







PaddleOCR是一个基于飞桨开发的OCR(Optical Character Recognition,光学字符识别)系统。其技术体系包括文字检测、文字识别、文本方向检测和图像处理等模块。以下是其优点:
高精度:PaddleOCR采用深度学习算法进行训练,可以在不同场景下实现高精度的文字检测和文字识别。
多语种支持:PaddleOCR支持多种语言的文字识别,包括中文、英文、日语、韩语等。同时,它还支持多种不同文字类型的识别,如手写字、印刷体、表格等。
高效性:PaddleOCR的训练和推理过程都采用了高效的并行计算方法,可大幅提高处理速度。同时,其轻量化设计也使得PaddleOCR能够在移动设备上进行部署,适用于各种场景的应用。
易用性:PaddleOCR提供了丰富的API接口和文档说明,用户可以快速进行模型集成和部署,实现自定义的OCR功能。同时,其开源代码也为用户提供了更好的灵活性和可扩展性。
鲁棒性:PaddleOCR采用了多种数据增强技术和模型融合策略,能够有效地应对图像噪声、光照变化等干扰因素,并提高模型的鲁棒性和稳定性。
总之,PaddleOCR具有高精度、高效性、易用性和鲁棒性等优点,为用户提供了一个强大的OCR解决方案。
一、环境安装
1.Anaconda安装
打开Anaconda官网去下载然后安装,这个在网上很多教程根据他们安装就行
2.cuda,cudnn安装
去这里找入口安装对应的cuda和cudnn版本 cuda各个版本的Pytorch下载网页版,模型转化工具,免费gpt链接_cuda国内镜像下载网站-CSDN博客
和yolov5配置跑通基本流程一样
ppocr环境
pip install requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
二、下载训练源码:
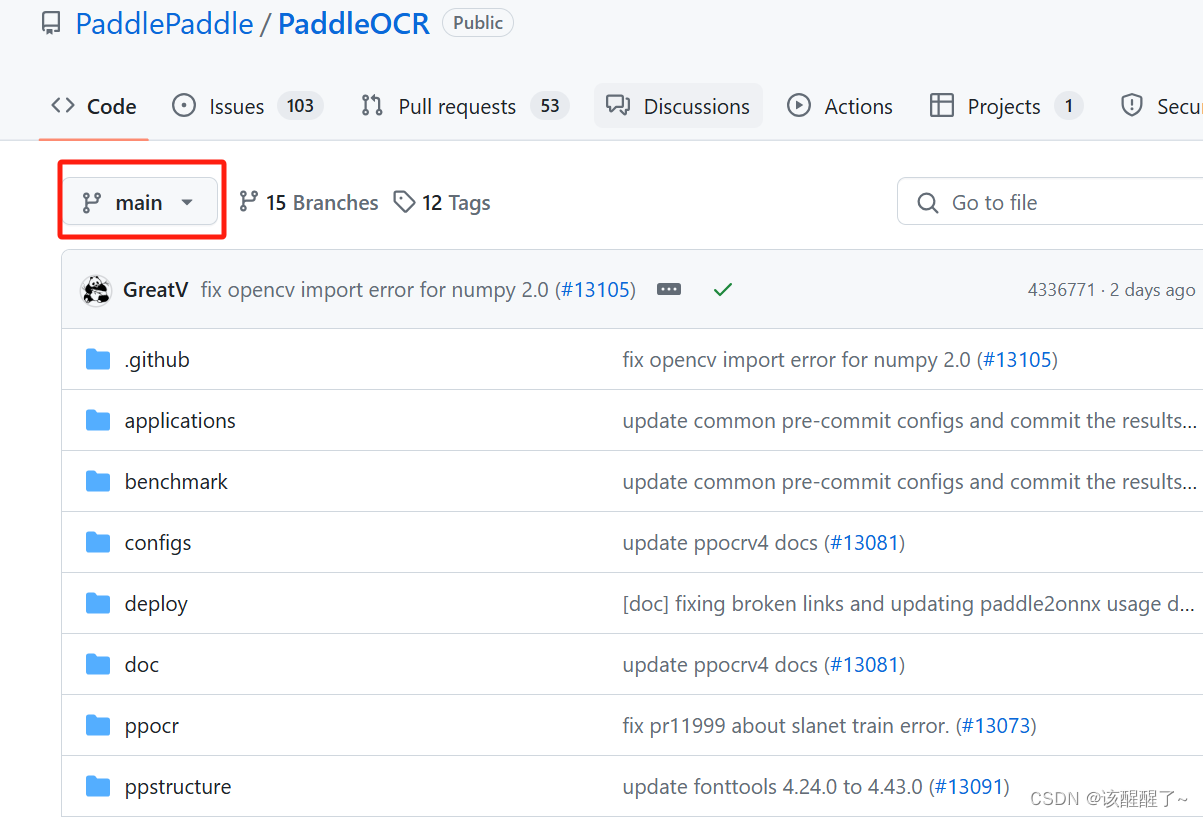
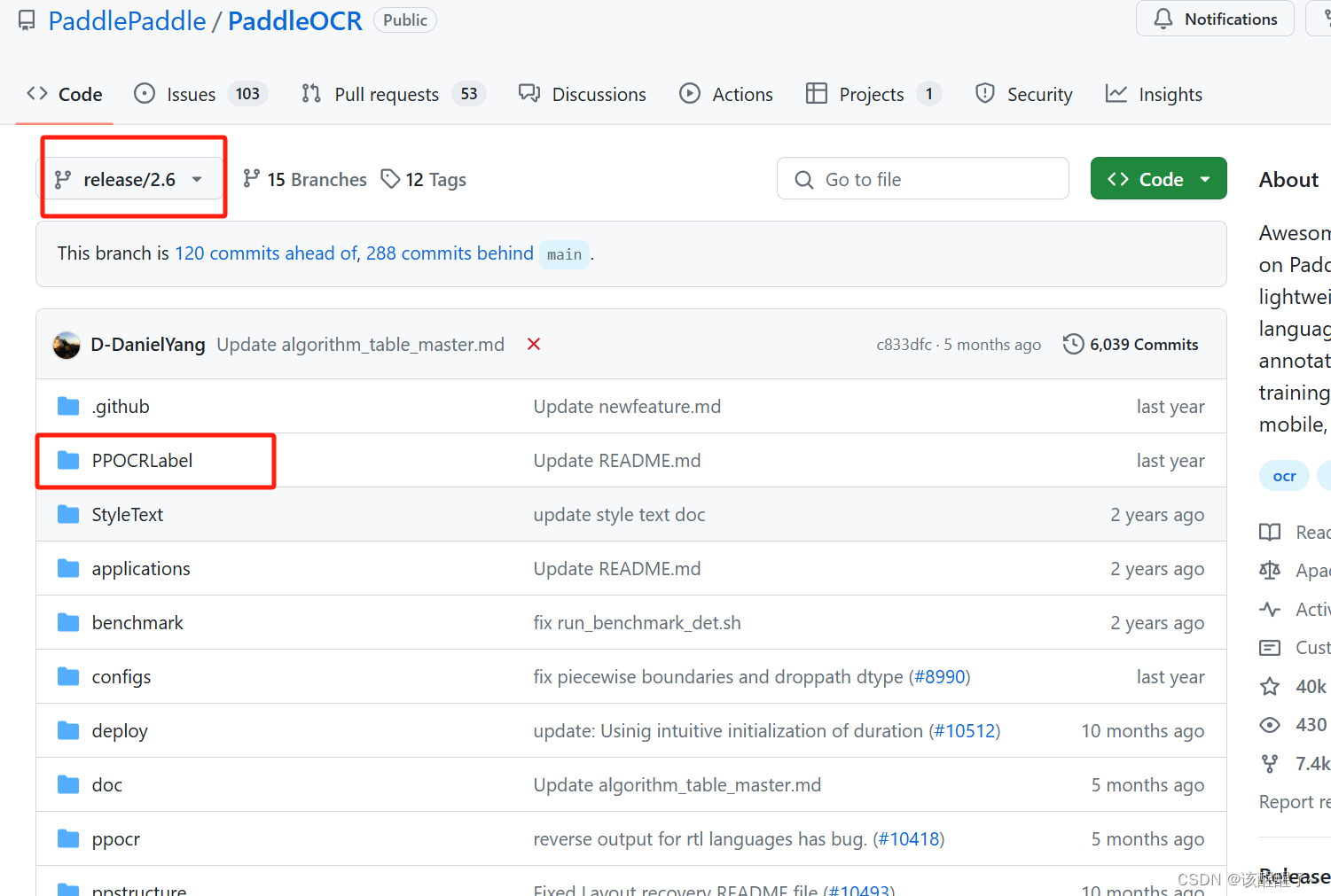
最好下载这个 其他版本可能报错
这个版本的没有标注的程序所以你还需要下载一个r2.6的把里面的PPOCRlabel复制到你下载的main版本的OCR。
验证环境是否跑通
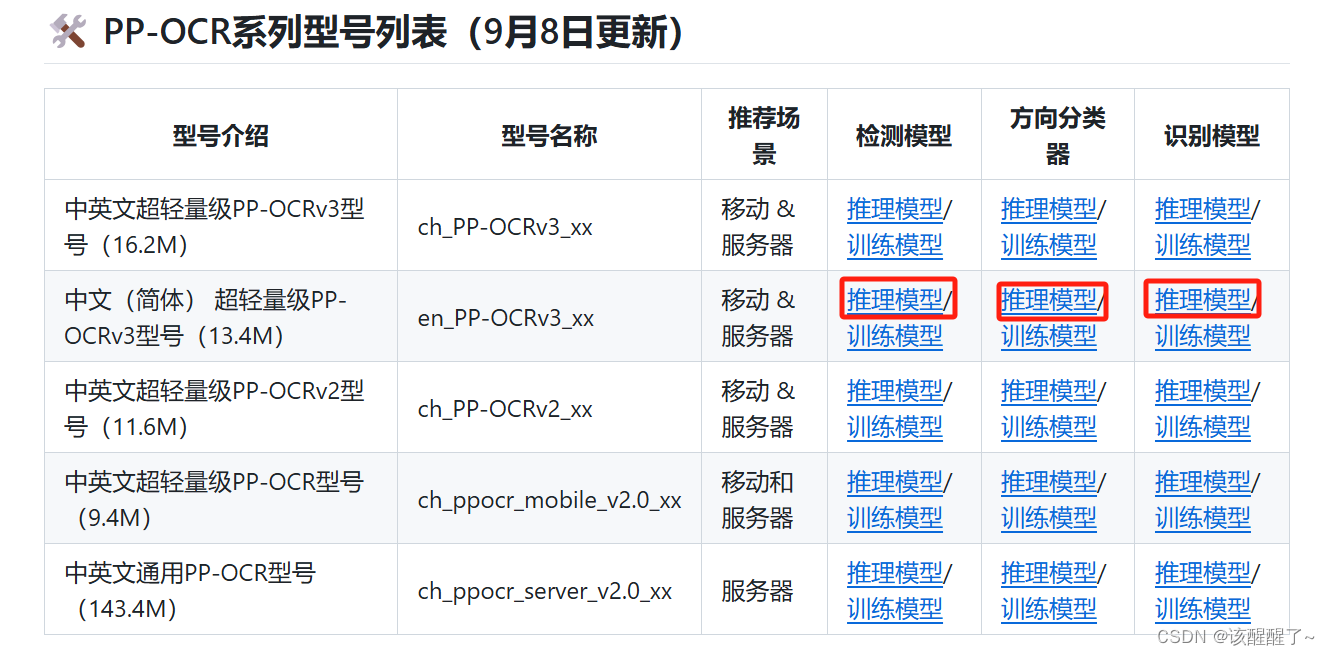
下载压缩然后放到下方文件夹中
打开py终端输入指令
python tools/infer/predict_system.py --image_dir="C:\Users\User\Desktop\test.jpg" --det_model_dir="./inference_model/en_PP-OCRv3_det_infer/" --rec_model_dir="./inference_model/en_PP-OCRv3_rec_infer"效果大概就是这个样子
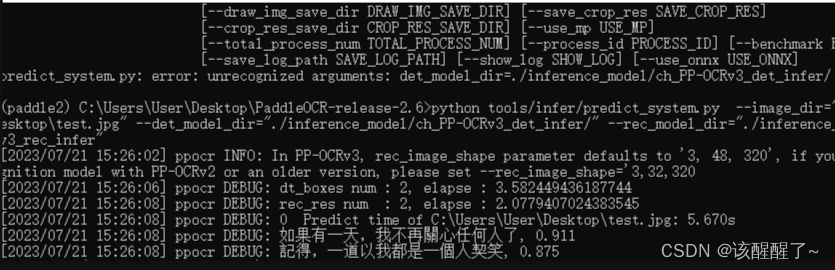
环境没问题的话就可以开始制作自己的数据集训练了
三、数据集制作
如果你的环境没问题,那么进入PPOCRLabel中直接右键运行,
网上又说用这个 python PPOCRLabel.py --lang ch指令的,我用不了这个,报错,所以这个指令用不了的可以直接右键run PPOCRLabel.py 文件即可
如果报错

就在 PPOCRLabel.py 文件头上加入
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"然后右键运行 PPOCRLabel.py
打开后是这样的

导入图片,再点击自动保存
旁边改成你需要标注的字符

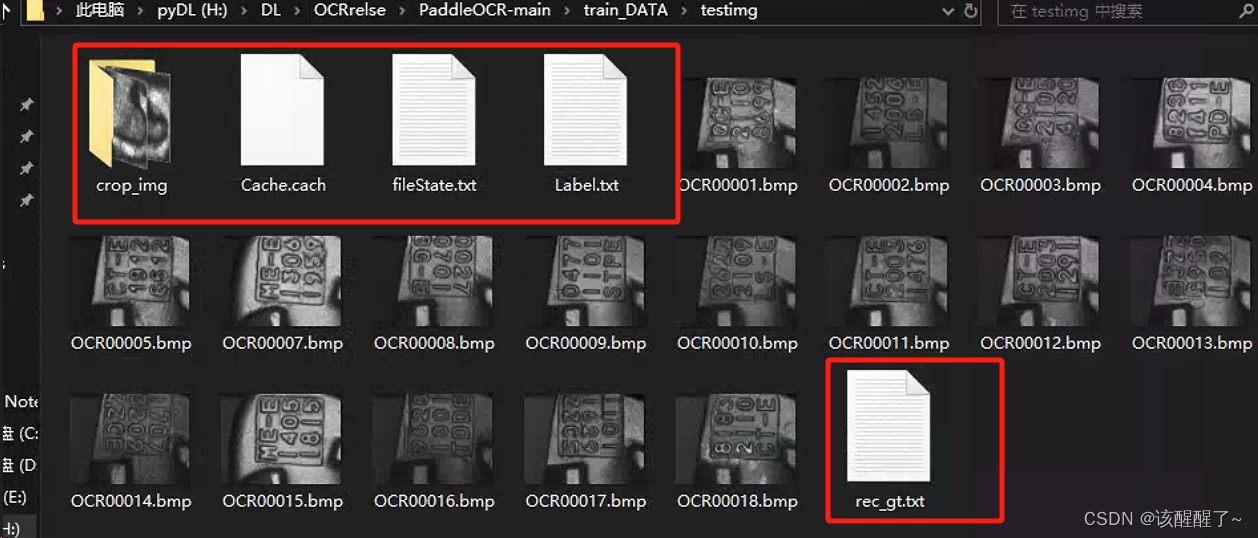
标注后你的数据集文件夹中会生成这些文件
全部打标完成之后,点击文件选择导出标记结果,再点击文件选择导出识别结果,完成后再文件夹多出四个文件fileState,Label,rec_gt, crop_img。
其中crop_img中的图片用来训练文字识别模型,
fileState记录图片的打标完成与否,
Label为训练文字检测模型的标签,
rec_gt为训练文字识别模型的标签。
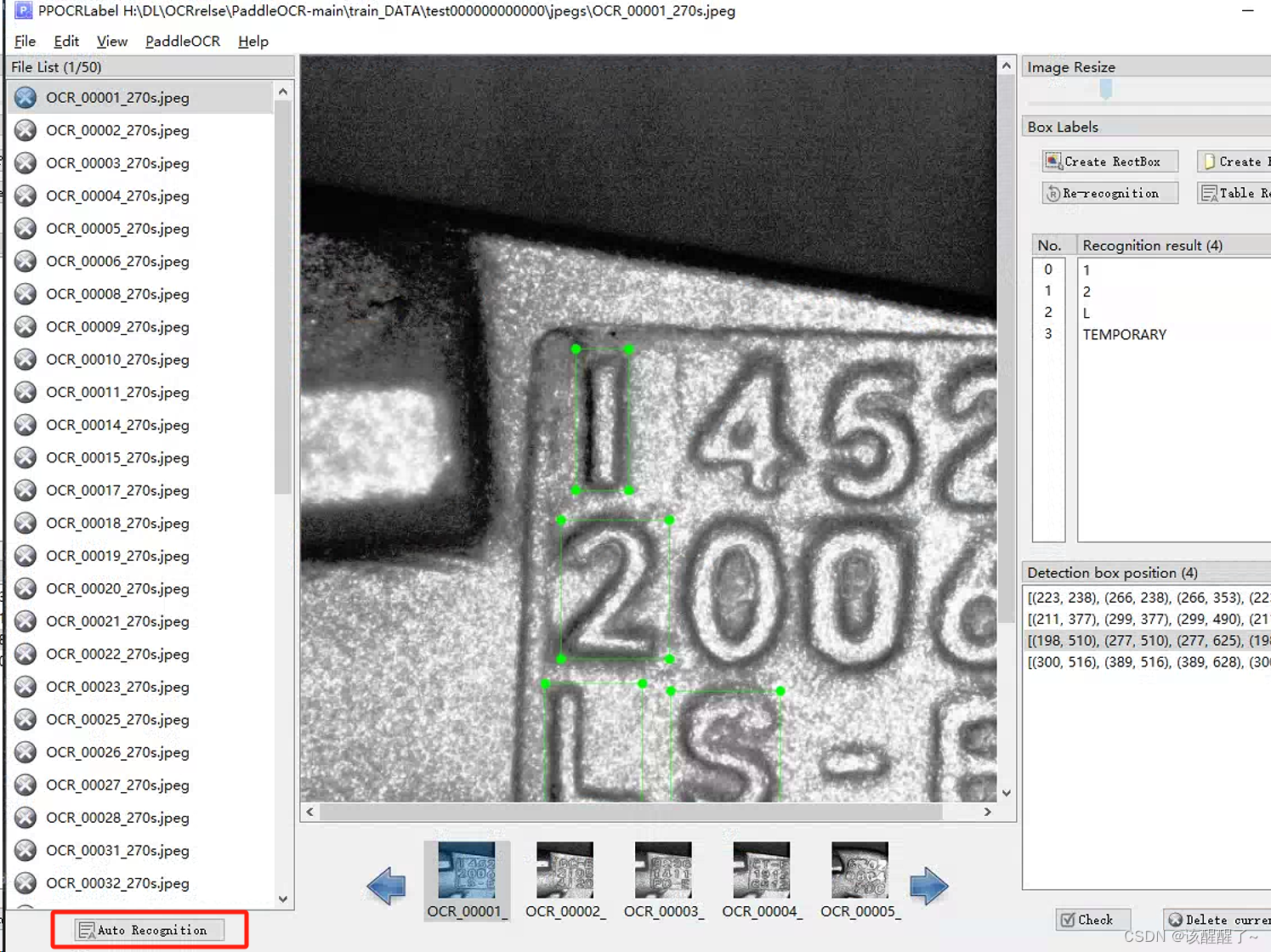
如果是文字文本识别标注那你可以直接点击左下角那里进行自动标注
然后数据集划分
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data/drivingData在终端运行上述指令 文件路劲在PPOCRLabel文件中
运行后数据集就会被划分

生成的det 和rec文件打开后为如下
四、开始训练字符模型
下载训练模型
最好三个都下载下来,也可以只下载检测和识别两个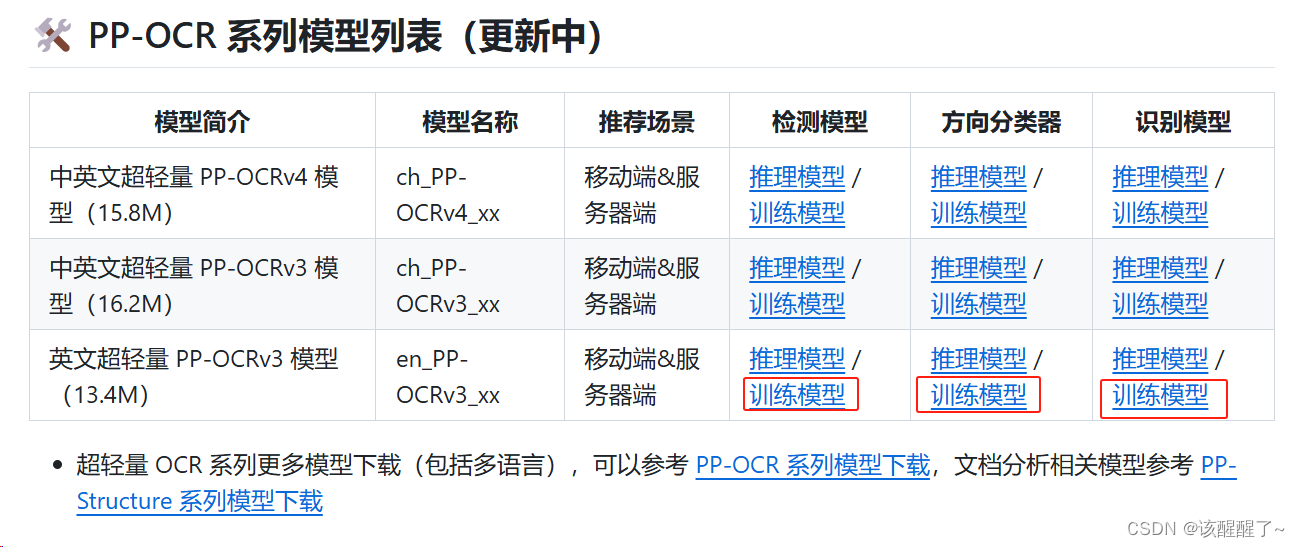
下载好解压,放入
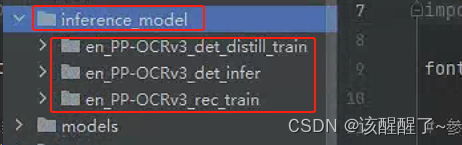
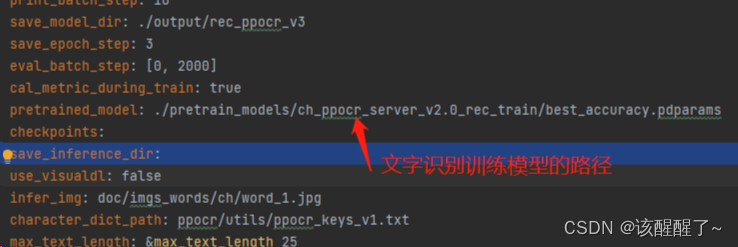
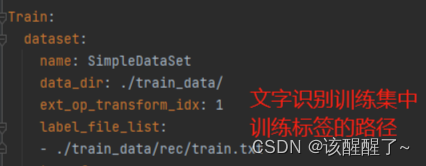
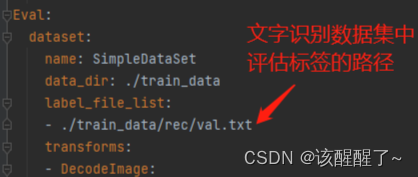
配置训练文件
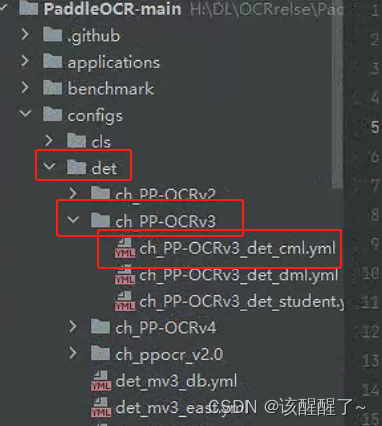
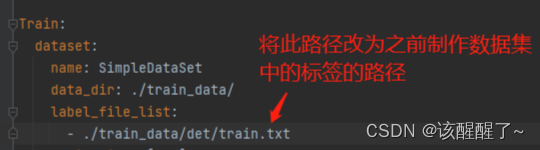
打开后你需要手动修改数据集路径
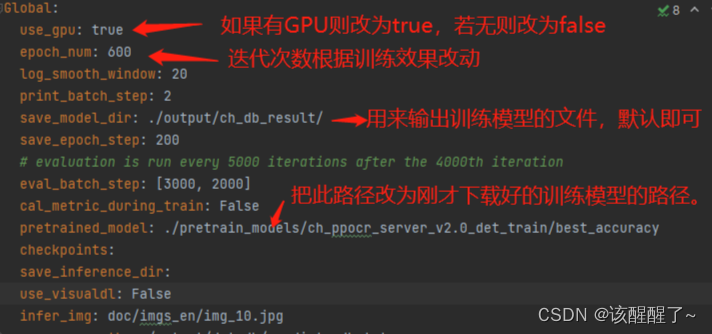
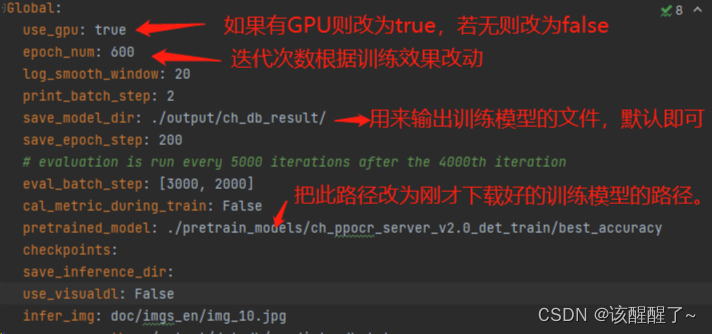
这里有一个是多少代保存一次,你可以设置为一代保存一次 改为1即可

py终端运行如下指令就可以开始运行了
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml
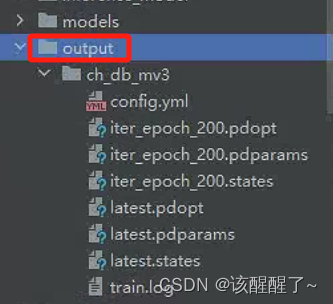
运行完毕了模型会报错在这里
五、测试
python tools/infer_det.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=output/ch_db_driving/iter_epoch_400.pdparams Global.infer_img="C:\Users\User\Desktop\PaddleOCR-release-2.6\train_data\det\test\0201_1 (3).jpg"
六、训练rec识别模型
和上面的检测det模型的训练方式一样
这里更改多少代 保存一次
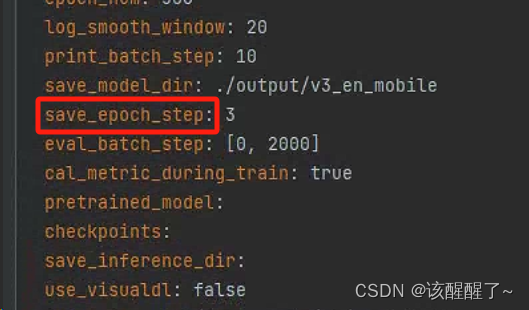
七、运行
python tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml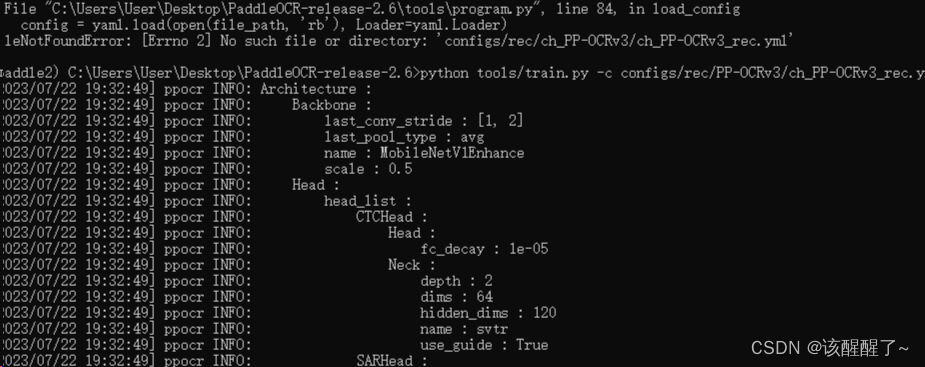
八、然后测试
和上面的方法一样,只是把模型换成rec模型
python tools/infer_det.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=output/en_db_driving/iter_epoch_400.pdparams Global.infer_img="C:\Users\User\Desktop\PaddleOCR-release-2.6\train_data\det\test\0201_1 (3).jpg"
你可以用如下代码进行批量推理和模型测试
中间那个是分类模型 你可以在官网上直接下载
将训练的rec和det模型,转为 推理模型 inf 模型
det模型
python tools/export_model.py -c "./configs/endet_enrec_encls/en_PP_OCRV3_det_cml.yml" -o Global.pretrained_model="./output/det/ch_PP-OCR_v3_det3/latest.pdparams" Global.save_inference_dir="./models/inf_det/"rec模型
python tools/export_model.py -c "./configs/endet_enrec_encls/en_PP_OCRv3_rec.yml" -o Global.pretrained_model="./output/rec/v3_en_mobile_rec4/latest.pdparams" Global.save_inference_dir="./models/inf_rec/"
转完后如下 det中可能是三个文件夹,可以将teacher中的三个模型文件拉出来,或者直接在下方代码中写路径

然后用如下代码进行推理,cls的分类模型可以直接用官方的
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from paddleocr import PaddleOCR, draw_ocr
import os
import skimage
font = cv2.FONT_HERSHEY_SIMPLEX
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="en", use_gpu=False,
rec_model_dir='./models/en_PP-OCRv3_rec_infer/',
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer/',
det_model_dir='./models/en_PP-OCRv3_det_infer/') # need to run only once to download and load model into memory
def OCRsspt_en(img_path,out_path):
for filename in os.listdir(img_path):
img = os.path.join(img_path,filename)
print(filename)
# ims = np.ndarray(range(img))
# img_flor=cv2.imread(ims,flags=1)
# img_flor=Image.open(img)
# img_flor = skimage.io.imread(img)
result = ocr.ocr(img, cls=True)
# 显示结果
image = Image.open(img).convert('RGB')
boxes = [line[0] for line in result[0]]
txts = [line[1][0] for line in result[0]]
scores = [line[1][1] for line in result[0]]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
im_show = Image.fromarray(im_show)
output_path = os.path.join(out_path, f"{os.path.splitext(filename)[0]}s.bmp")
im_show.save(output_path)
print(txts)
print("####################OK#####################")
img_path = "H:\\DL\\OCRrelse\\PaddleOCR-release-2.6\\train_DATA\\jpegs"
out_path = "H:\\DL\\OCRrelse\\PaddleOCR-release-2.6\\inference_results\\dete"
OCRsspt_en(img_path,out_path)
效果如下

九、C#部署(不完善)
官方部署包 https://github.com/sdcb/PaddleSharp
1.你需要下载ocr的包以及其他工具包

将你训练的两个模型导入进去,根据官方的部署包进行修改,读取模型
就像这样
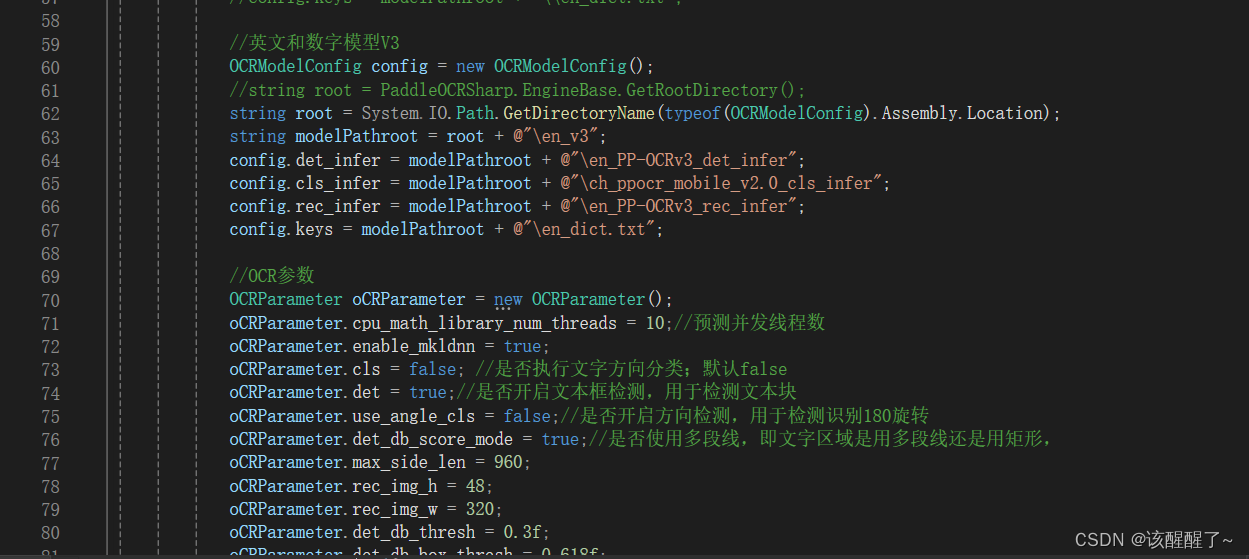
然后就可以进行ocr识别了
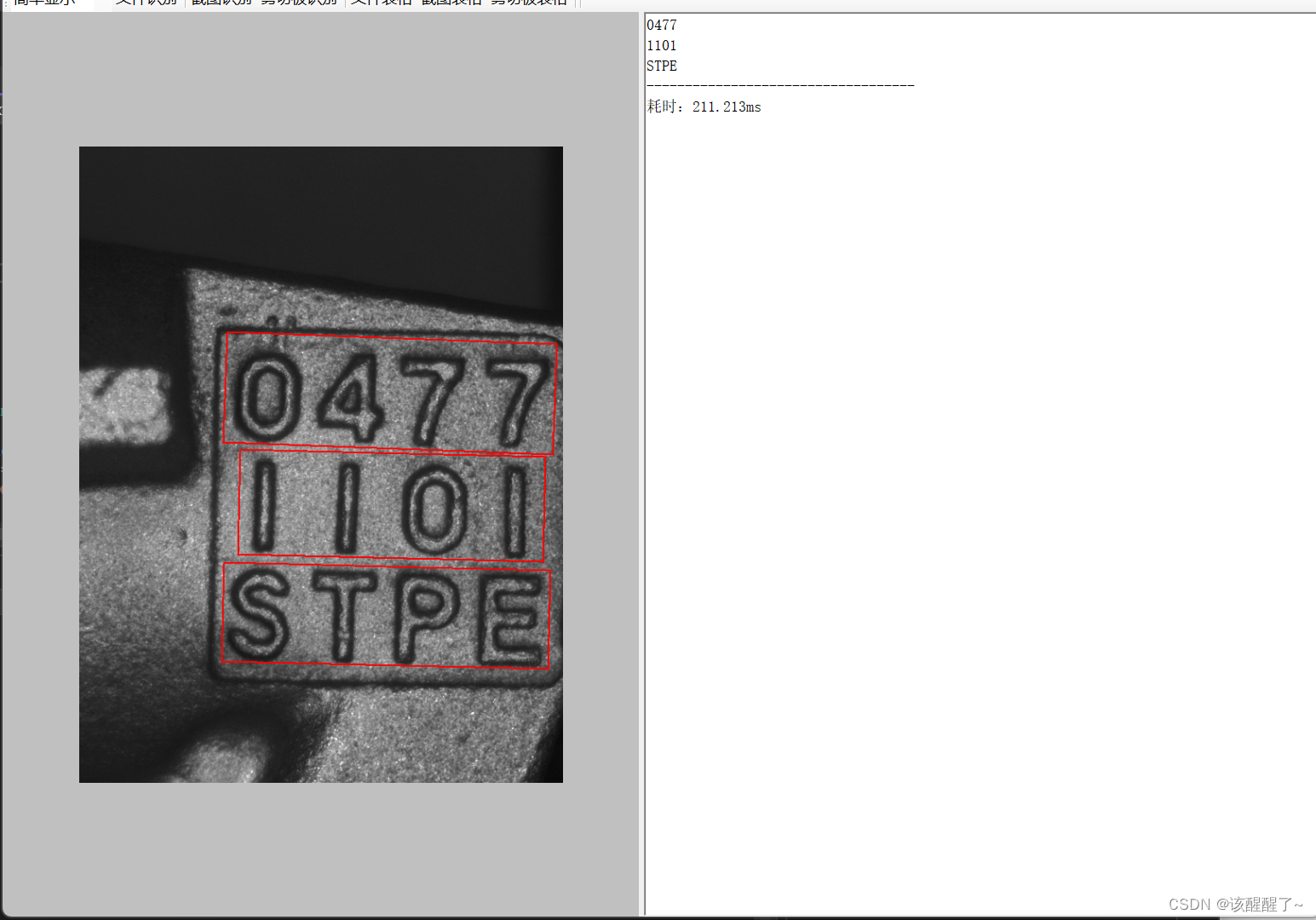
需要其他操作,都可以自己加
















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









