






系列文章目录
第一章:Pyhton机器学习算法之KNN
第二章:Pyhton机器学习算法之K—Means
目录
前言
K-Means,即K均值算法,是聚类算法中最流行的算法之一,属于无监督学习方法,核心任务是对给定的数据集进行数据点的有效分组,使同一群组内的数据点之间具有较高的相似性,而不同群组的数据点之间存在显著的差异。以下是对K-Means算法的详细介绍:
一、基本思想:
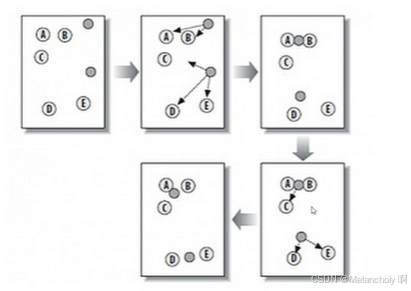
K-Means算法的工作原理基于迭代优化的思想:
- 选择初始聚类中心:算法首先随机选择K个数据点作为初始的聚类中心。
- 分配数据点:接着计算每个数据点到这K个聚类中心的距离,并将数据点分配到距离最近的聚类中心所属的群组。
- 更新聚类中心:然后算法会重新计算每个群组的聚类中心,即计算该群组内所有数据点的平均值,作为新的聚类中心。
- 重复迭代:上述过程会不断重复,直到满足某个终止条件,如聚类中心不再发生显著变化或达到预设的迭代次数。
通过这种方式,K-Means算法能够逐步优化聚类结果,使得同一群组内的数据点更加紧密,而不同群组的数据点更加分散。
二、实现步骤:
K-Means算法的实现可以概括为以下几个关键步骤:
- 选择K值:用户需要确定聚类的数量K,即希望将数据划分为多少个群组。
- 初始化聚类中心:随机选择K个数据点作为初始的聚类中心。
- 分配数据点:计算每个数据点到K个聚类中心的距离,并将数据点分配到距离最近的聚类中心所属的群组。
- 更新聚类中心:对于每个群组,计算该群组内所有数据点的平均值,作为新的聚类中心。
- 重复迭代:重复上述分配和更新的步骤,直到满足终止条件,如聚类中心不再发生显著变化或达到预设的迭代次数。
- 输出结果:最终,算法会输出K个聚类中心以及每个数据点所属的群组信息。
三、基本概念:
聚类:对数据集进行数据点的有效分组,帮助人们更好地理解和汇总数据,进而对数据的各个单元进行精准分类。
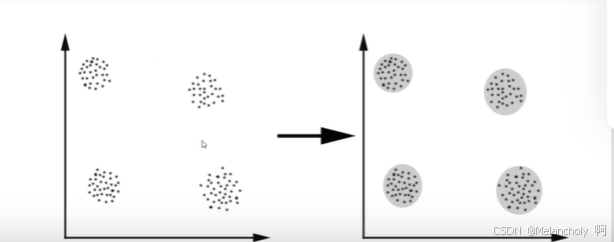
更新聚类中心与重复迭代:对于每个群组,计算该群组内所有数据点的平均值,作为新的聚类中心。重复上述分配和更新的步骤,直到满足终止条件,如聚类中心不再发生显著变化或达到预设的迭代次数。
四、代码实例:
from sklearn.datasets import load_iris
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 加载 Iris 数据集
iris = load_iris()
X = iris.data[:, :2] # 仅选择前两个特征进行可视化
# 注意:这里没有 target 变量用于 KMeans,因为我们是无监督学习
# 但为了可视化原始数据的类别,我们保留 iris.target
y_true = iris.target # 真实标签,用于后续可视化
# 创建 KMeans 模型并拟合数据
kmeans = KMeans(n_clusters=3, random_state=42) # 设置随机种子以确保结果可重复
y_predict = kmeans.fit_predict(X) # 对数据进行聚类并预测标签
# 设置全局字体为黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决坐标轴负号显示问题
plt.rcParams['axes.unicode_minus'] = False
fig,axs=plt.subplots(2,1,figsize=(10,10),dpi=70)
axs[0].scatter(X[:,0],X[:,1],c=y_true)
axs[0].set_title('真实数据')
axs[1].scatter(X[:,0],X[:,1],c=y_predict)
axs[1].set_title('预测数据')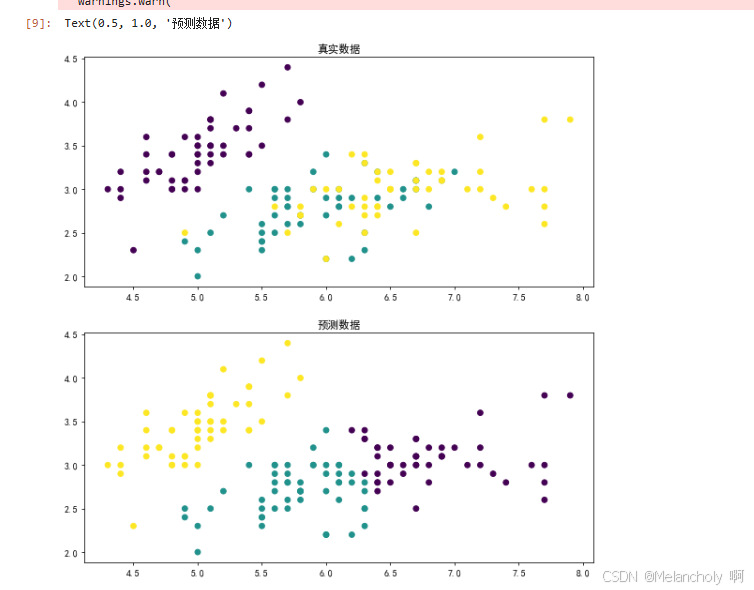
# 创建网格以进行可视化
x = np.linspace(X[:, 0].min(), X[:, 0].max(), 150)
y = np.linspace(X[:, 1].min(), X[:, 1].max(), 150)
xx, yy = np.meshgrid(x, y)
zz = kmeans.predict(np.c_[xx.ravel(), yy.ravel()]) # 预测网格中每个点的聚类标签
zz = zz.reshape(xx.shape) # 重塑 zz 以匹配 xx 和 yy 的形状
# 可视化聚类结果
plt.contourf(xx, yy, zz, cmap='viridis', alpha=0.3) # 使用 alpha 参数使颜色填充半透明
plt.scatter(X[:, 0], X[:, 1], c=y_true, cmap='gray', edgecolor='k', marker='o') # 可视化原始数据的类别
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', marker='x') # 可视化聚类中心
plt.title('KMeans Clustering of Iris Dataset (First 2 Features)')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# 打印聚类中心
print('聚类中心:\n', kmeans.cluster_centers_)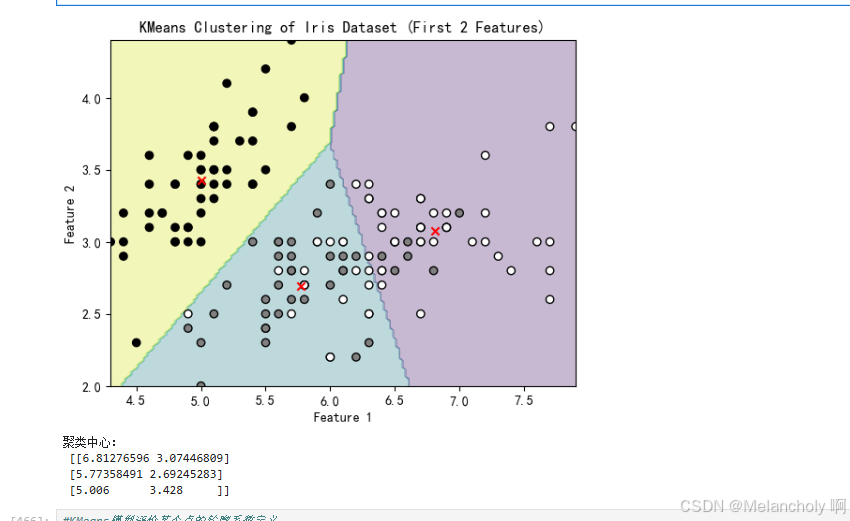
#计算轮廓系数的平均值
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
score= silhouette_score(X,y_predict) #与真实距离越接近 那么轮廓系数越高
score2= silhouette_samples(X,y_predict)
score2.mean()
五、实际案例:
#实战中国足球 数据我之后会上传
data = pd.read_csv(r'D:/data/data.csv',encoding='gbk')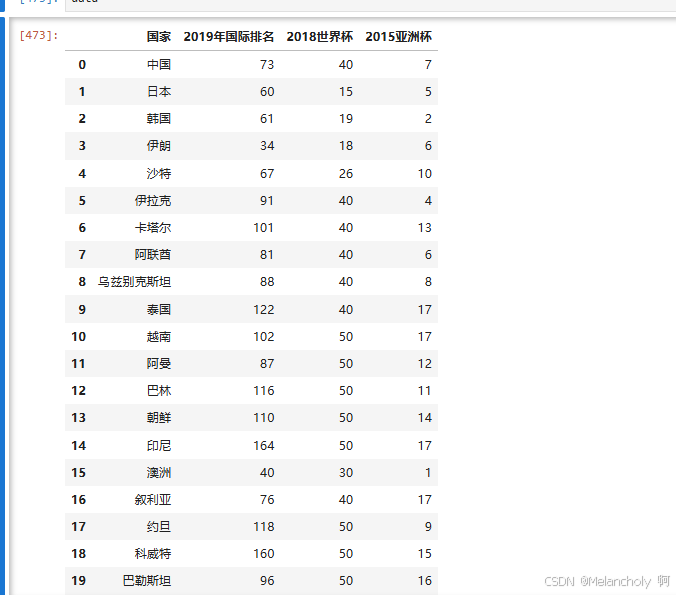
train =data.loc[:,'2019年国际排名':'2015亚洲杯'] #拆分训练集 舍去国家列
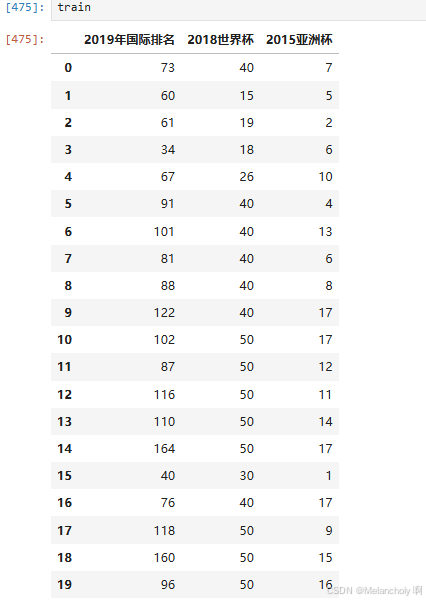
y_predict=kmeans.fit_predict(train) #进行分类预测
for i in [1,2,0]:
country=data['国家'][y_predict ==i]
print(country.tolist())
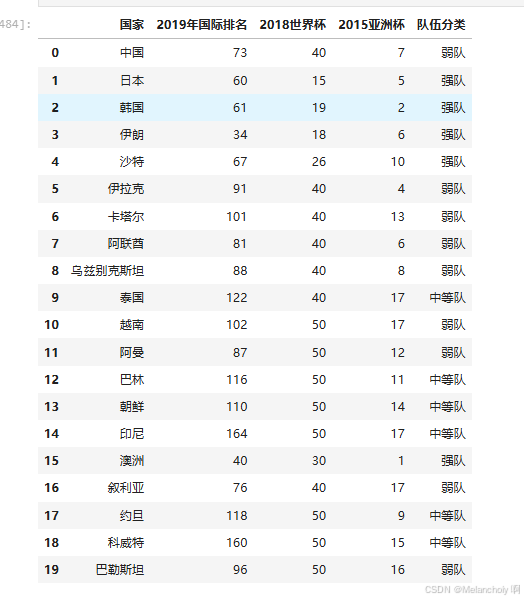
score3= silhouette_score(train,y_predict)data['队伍分类']=y_predict
data['队伍分类']= data['队伍分类'].replace({0:'弱队',1:'中等队',2:'强队'})
plt.scatter(train['2019年国际排名'],train['2018世界杯'],train['2015亚洲杯'],c=y_predict)
center = kmeans.cluster_centers_
plt.scatter(center[:,0],center[:,1],center[:,2],c='red',marker='+')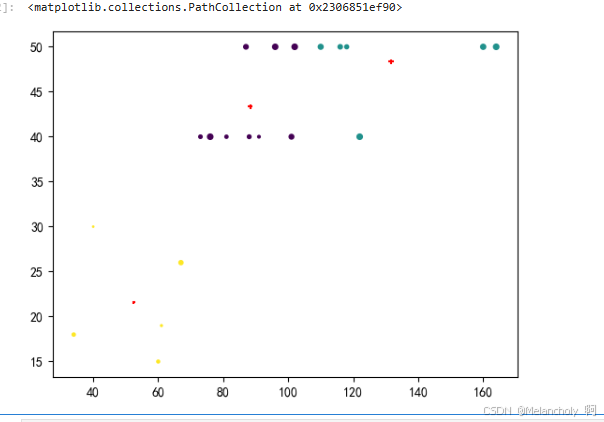
重要参数:
n_clusters:聚类的个数(即簇)
重要属性:
cluster_centers_:[n clusters,n features]的数组,表示聚类中心点的坐标。labels:每个样本点的标签
六、优缺点:
-
优点:
- 算法简单易懂,计算效率高。
- 适用于大规模数据集。
- 能够提供明确的聚类结果,便于后续的数据分析和处理。
-
局限性:
- 对初始聚类中心的选择较为敏感,不同的初始选择可能导致截然不同的聚类结果。
- 需要事先确定K值,这在某些情况下可能较为困难。
- 假设数据点是线性可分的,且每个群组的数据点都服从高斯分布,这在实际应用中可能并不总是成立。
- 对噪声和异常值较为敏感,可能会导致聚类中心的偏移,从而影响聚类结果的准确性。
- 只适用于凸形数据集,对于非凸形的数据集可能无法得到理想的聚类结果。
七、应用场景:
K-Means算法在多个领域都有广泛的应用,包括但不限于:
- 市场营销:企业可以利用K-Means算法对客户进行细分,从而制定更加精准的营销策略。
- 图像处理:K-Means算法可以用于图像分割和颜色压缩。
- 生物信息学:它可以帮助研究人员识别基因表达数据中的不同模式。
- 文本聚类:K-Means算法可以对文本数据进行聚类分析,将相似的文档或单词归为一类。
- 社交网络分析:K-Means算法可用于分析用户的行为模式、兴趣爱好等,将用户聚类为不同的社群,便于个性化推荐和社区管理。
- 物流配送优化:K-Means算法可用于对配送点进行聚类分析,优化配送路径、降低配送成本和提高配送效率。
八、K值选择方法:
选择合适的K值是K-Means算法中的一个关键问题。为了确定最佳的K值,用户可以尝试不同的K值,并利用内部验证的度量方法来评估聚类质量。例如:
- 肘部法则(Elbow Method):通过观察聚类误差平方和(SSE)随K值变化的趋势来确定最佳的K值。
- 轮廓系数(Silhouette Coefficient)和Davies-Bouldin指数:这些度量方法能够帮助用户更加客观地选择合适的K值,从而得到更加准确的聚类结果。(我们目前上面实际案例用的都是轮廓系数进行评估)
九、改进与优化方法:
为了克服K-Means算法的局限性,研究人员提出了多种改进和优化方法:
- K-Means++算法:一种改进的初始化方法,能够更加均匀地选择初始聚类中心,从而减少算法对初始选择的敏感性。
- 并行K-Means算法和分布式K-Means算法:这些方法通过利用并行计算和分布式存储等技术,提高了K-Means算法的计算效率和可扩展性。
- 与其他算法的结合:如与遗传算法、粒子群优化算法等智能优化算法的结合,以进一步提高聚类性能。
总结
综上所述,K-Means算法是一种简单高效的聚类算法,具有广泛的应用场景。然而,它也存在一些局限性,需要在实际应用中根据具体的数据特点和需求进行选择和优化。

















 2252
2252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









