







里面 有些东西 对于现在来说都是错误的
而且由大量的细节对于现在来说没有必要
而且是过度的enginnering
一篇论文的第一段通常是讲一则故事
我们在做什么研究 哪个方向 有什么东西然后为什么很重要
正则化 regularization好像没有那么重要,并不是最关键的
最关键的是 你神经网络的设计
设计得好 哪怕没有正则化 都可以出结果的
AlexNet第一段介绍了 大数据集的好处,从当初的cifar10 到2012那个时候的ImageNet
第二段作者表示想做大cnn ,CNN做大很容易但是 也会引发两个问题
1.过拟合
2.很难训练
在写作程度上,第二段有个问题 在当时CNN并不普及 半句话没有提别人的算法
是一个很窄的角度
写的时候要提及别的方向 做一个稍微公平的introduction
第四段讲了 这篇paper的贡献contribution
1.train 了一个当时最大的网络 得到了一个很好的结果
2.写了一个实现GPU上性能很好的 2d的卷积
3.新的,不常见的 特性来提升网络的性能和降低训练训练的时间
4.一些防止过拟合的方法
5.深度很重要,少了一层效果会差一些(现在看来不全对,深度和宽度一样重要 还有就是需要调好参数)
在数据集的最后一段有一个小细节
imagenet的图像分辨率不同大小并不是统一的
Alex就把每张图片变成256256
短边先减到256 长边按高宽比下降
长边不出意外会有多余 以中心为界能把两个边会给你裁掉
不抽特征(sift) 原始上做的
之后的卖点也会是end to end
简单有效的东西是能够持久的
第三章 是整个网络的架构
relu 非线性的东西Hinton
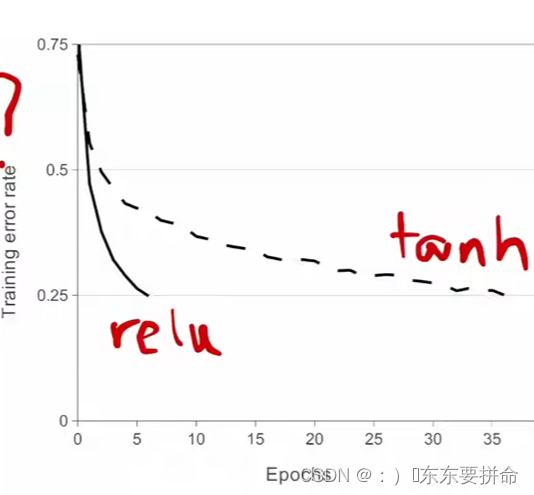
tan h 和SIGMOD
饱和的非线性激活函数会比那些非饱和的要慢
用了relu训练的特别快
而且 Relu比较简单
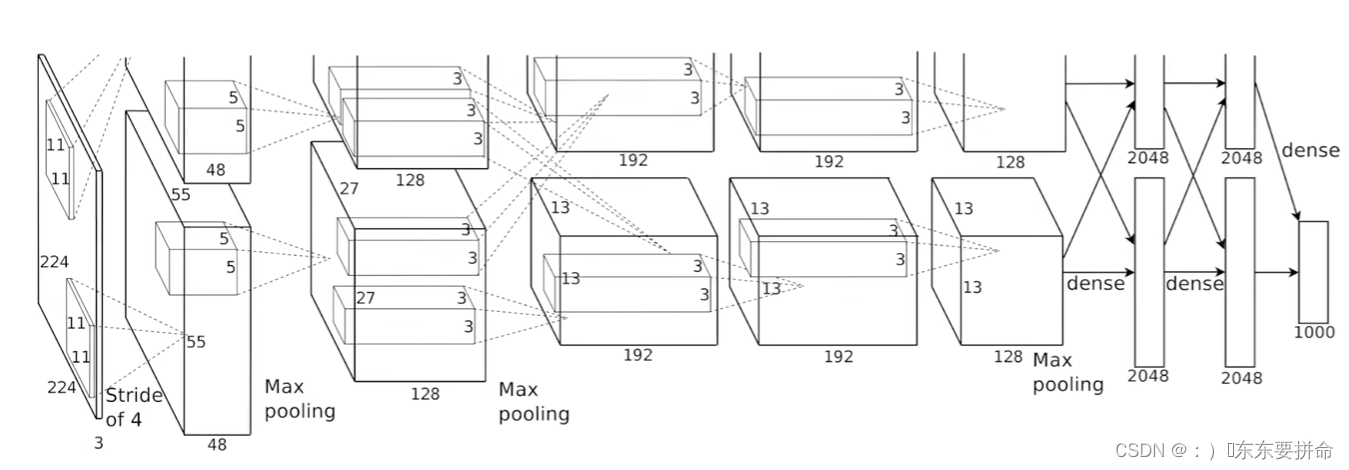
框表示每一层的输入输出这个数据的大小
有两个GPU
我就把 整个网络切开
不过 在第三层的时候 两格各自的输出都需要前面一层的输出结果
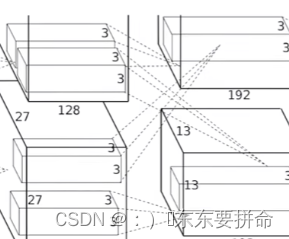
这个时候2块GPU会通讯一次
很瘪的很宽的图片然后把它高宽慢慢的变小,但是深度的慢慢的增加
随着深度的增加 我把空间信息压缩
在过程中我们发现我们的通道数在慢慢的增加
注意哦 这理由选一个细节
这个channel是干嘛的
这里的每个通道你可以当做是看待一种特定的模式
好像不说人话
一个channel 对应一个 feature
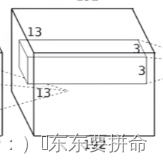
拿这个举例 这个model能够学到了图片中间的192种不同的模式
模式当做是一种知识吧 比如在识别猫的时候 猫的腿 猫的嘴巴 等等
而这个空间信息换来的是我们的语义信息越来越丰富
图像的底层特征、高层特征是什么,语义信息是什么意思_:)�东东要拼命的博客-CSDN博客_图像的低级特征往往是泛化的,如纹理,颜色等于什么
我们在继续往后 就进入了全连接层
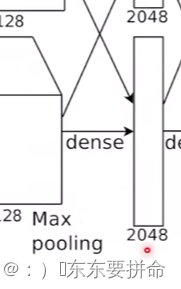
每一个 搞一个2048的全连接
最后的结果拼回成一个4096的
224224*3的image 最后进入的分类层的时候就是一个 4096的一个向量
然后用一个 线性分类器去做链接
那也就是 可以理解为 你最后看到的没有任何图片信息了哈哈
只能看到一堆数字 而这一对数字能够很好地学到图片的语义信息
你的工作要有一定的通用性 这句话对于当时来说是正确的
而当现在更大的模型出来之后 model parallel 又是一个很亮的点了
而第四节讲的是 如何降低过拟合
1.data augmentation
2.RGB的channel做一些改变(PCA主成分分析)
3.dropout(其实不是在做模型的融合,更多的是的L2正则项)没有dropout过拟合会非常严重,但是加了之后训练速度会慢上两倍
现在来看 dropout在attention和全连接上还是非常有用的
AlexNet 比较可学的点是 使用了sgd 随机梯度下降
因为sgd的里面的噪音对我们的模型泛华能力是有帮助的
weightdecay 相当于L2regularization
偏移本质上如果你的数据平衡一些的话,初始化为0
现在会用cos来平滑的降低我们的学习率(红线)

蓝色线为Alexnet中的学习率随训练轮数的变化
不过在这里 我想和大家分享一下第一学期跑分类网络遇到的两个准确率
一个是验证集的准确率 一个是测试集的准确率
验证集是可以拿来调参的 表示训练中的拟合程度
而测试集则代表着真正的detect的效果
这里吴恩达大佬有做很好的解释 用了偏差和方差来描述欠拟合和过拟合
这里也告诉大家 不用太高的准确率或者精度 八九十就差不多了
在底层的神经元或者说前面的神经层学到的是一些局部的信息低级信息
比如说纹理和方向我在笔记的前面有引用过自己写的文章这里再贴出来
图像的底层特征、高层特征是什么,语义信息是什么意思_:)�东东要拼命的博客-CSDN博客_图像的低级特征往往是泛化的,如纹理,颜色等于什么而偏上一点的学到的是全局一点 头 脸动物 高级一点的
而至于这个NN的可解释性一直比较好的研究方向
室友的师兄发了顶刊 羡慕
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











