






一、SSD简介
传统的机械硬盘(HDD)运行主要是靠机械驱动头,包括马达、盘片、磁头摇臂等必需的机械部件,它必须在快速旋转的磁盘上移动至访问位置,至少95%的时间都消耗在机械部件的动作上。SSD(固态硬盘)却不同机械构造,无需移动的部件,主要由主控与闪存芯片组成的SSD可以以更快速度和准确性访问驱动器到任何位置。传统机械硬盘必须得依靠主轴主机、磁头和磁头臂来找到位置,而SSD用集成的电路(电子处理)代替了物理旋转磁盘,访问数据的时间及延迟远远优于机械硬盘。
二、SSD基本原理
固态硬盘(SSD)的基本原理涉及到 NAND 闪存存储技术和控制器。以下是 SSD 的基本原理:
1. NAND 闪存存储技术:
-
概述: NAND 闪存是一种非易失性存储技术,它使用了电子存储单元(称为存储单元或存储单元格)来存储数据。每个存储单元通常由一个或多个闪存存储晶体管组成,这些晶体管可以存储数字数据(0 或 1)。
-
读取数据: 当需要读取数据时,SSD 会通过电压的方式读取存储单元中的数据。高电压表示1,低电压表示0。因为 NAND 闪存是非易失性的,它可以在断电后保持数据。
-
擦除和写入数据: NAND 闪存的写入过程相对比较复杂。要写入新数据,首先需要将存储单元的数据擦除,然后再写入新的数据。擦除通常需要操作一个较大的块(称为擦除块),而写入可以在单个存储单元级别完成。
固态硬盘主控和NAND闪存之间的沟通需要一个桥梁,称为通道(Channel)。每个通道也都会有多个NAND闪存颗粒并行。如下4通道,每通道放8颗NAND颗粒,共32颗粒。
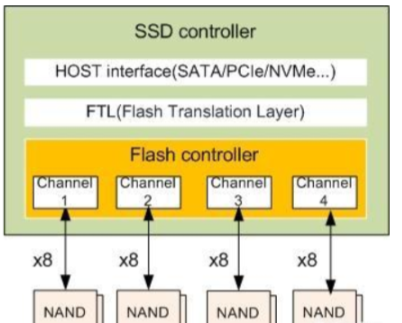
2. 控制器:
-
概述: SSD 内部配备了一个控制器,它是 SSD 的大脑,负责管理 NAND 闪存存储器的读、写、擦除等操作,同时与计算机系统进行通信。
-
读取数据: 当计算机需要读取数据时,控制器从 NAND 闪存中读取请求的数据,并将其发送到计算机系统。
-
写入数据: 当计算机需要写入数据时,控制器将数据写入闪存。写入操作通常包括擦除操作(如果需要覆盖现有数据)和写入新数据。
-
均衡负载和错误纠正: 控制器负责均衡负载,确保所有 NAND 存储单元被均匀使用,以延长 SSD 的寿命。它还负责错误检测和纠正,以确保数据的完整性。
-
垃圾回收: SSD 控制器负责垃圾回收,即将标记为已删除的数据块进行擦除,并将可用的存储单元重新分配给新的数据。
-
缓存管理: 控制器通常包含缓存(如DRAM),用于加速读写操作。缓存可以暂时存储数据,以便更快地满足计算机系统的读写请求。
综上所述,SSD 的基本原理涉及 NAND 闪存存储技术和控制器的协同工作。通过这种方式,SSD 实现了快速、可靠的数据存储和检索,相较于传统的机械硬盘(HDD),它具有更快的读写速度、更低的响应时间和更好的耐用性。
三、SSD的读写
硬盘:
早期的硬盘驱动器中,数据的存储确实是通过磁头(读/写磁头的数量)、扇区(每个磁道上的数据区块数量)和柱面(磁盘的一个圆柱形状的磁道)来进行管理的,而每个扇区通常包含512字节的数据。这种表示方法通常被称为CHS(磁头-柱面-扇区)表示法。
# fdisk -l
Disk /dev/cciss/c0d0: 146.7 GB, 146778685440 bytes
255 heads, 63 sectors/track, 17844 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytesheads/sectors/cylinders,分别就是磁头/扇区/柱面,每个扇区512byte
磁盘容量:heads*sectors*cylinders*512=255*63*17844*512=146771896320b=146.7G
现代硬盘驱动器中,由于技术的发展和存储密度的提高,CHS 表示法不再足够准确来描述大容量硬盘的物理结构。相反,现代硬盘通常使用LBA(逻辑块寻址)来寻址数据块。在LBA模式下,硬盘被看作是一系列按顺序编号的逻辑块,每个逻辑块的大小为512字节。因此,在LBA模式下,硬盘的分区和数据被表示为扇区的连续编号,而不再依赖于磁头、柱面等物理结构。
#fdisk -l
Disk /dev/nvme0n1: 953.89 GiB, 1024209543168 bytes, 2000409264 sectors
Disk model: Lexar SSD NM620 1TB
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xce01b44b
Device Boot Start End Sectors Size Id Type
/dev/nvme0n1p1 2048 2000409263 2000407216 953.9G 83 Linux/dev/nvme0n1 的 Sectors比 /dev/nvme0n1p1 Sectors小的原因:当分区被格式化为特定的文件系统时,文件系统会占用一部分空间用于存储元数据(如文件名、文件权限等信息),这部分空间不会被用户数据使用,因此分区的实际可用空间会少于硬盘的总容量。
相关解释:
-
硬盘信息:
-
设备路径:/dev/nvme0n1,这是Linux系统中硬盘的路径。
-
容量:953.89 GiB,或者说约为1TB(以1024为基础的二进制计算)。
-
总字节数:1,024,209,543,168 bytes,或者说约为1TB(以1000为基础的十进制计算)。
-
扇区数:2,000,409,264,硬盘被分割成了这么多个扇区。
-
-
硬盘型号:
-
型号:Lexar SSD NM620 1TB,这是硬盘的商标和型号。
-
-
扇区和字节信息:
-
扇区大小:每个扇区包含512 bytes。
-
逻辑/物理扇区大小:硬盘的逻辑扇区和物理扇区大小都是512 bytes。逻辑扇区是操作系统使用的单位,而物理扇区是硬盘实际存储数据的单位。
-
I/O大小:最小和最佳I/O(输入/输出)操作的大小都是512 bytes。这表示在硬盘上读取或写入数据时,每次操作都会处理512 bytes的数据。
-
-
分区信息:
-
分区表类型:这是一个DOS分区表,说明硬盘使用了DOS格式的分区表。
-
分区标识符:硬盘的唯一标识符,用于标识硬盘上的分区表。
-
-
分区信息详细解释:
-
/dev/nvme0n1p1:这是硬盘上的一个分区。
-
启动扇区:2048,分区的起始扇区。
-
结束扇区:2000409263,分区的结束扇区。
-
扇区数:2000407216,这个分区包含的扇区数目。
-
大小:953.9G,这个分区的容量。
-
文件系统类型:这个分区被格式化为Linux文件系统(类型代码83)
-
磁盘容量:sectors*512=2000409264*512=1024209543168b=953.89G
可以说硬盘的最小存储或者读写单位就是扇区,硬盘本身没有block的概念。
文件系统:
一个一个扇区来读写数据实在是太慢了,所以有了block的概念,是一个一个块在读,block才是操作系统读取的最小单位。
# df -T
/dev/nvme0n1p1 ext4 983456500 77852 933352084 1% /home/nvidia/data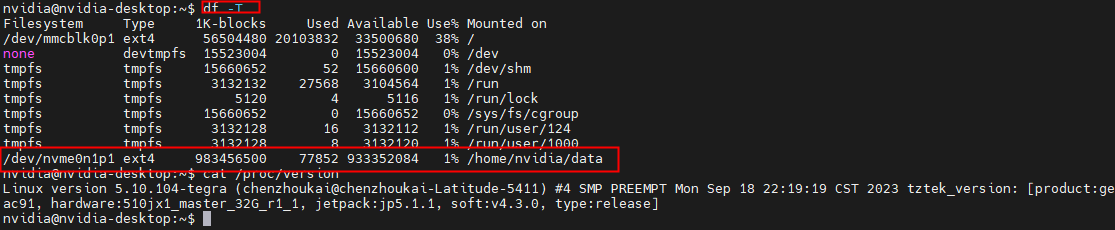
# sudo tune2fs -l /dev/nvme0n1p1 | grep "Block size"
Block size: 4096
一个block是4K,也就是说我所使用的文件系统中1个块是由连续的8个扇区组成。
总结:事实上SSD是没有扇区概念的,但是为了与HDD完全在接口层面兼容,所以SSD一样向操作系统提供了扇区参数,其次SSD都是以4K作为最低物理层面读写的最小单位,就算它向操作系统汇报512字节,实际上内部还是按照4K来读写。
四、SSD读写测试
1.常用的测试SSD读写的工具:
dd 命令:dd 命令是一个简单而强大的命令行工具,可以用于复制文件、转换文件和对设备进行低级别的读写操作;(dd 命令非常强大,但也非常危险,因为它可以直接访问硬盘设备并覆盖数据。在使用时,请确保仔细检查命令参数,避免意外的数据损失)
顺序读取:
dd if=/dev/sdX of=output_file bs=4k count=1000
# 参数解释:
# if:输入文件,指定要读取数据的文件名或设备路径。
# of:输出文件,指定要写入数据的文件名或设备路径。
# bs:块大小,指定每次读写的字节数(例如,1M 表示每次读写 1 MB 数据)。
# count:块数,指定要读写的块数目。顺序写入:
dd if=input_file of=/dev/sdX bs=4k count=1000
# 参数解释:
# if:输入文件,指定要读取数据的文件名或设备路径。
# of:输出文件,指定要写入数据的文件名或设备路径。
# bs:块大小,指定每次读写的字节数(例如,1M 表示每次读写 1 MB 数据)。
# count:块数,指定要读写的块数目。FIO命令:fio 是一个灵活的 I/O 性能测试工具,可以用于模拟各种不同的读写场景。它可以通过配置文件定义各种测试用例,包括顺序读写、随机读写、混合读写等
顺序读写:
equential-read]
rw=read ; 顺[s序equential-read]
rw=read ; 顺读
size=1M ; 测试文件大小为1M
filename=/path/to/sequential_read_test_file
direct=1 ; 使用直接 I/O 模式(绕过操作系统缓存)[sequential-write]
rw=write ; 顺序写
size=1M
filename=/path/to/sequential_write_test_file
direct=1随机读写:
[random-read]
rw=randread ; 随机读
size=4k
filename=/path/to/random_read_test_file
direct=1[random-write]
rw=randwrite ; 随机写
size=4k
filename=/path/to/random_write_test_file
direct=1混合读写:
[mixed-read-write]
rw=randrw ; 混合随机读写
rwmixread=70 ; 读操作占比70%
size=1M
filename=/path/to/mixed_read_write_test_file
direct=12.SSD读写类型
随机读写(Random Read/Write):
随机读写是指在存储介质上随机选择、访问不连续的数据块进行读写。随机读写性能对于许多应用程序来说至关重要,特别是需要快速响应小型数据请求的场景,如数据库和虚拟机存储。
顺序读写(Sequential Read/Write):
顺序读写是指按照数据在存储介质上的顺序进行连续的读写操作。顺序读写适用于处理大量大型文件或进行大规模数据传输的任务,如视频编辑、大文件复制等。
混合读写(Mixed Read/Write):
混合读写模式是同时进行随机读写和顺序读写的操作。混合读写场景常见于现实应用中,例如数据库中既有随机读写(例如事务处理),又有顺序读写(例如批量导入数据)。
大块读写(Large Block Read/Write):
大块读写操作是指读写大型数据块,通常以 MB 为单位。这种操作模式适用于需要处理大型文件的应用,如视频编辑和大数据处理。
小块读写(Small Block Read/Write):
小块读写操作是指读写小型数据块,通常以 KB 为单位。这种操作模式适用于需要快速响应小型数据请求的应用,如数据库和虚拟机存储。
五、SSD测试
功能测试:
SSD模块识别、分区、挂载、格式化、dd命令顺序读写,dd命令如下:
sudo dd if=/dev/zero of=/home/nvidia/data/test bs=100M count=20 iflag=nocache oflag=direct相关解释:
-
dd:dd 是一个用于复制和转换数据的命令行工具。它的名字 "dd" 代表"数据定义"(data definition)。它可以从一个输入源(input file)复制数据到一个输出目的地(output file),并且可以进行数据转换和处理。
-
if=/dev/zero:if 参数指定了输入源,即数据的来源。在这个命令中,输入源是 /dev/zero,这是一个特殊的设备文件,它提供无限多的空字节。
-
of=/home/nvidia/data/test:of 参数指定了输出目的地,即数据将要被写入的位置。在这个命令中,数据将被写入到 /home/nvidia/data/test 文件中。
-
bs=100M:bs 参数指定了每个数据块(block)的大小。在这个命令中,每个数据块的大小为 100MB。
-
count=20:count 参数指定了要复制的数据块的数量。在这个命令中,将会复制 20 个 100MB 的数据块。
-
iflag=nocache:iflag 参数用于设置输入标志。在这个命令中,nocache 标志用于禁用输入缓存,以确保数据从 /dev/zero 设备读取,而不是从缓存中读取。
-
oflag=direct:oflag 参数用于设置输出标志。在这个命令中,direct 标志用于启用直接 I/O 模式,确保数据直接写入到目标文件,而不是通过缓存。直接 I/O 可以提高数据写入的性能。
由于SSD的功能测试,作为SSD的使用方来说,安装SSD后,SSD可以正常模块识别、分区、挂载、格式化,以及正常的读写操作,会不会引起内核的异常报错,上面只有关于SSD的写操作,而没有SSD的读,可以增加SSD的读操作以及通过dmesg -w 查看内核日志是否有SSD相关报错
sudo dd if=/home/nvidia/data/test of=/dev/null bs=100M count=20 iflag=nocache oflag=direct性能测试:
通过fio脚本,常温和高温60℃按照块大小256M大小,进行随读写SSD内存的20%,fio命令如下(SSD为1T):
#!/bin/bash
export test=fio
gnome-terminal -t "SSD-TEST" -- bash -c " sudo iostat -d -m nvme0n1 1;exec bash;"
#随机写
echo "randwrite4k4job"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randwrite -ioengine=libaio -bs=256M -size=205G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=write_bandwidth_test -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
#随机读
echo "randread4k4job"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randread -ioengine=libaio -bs=256M -size=205G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=read_bandwidth_test -zero_buffers
echo $(date +%F%n%T)
sync相关解释:
-
export test=fio: 这一行设置了一个环境变量test的值为fio。
-
gnome-terminal -t "SSD-TEST" -- bash -c " sudo iostat -d -m nvme0n1 1;exec bash;": 这一行打开了一个新的gnome终端窗口,窗口标题为"SSD-TEST"。在这个窗口中,执行了一个iostat命令,用于实时监控nvme0n1设备的磁盘I/O活动。
-
-direct=1:使用直接 I/O 模式,绕过文件系统缓存,确保测试的是设备的实际性能而不是系统缓存的影响。
-
-iodepth=32:每个作业(job)的最大 I/O 深度,即在任何给定时间内可以在设备上进行的并发 I/O 操作的数量。
-
-rw=randwrite:进行随机写操作。这意味着数据将以不连续的方式写入设备,模拟实际应用中的随机写入负载。
-
-ioengine=libaio:指定 I/O 引擎为 libaio,这是 Linux 下一种异步 I/O 的实现,用于进行高性能的异步 I/O 操作。
-
-bs=256M:每个 I/O 操作的块大小为 256MB。这表示每次写入或读取的数据块大小。
-
-size=512G:指定测试文件的大小为 512GB。这是测试数据的总大小。
-
-numjobs=1:指定并发作业(jobs)的数量。在这个命令中,只使用一个并发作业。
-
-group_reporting:将多个作业的结果合并为一个报告,这样可以更容易地分析整体性能。
-
-filename=/dev/nvme0n1:指定测试的目标设备路径,即 SSD 的设备路径。
-
-name=write_bandwidth_test:为测试指定一个名称,以便在报告中标识。
-
-zero_buffers:在每次写操作之前将缓冲区清零。这样可以确保每次写入都是新数据,而不是之前的数据残留。
上述:
-
可以增加大块的顺序读写如1M、256M;
-
可以增加4k的随机读写;
-
可以增加4k的混合读写;(7读3写)
-
只读写SSD的20%,不太符合实际场景,可以读写SSD的80%;
-
可以增加SSD的温升测试,通过SSD的温升测试可以推测设备使用的极限温度;(如运行风扇最大转速、CPU/GPU满载,高速写入2H,监控SSD的温度是否超过10℃)
#!/bin/bash
export test=fio
gnome-terminal -t "SSD-TEST" -- bash -c "sudo iostat -d -m nvme0n1 1; exec bash;"
# 随机写
echo "randwrite256M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randwrite -ioengine=libaio -bs=256M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=write_bandwidth_test -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 随机读
echo "randread256M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randread -ioengine=libaio -bs=256M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=read_bandwidth_test -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 顺序写 1M
echo "seqwrite1M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=write -ioengine=libaio -bs=1M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=seq_write_1M -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 顺序读 1M
echo "seqread1M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=read -ioengine=libaio -bs=1M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=seq_read_1M -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 顺序写 256M
echo "seqwrite256M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=write -ioengine=libaio -bs=256M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=seq_write_256M -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 顺序读 256M
echo "seqread256M"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=read -ioengine=libaio -bs=256M -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=seq_read_256M -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 随机写 4K
echo "randwrite4k"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randwrite -ioengine=libaio -bs=4k -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=rand_write_4k -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 随机读 4K
echo "randread4k"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randread -ioengine=libaio -bs=4k -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=rand_read_4k -zero_buffers
echo $(date +%F%n%T)
sync
echo " "
# 混合读写 4K (7读3写)
echo "mixedrw4k"
echo $(date +%F%n%T)
sudo fio -direct=1 -iodepth=32 -rw=randrw -rwmixread=70 -ioengine=libaio -bs=4k -size=820G -numjobs=1 -group_reporting -filename=/dev/nvme0n1 -name=mixed_rw_4k -zero_buffers
echo $(date +%F%n%T)
sync
















 79
79

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









