






Logistic回归概述
Logistic回归是一种用于解决二分类问题的机器学习算法。尽管它的名字中包含"回归"一词,但实际上它是一种分类算法。Logistic回归通过将线性组合的结果映射到一个概率值,然后使用阈值将概率转化为类别,从而进行分类。
Sigmoid函数
Sigmoid函数,也称为 logistic 函数,是一种常用的激活函数,用于将实数映射到区间 (0, 1)。其数学表达式如下:
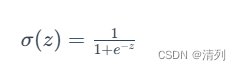
其中,e是自然对数的底(欧拉数),z 是输入值。
解释和特点:
1. 范围限制:Sigmoid函数的主要特点是将任意实数值映射到 0 和 1之间。这使得它非常适合用于二元分类问题,其中输出可以解释为概率。
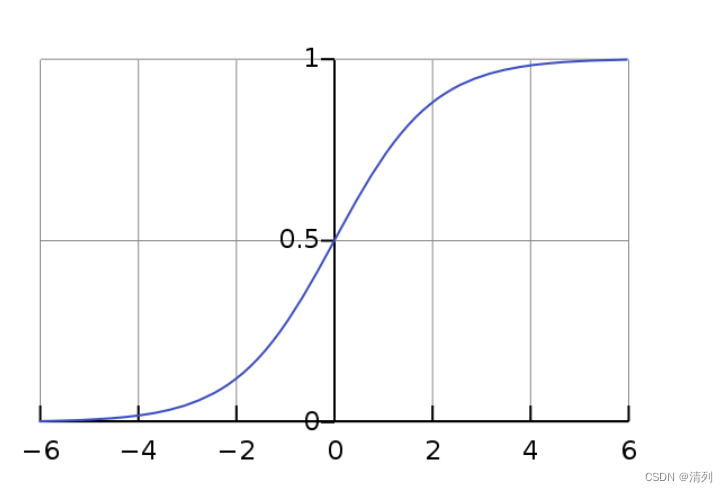
2. S形曲线:Sigmoid函数的图形呈S形曲线,因此被称为“S型曲线”。这种曲线形状有助于模型学习非线性关系,而且在接近极端值时变化较为平滑。
3. 概率解释:在二元分类中,Sigmoid函数的输出可以被解释为样本属于正类别的概率。通常,当输出概率大于或等于 0.5 时,样本被预测为正类别;否则,被预测为负类别。
4. 平滑性:Sigmoid函数在整个实数范围上都是可导的,这使得它在梯度下降等优化算法中应用广泛。
5. 逆函数:Sigmoid函数的逆函数称为 logit 函数,其表达式为
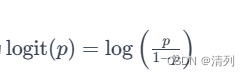
在 logistic 回归等模型中,这个逆函数用于将概率转换回线性组合的形式。
图形表示:
下面是Sigmoid函数的典型图形:
极大似然估计
Logistic回归中的参数估计通常采用极大似然估计。在Logistic回归中,我们的目标是找到能够最大化观测到的数据的概率的参数值。
考虑二元分类问题,对于每个样本 i,我们有一个输入特征向量 x^(i)和一个二元标签 y^(i)。Logistic回归的假设是:
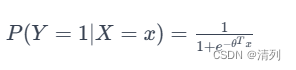
其中,Y是标签,X是输入特征,θ 是模型的参数。
似然函数表示观测到训练集中所有样本的概率。对于二元分类问题,似然函数可以写成:
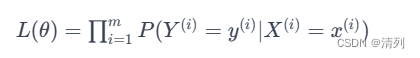
为了方便计算,通常会取对数,得到对数似然函数:
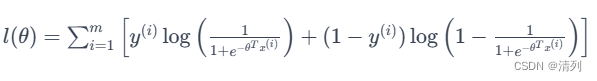
极大似然估计的目标是最大化对数似然函数。这相当于最小化负的对数似然函数:
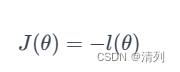
通常采用梯度下降等优化算法来最小化负对数似然函数,从而估计出最优的参数 θ。
Logistic回归的极大似然估计得到的参数能够最大化观测到的数据的似然,使得模型对观测到的数据的拟合最好。这样估计得到的模型参数可以用于进行预测和分类。
利用梯度下降法求解参数w
Logistic回归中使用梯度下降法求解参数 �w,其目标是最小化负对数似然函数。以下是梯度下降法的步骤:
对数似然函数:
首先,我们有对数似然函数:
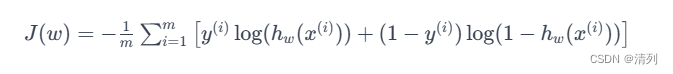
其中:
- m 是样本数量。
- y(i) 是第 i 个样本的实际标签。
- hw(x(i))是对数几率(logit)函数,即
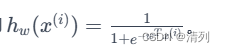
梯度下降步骤:
-
初始化参数 w:
- w 可以被初始化为零向量或者其他值。
-
计算预测值 hw(x(i))::
- 对每个样本计算模型的预测值hw(x(i)):
-
计算梯度:
- 计算对数似然函数关于参数 w 的梯度(偏导数)。
- 对于第 j 个参数 wj,梯度计算如下:
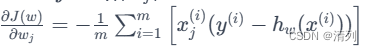
-
更新参数 w:
- 使用梯度下降更新参数:

- 其中,α 是学习率,是控制每一步迭代的步长。
- 使用梯度下降更新参数:
-
重复步骤 2-4 直到收敛:
- 重复以上步骤直到梯度下降收敛或达到预定的迭代次数。
代码示例(梯度下降的一步):
# 初始化参数
w = np.zeros((n_features, 1))
learning_rate = 0.01
m = len(y)
# 计算预测值
predictions = sigmoid(np.dot(X, w))
# 计算梯度
gradient = -1/m * np.dot(X.T, (y - predictions))
# 更新参数
w -= learning_rate * gradient
这里假设 sigmoid 函数已经定义,X 是包含所有样本的特征矩阵,y 是实际标签向量,w 是参数向量。这个过程将会被迭代多次,每次迭代都会更新参数 w,直到收敛到最优解。
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet():
dataMat = []
labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))
def stocGradAscent(dataMatrix, classLabels, numIter=150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4 / (1.0 + j + i) + 0.01 # 学习率每次迭代时都会调整
randIndex = int(random.uniform(0, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
def plotBestFit(weights):
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1, ycord1, xcord2, ycord2 = [], [], [], []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1])
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1])
ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s', alpha=.5)
ax.scatter(xcord2, ycord2, s=30, c='green', alpha=.5)
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
if __name__ == '__main__':
dataArr, labelMat = loadDataSet()
weights = stocGradAscent(array(dataArr), labelMat)
plotBestFit(weights)
实验总结:
通过本次实验,我们深入学习了Logistic回归算法的优化方法,主要包括梯度上升和随机梯度下降。以下是实验总结:
1. 数据准备: 首先,我们从文本文件中加载了包含特征和标签的数据集,用于Logistic回归的训练。
2. 梯度上升:我们实现了梯度上升算法,通过最大化对数似然函数来求解最佳的回归系数。梯度上升是一种批量梯度下降方法,每次迭代都使用全部的训练数据。
3. 随机梯度下降:我们进一步实现了随机梯度下降算法,与梯度上升相比,随机梯度下降每次迭代随机选择一个样本进行更新,以减少计算量。这种方法在大规模数据集上更加高效。
4. 模型评估:通过输出的回归系数,我们使用Matplotlib库绘制了数据集和Logistic回归的最佳拟合直线,以直观地评估模型的效果。
5. 比较:我们对梯度上升和随机梯度下降进行了比较。两种方法在一定程度上能够找到最佳的回归系数,但随机梯度下降具有更好的计算效率,尤其适用于大规模数据集。
实验收获:
1. 理解了Logistic回归的基本原理,以及如何使用梯度上升和随机梯度下降来优化模型参数。
2. 学会了通过代码实现Logistic回归的训练过程,包括数据准备、模型训练和可视化。
3. 了解了梯度上升和随机梯度下降的优劣势,以及在实际应用中的选择考量。
实验改进:
1. 可以尝试调整学习率、迭代次数等超参数,观察对模型训练效果的影响。
2. 进一步扩展实验,比较不同优化算法(如小批量梯度下降)的性能。
3. 尝试在实际数据集上应用Logistic回归,进一步验证模型的泛化能力。
通过这次实验,我们深化了对Logistic回归算法的理解,并掌握了常用的梯度优化方法,为进一步学习和应用机器学习算法奠定了基础。















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









