






一、引言
自然语言处理(NLP)是人工智能中的一个重要领域,它涉及计算机理解、解释和生成人类语言的能力。前馈神经网络(MLP)是NLP任务中常用的一种模型结构,通过对输入数据进行多层线性和非线性变换,实现复杂的特征提取和分类任务。本文实验的主要目的是通过对MLP及其相关技术的实现与测试,深入理解其在NLP中的应用及效果。
二、实验内容
-
前馈神经网络的基本实现
- 实现一个简单的MLP模型,并使用其进行姓氏分类任务。
-
Dropout正则化
- 研究和实现dropout技术,并观察其对MLP模型性能的影响。
-
批处理标准化(BatchNorm)
- 在MLP模型中加入批处理标准化层,分析其对模型训练的影响。
-
1x1卷积和残差连接
- 探讨1x1卷积和残差连接的应用,并在具体实验中验证其效果。
三、实验方法
-
数据准备
- 使用一个包含不同姓氏的数据集,每个姓氏对应一个类别标签。
-
模型实现
- 实现一个基础的MLP模型,包括输入层、隐藏层和输出层。使用ReLU激活函数进行非线性变换。
- 在MLP模型中加入dropout层,设置drop概率为0.5。
- 在隐藏层和输出层之间加入批处理标准化层。
-
代码实现
import torch.nn as nn
import torch.nn.functional as Fclass MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(p=0.5) # Dropout layer
self.bn = nn.BatchNorm1d(hidden_dim) # BatchNorm layerdef forward(self, x_in, apply_softmax=False):
"""
The forward pass of the MLPArgs:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
intermediate = self.bn(intermediate) # Apply BatchNorm
output = self.fc2(self.dropout(intermediate)) # Apply Dropoutif apply_softmax:
output = F.softmax(output, dim=1)
return output
-
训练与测试
- 使用交叉熵损失函数和随机梯度下降(SGD)优化器对模型进行训练。
- 记录和分析不同模型在训练集和测试集上的表现,包括准确率和损失值。
- 训练与测试代码
import torch
import torch.optim as optim
from sklearn.metrics import accuracy_score# 超参数设置
input_dim = 100 # 假设输入维度为100
hidden_dim = 50
output_dim = 10 # 假设有10个类别
num_epochs = 20
learning_rate = 0.01# 实例化模型、损失函数和优化器
model = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 模拟训练过程
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# 假设输入数据和标签
inputs = torch.randn(32, input_dim)
labels = torch.randint(0, output_dim, (32,))
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()# 验证过程
model.eval()
with torch.no_grad():
val_inputs = torch.randn(32, input_dim)
val_labels = torch.randint(0, output_dim, (32,))
val_outputs = model(val_inputs)
val_loss = criterion(val_outputs, val_labels)
_, predicted = torch.max(val_outputs, 1)
accuracy = accuracy_score(val_labels.numpy(), predicted.numpy())
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Validation Loss: {val_loss.item():.4f}, Accuracy: {accuracy:.4f}')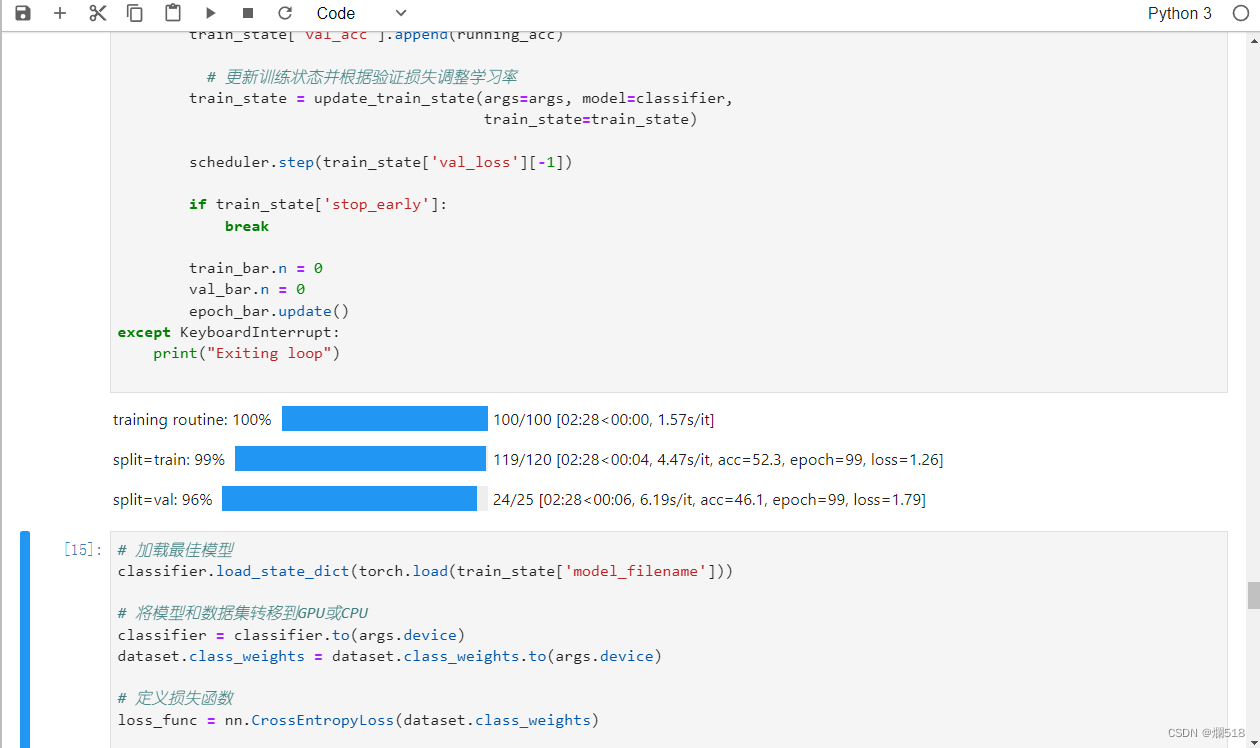
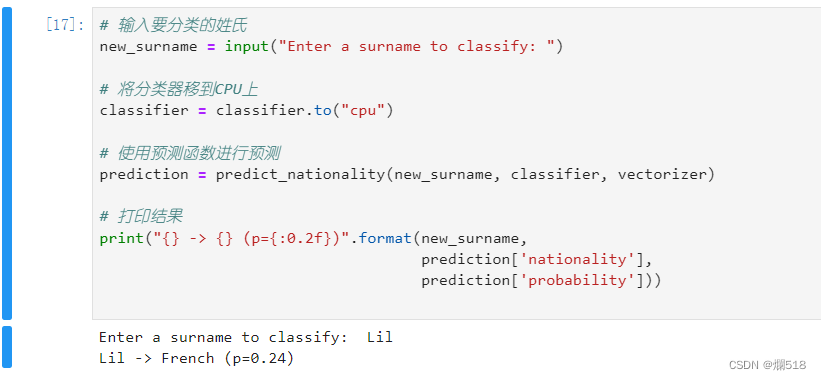
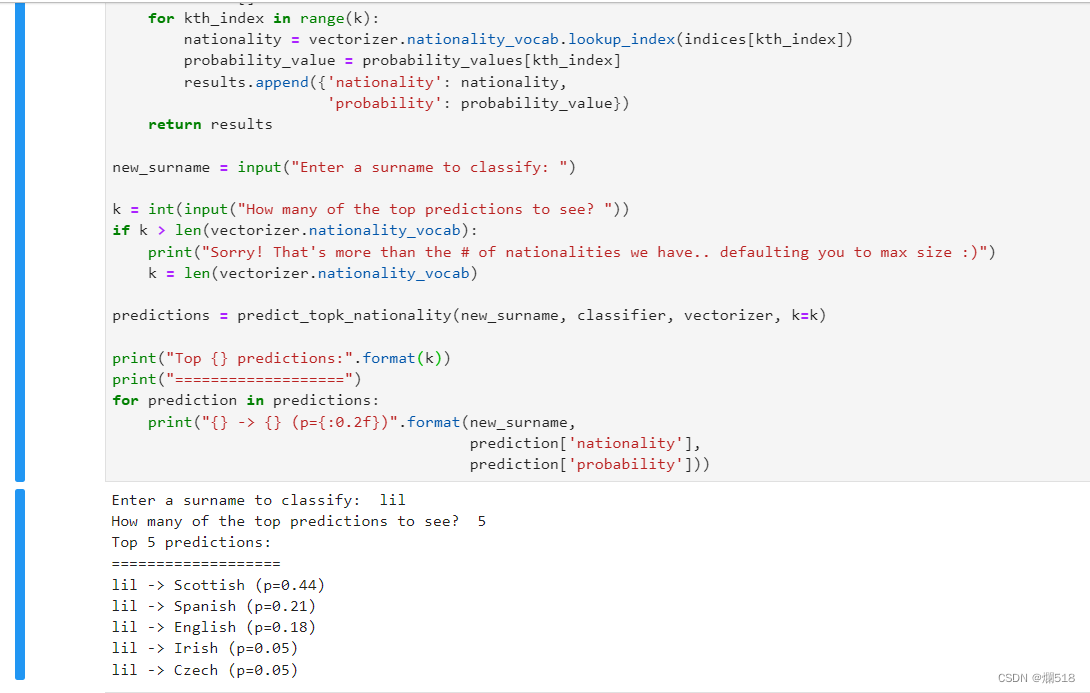
四、实验结果
-
基本MLP模型
- 训练过程中,记录模型在训练集和验证集上的准确率和损失值。
- 观察模型是否存在过拟合现象。

-
加入Dropout后的MLP模型
- 比较加入dropout前后的模型性能,分析dropout对过拟合问题的缓解效果。
- 记录dropout层的加入是否对训练时间产生影响。
-
加入BatchNorm后的MLP模型
- 比较加入BatchNorm前后的模型性能,分析BatchNorm对模型训练稳定性的影响。
- 记录BatchNorm层对训练时间和收敛速度的影响。
五、讨论与分析
-
Dropout的作用
- Dropout通过随机丢弃神经元之间的连接,减少了特征之间的相互适应,缓解了过拟合问题,提高了模型的泛化能力。
-
BatchNorm的作用
- BatchNorm对每个小批次的数据进行归一化处理,加快了模型的收敛速度,并使模型对学习率的选择更加鲁棒。
-
模型改进建议
- 根据实验结果,可以进一步优化模型的超参数,例如dropout的概率、隐藏层的大小等。
- 尝试其他正则化技术,如L2正则化,进一步提高模型性能。
六、结论
通过本次实验,我们深入了解了前馈神经网络在自然语言处理中的应用及其性能影响因素。Dropout和BatchNorm作为两种重要的正则化技术,有效地提高了模型的泛化能力和训练稳定性。本实验为进一步研究和应用深度学习模型打下了坚实的基础。
七、参考文献
- Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting.















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









