






# 第一种:两次DL求逆
import numpy as np
# 最大迭代次数,这里设置为100次,表示整个迭代过程最多进行100次循环
max_iter = 100
# 收敛精度,用于判断迭代结果是否足够接近真实解,当两次迭代结果的差值小于这个值时,认为收敛
Delta = 0.01
# 表示矩阵的行数,这里设定行数为3,即要处理的线性方程组对应的系数矩阵是3行
m = 3
# 表示矩阵的列数,同样为3,意味着系数矩阵是3列,也就是线性方程组有3个未知数
n = 3
# 函数功能:从给定的文件对象中读取张量(这里可以理解为二维数组,类似矩阵)数据,并转换为numpy数组返回
# 参数:
# - f:文件对象,从中读取数据
# - shape:一个包含两个元素的元组,表示要读取的张量的形状(行数和列数)
def read_tensor(f, shape):
data = []
# 按行读取数据,循环次数为指定的行数
for _ in range(shape[0]):
line = f.readline()
# 将每行字符串数据按逗号分割后转换为浮点数列表,再添加到data列表中,用于构造二维数组
data.append(list(map(float, line.split(","))))
return np.array(data)
# 函数功能:从给定的文件对象中读取向量(一维数组)数据,并转换为numpy数组返回
# 参数:f为文件对象,从中读取向量数据
def read_vector(f):
line = f.readline().replace("\n", "")
return np.array(list(map(float, line.split(","))))
try:
# 尝试打开名为'123.txt'的文件,如果文件不存在会抛出FileNotFoundError异常
f = open("123.txt")
# 调用read_tensor函数读取文件中的矩阵数据,传入文件对象和形状参数(m, n),得到系数矩阵A
A = read_tensor(f, (m, n))
# 调用read_vector函数读取文件中的向量数据,得到方程组右侧的常数向量b
b = read_vector(f)
f.close()
print('A:')
print(A)
print('b:', b)
# 初始化解向量x,初始值全为0,长度为n(即未知数的个数)
x = np.zeros(n)
# 开始迭代,循环次数为最大迭代次数max_iter
for iteration in range(max_iter):
# 复制当前的解向量x,用于在本次迭代中计算新的解向量,避免直接修改原解向量造成混乱
x_new = np.copy(x)
# 按行遍历系数矩阵A(这里的m表示行数),对每个方程进行处理
for i in range(m):
# 计算当前方程中除了主对角线元素对应的未知数之外,其他未知数与系数乘积的和
# np.dot(A[i, :i], x_new[:i]) 计算当前行中主对角线元素之前的系数与对应新解向量元素的点积
# np.dot(A[i, i + 1:], x[i + 1:]) 计算当前行中主对角线元素之后的系数与原解向量对应元素的点积
sigma = np.dot(A[i, :i], x_new[:i]) + np.dot(A[i, i + 1:], x[i + 1:])
# 根据高斯-赛德尔迭代法的公式,更新当前未知数的解
x_new[i] = (b[i] - sigma) / A[i, i]
# 打印当前迭代的解向量信息,包括迭代次数和对应的解向量值
print(f'Iteration {iteration + 1}: x = {x_new}')
# 判断当前迭代结果与上一次迭代结果的差值是否小于收敛精度Delta
# np.max(np.abs(x - x_new)) 计算两次解向量对应元素差值的绝对值的最大值
if np.max(np.abs(x - x_new)) < Delta:
print('收敛于第', iteration + 1, '次迭代')
break
# 如果未收敛,将本次迭代得到的新解向量赋值给原解向量,用于下一次迭代
x = x_new
print('最终解 x:', x)
except FileNotFoundError:
print("文件 '123.txt' 不存在,请检查文件路径")
except np.linalg.LinAlgError:
print("矩阵求逆过程中出现问题,可能矩阵不可逆,请检查数据")
# 第二种:三次处理
import numpy as np
# 函数功能:创建一个与输入矩阵A维度相同的全零矩阵,以列表形式返回
# 该函数主要用于后续存储一些中间计算结果等用途
def get_base(A):
base = list(np.zeros((len(A), len(A))))
D = []
for i in base:
D.append(list(i))
return D
# 函数功能:根据输入矩阵A,获取其对应的上三角部分取负后的矩阵
# 具体实现是先通过get_base函数获取一个初始全零矩阵,然后按照规则填充相应元素
def get_U(A):
D = get_base(A)
i = 0
while i < len(A):
k = i + 1
while k < len(A):
D[i][k] = -A[i][k]
k = k + 1
i = i + 1
return D
# 函数功能:根据输入的矩阵A和已经求得的上三角取负后的矩阵U,计算得到D - L矩阵
# 这里是将A矩阵和U矩阵对应元素相加,然后将结果以列表形式返回
def get_DL(A, U):
AA = np.array(A)
UU = np.array(U)
DDLL = AA + UU
DL = []
for i in DDLL:
DL.append(list(i))
return DL
# 函数功能:对输入的矩阵DL求逆,先将列表形式的DL转换为numpy矩阵类型,然后调用.I属性求逆矩阵
# 返回求得的逆矩阵DL2
def get_Dt_I(DL):
DLI = np.mat(DL)
DL2 = DLI.I
return DL2
# 函数功能:根据求得的D - L矩阵的逆DLI和上三角取负后的矩阵U,计算迭代过程中的系数矩阵B
# 通过矩阵乘法运算 DLI * U1 得到矩阵B并返回
def get_B(DLI, U):
U1 = np.mat(U)
B = DLI * U1
return B
# 函数功能:根据求得的D - L矩阵的逆DLI和输入的右端项向量b,计算迭代过程中的常数项向量f
# 先将b转换为numpy矩阵类型,然后通过矩阵乘法运算 DLI * b1.T 得到f并返回
def get_f(DtI, b):
b1 = np.mat(b)
f = DtI * b1.T
return f
# 函数功能:将输入的矩阵形式的数据x进行处理,先将矩阵元素转换为列表形式,然后提取每个子列表中的第一个元素
# 最终将这些元素组成一个新的列表ans并返回,主要用于将计算结果整理成合适的格式
def matrix_to_11st(x):
d = []
ans = []
for i in x:
d.append(i.tolist())
for i in d:
ans.append(i[0])
return ans
# 函数功能:执行一次迭代计算过程
# 该函数依次调用前面定义的函数,先获取U、DL、DL的逆、B、f等相关矩阵和向量,然后根据当前的解向量x0
# 通过计算 B * x + f 得到下一次迭代的解向量(经过格式整理后返回)
def rol1(A, b, x0):
U = get_U(A)
DL = get_DL(A, U)
DLI = get_Dt_I(DL)
B = get_B(DLI, U)
f = get_f(DLI, b)
x = np.mat(x0).T
y = B * x + f
return matrix_to_11st(y.T)
# 函数功能:控制整个迭代过程,直到满足给定的误差阈值e为止
# 首先初始化迭代次数n、结果列表ans和ans1等,然后不断调用rol1函数进行迭代,每次迭代将新的解向量添加到ans中
# 最后整理结果列表ans1并返回结果列表ans1以及迭代次数相关信息(len(ans1) - 2)
def main(A, b, x0, e):
n = 0
ans = []
ans.append(x0)
ans1 = []
ans1.append(x0[0])
while n == 0 or abs(ans[-1][0][1] - ans[-2][0][1]) > e:
n = n + 1
x0 = rol1(A, b, x0)
ans.append(x0)
for i in ans:
ans1.append(i[0])
return ans1, len(ans1) - 2
# 定义系数矩阵A,代表线性方程组的系数
A = [[10, 3, 1], [2, -10, 3], [1, 3, 10]]
# 定义右端项向量b,对应线性方程组等号右边的值
b = [[14, -5, 14]]
# 初始解向量x1,作为迭代的起始点
x1 = [[1, 1, 2]]
# 通过rol1函数获取第一次迭代前的初始解向量x0
x0 = rol1(A, b, x1)
# 设定误差阈值e,用于控制迭代停止的条件
e = 0.00001
# 调用main函数进行迭代求解,并打印最终的结果(包含迭代结果列表和迭代次数相关信息)
print(main(A, b, x0, e))
返回结果: 第一种
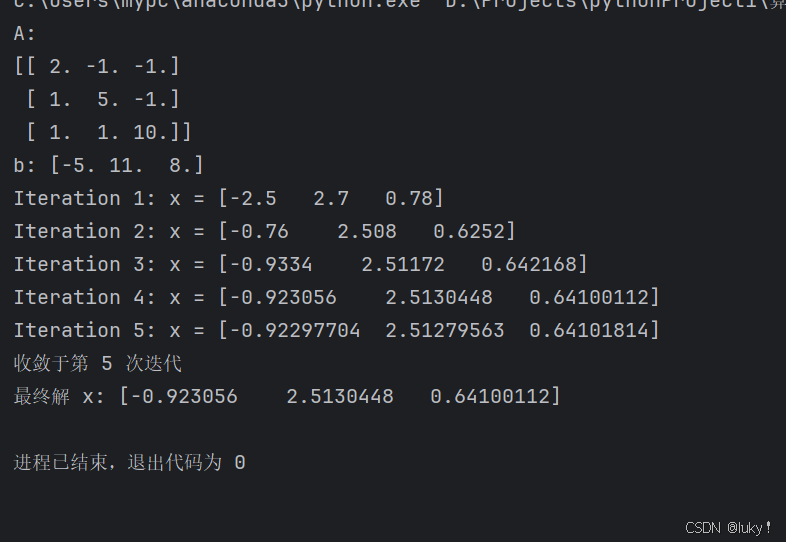
第二种:



















 5194
5194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











