







基于Cuda开发GPUGPU程序时,最重要的仍然是内核的设计,这是Cuda性能优化的难点,提供了不少岗位,养活了一大批工程师。这里以一个相对简单的的求平方和算法为例,从编程和优化,调试几个维度,介绍利用cuda开发并行计算程序时的关注点。
cuda API
NVIDIA CUDA计算架构为开发者提供了三个层面的API,分别是Cuda Lib, Cuda RT, 和cuda driver。cuda driver是比较底层的API,用法复杂但是性能高,可以深度二次优化,对于研发能力强的用户可以在这个层次上做出高性能的计算方案出来,其次是最常用的cuda runtime,也就是我们常用的cuda API.最上层是cudalib,cudalib提供给研发能力一般,希望快速上手的开发者,包含各类已经预先开发好的数学库和数学函数。

cuda编程模型
在CUDA编程模型中引入主机端和设备端的概念,CPU是主机端,GPU属于设备端,主机端仅有一个,而设备端可以同时有很多(比如NVLINK 8卡互联),CPU负责复杂逻辑处理和运算量少的计算,而GPU负责运行简单但是计算量大的并行计算。
一个kernel函数对应一个grid,每个grid根据需要配置不同的block数量和thread数量。从编程模型可以看出,cuda包含三个逻辑层,grid, block和thread. 一个GRID下的线程共享全局的内存空间。GRID是线程结构的第一层次,GRID下面分BLOCK,一个BLOCK包含很多个线程,线程是第三层次。
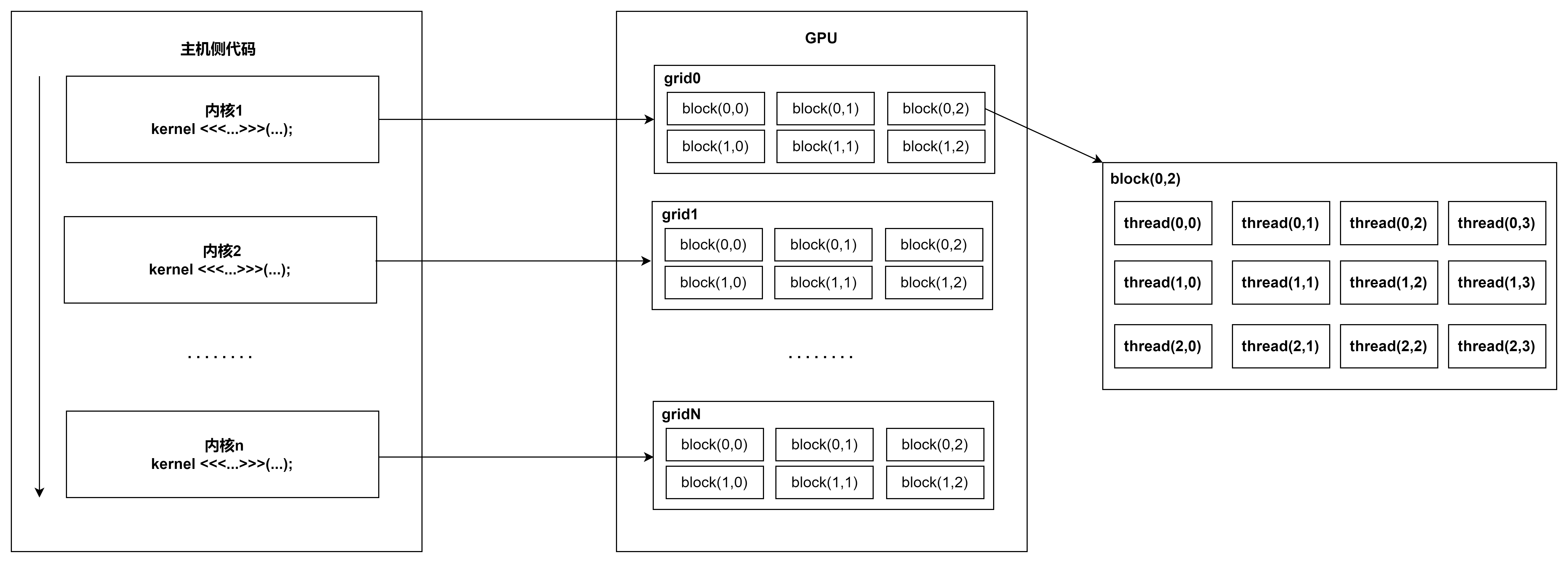
CUDA下,一个grid内只能跑一个KERNEL,KERNEL和GRID是一对一的关系,GRID是kernel launch的参数。GPU可以并行Launch多个grid.
warp
GPU编程的一个基本特点是大规模并行,让GPU内数千计的微处理器同时转向要处理的数据,每个线程处理一个数据元素,由SIMT模拟的SIMD(相比较SIMD,SIMT偏向于灵活性而损失了一部分性能)。
一方面是大量需要执行的任务,另一方面是很多等待任务的微处理器,如何让这么多的微处理器有条不紊的把所有任务都执行完毕呢?这里涉及到一个调度粒度的概念。
与军队里把士兵分成一个个小的战斗单位类似,在CUDA中,也把微处理器分成一个个小组。每个组的大小是一样的。NVIDIA 分组的粒度是32个。CUDA个这个组取了个特别的名字:Warp.
在GPU编程中,WARP(线程束)是指一组共同协作的线程,通常为32个线程。这些线程执行相同的指令,但对不同的数据进行计算。这些线程在同一个WARP中会被划分到同一个流处理器中,共享同一个指令单元和寄存器,以实现高效的并行计算。
WARP是GPU中的基本计算单元,因为GPU硬件中的每个流处理器都包含多个WARP处理器。WARP是由GPU硬件自动管理的,程序员通常只需要考虑如何将线程划分为WARP,并让它们协同工作以实现高效的并行计算。
Warp是GPU调度的基本单位,这意味着,当GPU调度硬件资源时,一次分派的执行单元至少是32个,如果每个线程的块大小不足32个,那么也会分配32个,多余的硬件单元处于闲置状态。
Warp一词来源于纺织机,纺织机的核心是织机(Loom),历经书千年的发展,世界各地的人们发明了很多织机,虽然种类很多,但是大多数织机的一个基本原理都是让经线和纬线交织到一起,通常的做法是首先部署好一组经线,然后把系着纬线的梭子穿过经线,如此往复。Warp就是经线。
在纺织中,经线的数量决定了织物的幅度,也可以认为经线的数量决定了并行操作的并行度,在CUDA中,使用Warp来代表同时操作的一批线程,也代表并行度。
在获取数据之后,在SM中以32个线程为一组的线程束(Warp)来调度,来开始处理顶点数据。Warp是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,之所以可以这么做是由于GPU需要处理的任务是天然并行的。
Warp调度器会按照顺序分发指令给整个warp,单个warp中的线程会锁步(lock-step)执行各自的指令,如果线程碰到不激活执行的情况也会被遮掩(be masked out)。被遮掩的原因有很多,例如当前的指令是if(true)的分支,但是当前线程的数据的条件是false,或者循环的次数不一样(比如for循环次数n不是常量,或被break提前终止了但是别的还在走),因此在shader中的分支会显著增加时间消耗,在一个warp中的分支除非32个线程都走到if或者else里面,否则相当于所有的分支都走了一遍,线程不能独立执行指令而是以warp为单位,而这些warp之间才是独立的。
Warp中的指令可以被一次完成,也可能经过多次调度,例如通常SM中的LD/ST(加载存取)单元数量明显少于基础数学操作单元。
由于某些指令比其他指令需要更长的时间才能完成,特别是内存加载,warp调度器可能会简单地切换到另一个没有内存等待的warp,这是GPU如何克服内存读取延迟的关键,只是简单地切换活动线程组。为了使这种切换非常快,调度器管理的所有warp在寄存器文件中都有自己的寄存器。这里就会有个矛盾产生,shader需要越多的寄存器,就会给warp留下越少的空间,就会产生越少的warp,这时候在碰到内存延迟的时候就会只是等待,而没有可以运行的warp可以切换。
算法描述
平方和算法是一种缩减算法,缩减算法指的是从多个数据中提炼出较少的数据的一类算法,在统计中求和,找最值,均值,和方差等应用中,以及在图像处理中求一副图像的总亮度等,都是缩减算法(reduction)。公式为:
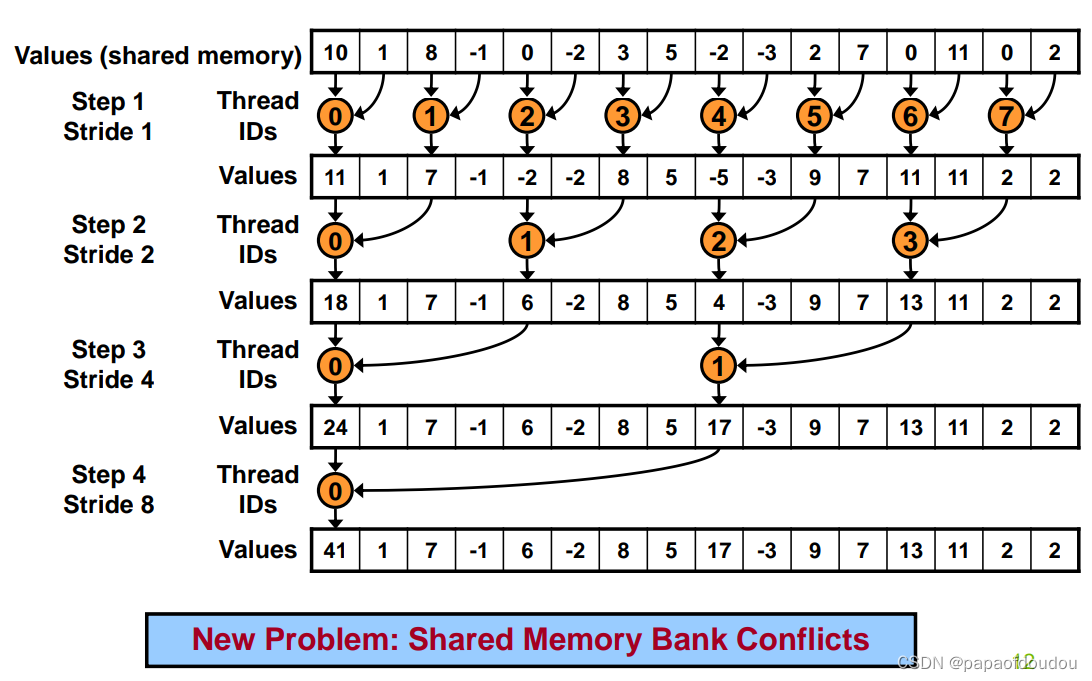
nvidia reduction 示意图:

CUDA并行编程方法
得益于数量巨大的核心数量,GPU具有强大的并行计算能力,但是它的局限性也很明显,GPU从单核的结构和ISA性能上讲,计算能力远不如CPU,优势是胜在核多。CPU有复杂的存储器缓冲系统,先进的指令缓存系统和强大的分支预测能力。而GPU中的标量处理器结构相对简单,甚至都不要求是图灵完备的(早期的GPU甚至都不支持条件分支)。CPU支持顺序执行,高效循环和跳转,而GPU相对简单的结构使它较适合处理顺序的,单一的,少循环,少跳转的语句。所以在由GPU和CPU构成的异构系统中,GPU不能独立运行。CUDA编程作为一种实现也不例外。CUDA开发的典型模式为:首先由主机分配主机端和设备端的内存,之后再将计算数据传输给GPU侧,调用设备端核函数得到运行结果,在进行设备到主机端的数据传输将结果回传给主机侧,如下图所示:

GPU Programing
GPU Programing 层次结构 as below:

sp(streaming processor) : 最基本的处理单元,最后具体的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很多个sp同时做处理。
sm(streaming multiprocessor):多个sp加上其他的一些资源组成一个sm。
warp:GPU执行程序时的调度单位,目前cuda一个warp有32个thread,同在一个warp的线程,以不同数据资源执行相同的指令。
grid、block、thread:在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread.其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和GPU本身的硬件特性。
一个BLOCK只能在一个SM上被调度,SM一般可以调度多个线程块,这要看SM本身的能力。进行划分时,最好保证每个block里的warp比较合理,那样可以一个sm可以交替执行里面的warp,从而提高效率,此外,在分配block时,要根据GPU的sm个数,分配出合理的block数,让GPU的sm都利用起来,提利用率。分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。
一个KERNEL的线程块可能被分配到一个SM上排队调度,也可能分配到多个SM上同时执行,GRID是逻辑层,而SM才是物理层。BLOCK竞争SM的的资源。SM采用SIMT方式执行。
一个KERNEL的所有线程在物理层面并不一定是同时执行的,而是按照BLOCK排队处理。SM的执行单元是WARP,一个WARP 32个线程,所以BLOCK大小一般要设置为32的倍数。
switch between different thread and block to see the warp change

初始化cuda设备:
初始化cuda设备的代码如下,通过这一步,可以获取到cuda设备的warp size,核心频率,内存大侠以及grid,block维数等信息,对于后续的调试调优有重要意义。
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
static cudaDeviceProp prop;
void init_cuda(void)
{
int count, dev;
int i;
cudaGetDeviceCount(&count);
if(count == 0) {
fprintf(stderr, "there is no cuda device.\n");
return;
} else {
cudaGetDevice(&dev);
fprintf(stdout,"there are %d cudda device found, id %d.\n", count, dev);
}
for(i = 0; i < count; i ++) {
printf("===============================Device %d==================================\n", i);
if(cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
printf("%s\n", prop.name);
printf("Total global memory: %ld Bytes\n", prop.totalGlobalMem);
printf("Max shareable memory per block %ld Bytes.\n", prop.sharedMemPerBlock);
printf("Maximum registers per block: %d\n", prop.regsPerBlock);
printf("Wrap Size %d.\n", prop.warpSize);
printf("Maximum threads per block %d.\n", prop.maxThreadsPerBlock);
printf("Maximum block dimensions [%d, %d, %d].\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("Maximum grid dimensions [%d, %d, %d].\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Total constant memory: %ld.\n", prop.totalConstMem);
printf("Support compute Capability: %d.%d.\n", prop.major, prop.minor);
printf("Kernel Frequency %d kHz.\n", prop.clockRate);
printf("Number of MultProcessors %d.\n", prop.multiProcessorCount);
printf("Is MultiGPU: %s.\n", prop.isMultiGpuBoard ? "Yes" : "No");
printf("L2 Cache Size: %d Bytes.\n", prop.l2CacheSize);
printf("Memory Bus Width: %d.\n", prop.memoryBusWidth);
printf("ECC status: %s.\n", prop.ECCEnabled? "Enable" : "Disable");
}
printf("=========================================================================\n");
}
cudaSetDevice(1);
}
int main(void)
{
init_cuda();
return 0;
}运行结果如下:
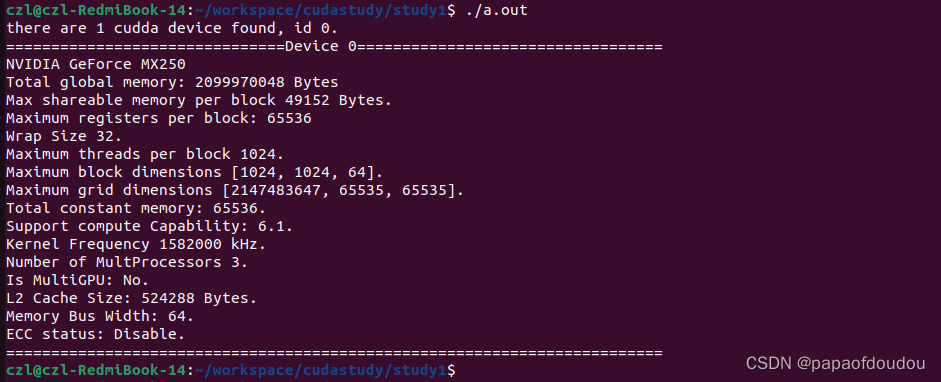
此信息和通过gpu-z工具解析到的数据是一致的,可以参考博客:
cuda-z/gpu-z/cpu-z工具分析GPU显卡和CPU算力信息_papaofdoudou的博客-CSDN博客_cuda-z
kernel运行时间统计
Kernel运行时间有GPU计时和事件记时两种,顾名思义,GPU记时是由设备端执行计时函数记录时间,相应的函数是clock. CUDA架构的GPU每个多处理器中有一个计数器,用于对核心时钟进行采样计数,clock返回的就是核心频率的计数值。通过计算kernel运行结束和运行开始的时间差值,在除以上一步得到的核心频率,即为kerne时间的运行时间。
由于设备端会同时调度多个Warper同时跑,而每个Warp由32个线程(第一步已经获取到打印出来),所以用clock函数得到的是线程从开始执行内核到执行结束所消耗的时间,并不是线程实际的指令执行时间。
Event方式要通过调用几组cuda API实现:
cudaEventCreate
cudaEventRecord
cudaEventSynchronize
cudaEventElapsedTime
cudaEventDestroy代码实现:
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#define DATA_SIZE (100*1024*1024)
#define BLOCK_NUM 32
#define THREAD_NUM 256
void generate_numbers(int *pnum, int size)
{
int i;
for(i = 0; i < size; i ++)
{
//pnum[i] = rand() % 10;
pnum[i] = 1;
}
}
__global__ static void sum_of_squares(int *pnum, int *pres, clock_t *pclock)
{
extern __shared__ int shared[];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int i;
if(tid == 0) pclock[bid] = clock();
shared[tid] = 0;
for(i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM)
{
shared[tid] += pnum[i] * pnum[i];
}
__syncthreads();
if(tid == 0) {
for(i = 1; i < THREAD_NUM; i ++){
shared[0] += shared[i];
}
pres[bid] = shared[0];
}
if(tid == 0) pclock[bid + BLOCK_NUM] = clock();
}
__global__ static void sum_of_squares_eff(int *pnum, int *pres, clock_t *clock_time)
{
extern __shared__ int shared[];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int i;
int offset = 1;
int mask = 1;
if(tid == 0) clock_time[bid] = clock();
shared[tid] = 0;
for(i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM)
{
shared[tid] += pnum[i] * pnum[i];
}
__syncthreads();
while(offset < THREAD_NUM) {
if((tid & mask) == 0){
shared[tid] += shared[tid + offset];
}
offset += offset;
mask += offset;
__syncthreads();
}
if(tid == 0) {
pres[bid] = shared[0];
clock_time[bid + BLOCK_NUM] = clock();
}
}
__global__ static void sum_of_squares_eff_2(int *pnum, int *pres, clock_t *clock_time)
{
extern __shared__ int shared[];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int i;
int offset = THREAD_NUM/2;
if(tid == 0) clock_time[bid] = clock();
shared[tid] = 0;
for(i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM)
{
shared[tid] += pnum[i] * pnum[i];
}
__syncthreads();
while(offset > 0) {
if(tid < offset){
shared[tid] += shared[tid + offset];
}
offset >>= 1;
__syncthreads();
}
if(tid == 0) {
pres[bid] = shared[0];
clock_time[bid + BLOCK_NUM] = clock();
//printf("%s line %ld\n", __func__, clock());
}
}
__global__ static void sum_of_squares_eff_intri(int *pnum, int *pres, clock_t *clock_time)
{
extern __shared__ int shared[];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int i = 0;
if(tid == 0) clock_time[bid] = clock();
shared[tid] = 0;
#pragma unroll
for(i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += __mul24(BLOCK_NUM, THREAD_NUM))
{
shared[tid] += __mul24(pnum[i], pnum[i]);
}
__syncthreads();
if(tid < 128) {
shared[tid] += shared[tid + 128];
}
__syncthreads();
if(tid < 64) {
shared[tid] += shared[tid + 64];
}
__syncthreads();
// because in the same wrap, the below thread are not need sync like above.
if(tid < 32) shared[tid] += shared[tid + 32];
__syncthreads();
if(tid < 16) shared[tid] += shared[tid + 16];
__syncthreads();
if(tid < 8) shared[tid] += shared[tid + 8];
__syncthreads();
if(tid < 4) shared[tid] += shared[tid + 4];
__syncthreads();
if(tid < 2) shared[tid] += shared[tid + 2];
__syncthreads();
if(tid < 1) shared[tid] += shared[tid + 1];
__syncthreads();
if(tid == 0) {
pres[bid] = shared[0];
clock_time[bid + BLOCK_NUM] = clock();
}
}
static cudaDeviceProp prop;
void init_cuda(void)
{
int count, dev;
int i;
cudaGetDeviceCount(&count);
if(count == 0) {
fprintf(stderr, "there is no cuda device.\n");
return;
} else {
cudaGetDevice(&dev);
fprintf(stdout,"there are %d cudda device found, id %d.\n", count, dev);
}
for(i = 0; i < count; i ++) {
printf("===============================Device %d==================================\n", i);
if(cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
printf("%s\n", prop.name);
printf("Total global memory: %ld Bytes\n", prop.totalGlobalMem);
printf("Max shareable memory per block %ld Bytes.\n", prop.sharedMemPerBlock);
printf("Maximum registers per block: %d\n", prop.regsPerBlock);
printf("Wrap Size %d.\n", prop.warpSize);
printf("Maximum threads per block %d.\n", prop.maxThreadsPerBlock);
printf("Maximum block dimensions [%d, %d, %d].\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("Maximum grid dimensions [%d, %d, %d].\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Total constant memory: %ld.\n", prop.totalConstMem);
printf("Support compute Capability: %d.%d.\n", prop.major, prop.minor);
printf("Kernel Frequency %d kHz.\n", prop.clockRate);
printf("Number of MultProcessors %d.\n", prop.multiProcessorCount);
printf("Is MultiGPU: %s.\n", prop.isMultiGpuBoard ? "Yes" : "No");
printf("L2 Cache Size: %d Bytes.\n", prop.l2CacheSize);
printf("Memory Bus Width: %d.\n", prop.memoryBusWidth);
printf("ECC status: %s.\n", prop.ECCEnabled? "Enable" : "Disable");
}
printf("=========================================================================\n");
}
cudaSetDevice(1);
}
#define USE_HOST_ALLOC
int main(void)
{
int *pdata, *psum;
clock_t *pclock;
int *pgpudata, *pres;
clock_t *pclock_t;
init_cuda();
cudaMallocHost((void**)&pdata, DATA_SIZE * sizeof(int));
if(pdata == NULL) {
fprintf(stderr, "malloc host buffer failure.\n");
return -1;
}
generate_numbers(pdata, DATA_SIZE);
cudaMallocHost((void**)&psum, BLOCK_NUM * sizeof(int));
if(psum == NULL) {
fprintf(stderr, "malloc host buffer failure.\n");
return -1;
}
memset(psum, 0x00, BLOCK_NUM * sizeof(int));
cudaMallocHost((void**)&pclock, sizeof(clock_t) * BLOCK_NUM * 2);
if(pclock == NULL) {
fprintf(stderr, "malloc host buffer failure.\n");
return -1;
}
memset(pclock, 0x00, sizeof(clock_t) * BLOCK_NUM * 2);
cudaMalloc((void**)&pgpudata, sizeof(int) * DATA_SIZE);
if(pgpudata == NULL) {
fprintf(stderr, "malloc device buffer failure.\n");
return -1;
}
#ifndef USE_HOST_ALLOC
cudaMalloc((void**)& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











