









引言:消息处理的新范式
在实时数据处理、事件驱动架构和微服务通信场景中,传统的消息队列(如RabbitMQ)虽然功能完善,但存在部署复杂、性能瓶颈等问题。Redis Streams(Redis 5.0+)作为新一代消息处理解决方案,支持每秒百万级吞吐、持久化存储和消费者组机制,同时保持Redis标志性的低延迟特性。本文将深入解析如何利用Redis Streams构建高性能、可靠的消息处理系统。
目录
一、Redis Streams 核心概念
1.1 数据结构解析
消息ID:
<timestamp>-<sequence>格式(如1651234567890-0),支持自定义消息体:由键值对组成的字典结构
消费者组(Consumer Group):实现多消费者负载均衡
Pending Entries List (PEL):跟踪已分发但未ACK的消息
1.2 与传统Pub/Sub对比
| 特性 | Redis Streams | Pub/Sub |
|---|---|---|
| 消息持久化 | ✅ 支持 | ❌ 不持久 |
| 消费者状态跟踪 | ✅ 精确控制 | ❌ 无状态 |
| 历史消息回溯 | ✅ 支持 | ❌ 仅实时 |
| 多消费者组 | ✅ 多个独立消费组 | ❌ 单一广播 |
| 消息确认机制 | ✅ XACK/XCLAIM | ❌ 无确认 |
二、核心操作实战
2.1 基础消息生产与消费
# 生产消息(自动生成ID)
XADD orders * product_id 1001 user_id 42 quantity 3
# 消费最新消息(阻塞式)
XREAD BLOCK 5000 STREAMS orders $
# 范围查询(历史消息)
XRANGE orders - + COUNT 102.2 消费者组操作
# 创建消费者组
XGROUP CREATE orders order-group $ MKSTREAM
# 消费者加入组(自动创建)
XREADGROUP GROUP order-group consumer1 COUNT 1 STREAMS orders >2.3 消息确认与重试
# 确认消息处理完成
XACK orders order-group 1651234567890-0
# 认领超时消息(死信处理)
XCLAIM orders order-group consumer2 60000 1651234567890-0三、高性能架构设计
3.1 消费者组负载均衡
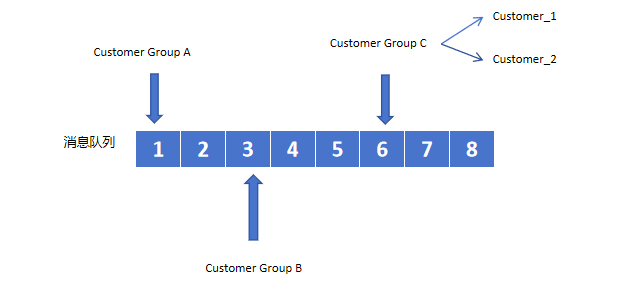
最佳实践:
每个消费者对应独立客户端实例
使用
XREADGROUP的BLOCK参数实现长轮询合理设置
COUNT参数平衡吞吐与延迟
3.2 消息分片策略
# 创建分片Stream(按用户ID分片)
XADD orders:{user_id%10} * product_id 1001 user_id 42 quantity 3优势:
水平扩展处理能力
降低单个Stream的竞争
提升消费者并行度
四、高级特性与生产调优
4.1 消息保留策略
# 设置最大长度(防止内存溢出)
XTRIM orders MAXLEN 1000000
# 按时间保留(自动清理旧数据)
XTRIM orders MINID 1651234567890-04.2 监控关键指标
| 指标 | 监控命令 | 健康阈值 |
|---|---|---|
| 消息积压量 | XLEN orders | < 分片容量80% |
| 未ACK消息数 | XPENDING orders order-group | < 消费者数*100 |
| 消费者延迟 | XINFO CONSUMERS | 最新ID差 < 1000 |
4.3 容灾与故障恢复
方案设计:
主从复制:每个分片配置Redis主从
持久化配置:AOF everysec + RDB每小时
消费者检查点:定期记录最后处理的ID
死信队列:通过XCLAIM处理超时消息
五、真实场景应用案例
5.1 电商订单处理流水线
# 生产者(订单创建)
def create_order(order_data):
redis.xadd('orders', order_data, id='*')
# 消费者组处理(库存扣减)
while True:
messages = redis.xreadgroup('order-group', 'inventory-service', {'orders': '>'}, count=10)
for msg in messages:
process_inventory(msg)
redis.xack('orders', 'order-group', msg.id)5.2 实时日志分析系统
// 日志收集端
Jedis jedis = new Jedis("redis-host");
Map<String, String> logEntry = new HashMap<>();
logEntry.put("level", "ERROR");
logEntry.put("message", "DB connection failed");
jedis.xadd("logs", StreamEntryID.NEW_ENTRY, logEntry);
// 分析服务端
Consumer consumer = new Consumer("log-group", "analytics-1");
while (true) {
List<StreamEntry> entries = jedis.xreadGroup(consumer,
StreamReadOptions.block(5000),
StreamOffset.from("logs", ">"));
analyzeLogs(entries);
jedis.xack("logs", "log-group", entries.stream().map(e->e.getID()));
}六、性能压测数据参考
测试环境:
Redis 6.2 单节点(8核/16GB)
消息体大小:500字节
| 场景 | 吞吐量(msg/s) | P99延迟(ms) |
|---|---|---|
| 单生产者单消费者 | 120,000 | 2.1 |
| 10消费者组 | 850,000 | 4.8 |
| 分片(10个Stream) | 1,200,000 | 3.2 |
优化建议:
使用Pipeline批量发送消息
避免在消息体中存储大对象
禁用非必要监控命令(如XINFO)
结语:Streams的无限可能
通过Redis Streams,开发者可以轻松构建:
实时事件处理平台
分布式任务队列
物联网设备数据管道
金融交易流水线
结合Redis原生的高性能与持久化能力,Streams正在重新定义实时消息处理的标准范式。
附录:常用命令速查
| 操作 | 命令示例 |
|---|---|
| 查看Stream信息 | XINFO STREAM orders |
| 删除消息 | XDEL orders <ID1> <ID2> |
| 监控消费者组状态 | XPENDING orders order-group |
| 重置消费者偏移量 | XGROUP SETID orders group-id 0 |


















 2352
2352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









