






 本文介绍了如何在数据分析中处理定量和定性数据,包括数据导入、清屏、描述性统计、多元回归模型建立(包括R2、调整R2、显著性检验和多重共线性处理)、异方差检验以及使用Stata进行逐步回归。重点讨论了方差膨胀因子和稳健标准误的应用,以及标准化回归在特定情境下的使用。
本文介绍了如何在数据分析中处理定量和定性数据,包括数据导入、清屏、描述性统计、多元回归模型建立(包括R2、调整R2、显著性检验和多重共线性处理)、异方差检验以及使用Stata进行逐步回归。重点讨论了方差膨胀因子和稳健标准误的应用,以及标准化回归在特定情境下的使用。
文章目录
导入数据
import excel "D:\my_document\数学建模\清风\清风代码\第7讲.多元回归分析\第7讲.多元回归分析\代码和例题数据\课堂中讲解的奶粉数据.x
lsx", sheet("Sheet1") firstrow
清屏
cls clear
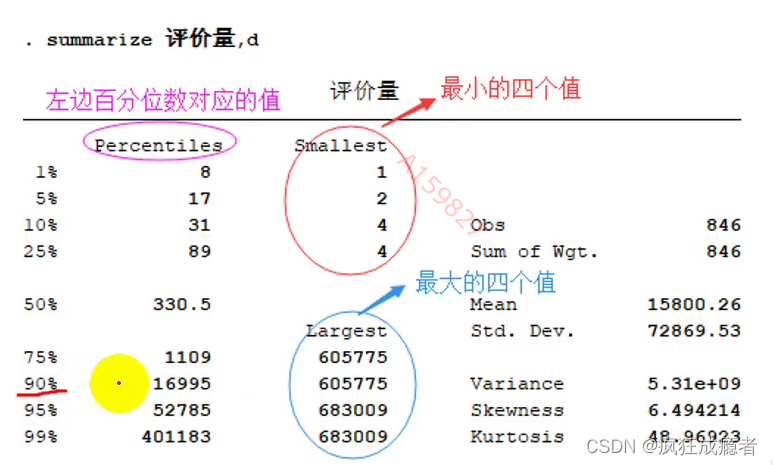
分为定量数据(summarize)
summarize
有数字

obs:样本量
mean:均值
std:标准差
最小最大值
定性数据
tabulate 变量名,gen(A)
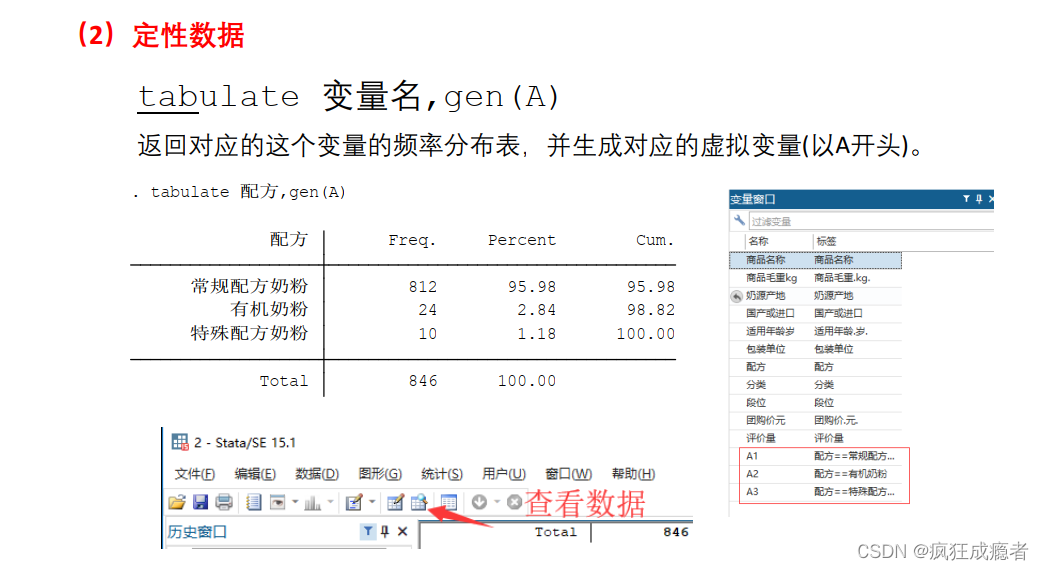
Freq:频数
percent:比率
cum:累计频率
多元回归分析(定量)
regress y x1 x2 … xk
回归只引入定量
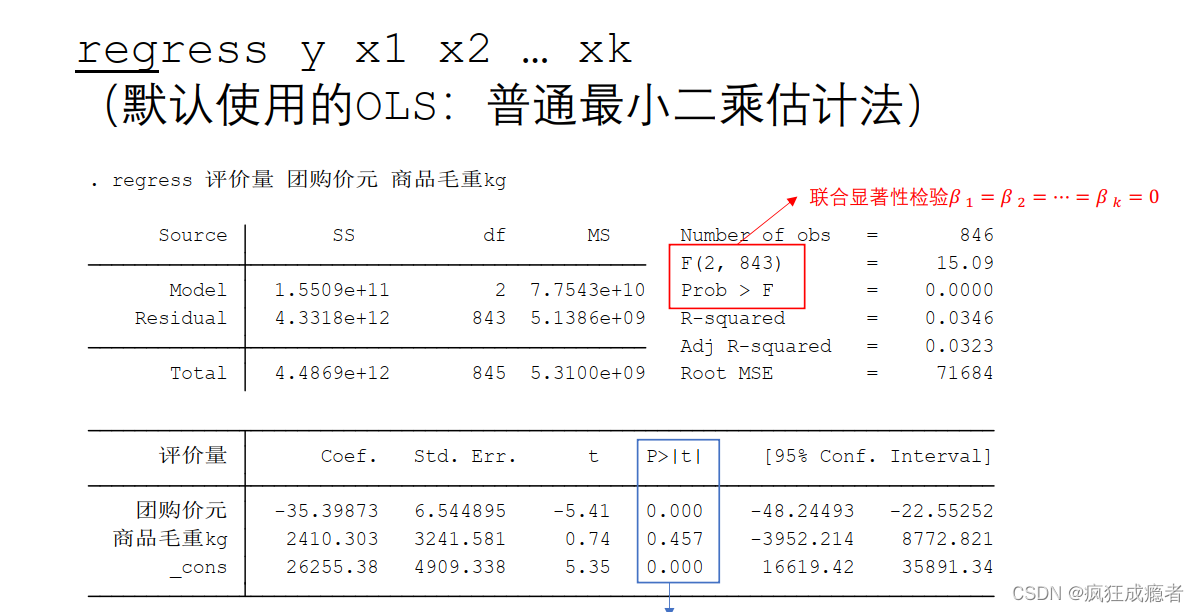
Model:SSR 回归评分和
Residual:SSE 误差平方和
Total:SST
拟合优度:
R
2
R^2
R2=SSR/SST
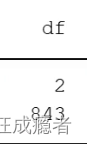
df:自由度
引入调整后
R
2
R^2
R2:

联合显著性检验

注释:
1.number of obs:观测值的个数n
2.F(2,843)代表联合显著性检验,15.06为检验值,检验值值为F统计量构造出来,F统计量第一个自由度为2,第二个自由度为
843。
即为这两个自由度:
其对应的p值为0.00。
看清一个假设一定要知道三个东西:
1.构造出来的统计量为什么统计量,(比如这位F统计量)
2.看统计量对应的p值。
3.
H
0
H_0
H0:联合显著性检验,
β
1
=
β
2
=
⋯
=
β
k
=
0
\beta_1=\beta_2=\cdots=\beta_k=0
β1=β2=⋯=βk=0,
检验k个自变量前面的回归系数是否都为0,(看p值是否大于0.05),
如果p值大于0.05,则下结论,则我们回归不能拒绝原假设,则认为回归无多大的意义。(即回归自变量系数都为0),即模型设定不合理。
联合显著性通过,即p值是否小于等于0.05,我们拒绝原假设,我们认为回归模型有一定意义。

显著性
显著性水平是一个事先指定的概率阈值,通常表示为α。常见的显著性水平包括0.05(5%)和0.01(1%),这意味着 只有当样本数据产生的结果具有非常低的概率(低于0.05或0.01)时,才会认为结果是显著的。如果计算出的P值小于显著性水平α,则认为结果是显著的,拒绝原假设**;如果P值大于α,则认为结果是不显著的,没有足够的证据来拒绝原假设。
调整后 R 2 R^2 R2
R
2
R^2
R2和调整后
R
2
R^2
R2
在论文中我们需要加入调整后
R
2
R^2
R2而不是
R
2
R^2
R2,
加入这句话:
Root MSE:均方误差。
回归系数表以及它们对应的p值
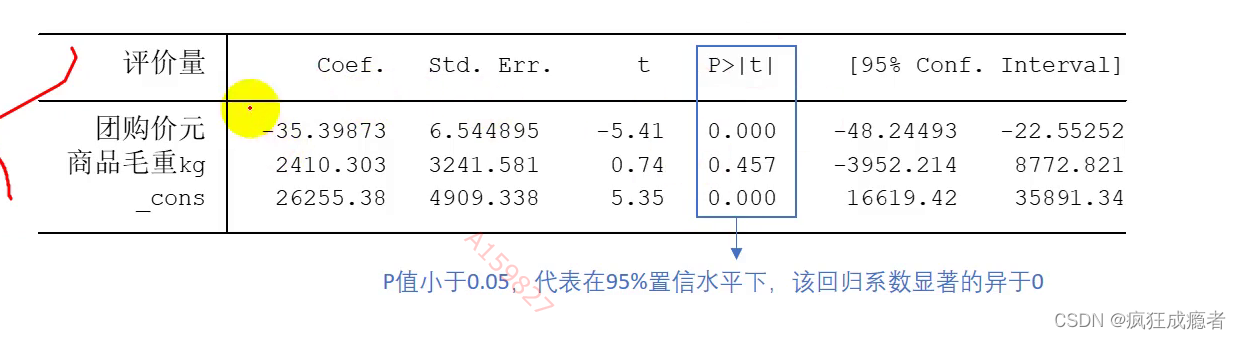
cons:第一列代表常数项,
β
0
,
β
1
,
⋯
\beta_0,\beta_1,\cdots
β0,β1,⋯
β
0
^
\hat{\beta_0}
β0^为26255.38,
β
1
^
\hat{\beta_1}
β1^为2410.303(代表商品毛重的系数)。
β
1
^
x
+
β
2
^
x
+
β
3
^
x
+
⋯
\hat{\beta_1}x+\hat{\beta_2}x+\hat{\beta_3}x+\cdots
β1^x+β2^x+β3^x+⋯
std.err:第二列代表回归系数对应的标准误差,(标准误用于计算t值)。
−
35
6
≈
−
5
\frac{-35}{6}\approx-5
6−35≈−5
t检验统计量即为回归误除以标准
P值:t检验对应的p值
检验
β
1
\beta_1
β1是否等于0,
因为商品毛重p值大于0.05,所以不用分析它,因为它不显著,
wom只分析回归中显著的量。
置信区间
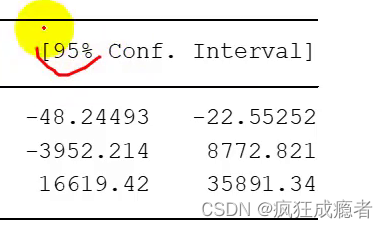
95%代表有百分之九十五系数落在这个区间内。
cons第一列是点估计,上图为区间估计。
只有关注第一列和p值。
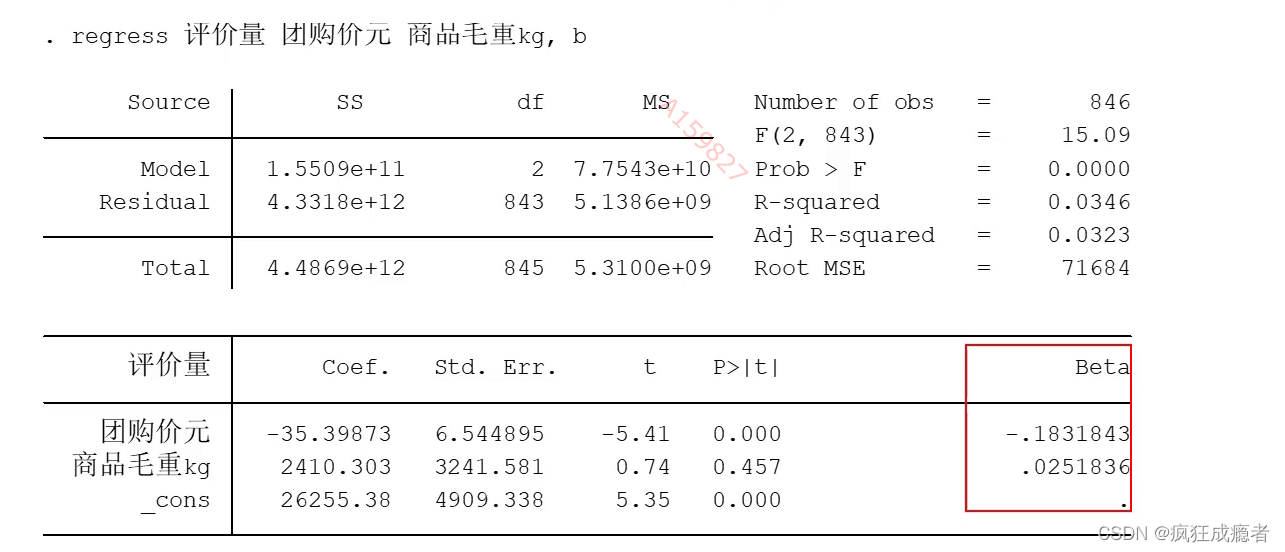
多元回归分析(定性)(既有虚拟变量)
定性分析(设置虚拟变量)
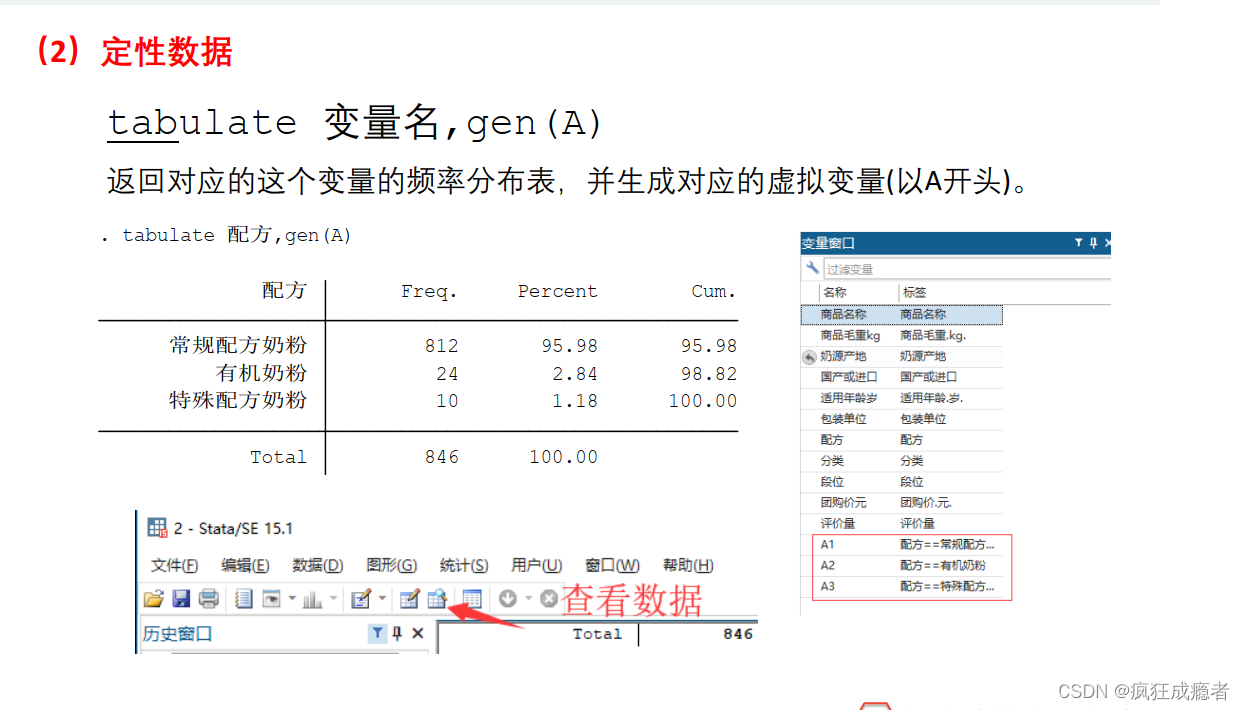
代码:
tabulate 配方,gen(A)
tabulate 奶源产地 ,gen(B)
tabulate 国产或进口 ,gen(C)
tabulate 适用年龄岁 ,gen(D)
tabulate 包装单位 ,gen(E)
tabulate 分类 ,gen(F)
tabulate 段位 ,gen(G)
输出结果为:

表示:G4被忽略了,因为完全多重共线性
为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1。

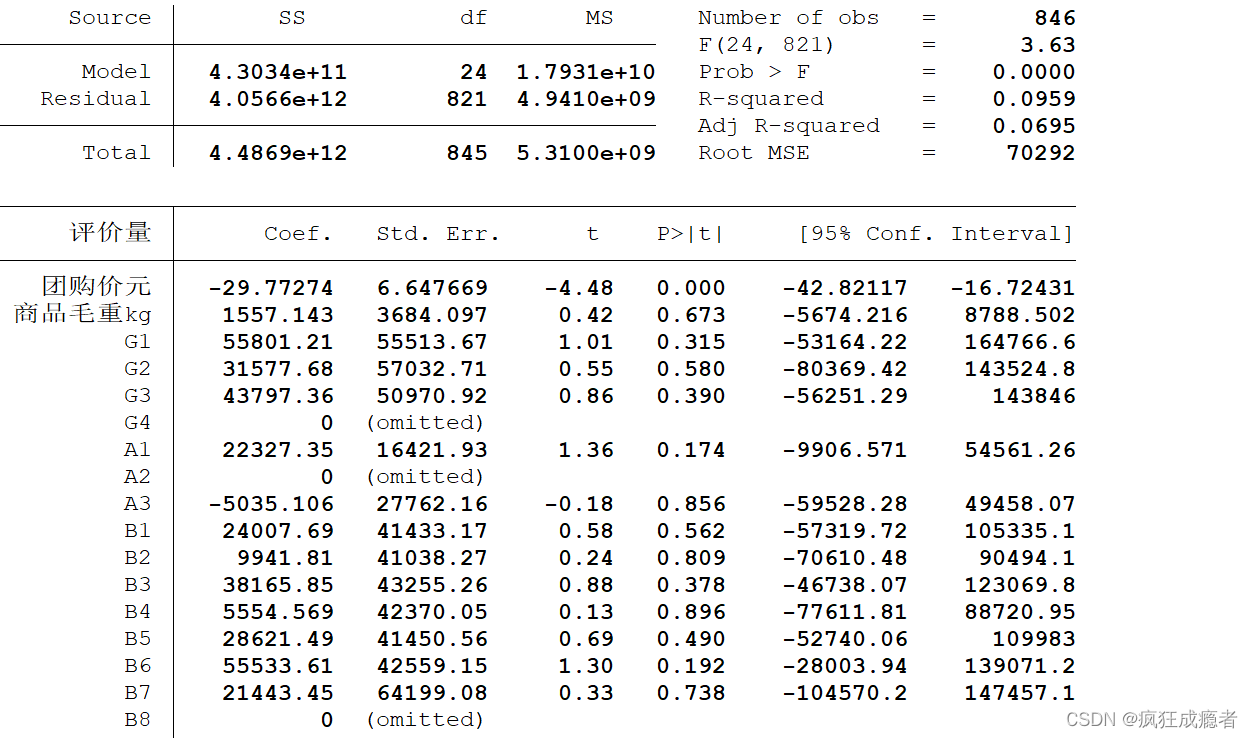
在百分之九十的置信水平下,有两个自变量对应回归系数是显著的。
(评价量为因变量)。
第一个是团购价元,-29.77274代表在其他条件不变的情况下,团购价格每增加一元,评价量平均减小==-29.77274==。
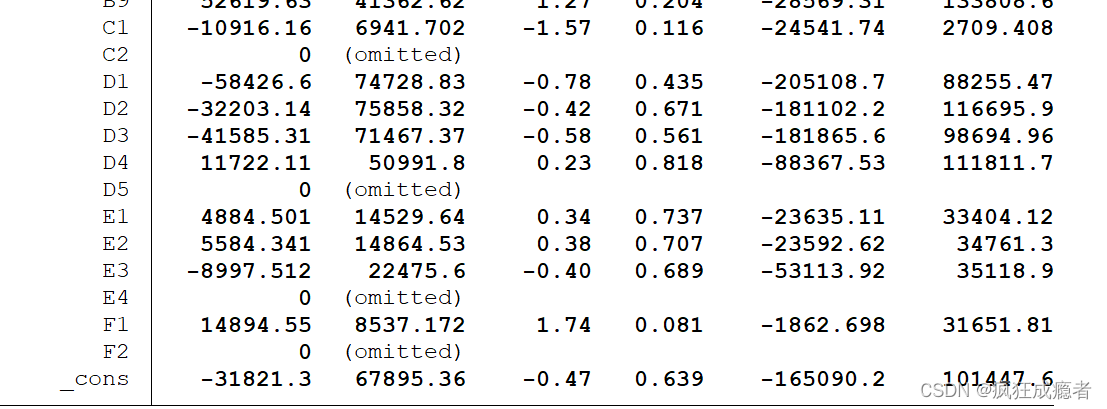
F1
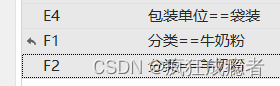
在其他条件不变的情况下,分类为牛奶粉比分类为羊奶粉的评价量高出14894.55。

括号里面为t检验值
*** p<0.01 ** p<0.05 * p<0.1
Stata会自动检测数据的完全多重共线性问题。
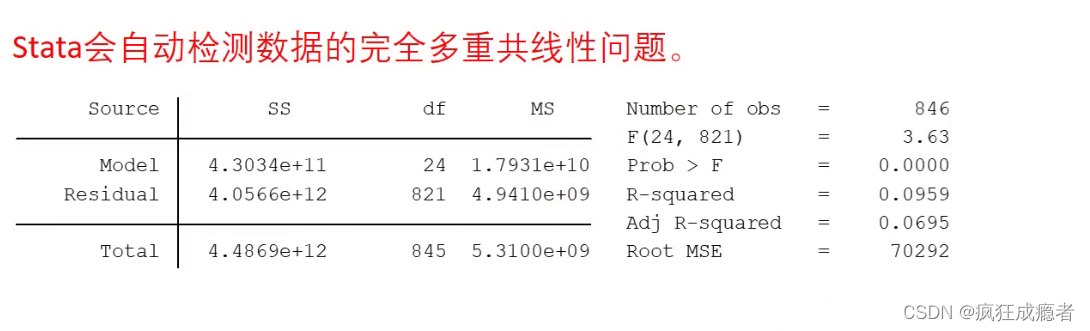
拟合的效果越好
拟合优度

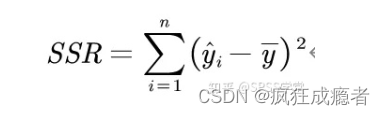


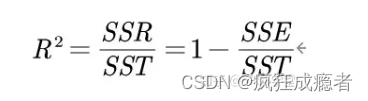
拟合优度低的原因:

标准化回归系数
去除量纲


运行结果显示:
绝对值系数进行比较,0.15>0.06,所有团购价才是影响评价量最重要的因素。
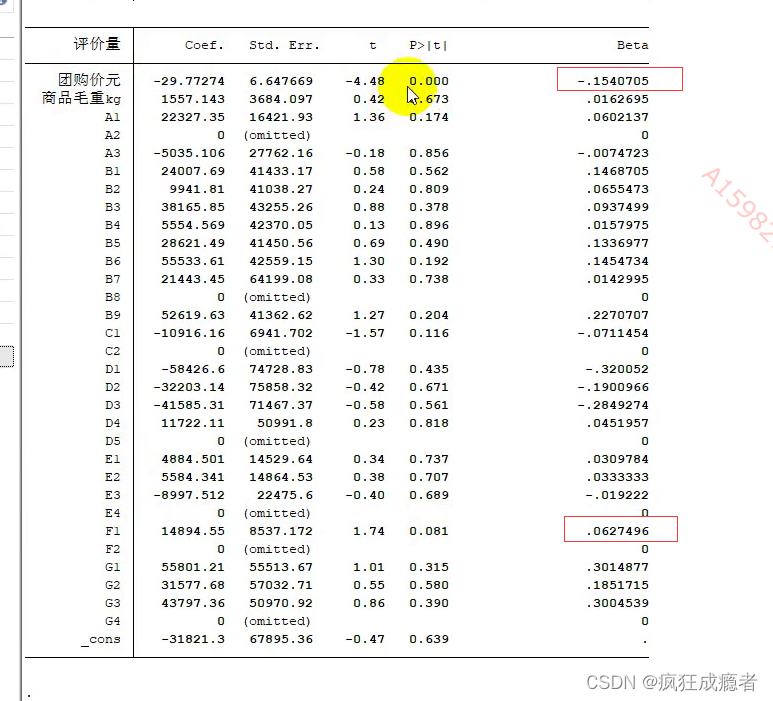
对数据进行标准化处理不会影响回归系数的标准误,也不会影响显著性.
常数的均值是其本身,经过标准化后变成了0.
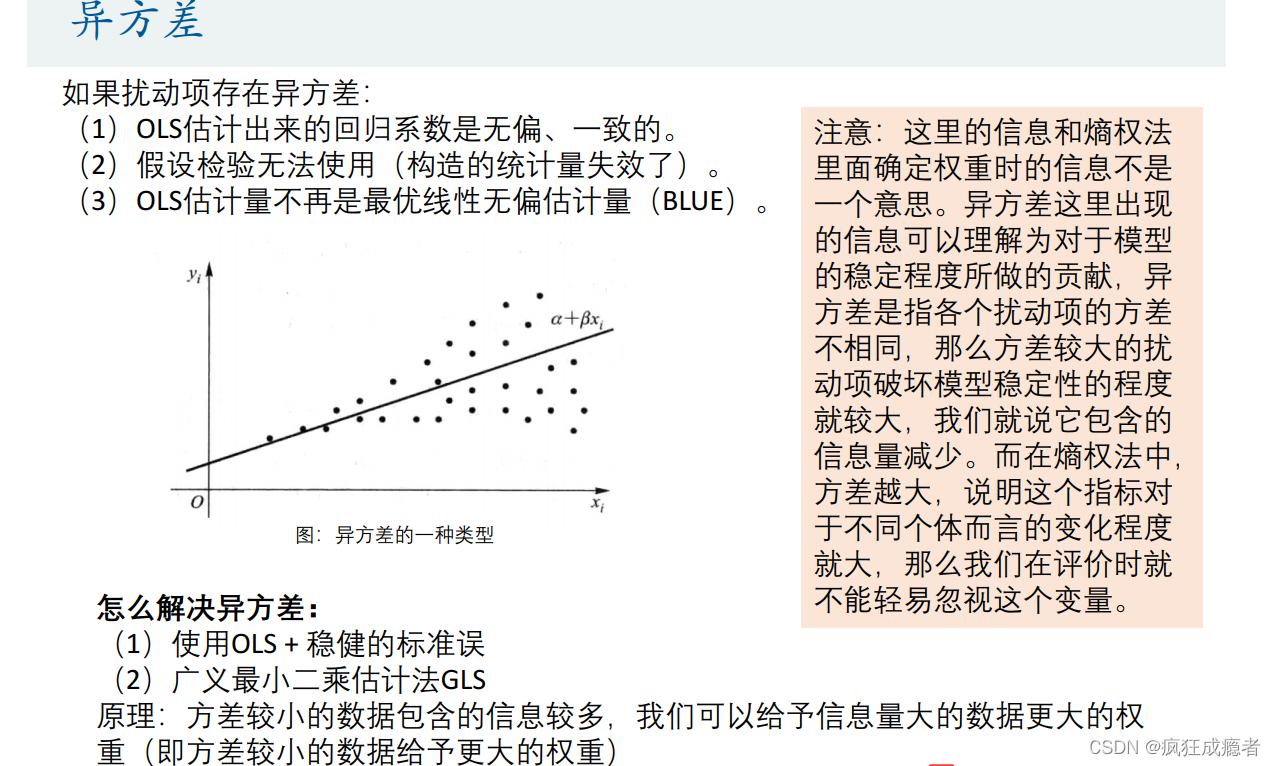
异方差

解决异方差:

画图命令:

rvfplot
横坐标为拟合值,纵坐标为残差的图。
rvpplot
残差和自变量的图
保存图片:
graph export a1.png ,replace
求出一个数的密度取值
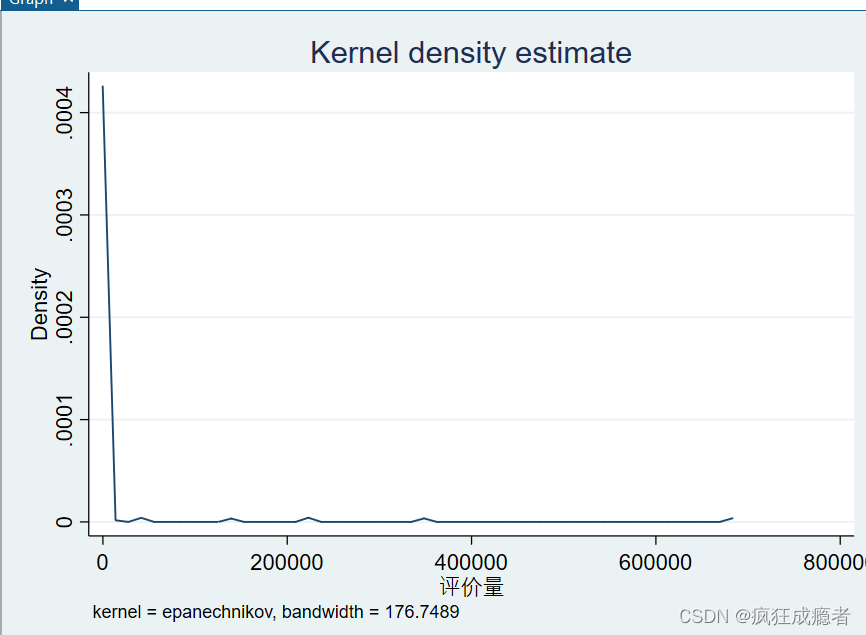
kdensity 评价量
、
检验多重共线性
###方差膨胀因子
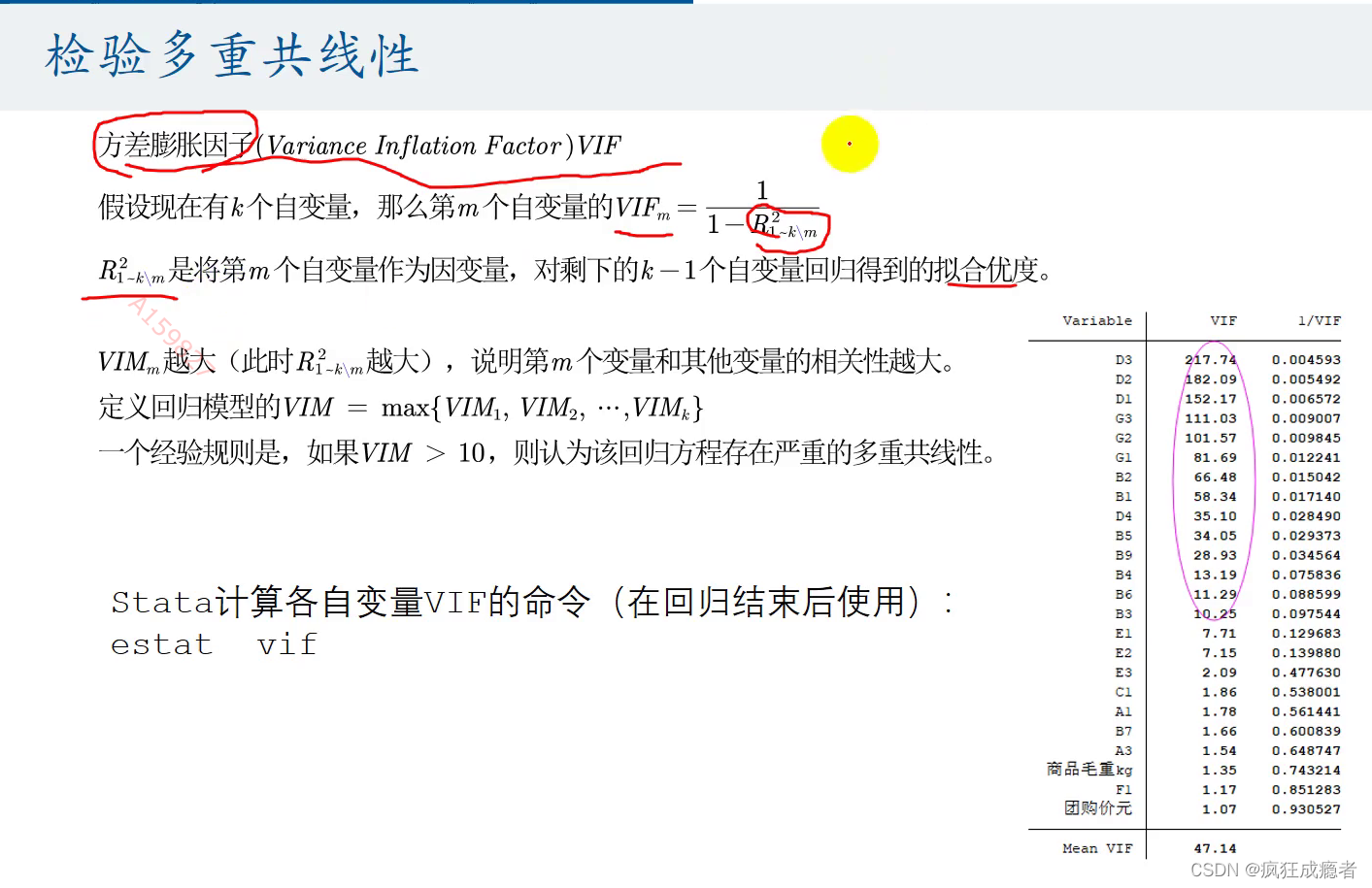
estat vif
存在多重共线性的处理方法
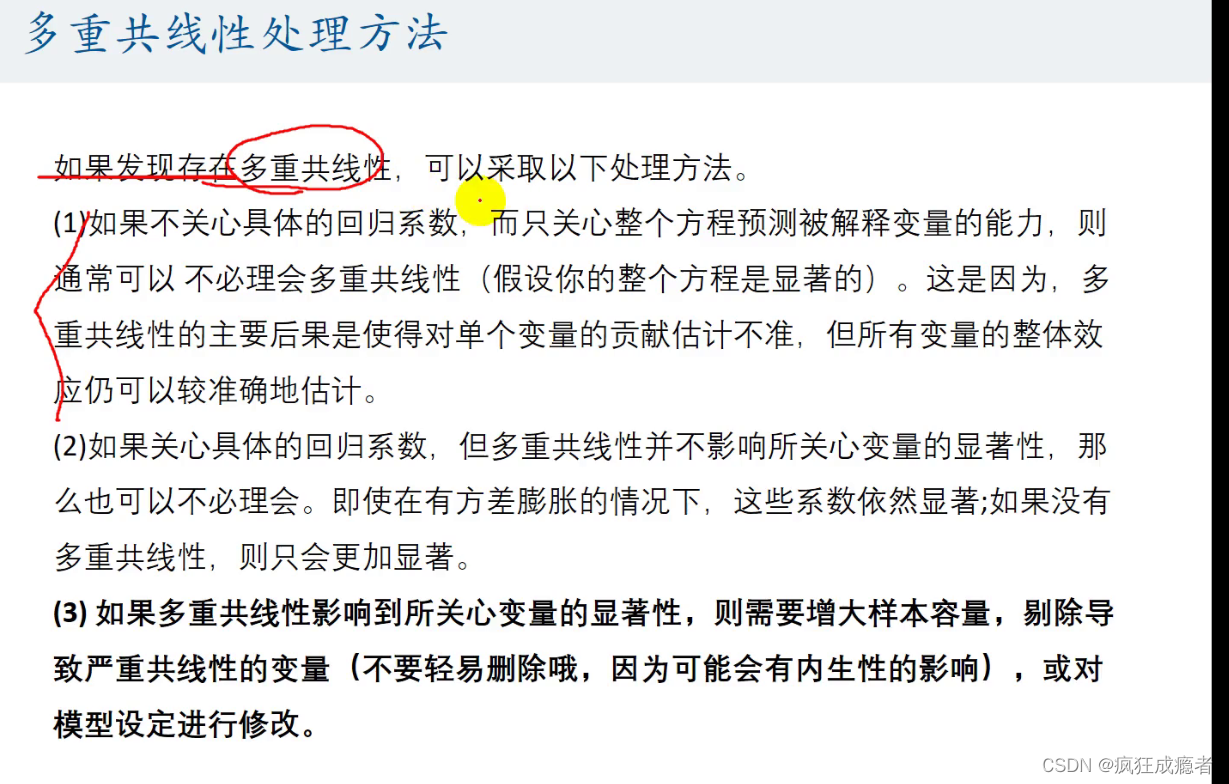
不能轻易删除多重共线性,因为可能受到内生性的影响

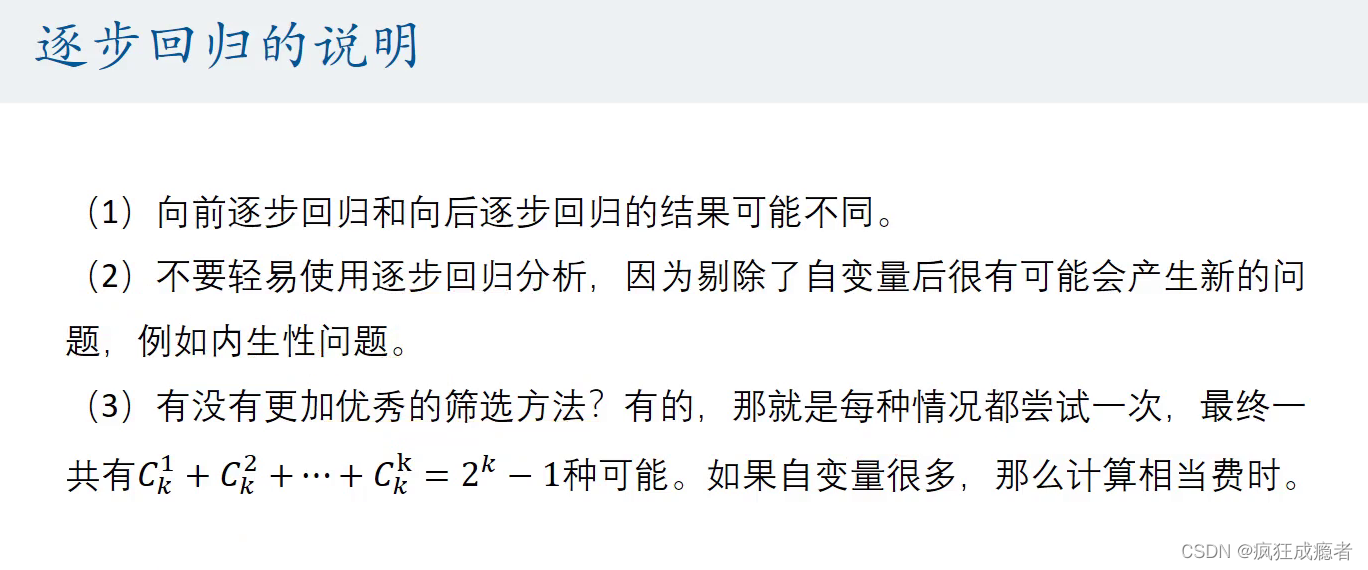
逐步回归(用于解决多重共线性的问题)
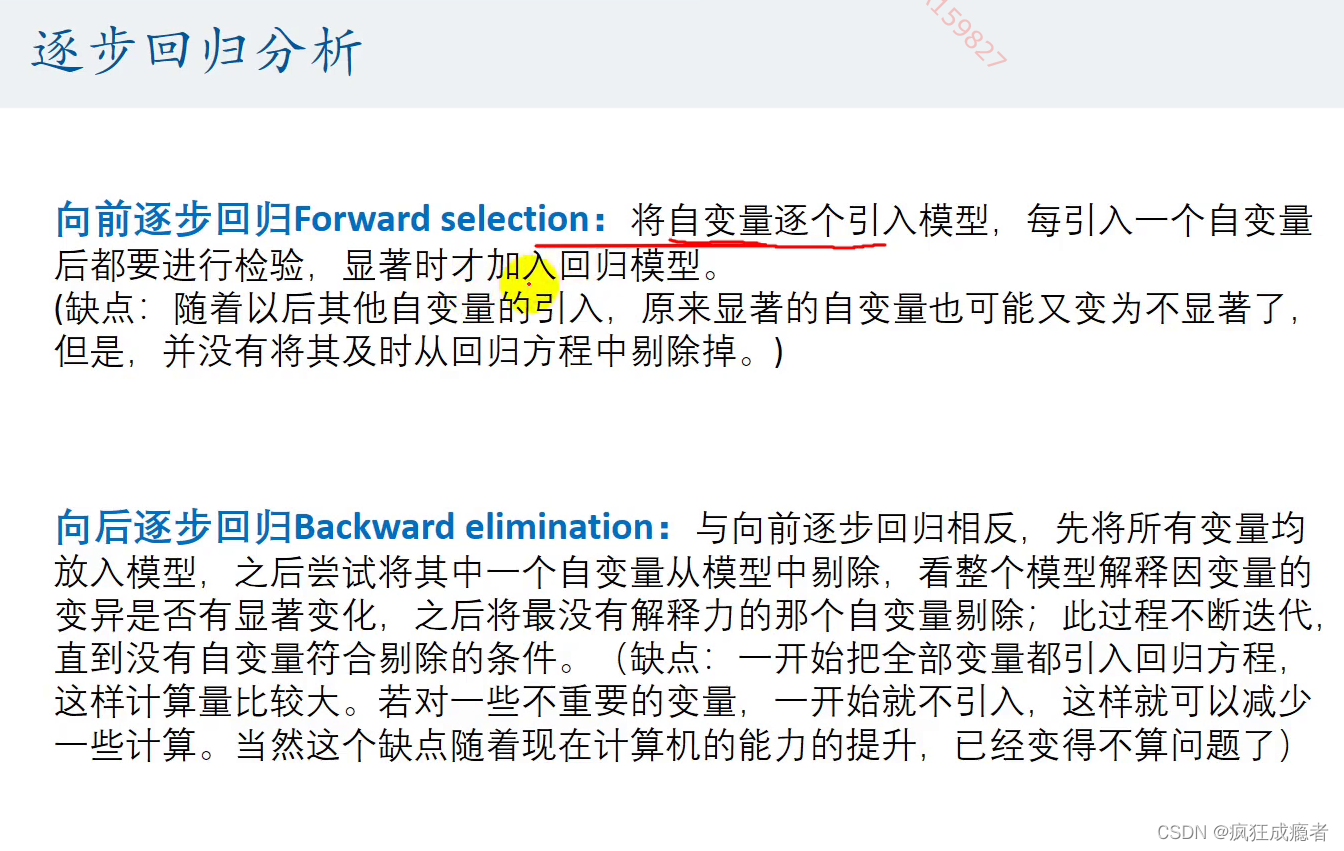
向后逐步回归一般要好于向前逐步回归。
stata实现逐步回归

检验一般使用t检验和F检验。
x1 x2 …xk之间不能有完全多重共线性(和regress不同哦)

通过regress剔除有完全共线性的变量,再进行逐步回归。
stepwise reg评价量团购价元商品毛重xg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 c1 D1 D2 D3 D4 E1E2 B3 F1 G1 G2 G3, r pe(0.05)
pe是向前逐步回归.
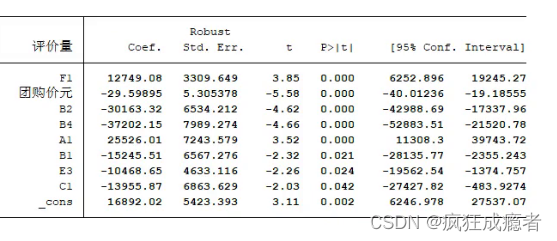
生成结果所有自变量显著。
向后逐步回归操作
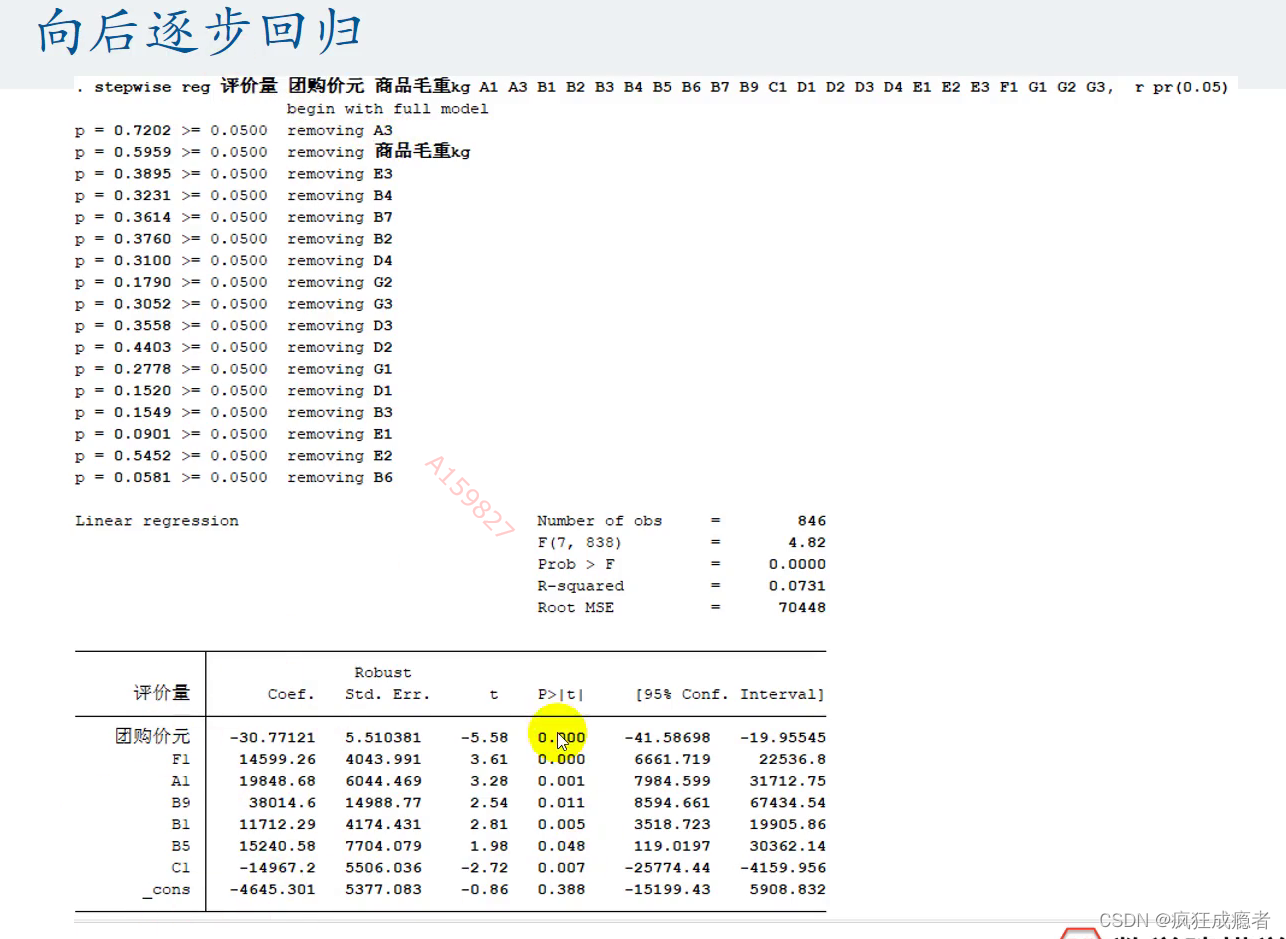
注释:
向前逐步回归和向后逐步回归不一定相同。
国赛的例子
检验多重共线性的代码

方差膨胀因子
我们看它vif即方差膨胀因子,如果大于10即代表有共线性
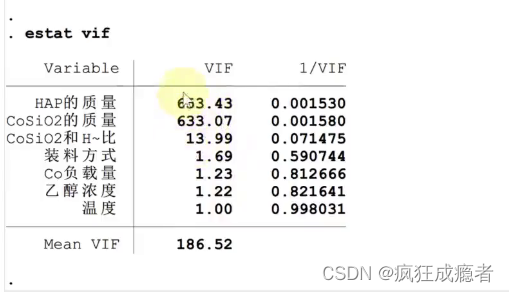
剔除因子
有共线性我们考虑剔除因子。
检验异方差
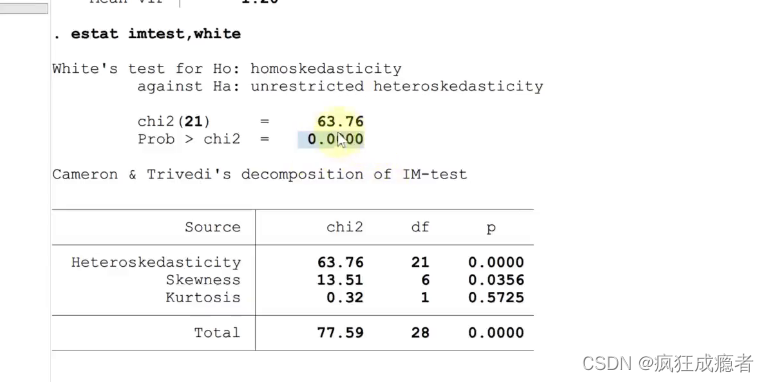
主要关注p值,p值小于等于0.05即存在稳健标准误差,
稳健标注误
我们使用稳健标注误
代码:

标准化回归
看哪一个变量对乙醇转化率最大,使用标注化回归
代码:


















 3098
3098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









