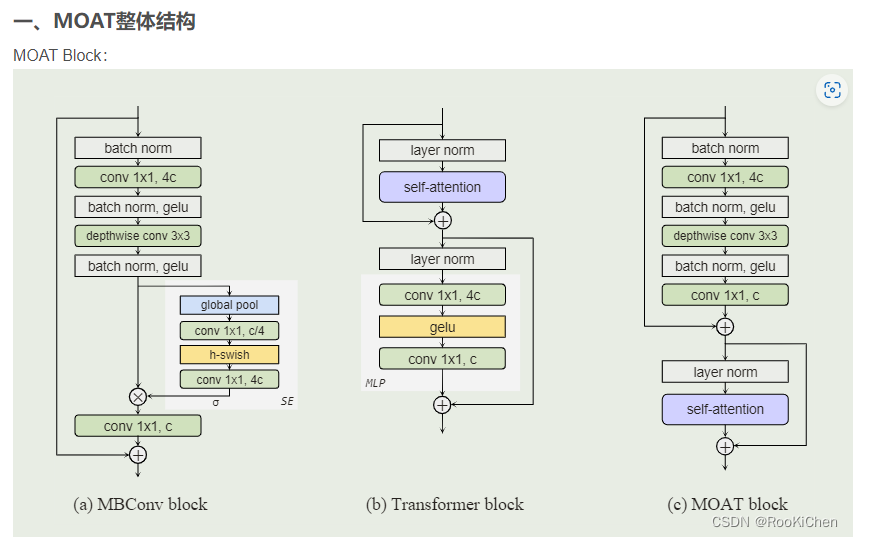
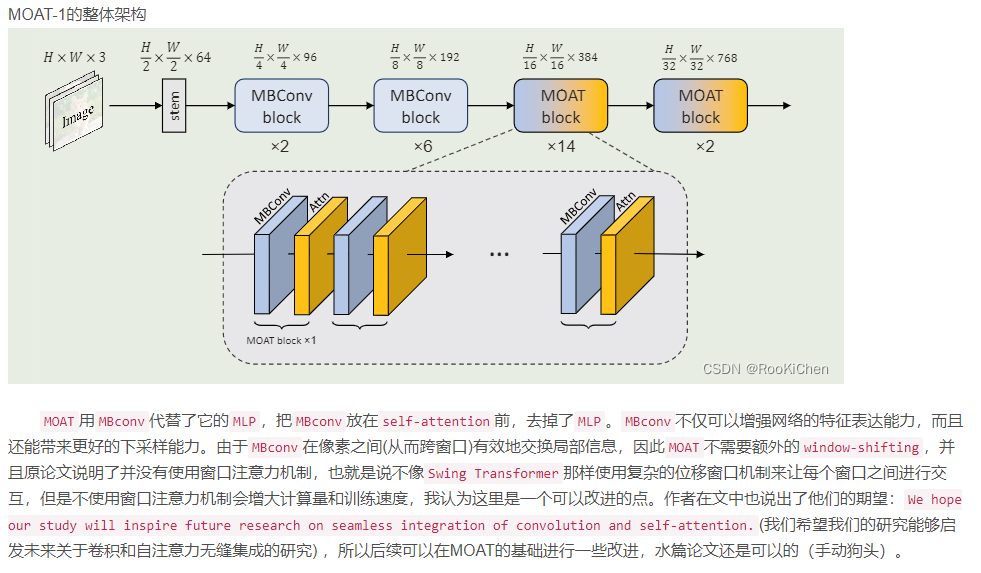
详情:
https://blog.csdn.net/RooKichenn/article/details/127449813
点2:这里的image to text是怎么实现的。笔者认为就是多分类问题,对于输出用sigmoid表示的多个标签的预测结果。
这里的string literal 用于形容黏土风格。
中间三个元件用于text的处理啦。
有两个名为Clip text encode的元件。上面的用于串联positive prompt的文字,下面的是negative prompt了。然后这些文字送入利用前面sdxl自带的text encoder(clip部分的文字encode部分)做encode的过程。
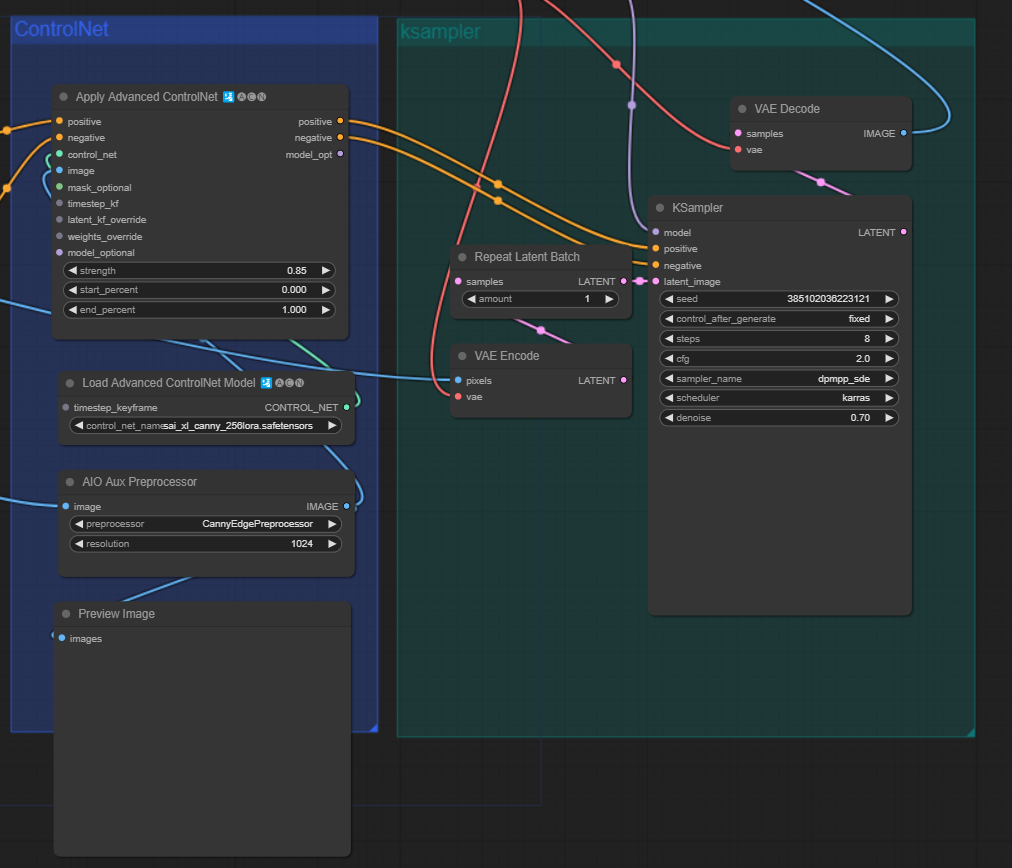
ControlNet
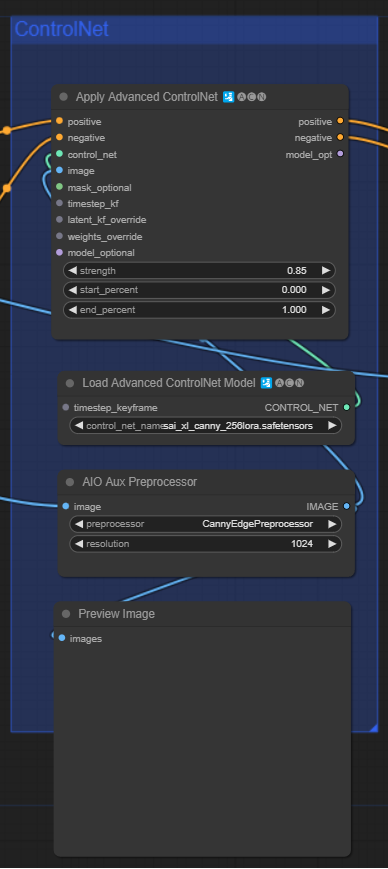
这部分主要是加载canny边缘处理的controlnet,主要是在SD Encoder Block旁边增加condition模块,用于保留边缘信息。这里经过Apply Advanced ControlNet后的positive和negative是经过指之前的text处理的内容,以及带有controlnet(一个在sd model层面的插件,详情看
https://mp.weixin.qq.com/s/t6ZHyjO65x1hWTmUyBWhoQ)、IP Adapter(一个在Unet内部attention层面处理的插件)这些image要经过condition的信息内容。【这里存疑】
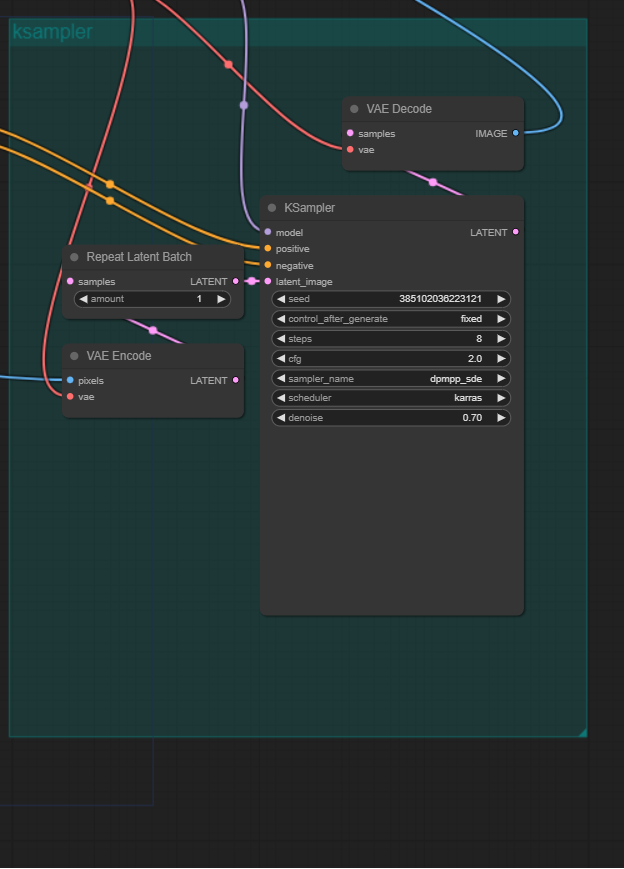
Ksampler
这一部分就到了利用diffusion model(前面加载的sdxl)预测噪声,vae部分 encode输入的图像然后根据之前的condition预测噪声逐渐去噪得到图片。这个过程有博客写得比我好,见
https://cloud.tencent.com/developer/article/2393003。

















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









