










笔者是在windows下进行GPU环境的配置,以及Cuda、CuDNN、TensorRT的安装。
一、查看你本机的显卡
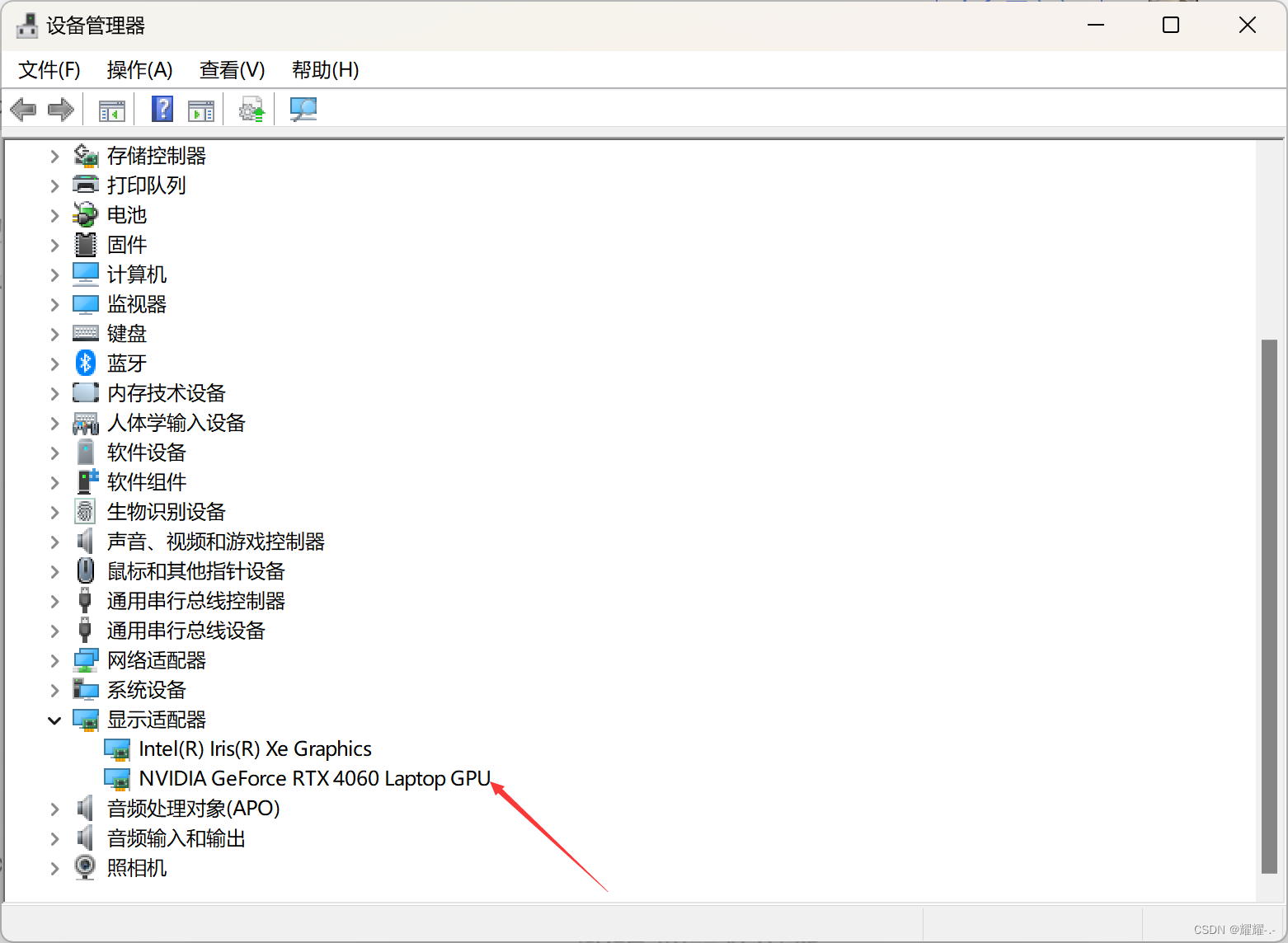
首先你要看你的电脑是否有NVIDIA的独立显卡,你可以在设备管理器-显示适配器中查看。
二、CUDA的下载与安装
笔者这里选择的是CUDA11.8。你首先要去CUDA安装官方你所要安装的CUDA Toolkit,比如这样。
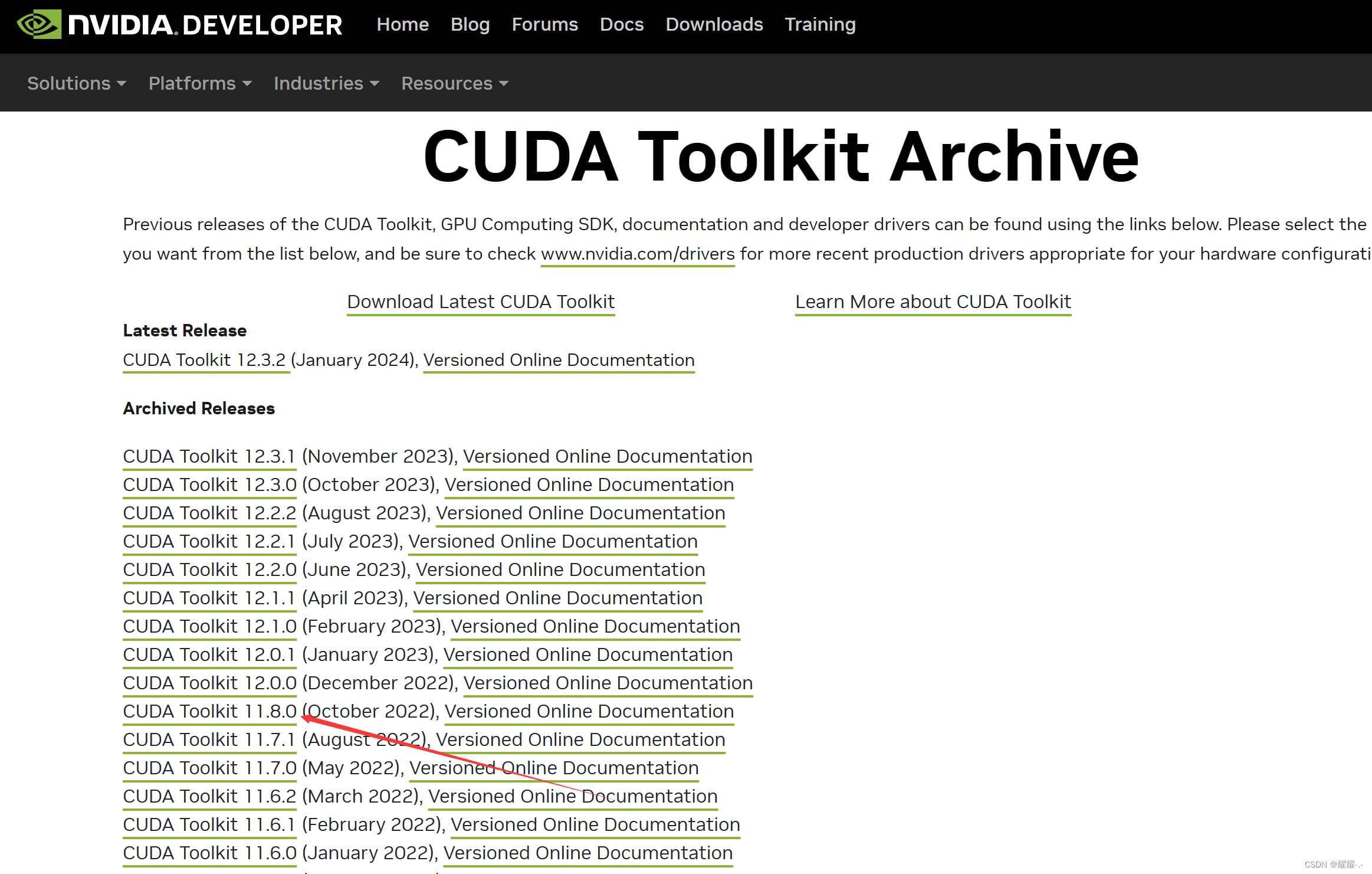
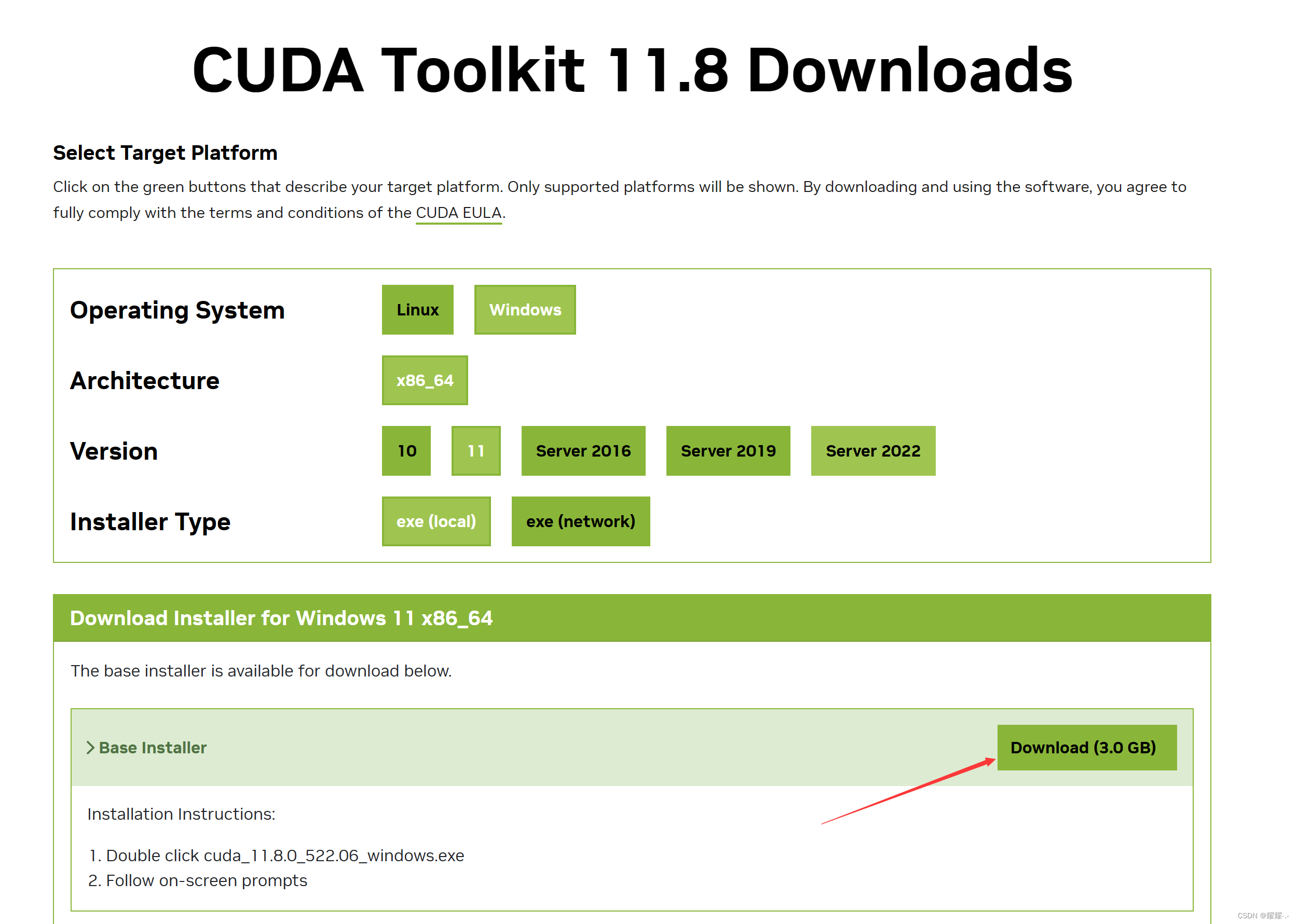
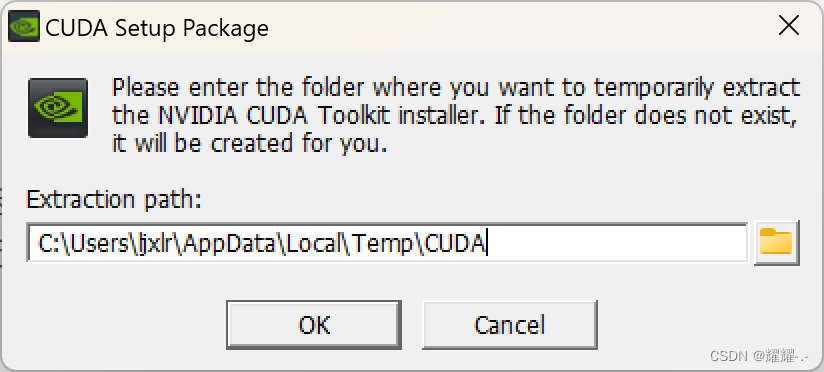
我们一般选择local模式,这个包有几个G。使用这个模式就不会因为网络问题而中断安装的过程了。下载好之后双击exe文件,会显示以下窗口,我们默认OK就行。这个路径是会暂时存放安装中的缓存,安装结束后,这一些缓存会自动清除掉,所以不需要管。
点击同意,然后继续下一步
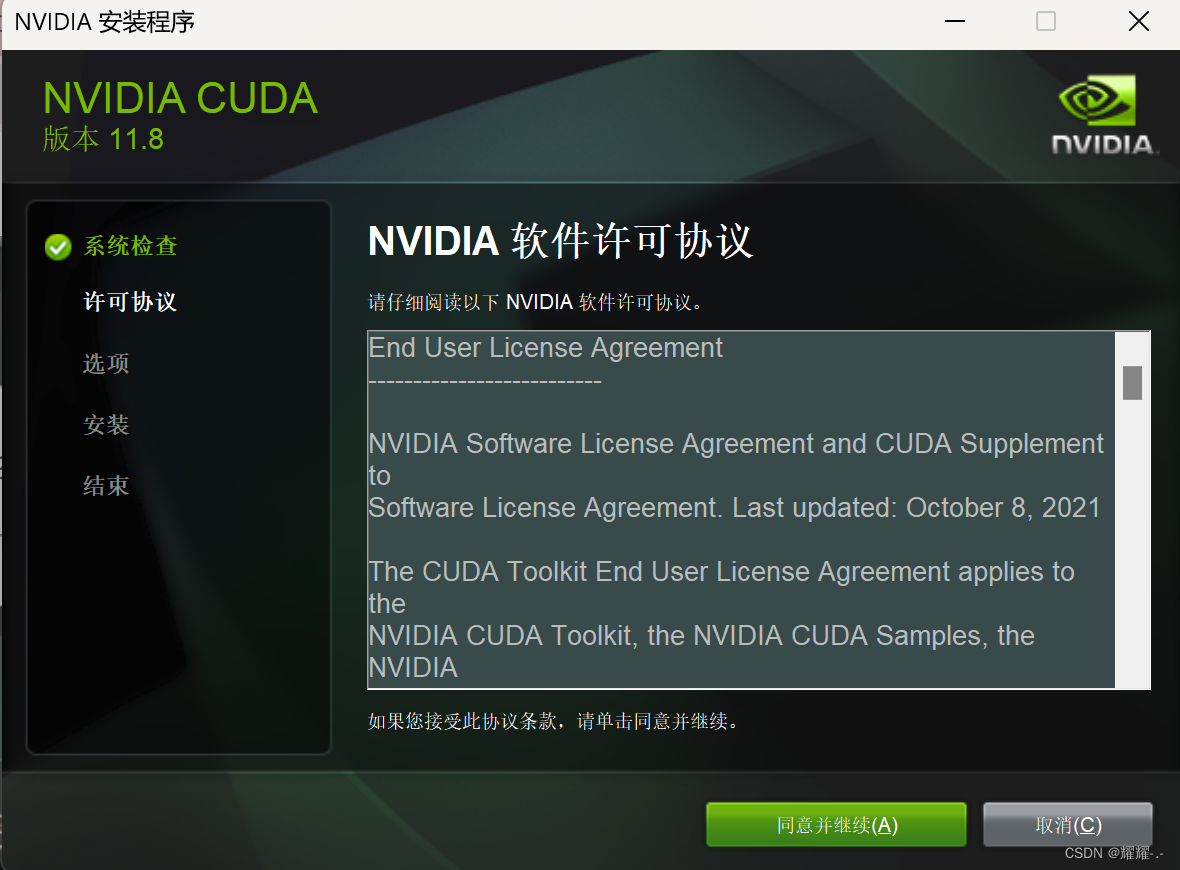
选择自定义安装,选择这几项就差不多了,其他的你用不到,就不用安装了,节省安装的时间。
接下来等待安装结束即可
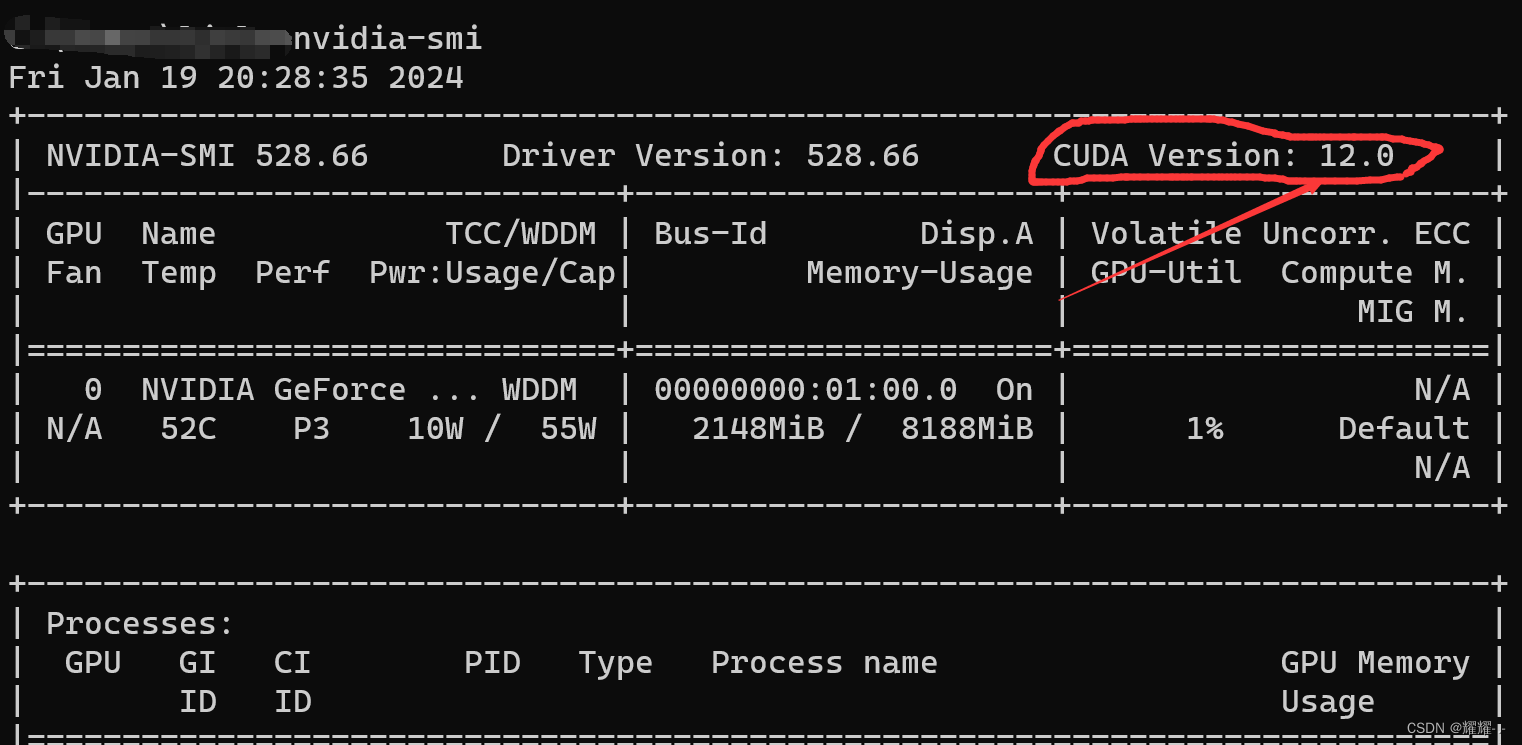
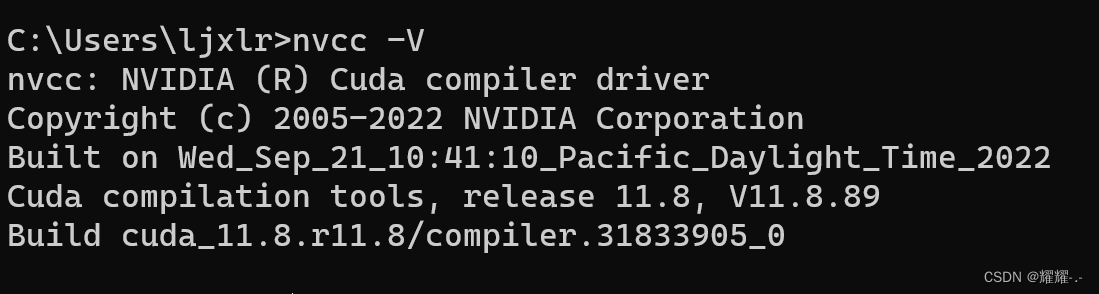
你可以在cmd中执行nvcc -V或者nvidia-smi,如果不报错,就代表安装成功。
打开查看显卡cuda,最高安装GPU版本
三、CuDNN的下载与安装
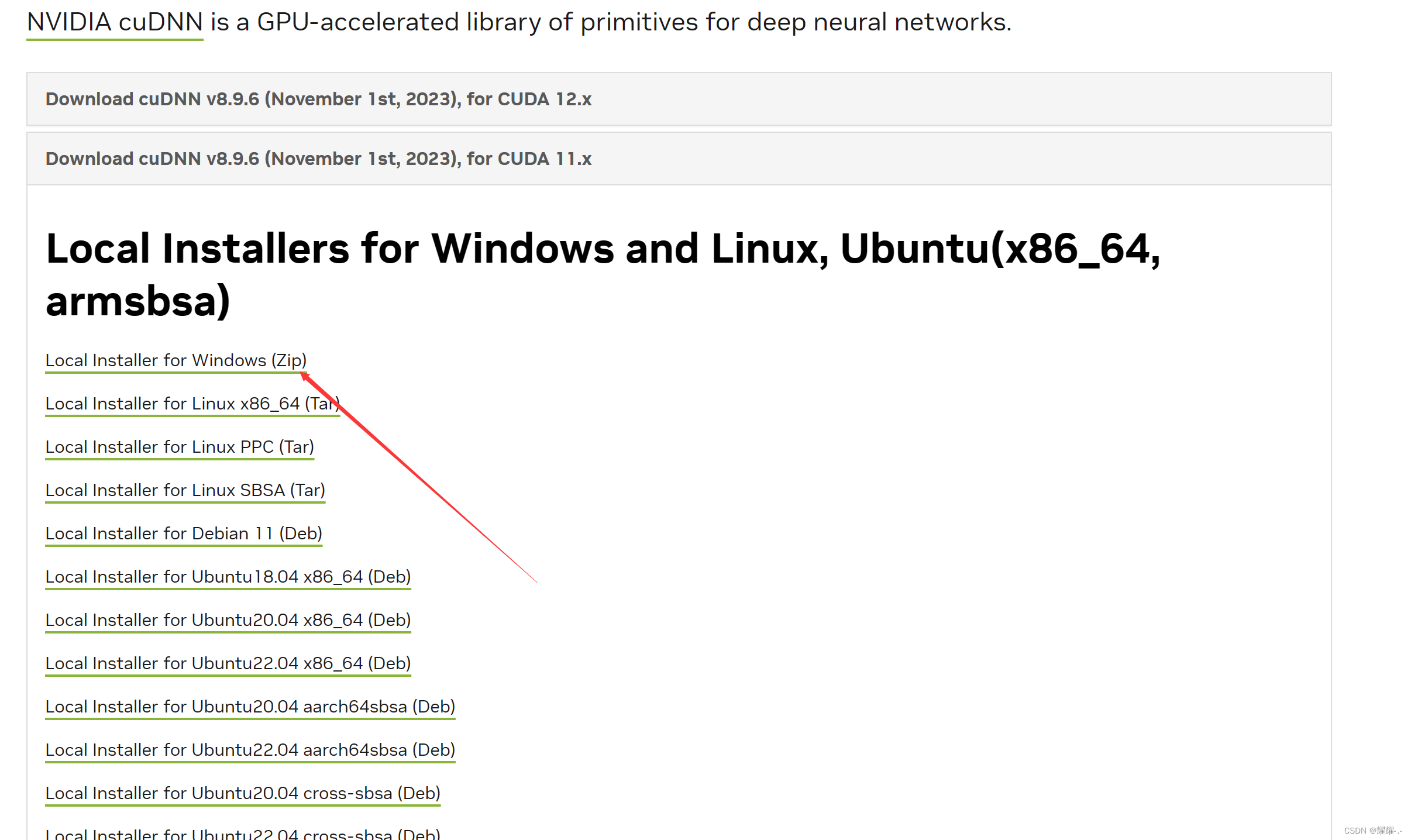
cuDNN安装起来比较简单,就是下载安装包。解压之后放到CUDA下的指定文件夹下即可。你可以通过这里CuDNN下载官网选择你想要的CuDNN版本。我选择的是cudnn-windows-x86_64-8.9.6.50_cuda12-archive。

把下载后的压缩包进行解压,分别将cuda/include、cuda/lib、cuda/bin三个目录中的内容拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8对应的include、lib、bin目录下就可以了。
四、TensorRT的下载与安装
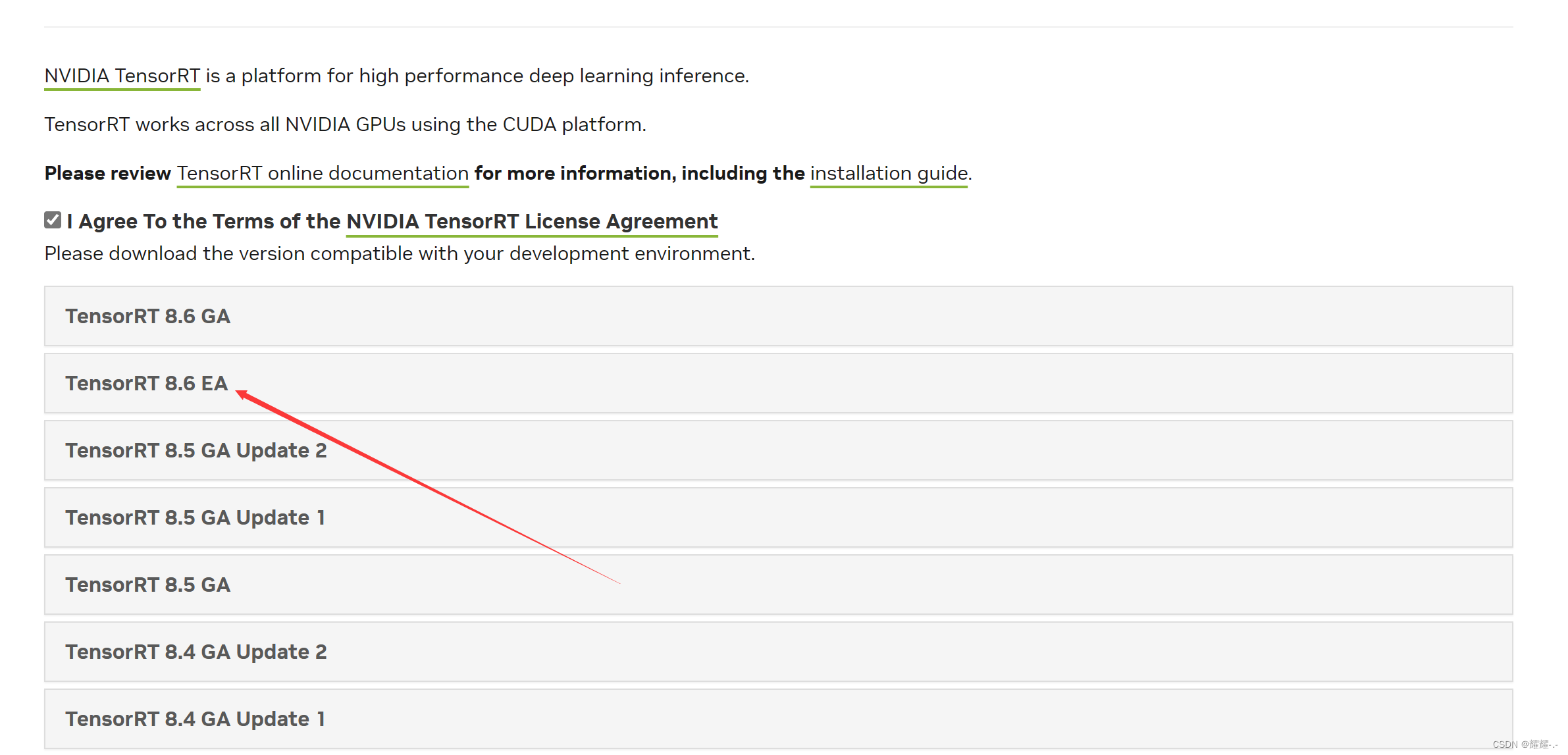
去这里TensorRT下载官方下载TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8并解压。
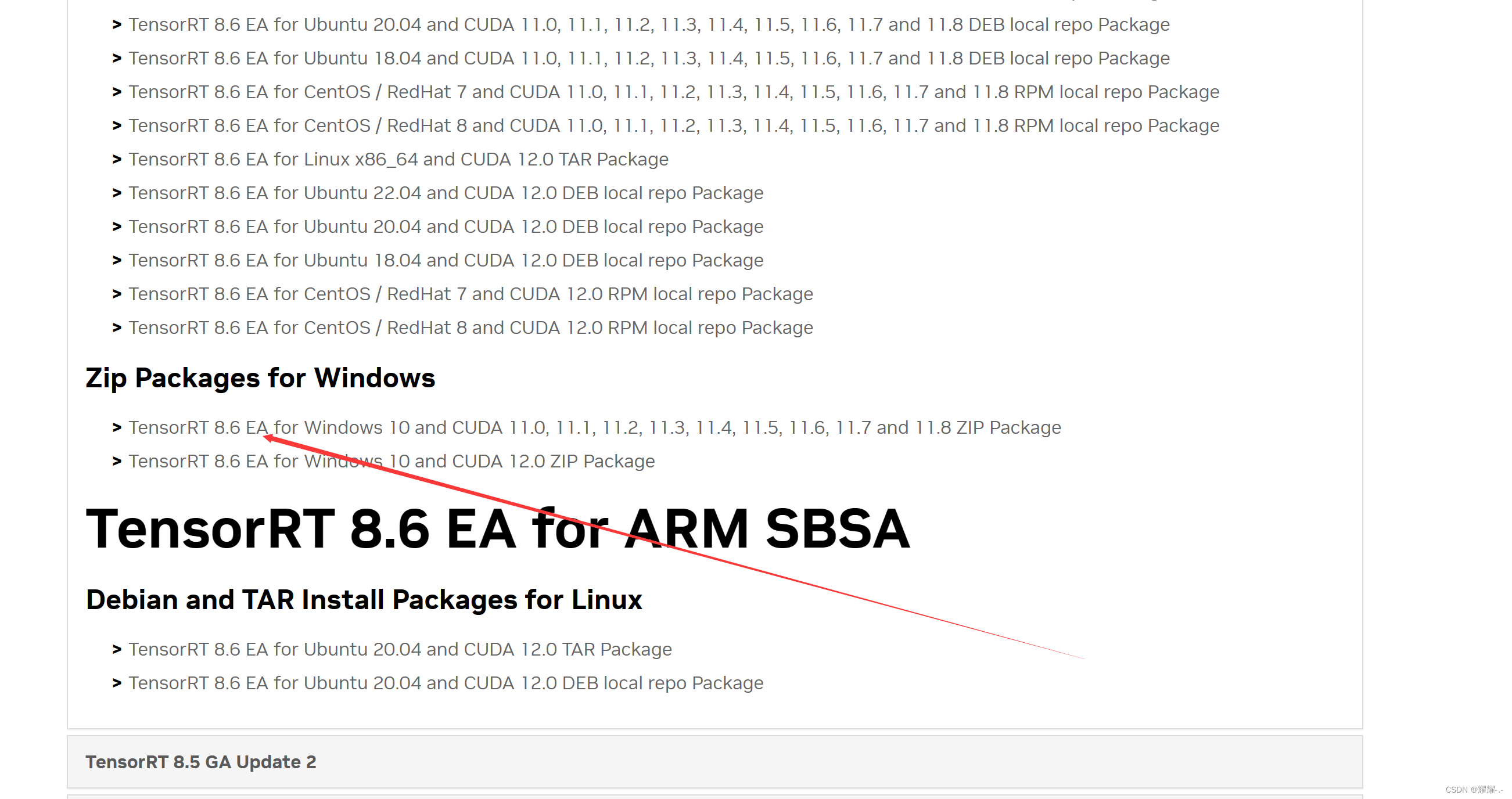
与安装CuDNN的步骤类似,只需要将文件放到CUDA下的指定文件夹下即可。
核心重点:
将 TensorRT-8.5.2.2\include中头文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include
将TensorRT-8.5.2.2\lib 中所有lib文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64
将TensorRT-8.5.2.2\lib 中所有dll文件copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin
1. Python安装TensorRT库
点开python
在目录上打上cmd
查看自己的虚拟环境: conda env list
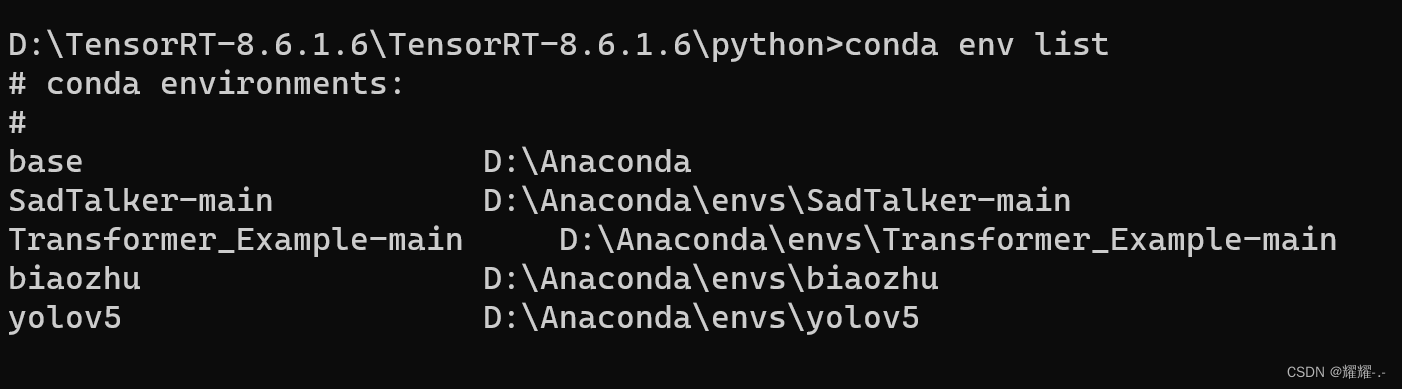
小编这里用的是yolov5的虚拟环境变量
激活虚拟环境:conda activate yolov5
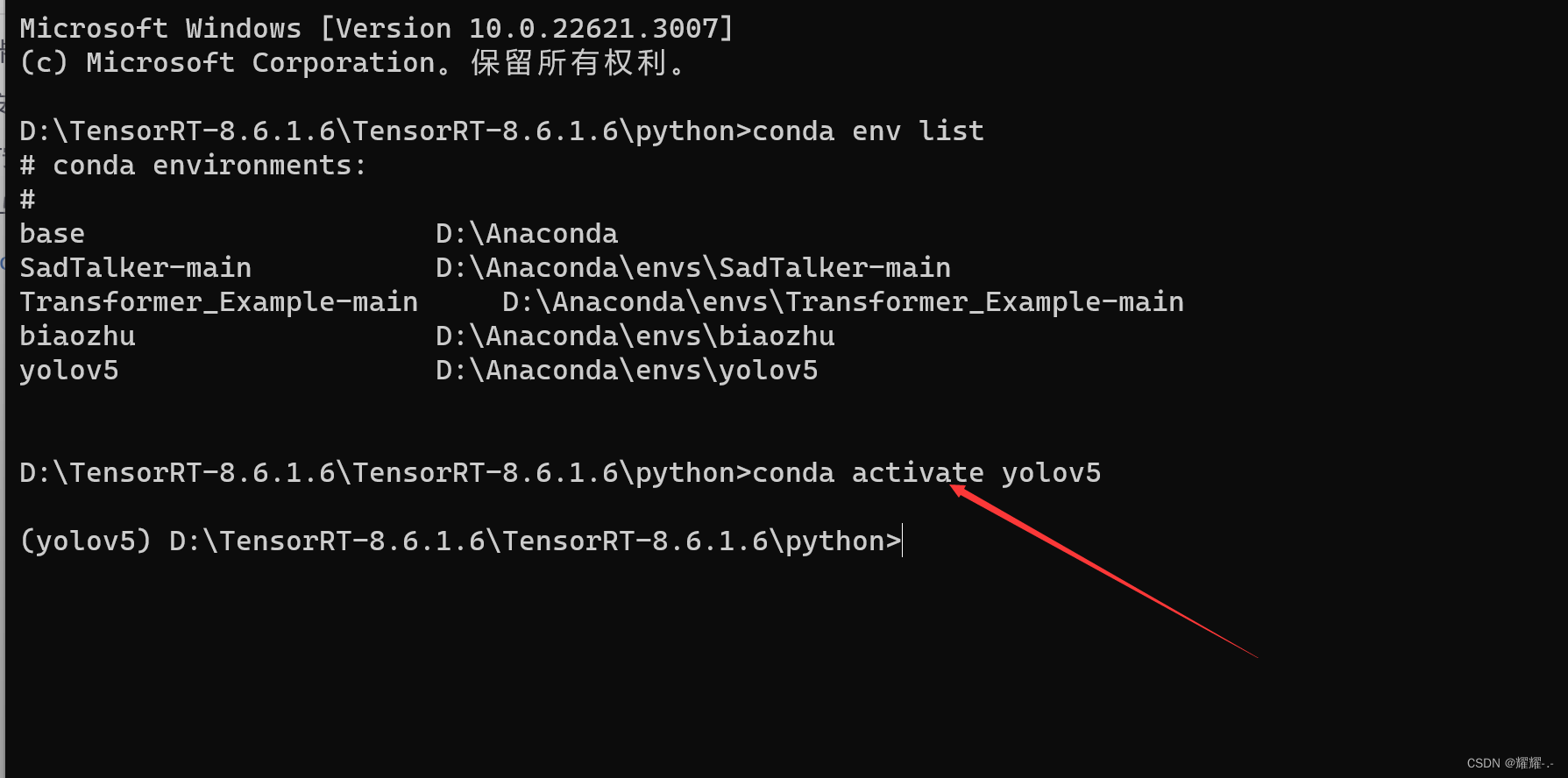
查看当前目录:dir
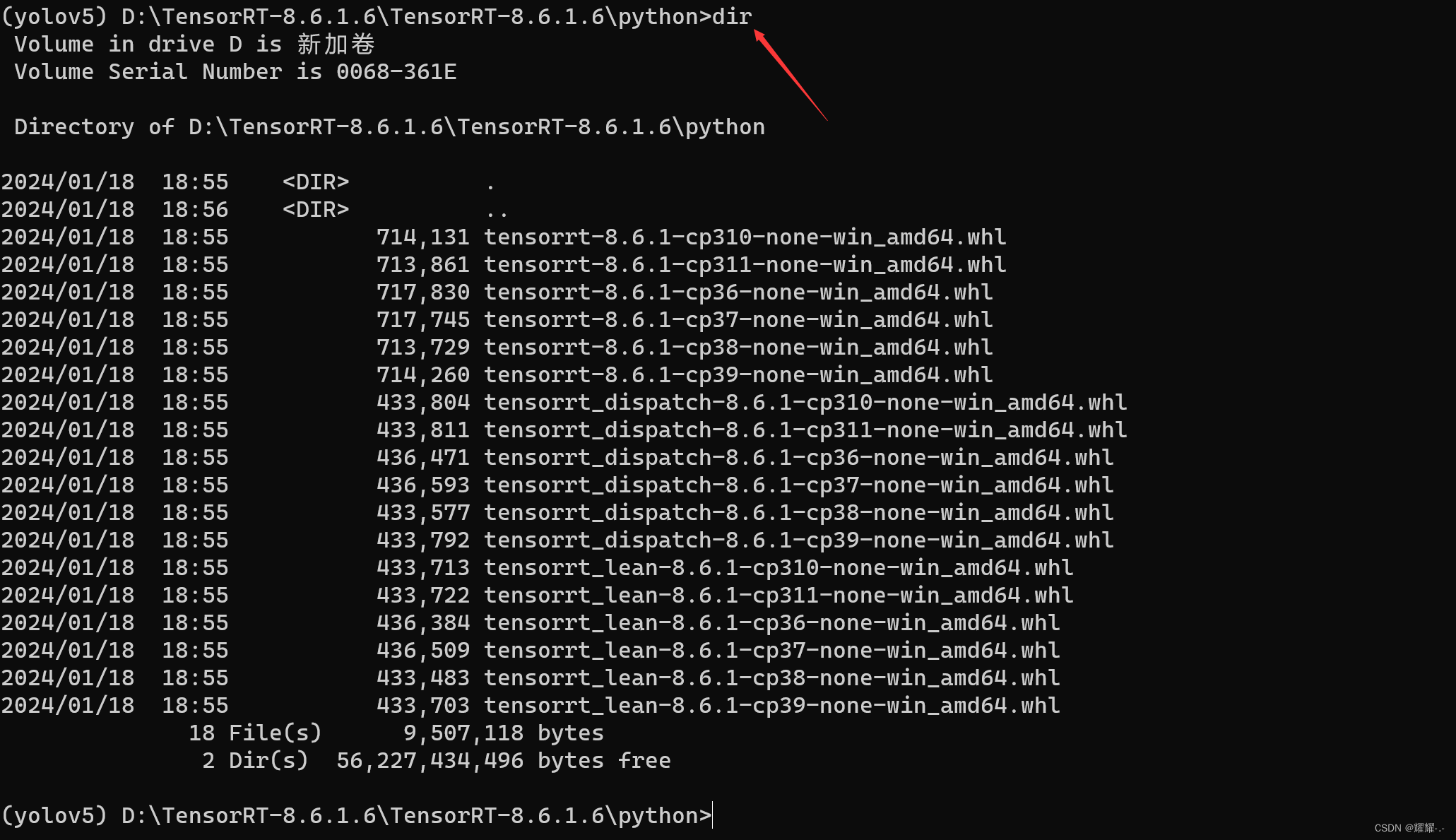
小编这里python是3.9的,所以把目录3.9的都下载完
pip install ./tensorrt_dispatch-8.6.1-cp39-none-win_amd64.whl
pip install ./tensorrt_lean-8.6.1-cp39-none-win_amd64.whl
pip install ./tensorrt-8.6.1-cp39-none-win_amd64.whl
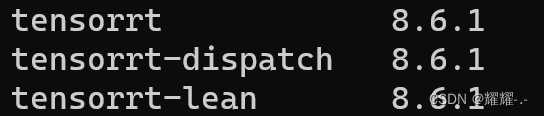
安装完输入:pip list 查看安装包
五、进行测试
建立一个python工程输入代码进行测试
import tensorrt as trt
if __name__ == "__main__":
print(trt.__version__)
print("hello trt!!")
结果

六、用tensorRT加速yolov5
1.点开yolov5工程里的export.py
这个部分是模型的转换部分,将模型转换为torchscript、 onnx、coreml等格式,用于后面的应用中,方便将模型加载到各种设备上。
2、导入需要的包和基本配置注释
import argparse # 解析命令行参数模块
import sys # sys系统模块 包含了与Python解释器和它的环境有关的函数
import time # 时间模块 更底层
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
import torch # PyTorch深度学习模块
import torch.nn as nn # 对torch.nn.functional的类的封装 有很多和torch.nn.functional相同的函数
from torch.utils.mobile_optimizer import optimize_for_mobile # 对模型进行移动端优化模块
FILE = Path(__file__).absolute() # FILE = WindowsPath 'F:\yolo_v5\yolov5-U\export.py'
# 将'F:/yolo_v5/yolov5-U'加入系统的环境变量 该脚本结束后失效
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
from models.common import Conv
from models.yolo import Detect
from models.experimental import attempt_load
from models.activations import Hardswish, SiLU
from utils.general import colorstr, check_img_size, check_requirements, file_size, set_logging
from utils.torch_utils import select_device
3、文件入口
脚本执行入口
if __name__ == "__main__":
opt = parse_opt()
main(opt)
4、parse_opt
设置opt参数。
def parse_opt():
"""
weights: 要转换的权重文件pt地址 默认='../weights/best.pt'
img-size: 输入模型的图片size=(height, width) 默认=[640, 640]
batch-size: batch大小 默认=1
device: 模型运行设备 cuda device, i.e. 0 or 0,1,2,3 or cpu 默认=cpu
include: 要将pt文件转为什么格式 可以为单个原始也可以为list 默认=['torchscript', 'onnx', 'coreml']
half: 是否使用半精度FP16export转换 默认=False
inplace: 是否set YOLOv5 Detect() inplace=True 默认=False
train: 是否开启model.train() mode 默认=True coreml转换必须为True
optimize: TorchScript转化参数 是否进行移动端优化 默认=False
dynamic: ONNX转换参数 dynamic_axes ONNX转换是否要进行批处理变量 默认=False
simplify: ONNX转换参数 是否简化onnx模型 默认=False
opset-version: ONNX转换参数 设置版本 默认=10
"""
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='../weights/best.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image (height, width)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--include', nargs='+', default=['torchscript', 'onnx', 'coreml'], help='include formats')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', default="True", action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--dynamic', action='store_true', help='ONNX: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset-version', type=int, default=10, help='ONNX: opset version')
opt = parser.parse_args()
return opt
5、main
def main(opt):
# 初始化日志
set_logging()
print(colorstr('export: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items())) # 彩色打印
# 脚本主体
run(**vars(opt))
4、run
脚本主体,可将pt权重文件转化为[‘torchscript’, ‘onnx’, ‘coreml’]三种格式权重文件。
def run(weights='../weights/yolov5s.pt', img_size=(640, 640), batch_size=1, device='cpu',
include=('torchscript', 'onnx', 'coreml'), half=False, inplace=False, train=False,
optimize=False, dynamic=False, simplify=False, opset_version=12,):
"""
weights: 要转换的权重文件pt地址 默认='../weights/best.pt'
img-size: 输入模型的图片size=(height, width) 默认=[640, 640]
batch-size: batch大小 默认=1
device: 模型运行设备 cuda device, i.e. 0 or 0,1,2,3 or cpu 默认=cpu
include: 要将pt文件转为什么格式 可以为单个原始也可以为list 默认=['torchscript', 'onnx', 'coreml']
half: 是否使用半精度FP16export转换 默认=False
inplace: 是否set YOLOv5 Detect() inplace=True 默认=False
train: 是否开启model.train() mode 默认=True coreml转换必须为True
optimize: TorchScript转化参数 是否进行移动端优化 默认=False
dynamic: ONNX转换参数 dynamic_axes ONNX转换是否要进行批处理变量 默认=False
simplify: ONNX转换参数 是否简化onnx模型 默认=False
opset-version: ONNX转换参数 设置版本 默认=10
"""
t = time.time() # 获取当前时间
include = [x.lower() for x in include] # pt文件要转化的格式包括哪些
img_size *= 2 if len(img_size) == 1 else 1 # expand
# Load PyTorch model
device = select_device(device) # 选择设备
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = attempt_load(weights, map_location=device) # load FP32 model
labels = model.names # 载入数据集name
# Input
gs = int(max(model.stride)) # grid size (max stride)
img_size = [check_img_size(x, gs) for x in img_size] # verify img_size are gs-multiples
img = torch.zeros(batch_size, 3, *img_size).to(device) # 自定义一张图片 输入model
# Update model
# 是否采样半精度FP16训练or推理
if half:
img, model = img.half(), model.half() # to FP16
# 是否开启train模式
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
# 调整模型配置
for k, m in model.named_modules():
# pytorch 1.6.0 compatibility(关于版本兼容的设置) 使模型兼容pytorch 1.6.0
m._non_persistent_buffers_set = set()
# assign export-friendly activations(有些导出的格式是不兼容系统自带的nn.Hardswish、nn.SiLU的)
if isinstance(m, Conv):
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# 模型相关设置: Detect类的inplace参数和onnx_dynamic参数
elif isinstance(m, Detect):
m.inplace = inplace
m.onnx_dynamic = dynamic # 设置Detect的onnx_dynamic参数为dynamic
# m.forward = m.forward_export # assign forward (optional)
for _ in range(2):
y = model(img) # dry runs 前向推理2次
print(f"\n{colorstr('PyTorch:')} starting from {weights} ({file_size(weights):.1f} MB)")
# ================================ 转换模型 ====================================
# TorchScript export -----------------------------------------------------------------------------------------------
if 'torchscript' in include or 'coreml' in include:
prefix = colorstr('TorchScript:')
try:
print(f'\n{prefix} starting export with torch {torch.__version__}...')
f = weights.replace('.pt', '.torchscript.pt') # export torchscript filename
ts = torch.jit.trace(model, img, strict=False) # convert
# optimize_for_mobile: 移动端优化
(optimize_for_mobile(ts) if optimize else ts).save(f) # save
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'{prefix} export failure: {e}')
# ONNX export ------------------------------------------------------------------------------------------------------
if 'onnx' in include:
prefix = colorstr('ONNX:')
try:
import onnx
print(f'{prefix} starting export with onnx {onnx.__version__}...') # 日志
f = weights.replace('.pt', '.onnx') # export filename
# convert
torch.onnx.export(model, img, f, verbose=False, opset_version=opset_version,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train, # 是否执行常量折叠优化
input_names=['images'], # 输入名
output_names=['output'], # 输出名
# 批处理变量 若不想支持批处理或固定批处理大小,移除dynamic_axes字段即可
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# print(onnx.helper.printable_graph(model_onnx.graph)) # print
# Simplify
if simplify:
try:
check_requirements(['onnx-simplifier'])
import onnxsim
print(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
# simplify 简化
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(img.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f) # save
except Exception as e:
print(f'{prefix} simplifier failure: {e}')
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'{prefix} export failure: {e}')
# CoreML export ----------------------------------------------------------------------------------------------------
# 注意: 转换CoreML时必须设置model.train 即opt参数train为True
if 'coreml' in include:
prefix = colorstr('CoreML:')
try:
import coremltools as ct
print(f'{prefix} starting export with coremltools {ct.__version__}...')
assert train, 'CoreML exports should be placed in model.train() mode with `python export.py --train`'
model = ct.convert(ts, inputs=[ct.ImageType('image', shape=img.shape, scale=1 / 255.0, bias=[0, 0, 0])]) # convert
f = weights.replace('.pt', '.mlmodel') # export coreml filename
model.save(f) # save
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'{prefix} export failure: {e}')
# Finish
print(f'\nExport complete ({time.time() - t:.2f}s). Visualize with https://github.com/lutzroeder/netron.')
5、使用
三种格式想要用哪种就要下载相应的包:
torchscript 不需要下载对应的包 有Torch就可以
onnx: pip install onnx
coreml: pip install coremltools
然后想要转换哪张格式在opt参数include参数list中中加入对应名字就可以,如:

转换效果
转换前:

转换后:

发现报错:
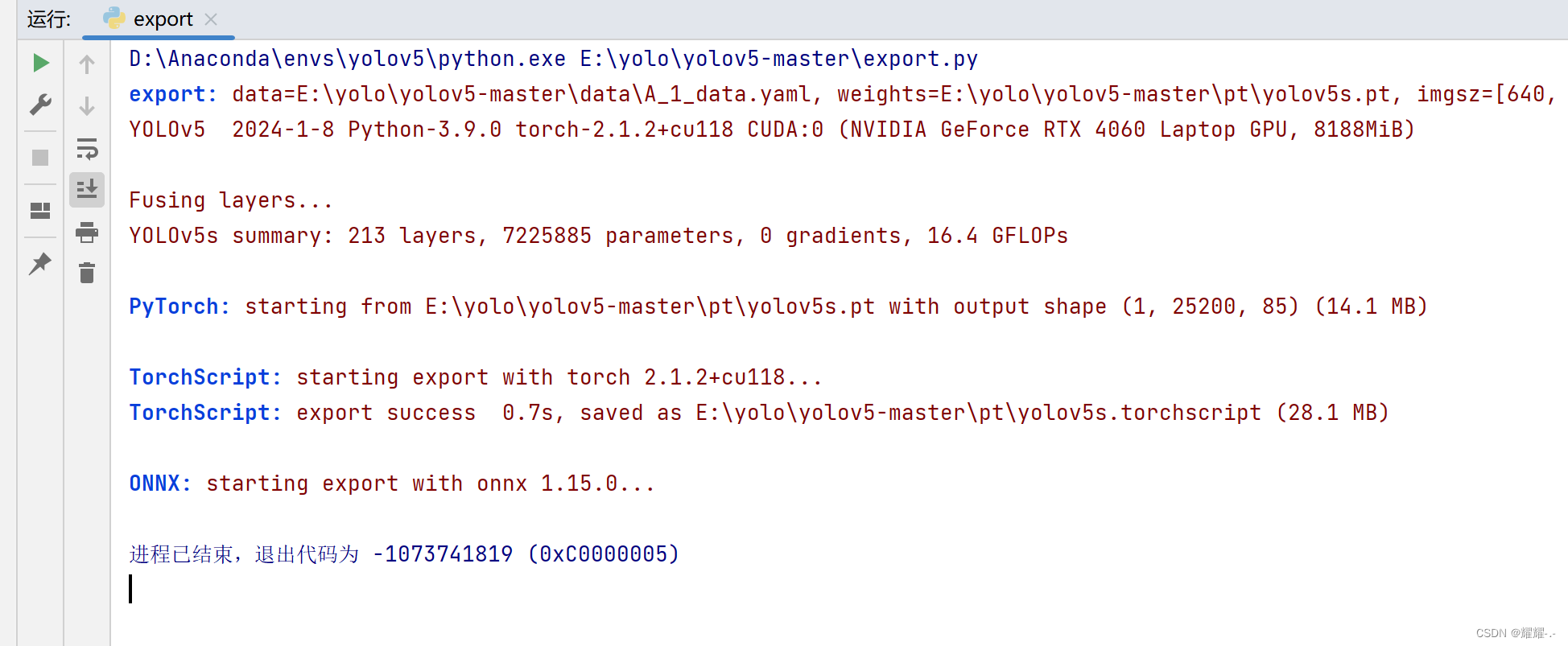
需要将Opset参数default设为15:
把onnx成局部变量设置成全局变量
把onnx包给卸载掉,让yolov5从新安装匹配版本onnx
parser.add_argument("--opset", type=int, default=15, help="ONNX: opset version")执行代码,转换成功:
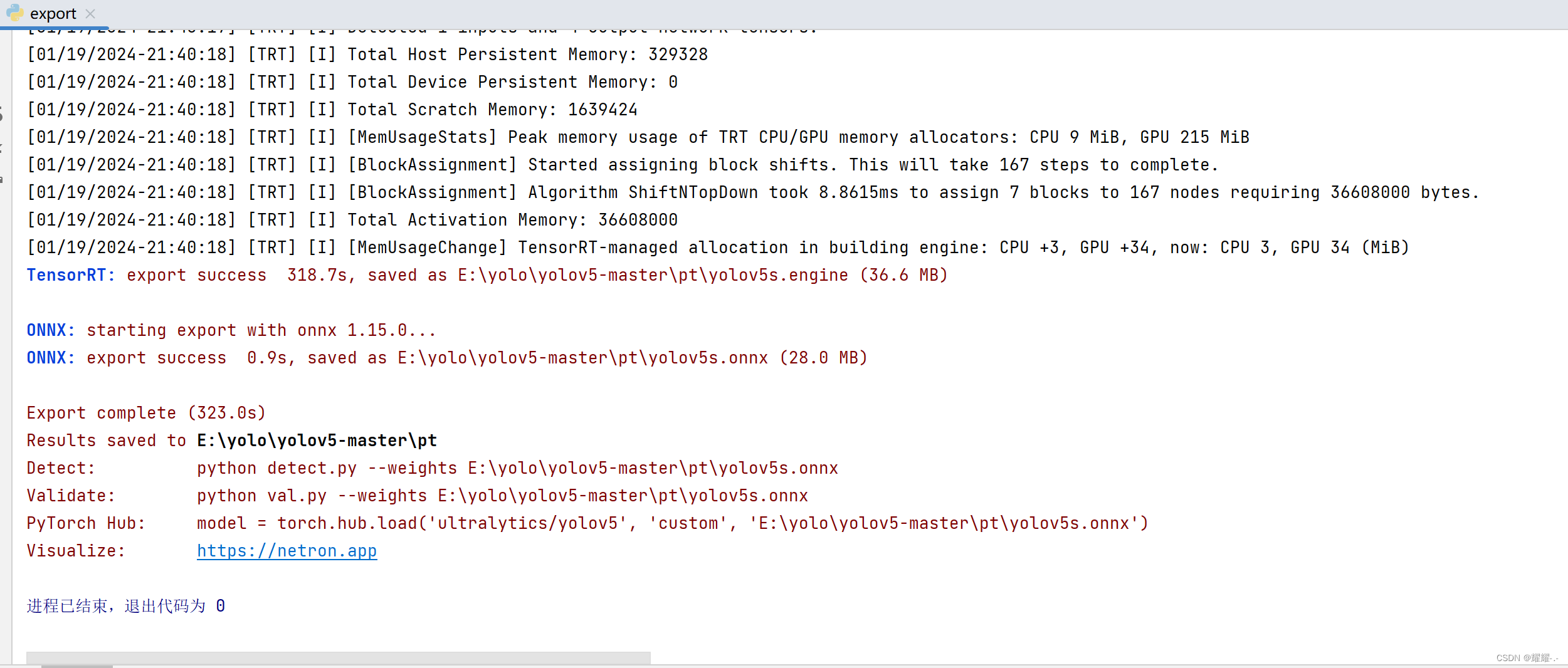
七、总结
确保正确导出onnx文件需要注意以下几个方面:
1:任何用到shape/size返回值的参数时,例如tensor.view(tensor.size(0), -1)这种操作,避免直接使用tensor.size()的返回值,而是加上int强转,例如tensor.view((tensor.size(0)), -1),断开跟踪。
2:nn.Upsample或者nn.functional.interpolate函数,使用scale_factor指定倍率,而不是用size参数指定。
3:reshape/view操作,batch指定为-1,其它通过计算得到。
4:动态batch指定,torch.onnx.export指定dynamic_axes参数,只指定batch维度动态。
5:opset_version=11或11以上版本。
6:避免使用inplace操作,y[..., 0:2] = y[..., 0:2]*2 - 0.5
7:避免出现5个维度,虽然trt对5维度支持比较好,其它框架不一定支持。
8:当执行完以上操作,依然存在gather/shape/Unsqueeze等奇怪的节点,可以尝试使用onnx-simplifer过一遍模型,简化节点。
博客编写不易,求点赞收藏。


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









