






决策树(Decision Tree)是一种直观且强大的机器学习算法,被广泛用于分类与回归任务。本文从核心原理(信息熵、基尼系数)、构建过程(ID3/C4.5/CART)、剪枝优化到Python代码实战,全方位解析决策树,并教你如何用Graphviz可视化树结构!
目录
一、什么是决策树?
决策树通过一系列“if-else”规则对数据进行分层决策,最终达到预测目标。其结构类似于一棵倒置的树,包含:
-
根节点:起始特征选择
-
内部节点:特征判断分支
-
叶节点:最终分类/回归结果
应用场景:客户分类、医疗诊断、金融风控(如判断贷款风险)
二、决策树的核心原理
1. 特征划分标准
决策树的关键在于选择最优划分特征,常用方法如下:
| 算法 | 划分标准 | 特点 |
|---|---|---|
| ID3 | 信息增益(熵) | 偏向多值特征,易过拟合 |
| C4.5 | 信息增益率 | 解决ID3多值特征偏置问题 |
| CART | 基尼系数(分类) 均方误差(回归) | 二叉树结构,支持分类与回归 |
2. 关键公式推导
-
信息熵(Entropy):衡量数据混乱程度
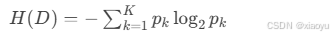
(pk为第k类样本占比,熵越小数据越纯) -
信息增益(ID3):
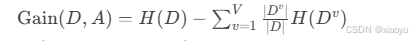
(A为特征,V为特征A的取值数) -
基尼系数(CART分类):
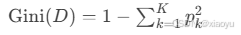
(基尼系数越小,数据纯度越高)
3. 决策树构建流程
-
从根节点开始,计算所有特征的信息增益/基尼系数。
-
选择最优特征作为划分标准,生成子节点。
-
递归执行步骤1-2,直到满足停止条件(如节点样本数过少或纯度达标)。
三、Python代码实战
1. 数据集准备
使用Scikit-learn的鸢尾花数据集:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)2. 模型训练与评估
使用CART算法(分类任务):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 创建模型(max_depth控制树深度防止过拟合)
model = DecisionTreeClassifier(criterion='gini', max_depth=3)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
print("准确率:", accuracy_score(y_test, y_pred))
3. 决策树可视化
安装Graphviz并导出树结构图:
from sklearn.tree import export_graphviz
import graphviz
# 导出dot文件
dot_data = export_graphviz(
model,
out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,
rounded=True
)
# 生成可视化图像
graph = graphviz.Source(dot_data)
graph.render("iris_decision_tree") # 保存为PDFdot文件转为png:
dot -Tpng iris_decision_tree -o iris_decision_tree.png可视化效果:
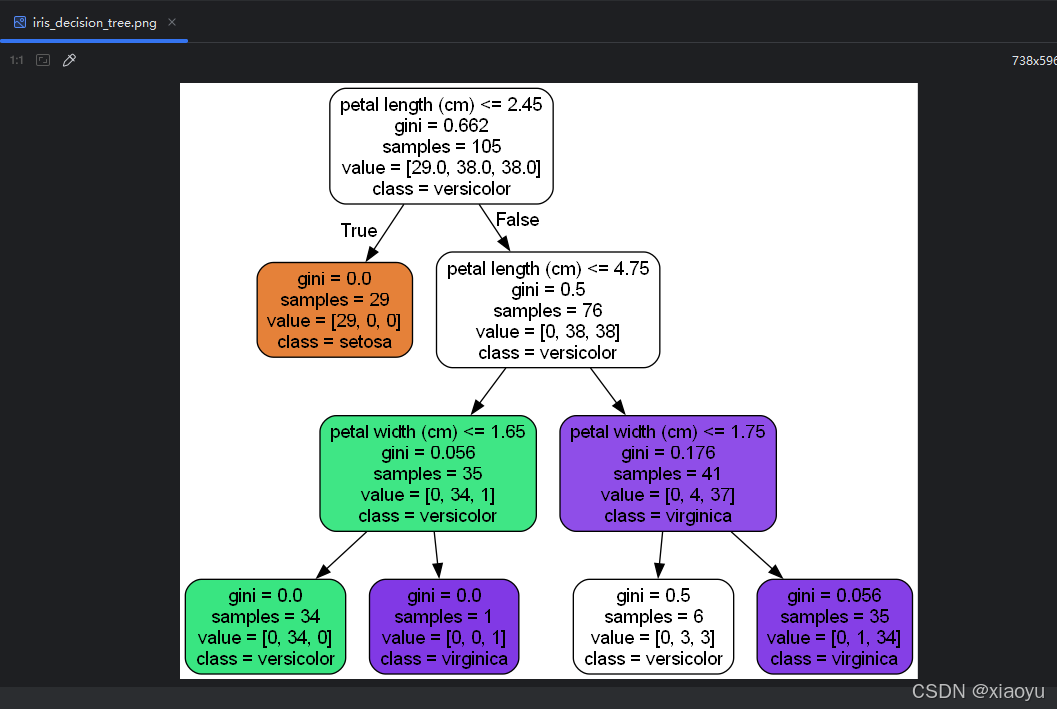
四、决策树的优化与剪枝
1. 过拟合问题
决策树容易生成复杂树结构导致过拟合,
解决方法:
预剪枝:限制树的深度(
max_depth)、最小叶子样本数(min_samples_leaf)后剪枝:通过验证集自底向上替换子树为叶节点
2. 超参数调优
使用网格搜索(GridSearchCV)寻找最优参数组合:
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [3, 5, 7],
'min_samples_split': [2, 5, 10]
}
grid = GridSearchCV(DecisionTreeClassifier(), params, cv=5)
grid.fit(X_train, y_train)
print("最优参数:", grid.best_params_)五、决策树的优缺点
优点
可解释性强,规则可视化
无需数据标准化,支持混合数据类型
可处理缺失值(通过代理分裂)
缺点
容易过拟合,需剪枝优化
对样本分布敏感,小变化可能导致树结构巨变
不适合复杂非线性关系(需结合集成学习如随机森林)
六、实战案例:泰坦尼克生存预测
使用Kaggle数据集,完整流程如下:
-
数据清洗:处理缺失值(如Age填充中位数)
-
特征工程:提取Title(Mr/Miss)、FamilySize等新特征
-
模型训练:
model = DecisionTreeClassifier(max_depth=5)
model.fit(X_train, y_train)-
提交结果:Kaggle准确率可达78%~82%
七、总结
决策树是理解树模型和集成学习(如随机森林、GBDT)的基础。其核心在于特征选择与剪枝优化。建议初学者通过可视化工具深入理解决策过程,并尝试在Kaggle比赛中应用。


















 3925
3925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









