






目录标题
- eye函数
- [0,1]区域转化为实数域的方法
- 斯皮尔曼相关系数求法
- 多项式拟合
- text函数
- string函数
- 画堆叠图
- strrep函数
- tiledlayout绘图
- 堆叠柱状图
- 计算增长率
- 拟合函数设置(自定义函数)
- logit变换
- 算一个数组的不重复的长度
- startsWith函数
- max函数返回索引值
- 添加实验的思路
- numel函数
- newline函数(输出格式的时候经常用)
- 求间隔差的方差的代码(均匀性分布原则)
- 枚举法:
- sort函数(返回索引)
- std函数(标准差函数)
- 统一量纲的代码(zscore标准化)(使得X4_z方差均为一)
- 将矩阵展开的方法
- reshape函数(重构数组把数组按照自己想要的行和列进行改写)
- repmat
- transpose(转置向量)
- 提取数组唯一值
- cumsum函数
- zcore标准化
- 绘图
- 图一
- 代码:
- 图二(许多子图)
- 图三(线性图)
- 字符串拼接
- 组合字母和数字并进行输出(join函数)
- cell 数组中是否包含特定的单词(字符串)
- 区分包含不同字符的字符串数组
- 排序
- 筛选
- 储存
- 导入
把X’归一化到0.01到1
x=mapminmax(X',0.01,1);
eye函数
eye(3):阶数为三的单位矩阵
[0,1]区域转化为实数域的方法

logit代码:
lyc = log(yc ./ (1 - yc)); % logit变换后的乙醇转化率
lxt = log(xt ./ (1 - xt)); % logit变换后的C4烯烃选择性
data1.lyc = lyc;
data1.lxt = lxt;
斯皮尔曼相关系数求法
[r1,p1] = corr(tmp.wd,tmp.lyc,"type","Spearman")
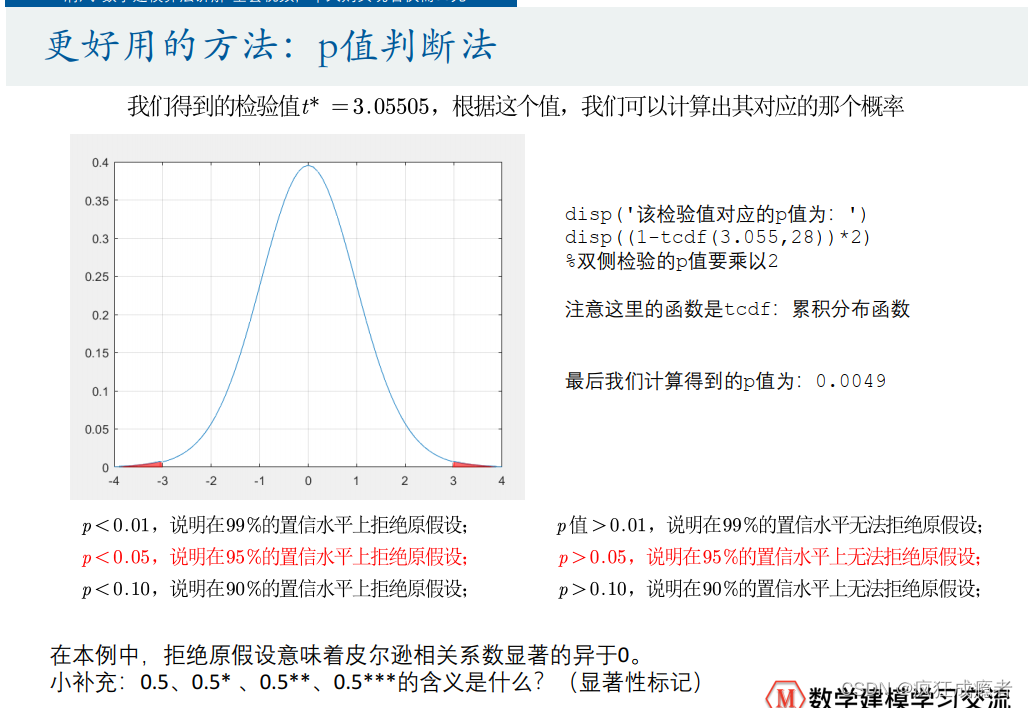
多项式拟合
Y1 = tmp.lyc; % logit变换后的乙醇转化率
Y2 = tmp.lxt; % logit变换后的C4烯烃选择性
X = tmp.wd; % 自变量 温度%两个
ft1 = fittype( 'poly1' ); % 一次函数拟合
format long % 设置输出显示格式
[fitresult1, gof1, output1] = fit( X, Y1, ft1)
output1

自变量样本有5个,拟合的未知数两个。(a0,a1)
fitresult1

feval(fitresult1,X) % 计算拟合值
即计算拟合值,即把X带入到f(x)中
output1.residuals % 残差
coeffvalues(fitresult1) % 拟合出来的系数
调整后的R方(Adjusted R-squared)是一种修正的决定系数,用于解决多元回归模型中自变量个数对决定系数的偏差问题。相对于原始的R方,调整后的R方考虑了要拟合的参数数量的影响,提供了更准确的模型拟合度量。
Adjusted_R² = 1 - [(1 - R²) * (n - 1) / (n - v)]
其中,R²为原始的决定系数,n为样本数量,v为拟合的未知参数的个数。
调整后的R方与原始的R方相比,可以更准确地评估多元回归模型的拟合程度。它考虑了自变量个数的增加对模型的复杂度和解释能力的影响,从而避免了自变量个数过多时原始R方过于乐观的估计。
比较调整后的R方来判断用一次还是二次
绘制拟合效果图:
figure(111)
p1 = plot(fitresult1,'b-',X, Y1,'k*');
绘制一次的图:
‘k*’:黑色的散点
改标记大小:
p1(1).MarkerSize = 10;
p1(2).LineWidth = 1.5;
leg.String = {'原始数据','一次函数','二次函数'};
leg.Location = 'northwest';
% 改图例的位置
xlabel('温度');
ylabel('logit变换后的乙醇转化率')
title(uid(k))
hold off
% hold on后要hold off
改图例显示和方位
res(:,1) > 0
输出一个逻辑矩阵
uid(res(:,1) > 0)
输出开口向上的编号
join(uid(res(:,1) > 0),",")
将这些字符串中间逗号连接
输出结果如图:
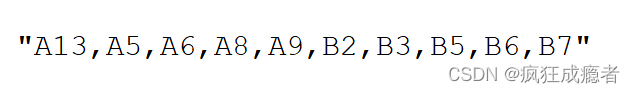
text函数
绘制一条正弦曲线。在点 (π,0) 处,添加文本说明 sin(π)。使用 TeX 标记 \pi 表示希腊字母 π。使用 \leftarrow 显示一个向左箭头。
eg1
x = 0:pi/20:2*pi;
y = sin(x);
plot(x,y)
text(pi,0,'\leftarrow sin(\pi)')
eg2
text(t+5,d2(:,k),(string(round(d2(:,k),2))))
t+5为7个数:7*1,d2(:,k)也为向量组,(string(round(d2(:,k),2))为表达的值。
string函数
a=1;
b=string(a);

把数组变为字符串数组(一般再添加文本时用)
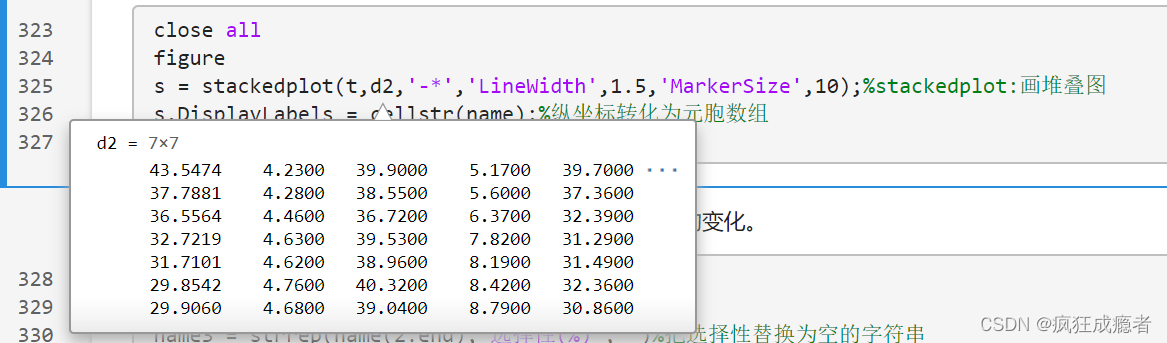
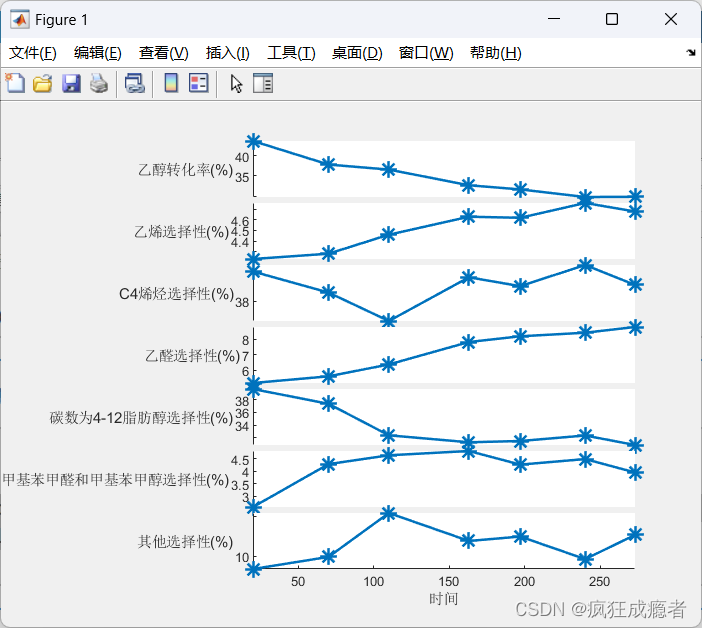
画堆叠图
figure
s = stackedplot(t,d2,'*','LineWidth',1.5,'MarkerSize',10);%stackedplot:画堆叠图
s.DisplayLabels = cellstr(name);%纵坐标转化为元胞数组
xlabel('时间')
strrep函数
查找并替换子字符串
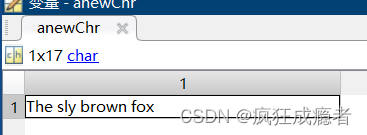
eg1
chr = 'The quick brown fox'
newChr = strrep(chr,'quick','sly')
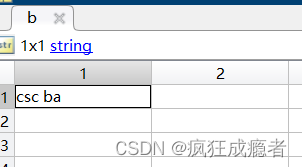
eg2
a=["csc cc"];
b=strrep(a,"cc","ba");
name3 = strrep(name(2:end),"选择性(%)","")%把选择性替换为空的字符串
name3:1*6
tiledlayout绘图
close all
f = figure;
set(f, 'Units', 'normalized') % 设置 Units 为 normalized
set(f, 'Position', [0.05 0.05 0.8 0.8]) % 设置窗口位置和大小
% 前两个元素 [0.05 0.05] 是窗口左下角的位置,
% 后两个元素 [0.8 0.8] 是窗口的宽度和高度。
tiledlayout(3,3) % tiledlayout绘图;也可以用subplot
% tiledlayout绘图方便使用legend
for ii = 1:length(unique(t))
% unique排序(重复只要一次)
nexttile
pie(d3(ii,:),'%.2f%%');% pie画饼图
%.2f:保留两位有效数字
tit = title(string(t(ii))+"min");
tit.Position(2) = tit.Position(2) * 1.1; % 调整位置:调整标题到图像的距离
tit.Color = [1 0 0];
end
lgd = legend(name3,'Orientation','horizontal', ...
'NumColumns',3, ...
'FontSize',15);%3:每一行支持几个元素
lgd.Layout.Tile = 'south';
注释:
pie(d3(ii,:),'%.2f%%');
一个百分号代表数据的样式。
它以百分号开头。
‘%.2f%%’:保留两位数且加个百分号。
.2f表示保留两位有效数字。
pie(d3(ii,:),'%.2f');
此时去掉百分号
tit.Position(2) = tit.Position(2) * 1.1;
调整标题距离图像的位置(之前可能有点挤)
lgd = legend(name3,'Orientation','horizontal', ...
'NumColumns',3, ...
'FontSize',15);
注释:
3:每一行最多有几个元素
堆叠柱状图
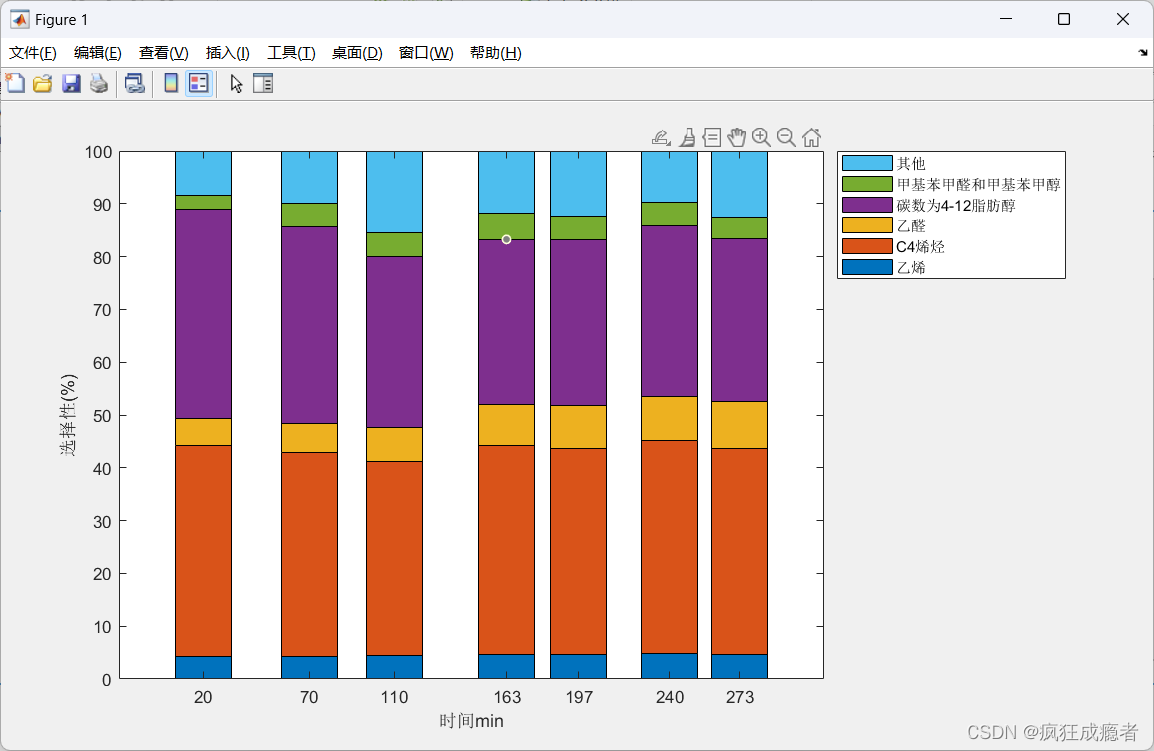
close all
f = figure;
set(f, 'Units', 'normalized') % 设置 Units 为 normalized
set(f, 'Position', [0.2 0.2 0.6 0.6]) % 设置窗口位置和大小
bar(t,d3,'stacked')
xlabel('时间min')
ylabel('选择性(%)')
lgd = legend(name3,'Location','bestoutside');
% % 下面四行代码可以翻转图例,这样图形的颜色顺序和图例顺序能对应上
labels = get(lgd, 'String');
plots = flipud(get(gca, 'children'));
neworder = 6:-1:1;
legend(plots(neworder), labels(neworder))
注释:
set(f, 'Units', 'normalized') % 设置 Units 为 normalized
set(f, 'Position', [0.2 0.2 0.6 0.6]) % 设置窗口位置和大小
设置图像的大小,位置。
计算增长率
增长率:(后一期数据 - 前一期数据) / 前一期数据 * 100 %
d2
% diff:求差分
diff(d2) % diff(d2)等同于:d2(2:end,:) - d2(1:(end-1),:)
growth_rate = (diff(d2) ./ d2(1:(end-1),:)) * 100
name
注释:即第二行减去第一行

根据判断标准,判断哪个指标趋于稳定。
拟合函数设置(自定义函数)
一次函数拟合
ft1 = fittype( @(a, b, t) (a*t+b).*(t<240) + (a*240+b).*(t>=240) , ...%也可以写m文件
'independent','t');% 'independent','t'定义自变量t
%使用fittype自定义函数
[fitresult1, gof1, output1] = fit(t, d, ft1, ...%fit函数进行拟合
'Start', [-1e-2 -0.2])
% rmse均方根误差
注释:
1.
ft1 = fittype( @(a, b, t) (a*t+b).*(t<240) + (a*240+b).*(t>=240) , ...%也可以写m文件
'independent','t')
说明t为自变量
[fitresult1, gof1, output1] = fit(t, d, ft1, 'Start', [-1e-2 -0.2])
为了更快拟合,设置初始点搜索范围(拟合的a,b在哪一点开始搜索)
二次函数拟合
ft2 = fittype( @(a, b, c, t) (a*t.^2+b*t+c).*(t<240) + (a*240^2+b*240+c).*(t>=240), ...
'independent','t');
[fitresult2, gof2, output2] = fit(t,d, ft2, ...
'Start', [1e-5, -1e-2 -0.2])
注释:
给三个初始点。
ft2 = fittype( @(a, b, c, t) (a*t.^2+b*t+c).*(t<240) + (a*240^2+b*240+c).*(t>=240), ...
'independent','t');
注意这里是点乘.^2
Logistic模型的公式:
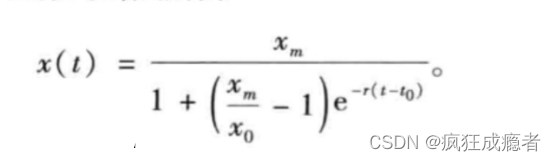
(递增的)
xm表示趋于稳定时x的取值,r表示增长率,这两个参数是要拟合的参数。
x0表示初始时刻x的值,t0表示初始时刻。
如果要改成递减的阻滞模型,只需要将分母中增长率r前面的负号去掉,此时拟合得到的r会是一个负数,表示衰减率。
x0 = d(1)
t0 = t(1)
ft3 = fittype( @(xm, r, t) xm./(1+ (xm/-0.2596 - 1)*exp(r*(t-20))), ...
'independent','t');
[fitresult3, gof3, output3] = fit(t,d, ft3, ...
'Start', [-0.9 -0.1])
logit变换

把[0,1]转化到实数域
lyc = log(yc ./ (1 - yc)); % logit变换后的乙醇转化率
lxt = log(xt ./ (1 - xt)); % logit变换后的C4烯烃选择性
logit变换:
d = d2(:,1)/100;
d = log(d./(1 - d));
logit变换还原:
exp(y1) / (1 + exp(y1)) * 100
exp(y2) / (1 + exp(y2)) * 100
算一个数组的不重复的长度
length(unique(t))
startsWith函数
str = ["abstract.docx","data.tar","code.m"; ...
"data-analysis.ppt","results.ptx","summary.ppt"]
pat = "data";
TF = startsWith(str,pat)
TF为逻辑数组

设置装料方式:
zl(startsWith(data1.id,"A")) = 1;
max函数返回索引值
[m1,ind1] = max(data1.yc .* data1.xt / 10000)
对向量组进行操作
添加实验的思路

numel函数
n = numel(A) 返回数组 A 中的元素数目 n。
newline函数(输出格式的时候经常用)
换行
eg1:
fprintf("温度:"+wd(ii)+newline)
eg2:
fprintf(join( zbmc + ":"+ string(x), newline))
注释:
1.

2.

输出结果:

求间隔差的方差的代码(均匀性分布原则)
均匀性分布原则:在进行多元实验设计时,应尽可能保证样本点在整个因素水平空间内均匀分布。也就是说,对于你正在研究的每个因素,你都应该尝试涵盖其可能的全范围,而且这些测试点应该在这个范围内均匀分布。
目标:相邻的指标之间的间隔差的方差最小
wd1 = [10 20 100];
var(diff(sort(wd1)))
wd1 = [10 40 100];
var(diff(sort(wd1)))
wd1 = [10 55 100];
var(diff(sort(wd1)))
枚举法:
load meijv.mat
numIndicators = 5;
numPossibilities = 5;
% 生成指标的所有可能取值
indicators = cell(1, numIndicators);
[indicators{:}] = ndgrid(1:numPossibilities);
% 将指标的所有可能取值合并成一个矩阵
allCombinations = reshape(cat(numIndicators + 1, indicators{:}), [], numIndicators);
% 显示所有组合
allCombinations
N = size(allCombinations,1);
c4xtsl = zeros(N,1);
X = ones(N,6);
for ii = 1:N
x = ones(1,6);
tmp = allCombinations(ii,:);
for jj = 1:5
x(jj) = Result(jj,tmp(jj));
end
X(ii,:) = x;
y1 = predict(gprMdl1, x);
y1 = exp(y1) / (1 + exp(y1)); % 乙醇转化率
y2 = predict(gprMdl2, x);
y2 = exp(y2) / (1 + exp(y2)); % C4烯烃选择性
c4xtsl(ii) = y1*y2;
end
[c4xtsl_sort,ind] = sort(c4xtsl,'descend');
X_sort = X(ind,:);
c4xtsl_sort(1:5,:)
X_sort(1:5,:)
sort函数(返回索引)
[c4xtsl_sort,ind] = sort(c4xtsl,'descend');
std函数(标准差函数)
统一量纲的代码(zscore标准化)(使得X4_z方差均为一)
mean_x4 = mean(X4);
std_x4 = std(X4);
X4_z = (X4 - mean_x4) ./ std_x4;
将矩阵展开的方法
aaa=lb(:);
注释:

展开后:
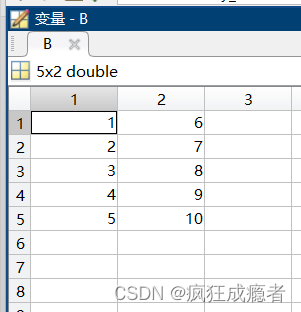
reshape函数(重构数组把数组按照自己想要的行和列进行改写)
eg1:
A = 1:10;
B = reshape(A,[5,2])
eg2:
A = magic(4);
B = reshape(A,[],2);
reshape(A,[],2)把数组写成两列的
repmat
重复数组副本
A = repmat(10,3,2)

transpose(转置向量)
transpose(zbmc(1:end-1)
提取数组唯一值
uid = unique(data1.id,'stable')
uid = unique(data1.id)
unique函数:返回data1.id唯一值。
C = unique(A,setOrder) 以特定顺序返回 A 的唯一值。setOrder 可以是 ‘sorted’(默认值)或 ‘stable’。
eg:计算 A 的唯一值。
A = [9 2 9 5];
C = unique(A)
C = 1×3
2 5 9

cumsum函数
A = [1 4 7; 2 5 8; 3 6 9]
B = cumsum(A)

A = [1 3 5; 2 4 6]
B = cumsum(A,2)

数据标准化
zcore标准化
2021b代码

zcore标准化目的是去除量纲,使得方差相等。
ab=zscore (S) ;
ab=zscore (S) ;
a=ab(:,[1:3]); b=ab( : ,[4 :end]);
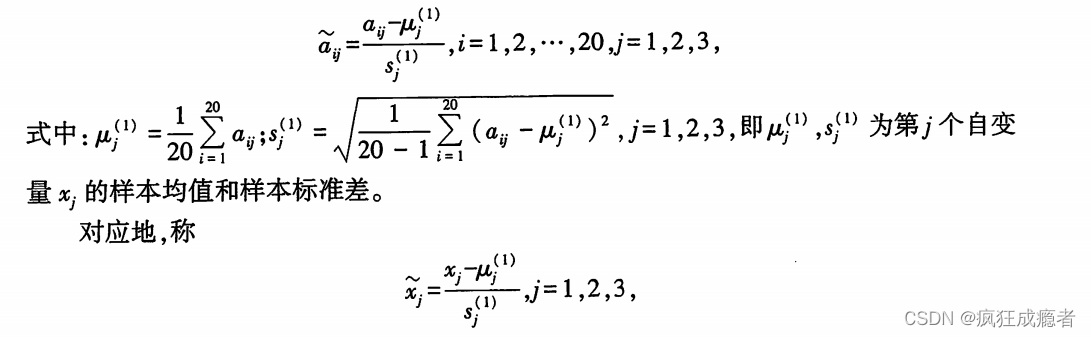

求相关系数矩
r=corrcoef (S);
分别提出自变量组和因变量组的成分

[XL,YL,XS,YS,BETA,PCTVAR,MSE,stats ] =plsregress (a ,b);
% PCTVAR是_个两行矩阵,第一行的每个元素对应着自变量提出成分的贡献率,第二行的每个元素对
% 应着因变量提出成分的贡献率
contr=cumsum(PCTVAR,2);
xw=a\XS;
yw=b\YS;
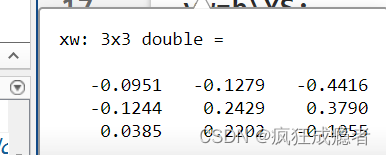
x的 系数(竖的看)对比:
y的 系数(竖的看)对比:

求因变量组与子变量组之间的回归方程。
[XL2,YL2,XS2,YS2,BETA2,PCTVAR2,MSE2,stats2] =plsregress (a,b,ncomp)

BETA2为标准化前的系数(竖着看):

beta3(1, : ) =mu (n+1:end)-mu (1 :n)./sig (1:n)* BETA2([2:end] , : ).* sig (n+1:end);
beta3([2:n+1],:)=(1./ sig(1:n) )' * sig (n+1:end).* BETA2([2:end], :)

系数(竖着看)
反标准化
bar函数
绘制反zcore化前的图像
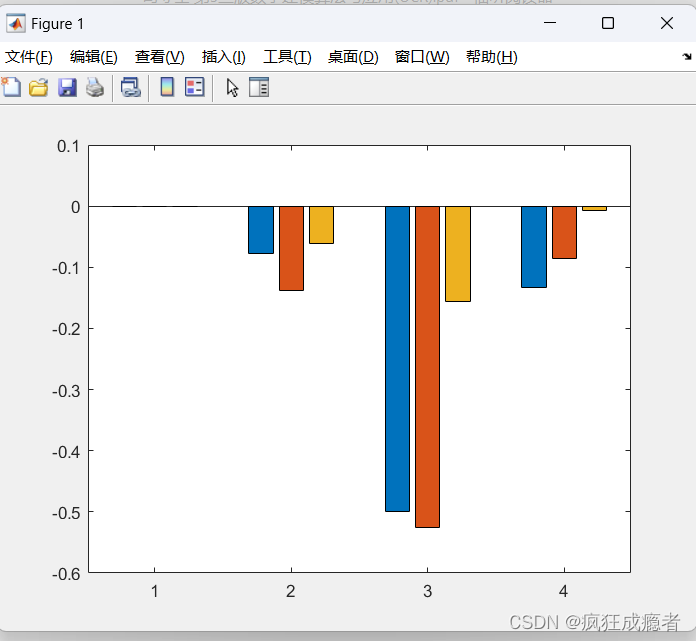
bar(xBETA2);
legend({'图例1', '图例2','图例2'})
labels = {'单杠', '弯曲', '酬工'};
xticklabels(labels)
求预测值
20个样本,三个特征

yhat =repmat (beta3 (1,:),[size(a,1),1] )+ab0(:,[1:n] ) * beta3( [2:end], :)
求预测值和观测值的最大值(画图用)
ymax =max([yhat ;ab0( : , [n+1:end])]);%求预测值和观测值的最大值
画图分析

在这个预测图上,如果
所有点都能在图的对角线附近均匀分布’则方程的拟合值与原值差异很小,这个方程的拟
合效果就是令人满意的。
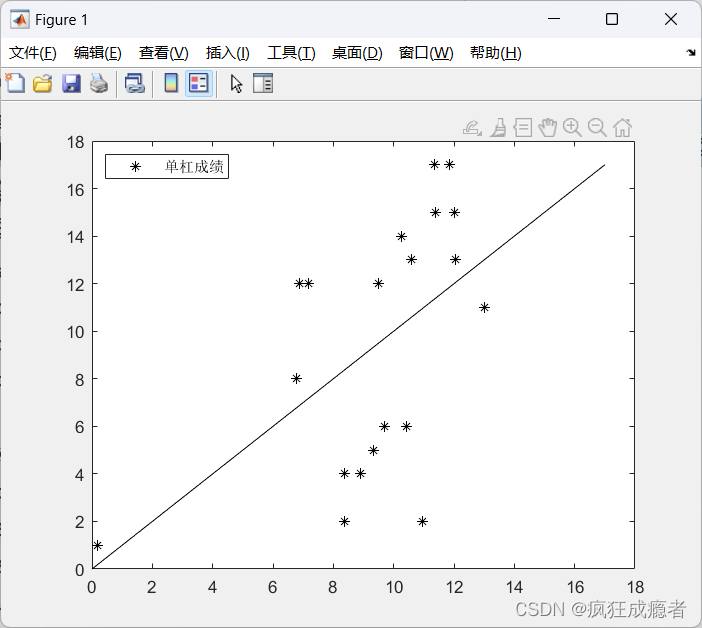
绘图
图一
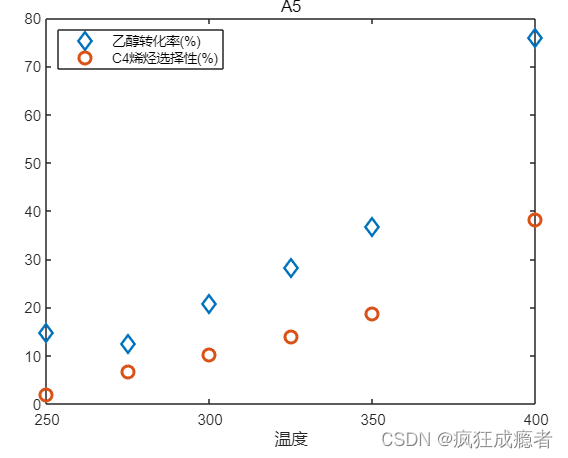
代码:
figure
plot(wd,yc,'d',wd,xt,'o','LineWidth',2,'MarkerSize',8)
% LineWidth对图例宽度起到作用
xlabel('温度')
title(uid(k))
legend('乙醇转化率(%)','C4烯烃选择性(%)','Location','northwest')
图二(许多子图)
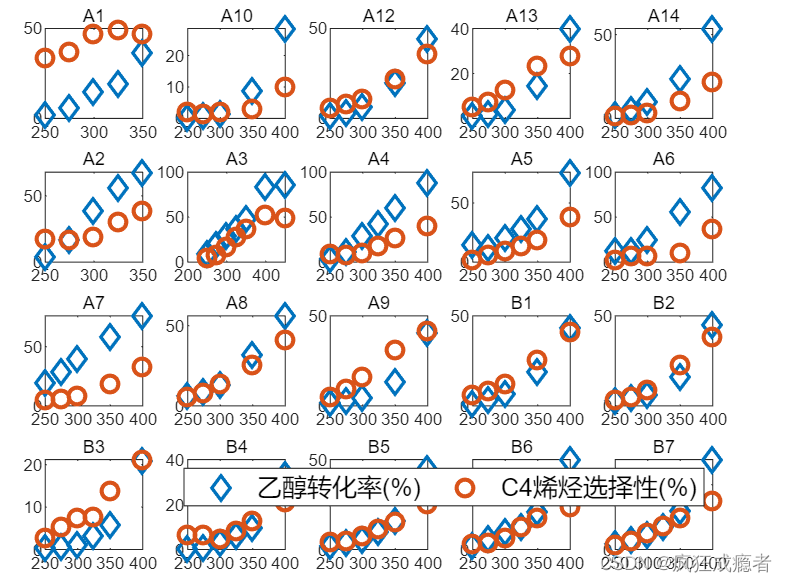
代码
close all
figure
for k = 1:m
tmp = data1(data1.id == uid(k),:);
% yc: 乙醇转化率(%)
% xt: C4烯烃选择性(%)
wd = tmp.wd;
yc = tmp.yc;
xt = tmp.xt;
subplot(4,5,k)
% 20个催化剂正好4*5=20
plot(wd,yc,'d',wd,xt,'o','LineWidth',2,'MarkerSize',8)
% xlabel('温度')
title(uid(k))
if k == 20
legend('乙醇转化率(%)','C4烯烃选择性(%)','Orientation','horizontal','FontSize',12)
% Orientation(方向),horizontal方向给成立水平方向
end
end
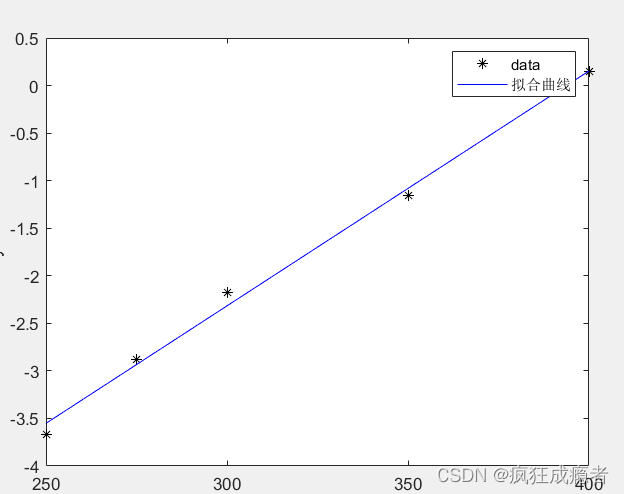
图三(线性图)
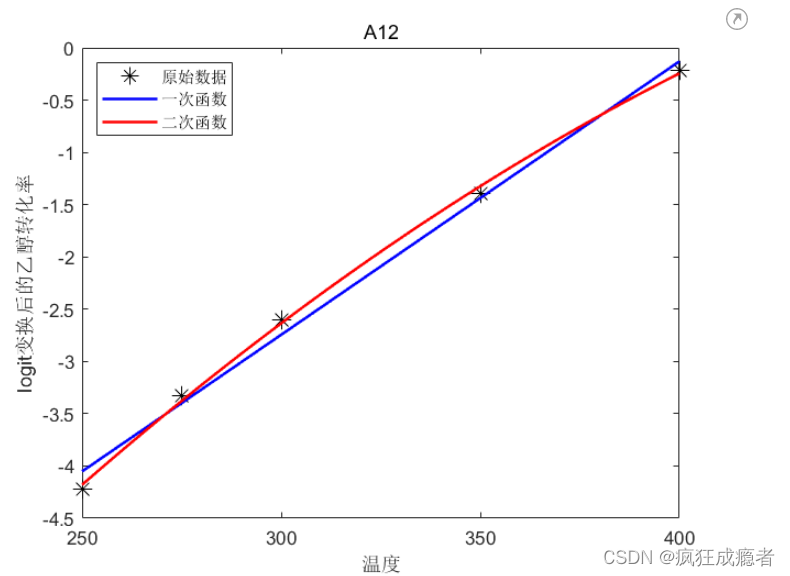
代码
close all
figure(111)
p1 = plot(fitresult1,'b-',X, Y1,'k*');
% k:指黑色的散点
p1(1).MarkerSize = 10;
p1(2).LineWidth = 1.5;
hold on
p2 = plot(fitresult2,'r-');
p2.LineWidth = 1.5;
leg = findobj(gcf,'Type','legend');
% findobj:找到当前图的图例
leg.String = {'原始数据','一次函数','二次函数'};
leg.Location = 'northwest';
% 改图例的位置
xlabel('温度');
ylabel('logit变换后的乙醇转化率')
title(uid(k))
hold off
字符串拼接
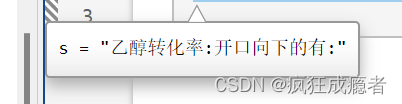
字符串连接1
s = "乙醇转化率"+":"+"开口向下的有:"
字符串连接2(join)
str = ["Carlos","Sada";
"Ella","Olsen";
"Diana","Lee"]
newStr = join(str)

组合字母和数字并进行输出(join函数)
for qq = 1:k
fprintf("-----------------------------------------------------------" + newline)
fprintf("第"+qq+"组"+newline)
fprintf(join( transpose(zbmc(1:end-1) )+ ":"+ string(Result(:,qq)), newline))
fprintf(newline)
end

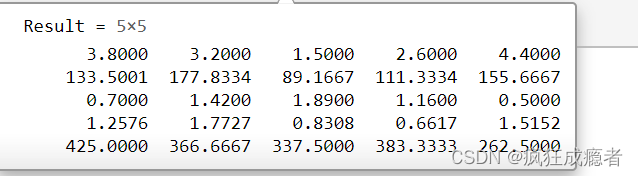
运行结果:

字符串连接(加入符合)1
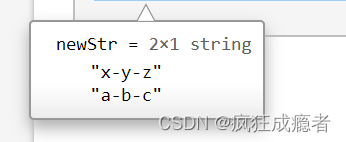
str = ["x","y","z";
"a","b","c"]
newStr = join(str,"-")
字符串连接(加入符合)2
str = ["x","y","z";
"a","b","c"]
delimiters = [" + "," = ";
" - "," = "];
newStr = join(str,delimiters)

cell 数组中是否包含特定的单词(字符串)
要判断一个 cell 数组中是否包含特定的单词(字符串),你可以使用循环遍历每个 cell 元素,并使用字符串处理函数来判断每个单元格中是否包含该单词。以下是一个示例:
% 创建一个包含字符串的 cell 数组
cellArray = {'This is a sample string.', 'Another cell.', 'No c here.', 'Contains c.'};
wordToFind = 'c';
% 初始化一个标志变量
found = false;
% 遍历每个 cell 元素
for i = 1:numel(cellArray)
if contains(cellArray{i}, wordToFind)
found = true;
break; % 一旦找到,就可以退出循环
end
end
if found
disp('The word c is present in the cell array.');
else
disp('The word c is not present in the cell array.');
end
区分包含不同字符的字符串数组

我们将FileNames进行分类,区分出包含c和d字符串数组。
FileNames如图所示。
n = length(FileNames);
cc=0;
dd=0;
FileNamesc={};
FileNamesb={};
for ii=1:n
tem1= FileNames(ii);
wordToFind = 'c';
found = false;
for i = 1:numel(tem1)
if contains(tem1{i}, wordToFind)
found = true;
break;
end
end
if found
cc=cc+1;
FileNamesc(cc,1)=FileNames(ii);
else
dd=dd+1;
FileNamesb(dd,1)=FileNames(ii);
end
end
注释:
1.定义cell数组FileNamesc={},数值数组定义为格式为:FileNamesc=[]。
2.tem1= FileNames(ii);取第
i
i
ii
ii个元素进行判断。
3.wordToFind = ‘c’;为区分的元素。
4.FileNamesc(cc,1)=FileNames(ii);cell数组和cell数组之间转化用(),cell转化为double用{}。
eg:
a={1}
b=a{1}
a为cell型,b为double型。
排序
例题一
data = [5, 1, 3, 8, 2];
% [sortedData, sortedIndex] = sort(data);%升序排序
[sortedData, sortedIndex] = sort(data,'descend');%降序排序
rearrangedData = data(sortedIndex);
disp(rearrangedData);;
在这个例子中,我们按行对矩阵进行排序,并使用 sortedIndex 对矩阵进行索引操作,得到按行排序后的矩阵。
例题二
for ii = 1:cc
pattern = '(\d+)';
matches = regexp(FileNamesc, pattern, 'tokens');
tem2= matches{ii};
ccz(ii,1)=str2double(tem2{1});
end
[C, idxc] = sort(ccz);
cxFileNames=FileNamesc(idxc);
我们需要把这组数据按照数字大小进行升序排序。
1.使用正则化提取文章中的数字。
2.使用 sort函数进行沈旭排序,并使用 idxc 对矩阵进行索引操作,得到按行排序后的矩阵。
筛选
数据提取
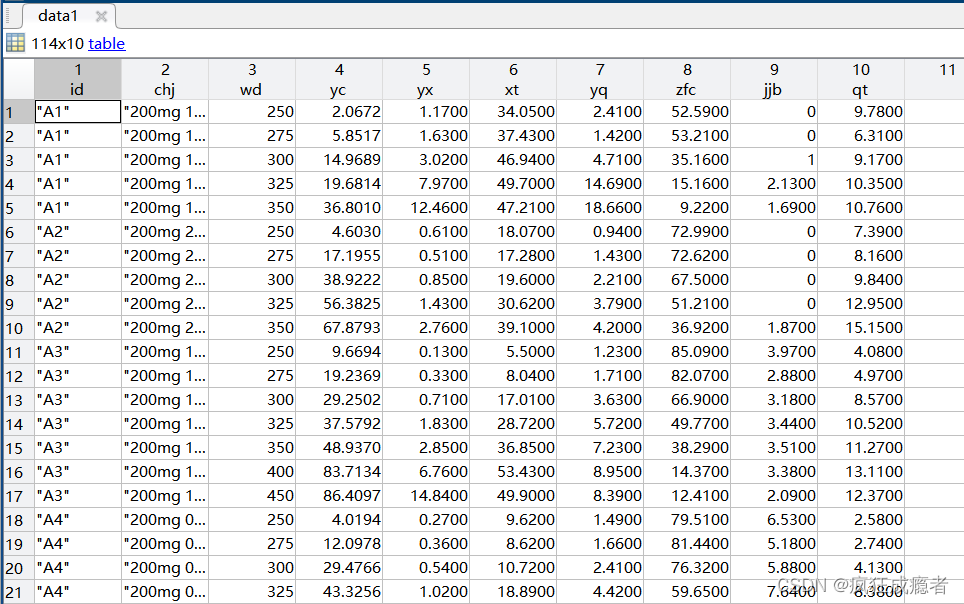
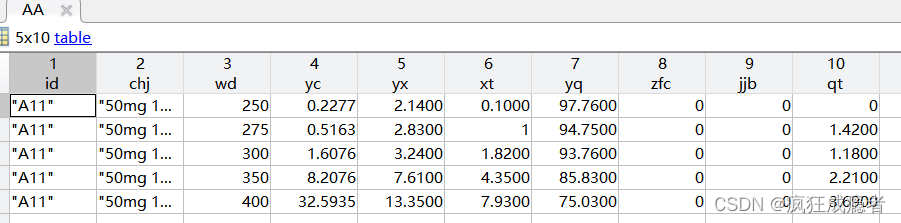
我们需要对data1数据提取ind行作为一个新组AA。

代码实现:
AA=data1(ind,:);
结果:
数据删除
我们需要将data1数据ind进行删除,代码实现:
data1(ind,:) = [];
%data1([55,56,57,58,59],:)%或者
data1
数据筛选
我们需要得到,data2相加介于85~105之间的数据。
ss = sum(tmp,2);% sum(A,2) 每一行求和
idx = find((ss < 85 ) | (ss > 105));%|或
data2(idx,:) = [];
数据透视表
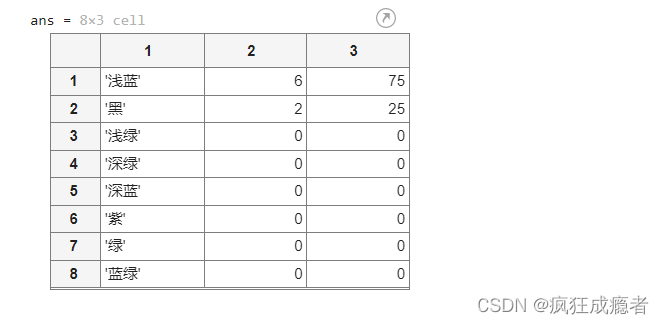
tmp1 = data1(data1.bmfh=='风化' & data1.lx=='铅钡' & data1.ws=='A' ,:);%找到满足这三点要求的数据
tabulate(tmp1.ys)%写出所以颜色对应出现的次数,比率
sortrows(tabulate(tmp1.ys),2,'descend') %对行进行排序,descend降序
精确查找
clc,clear
shuju = readtable("D:\my_document\latex\markdown\shuju.xlsx");
tem=shuju{:,2};
id=find(tem=="西门花店");
A=shuju(id,:);
储存
excel文件
1.存储为excel文件,使用函数xlswrite。
filename = 'testdata.xlsx';
A = [12.7 5.02 -98 63.9 0 -.2 56];
xlswrite(filename,A)
1.存储为excel文件,使用函数xlswrite。:
filename = 'testdata.xlsx';
A = [12.7 5.02 -98 63.9 0 -.2 56];
save('testdata.xlsx', 'A');
mat文件
1.存储为mat文件,使用函数save。
filename = 'testdata.xlsx';
A = [12.7 5.02 -98 63.9 0 -.2 56];
save('testdata', 'A');
导入
excel文件
readtable函数(只能读取double型)
filename = 'shuju.xlsx';
A = xlsread(filename);
限制范围:
filename = 'myExample.xlsx';
sheet = 1;
xlRange = 'B2:C3';
subsetA = xlsread(filename,sheet,xlRange)
xlsread函数
shuju = readtable("D:\my_document\latex\markdown\shuju.xlsx");
table型
%% 设置导入选项并导入数据
opts = spreadsheetImportOptions("NumVariables", 3);
% 指定工作表和范围
opts.Sheet = "Sheet1";
opts.DataRange = "A2:C14";
% 指定列名称和类型
opts.VariableNames = ["VarName1", "VarName2", "VarName3"];
opts.VariableTypes = ["string", "categorical", "double"];
% 指定变量属性
opts = setvaropts(opts, "VarName1", "WhitespaceRule", "preserve");
opts = setvaropts(opts, ["VarName1", "VarName2"], "EmptyFieldRule", "auto");
% 导入数据
shuju = readtable("D:\my_document\latex\markdown\shuju.xlsx", opts, "UseExcel", false);
shuju = readtable("D:\my_document\latex\markdown\shuju.xlsx");
filename = 'shuju.xlsx';
A = xlsread(filename);
mat文件
load data123.mat















 4131
4131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









