







前言
Pandas 是基于 NumPy 的数据分析工具,它提供了各种数据结构,如 Series 和 DataFrame,以及各种功能强大的函数,用于数据的统计、清洗、处理和分析。
一、统计函数
1. 描述性统计
Pandas 提供了多种描述性统计函数,用于快速了解数据的基本情况,例如均值、标准差、最小值、最大值等。
import pandas as pd
# 创建一个示例 DataFrame
data = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]})
# 均值
mean = data.mean()
print("均值:")
print(mean)
# 标准差
std = data.std()
print("\n标准差:")
print(std)
# 最小值
min_val = data.min()
print("\n最小值:")
print(min_val)
# 最大值
max_val = data.max()
print("\n最大值:")
print(max_val)
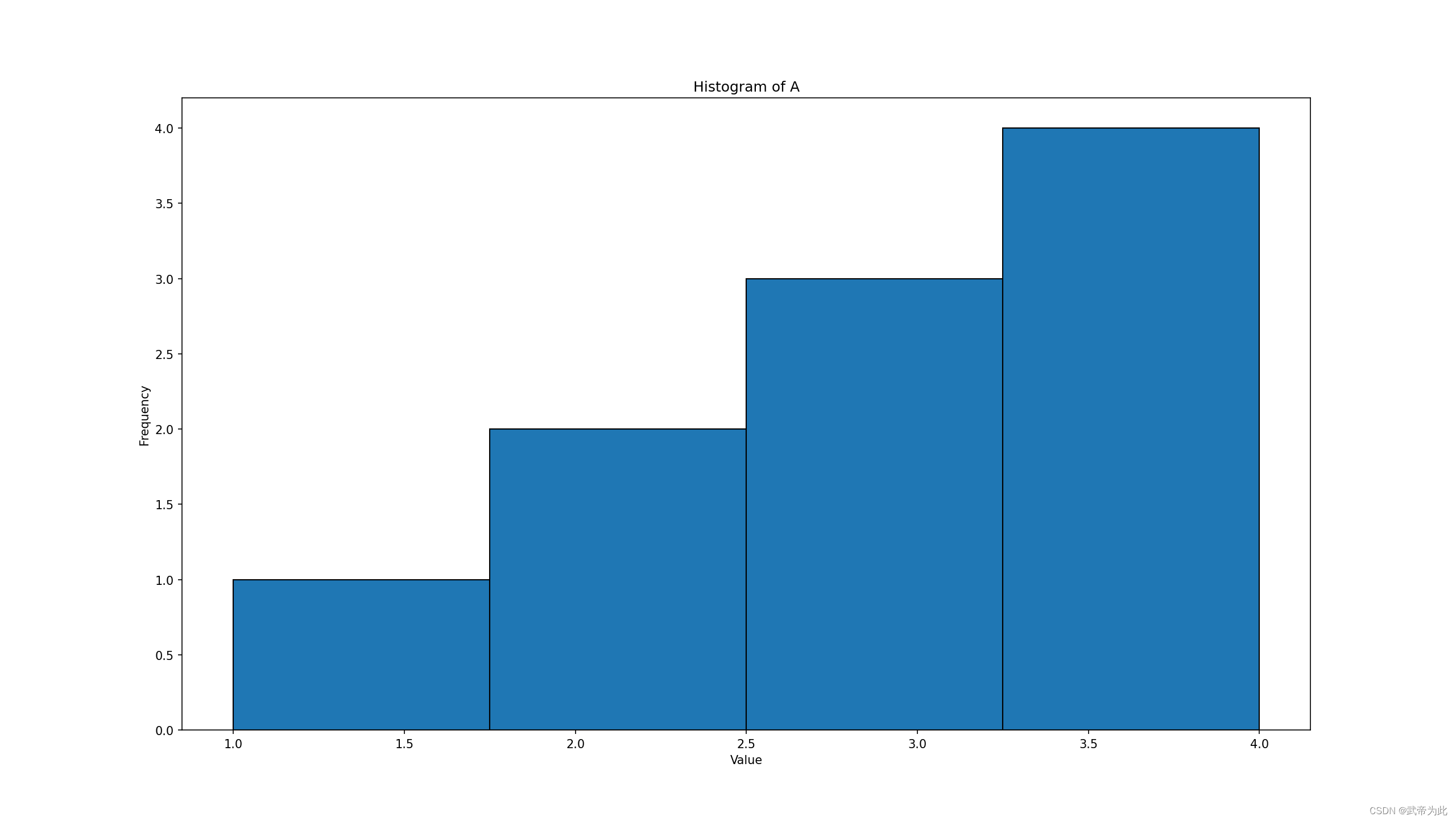
2. 直方图
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个示例 DataFrame
data = pd.DataFrame({'A': [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]})
# 绘制直方图
data['A'].plot(kind='hist', bins=4, edgecolor='k')
plt.title('Histogram of A')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
二、自定义函数
除了内置的统计函数,还可以创建自定义函数来处理数据。这些自定义函数可以根据需求进行定制,以执行特定的数据操作。
1. 自定义函数示例
创建一个自定义函数,将工资大于某个阈值的员工标记为高工资,否则标记为低工资。
import pandas as pd
# 创建示例 DataFrame
data = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Salary': [60000, 75000, 48000, 90000]})
# 自定义函数
def categorize_salary(salary):
if salary > 60000:
return '高工资'
else:
return '低工资'
# 应用自定义函数并创建新列
data['Salary_Category'] = data['Salary'].apply(categorize_salary)
print(data)
总结
Pandas 中的统计函数可以帮助我们快速了解数据的基本统计信息,而自定义函数则允许我们根据具体需求对数据进行灵活的处理。
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











