






- 实验内容
决策树是一种用于分类和回归的非参数监督学习方法,作用是创建一个模型,通过从数据特征中推断出的简单决策规则来预测目标变量的值。
数据描述
部分股票数据如下: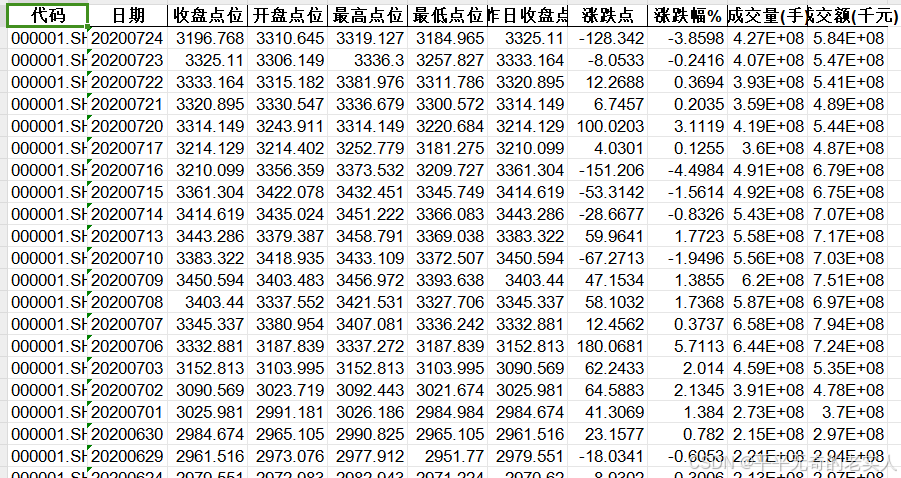
该只股票数据包含了代码、日期、收盘点位、开盘点位、最高点位、最低点位、昨日收盘点、涨跌点、涨跌幅、成交量、成交额11种指标。
要求
1.对数据进行审查,查看是否有缺失值。
2.1990-2020年该股票成交量的时间序列图。
3.2015-2020年该股票的成交量和收盘点位的时间序列图。
4.2018-2020年该股票的成交量与最高点位、最低点位、涨跌点、涨跌幅作相关性分析。
5.用决策树进行预测威力的股票涨跌情况,并输出预测结果的正确率。
- 分析过程
- 导入数据并查看
要得到数据的详细信息,需要编写的代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 解决中文乱码问题
plt.rcParams["font.sans-serif"] = "SimHei"
# 特殊符号 ——
plt.rcParams["axes.unicode_minus"] = False
data = pd.read_excel('./股票.xls')
df = data[['日期','收盘点位','开盘点位','最高点位','最低点位','昨日收盘点','涨跌点','涨跌幅%','成交量(手)','成交额(千元)']]
print(data.describe().round(4).T)
查看数据情况: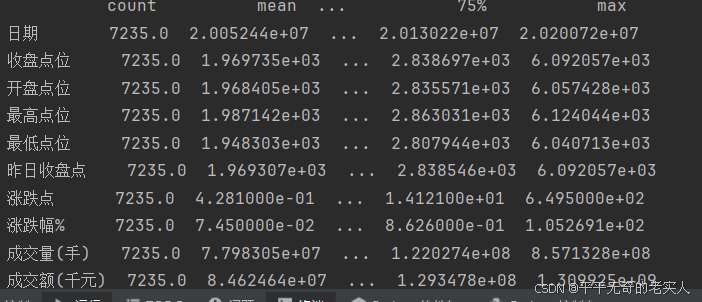
-
- 查看数据是否有缺失值
为了获取更多的数据信息,.info()方法告诉我们该数据一共7235行,且没有缺失值,代码如下所示:
print('{:*^60}'.format('数据样本:统计描述'))
print(df.info())
数据情况如下:
由上图可看出日期、收盘点位、开盘点位等数据相同,可知数据无缺失值。
-
- 1990-2020年该股票成交量的时间序列图
绘制股票1990到2020年的日成交量的时间序列图。以时间为横坐标,每日的成交量为纵坐标,作折线图,可观查股票成交量随时间的变化情况。代码如下:
import matplotlib.pyplot as plt
data['成交量(手)'].plot(grid=True,color='red',label='000001.SH')
plt.title('1990-2020 成交量', fontsize='9')
plt.ylabel('成交量', fontsize='8')
plt.xlabel('日期', fontsize='8')
plt.legend(loc='best',fontsize='small')
plt.show()
1990-2020年成交量如下图: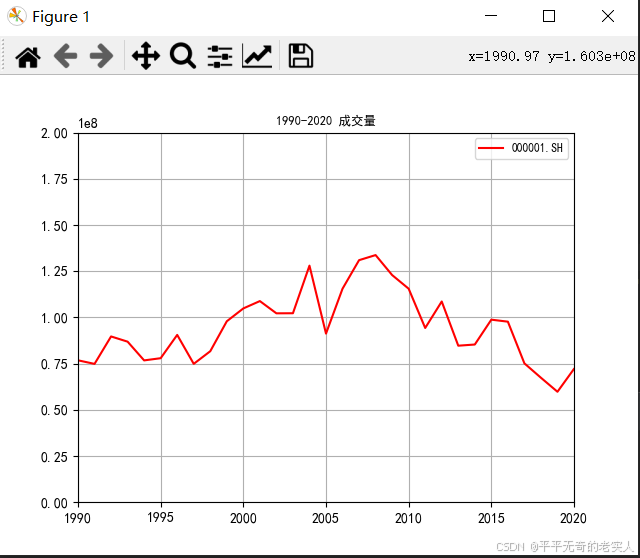
-
- 2015-2020年该股票的成交量和收盘价的时间序列图
绘制股票2015到2020年的成交量和收盘价的时间序列图,为了能同时观察这两种数据的差异,所以采用两套纵坐标系作图,代码如下:
#2015到2020的成交额
data.index.name='date' #日期为索引列
#对股票数据的列名重新命名
data.columns=['code','date','close','open','high','low','closed','up_down_point','up_down_wave','submit_amount','volume']
data=data.loc['2015':'2020'] #获取某个时间段内的时间序列数据
data[['close','volume']].plot(secondary_y='volume',grid=True)
plt.title('2015-2020 收盘位点和成交额', fontsize='9')
plt.show()
2015-2020年该股票的成交量和收盘点位如下: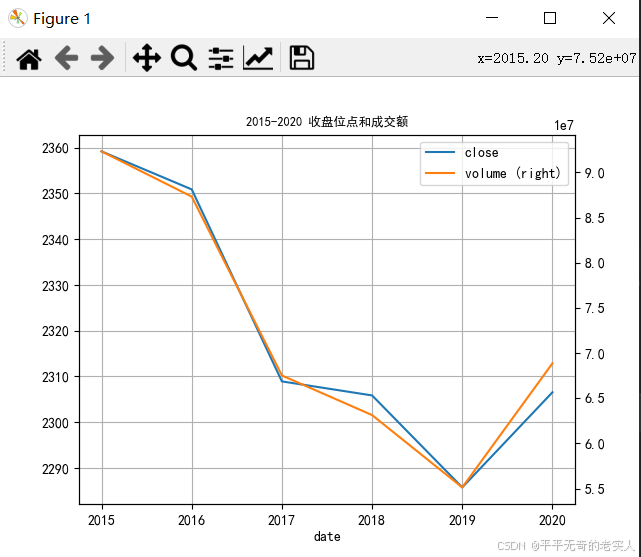
-
- 2018-2020年该股票的成交量与最高点位、最低点位、涨跌点、涨跌幅作相关性分析。
挑选股票的成交量与开盘点位、收盘点位、涨跌点、涨跌幅,并使用pandas.scatter_matrix()函数,将各项指标数据两两关联作散点图,对角线是每个指标数据的直方图。代码如下:
from pandas.plotting import scatter_matrix
#对股票数据的列名重新命名
data.columns=['code','date','close','open','high','low','closed','point','wave','submit_amount','volume']
data=data.loc['2018':'2020'] #获取某个时间段内的时间序列数据
scatter_matrix(data[['volume','open','close','point','wave']])
plt.show()
2018-2020年该股票的成交量与开盘点位、收盘点位、涨跌点、涨跌幅相关性分析如下: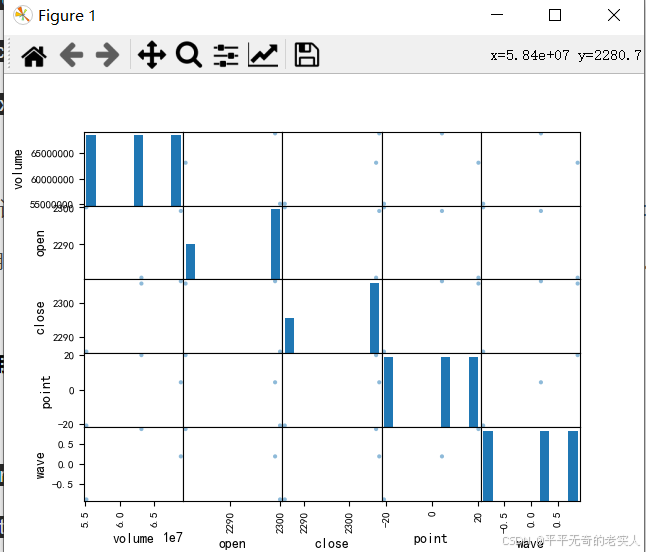
从图中可以明显发现成交量与开盘点位、收盘点位、涨跌点、涨跌幅无明显的线性关系。
-
- 用决策树进行预测股票涨跌情况,并输出预测结果的正确率。
代码如下:
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# 换手率 = 成交量 / 流通股本
df['换手率'] = df['成交量(手)'] / (df['成交额(千元)'] / df['收盘点位'])
df['20日波动率'] = df['收盘点位'].rolling(20).std()
df['收益率'] = df['收盘点位'] / df['昨日收盘点'] - 1
df['涨还是跌'] = '涨'
# 不涨不跌也是跌
df.loc[df['收益率']<=0, '涨还是跌'] = '跌'
df['下一天涨还是跌'] = df['涨还是跌'].shift(-1)
df = df[['日期', '收益率', '涨还是跌', '下一天涨还是跌', '换手率', '20日波动率']]
df.dropna(inplace=True)
df.reset_index(inplace=True, drop=True)
print(df)
# 划分训练和测试集,20%为训练集,随机种子为1(这里不考虑时间序列的问题,单纯考虑因子是否有效,现实中不能做到)
train_x, test_x, train_y, test_y = train_test_split(df[['换手率', '20日波动率']], df['下一天涨还是跌'], test_size=0.2, random_state=1)
model = DecisionTreeClassifier(max_depth=3)
model.fit(train_x, train_y)
pred_y = model.predict(test_x)
pred_df = pd.DataFrame()
pred_df['下一天涨还是跌'] = list(test_y)
pred_df['预测下一天涨还是跌'] = list(pred_y)
print(pred_df)
print('DT的涨跌预测准确率为:{:.4f}'.format(accuracy_score(pred_y, test_y)))
预测结果为: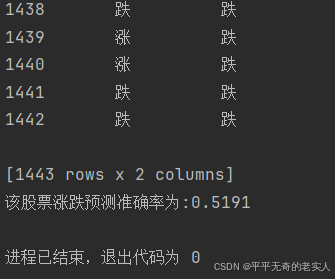

















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









