







目录标题
问题描述
在matlab中,如果我们需要对一个数组按一定排序进行重组或者对一些行数进行筛选,我们可以使用 MATLAB 的索引操作。
代码实现
排序
例题一(升降序排序)
data = [5, 1, 3, 8, 2];
% [sortedData, sortedIndex] = sort(data);%升序排序
[sortedData, sortedIndex] = sort(data,'descend');%降序排序
rearrangedData = data(sortedIndex);
disp(rearrangedData);
在这个例子中,我们按行对矩阵进行排序,并使用 sortedIndex 对矩阵进行索引操作,得到按行排序后的矩阵。
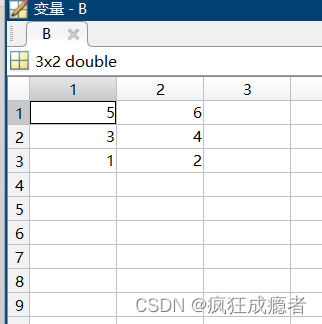
例题二(颠倒排序)
A=[1,2;3,4;5,6];
i=[3;2;1];
B=A(i,:);
例题三(字符串中包含数字排序)
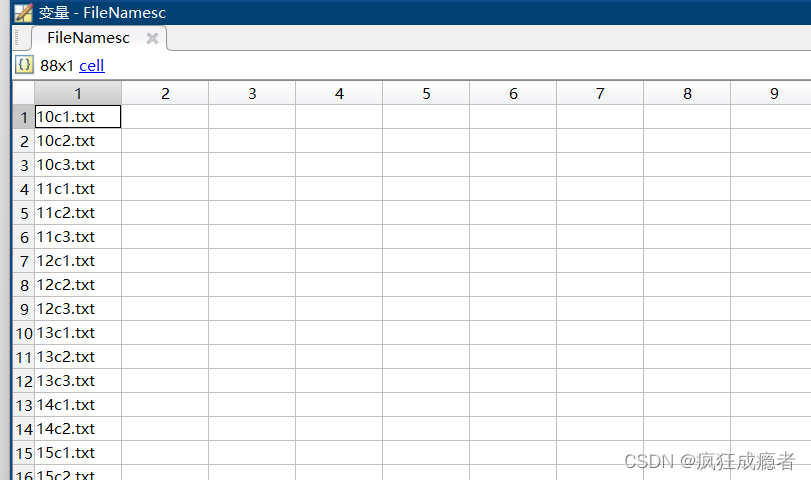
for ii = 1:cc
pattern = '(\d+)';
matches = regexp(FileNamesc, pattern, 'tokens');
tem2= matches{ii};
ccz(ii,1)=str2double(tem2{1});
end
[C, idxc] = sort(ccz);
cxFileNames=FileNamesc(idxc);
我们需要把这组数据按照数字大小进行升序排序。
1.使用正则化提取文章中的数字。
2.使用 sort函数进行沈旭排序,并使用 idxc 对矩阵进行索引操作,得到按行排序后的矩阵。
例题四(把一列数据转化为矩阵形式)
方法一
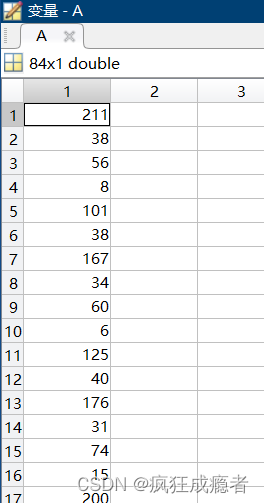
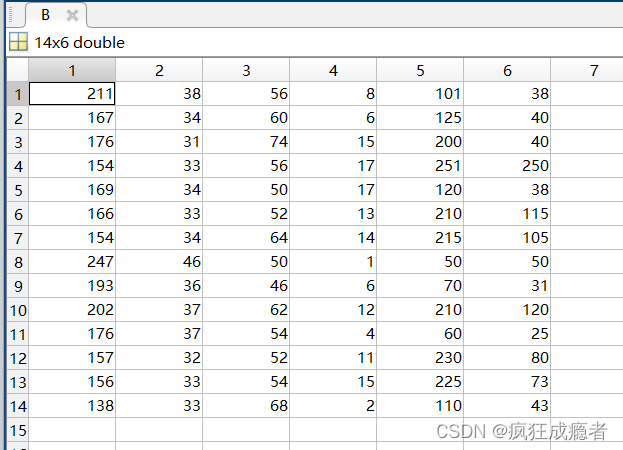
A为841矩阵,我们把A转化为B146的矩阵
代码
% clc,clear
B=[],b=ones(6,1);
for j=0:13
for i=1:6
a=6*j+i;
b(i)=A(a,:)';
end
B=[B,b];
end
B=B';
方法二
reshape(x,4,5)'
构造矩阵
构造如图矩阵:

代码:
A=zeros(5,20);
for i=1:5
for j=1:4
d=j+(i-1)*4;
A(i,d)=1;
end
end
repmat函数(重复数组)
筛选
数据提取
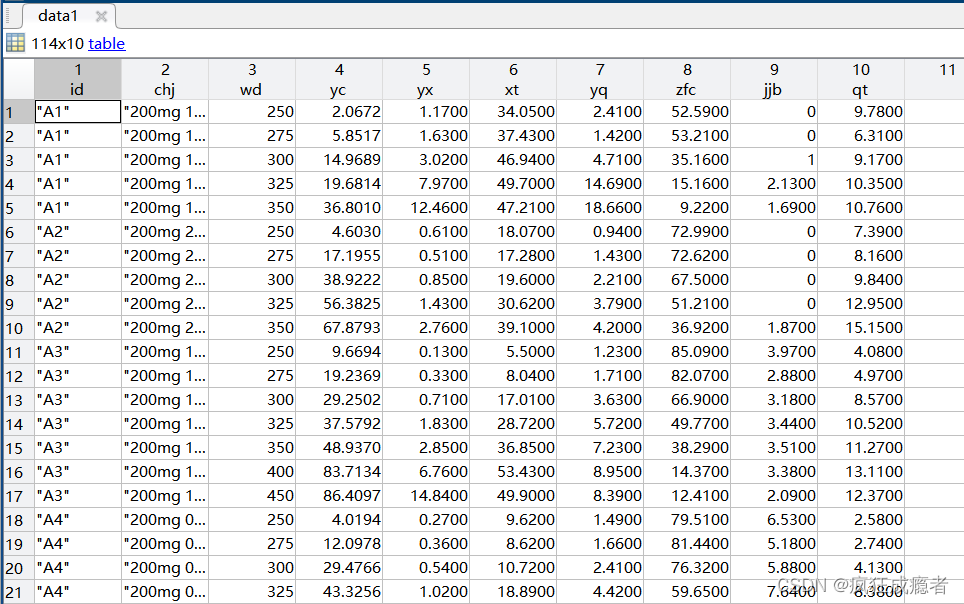
我们需要对data1数据提取ind行作为一个新组AA。

代码实现:
AA=data1(ind,:);
结果:
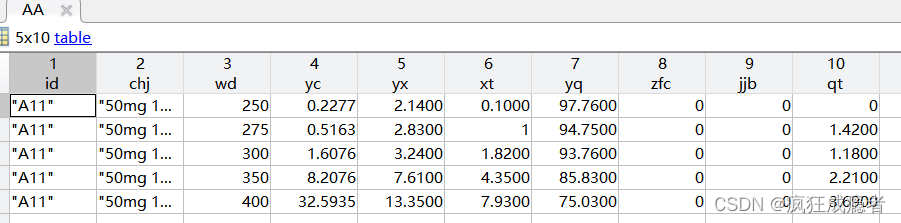
对表格具有特定属性的样本进行操作
% 删除特定属性的行
clc,clear
opts = spreadsheetImportOptions("NumVariables", 5);
opts.Sheet = "Sheet1";
opts.DataRange = "B2:F155";
opts.VariableNames = ["VarName2", "VarName3", "VarName4", "VarName5", "VarName6"];
opts.VariableTypes = ["double", "double", "categorical", "categorical", "double"];
Untitled = readtable("整理的数据.xlsx", opts, "UseExcel", false);
clear opts
A=Untitled(1:20,:);
B=A;
B(B.VarName4=="云南生菜" | B.VarName2==0.338,:) = [];
数据删除
我们需要将data1数据ind进行删除,代码实现:
data1(ind,:) = [];
%data1([55,56,57,58,59],:)%或者
data1
数据筛选
我们需要得到,data2相加介于85~105之间的数据。
ss = sum(tmp,2);% sum(A,2) 每一行求和
idx = find((ss < 85 ) | (ss > 105));%|或
data2(idx,:) = [];
数据透视表
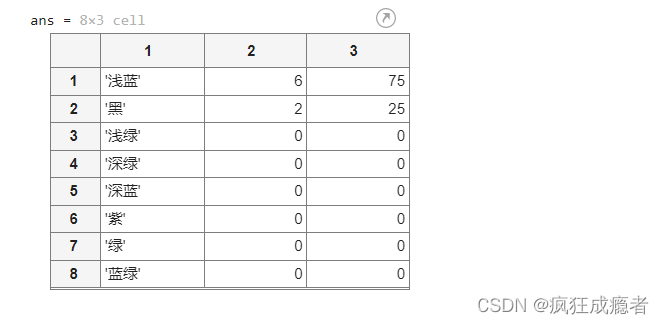
tmp1 = data1(data1.bmfh=='风化' & data1.lx=='铅钡' & data1.ws=='A' ,:);%找到满足这三点要求的数据
tabulate(tmp1.ys)%写出所以颜色对应出现的次数,比率
sortrows(tabulate(tmp1.ys),2,'descend') %对行进行排序,descend降序
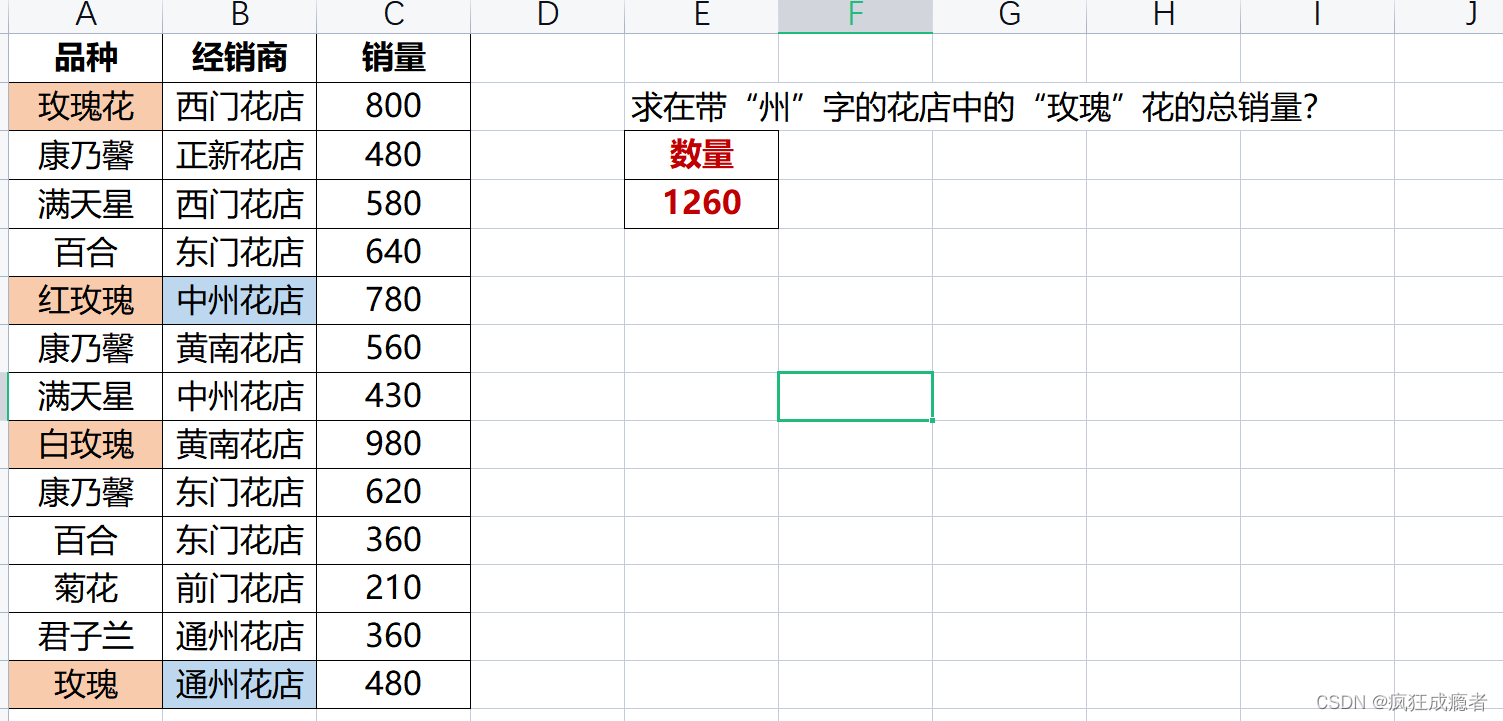
精确查找
clc,clear
shuju = readtable("D:\my_document\latex\markdown\shuju.xlsx");
tem=shuju{:,2};
id=find(tem=="西门花店");
A=shuju(id,:);
find函数
1.取特定几个数
X = magic(4)
k = find(X<10,5)
找到矩阵中小于10的前五个索引
2.查找后四个非零值。
k = find(X,4,'last')
3.返回行和列
X = [18 3 1 11; 8 10 11 3; 9 14 6 1; 4 3 15 21]
[row,col] = find(X>0 & X<10,3)


4.找到矩阵中最小值坐在的行与列
min_sse = min(min(SSE));
[r,c] = find(SSE == min_sse,1);
数组分类(根据包含特定字符分类)
例题一
要判断一个 cell 数组中是否包含特定的单词(字符串),你可以使用循环遍历每个 cell 元素,并使用字符串处理函数来判断每个单元格中是否包含该单词。以下是一个示例:
% 创建一个包含字符串的 cell 数组
cellArray = {'This is a sample string.', 'Another cell.', 'No c here.', 'Contains c.'};
wordToFind = 'c';
% 初始化一个标志变量
found = false;
% 遍历每个 cell 元素
for i = 1:numel(cellArray)
if contains(cellArray{i}, wordToFind)
found = true;
break; % 一旦找到,就可以退出循环
end
end
if found
disp('The word c is present in the cell array.');
else
disp('The word c is not present in the cell array.');
end
例题二

我们将FileNames进行分类,区分出包含c和d字符串数组。
FileNames如图所示。
n = length(FileNames);
cc=0;
dd=0;
FileNamesc={};
FileNamesb={};
for ii=1:n
tem1= FileNames(ii);
wordToFind = 'c';
found = false;
for i = 1:numel(tem1)
if contains(tem1{i}, wordToFind)
found = true;
break;
end
end
if found
cc=cc+1;
FileNamesc(cc,1)=FileNames(ii);
else
dd=dd+1;
FileNamesb(dd,1)=FileNames(ii);
end
end
注释:
1.定义cell数组FileNamesc={},数值数组定义为格式为:FileNamesc=[]。
2.tem1= FileNames(ii);取第
i
i
ii
ii个元素进行判断。
3.wordToFind = ‘c’;为区分的元素。
4.FileNamesc(cc,1)=FileNames(ii);cell数组和cell数组之间转化用(),cell转化为double用{}。
eg:
例子三(分类字符在开头 startsWith函数)
str = ["abstract.docx","data.tar","code.m"; ...
"data-analysis.ppt","results.ptx","summary.ppt"]
pat = "data";
TF = startsWith(str,pat)















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









