







本周周报,虽然说是周报,但其实是对一直以来的尝试的各个思路的梳理。目的是理清楚方向,争取能早点实现一个能达到 SOTA 效果的方案,下周就写不了这么多了。
1. 多标签分类
本节介绍多标签分类的基本概念,描述要解决的问题,为自己理清思路。
1.1 MLC 的概念
多标签分类是相对于传统的单标签分类而提出的概念。
单标签分类
传统分类问题的数据集由
D
=
{
x
i
,
y
i
}
i
=
1
n
\mathcal{D}=\left\{\boldsymbol{x}_i, y_i\right\}_{i=1}^n
D={xi,yi}i=1n 构成,其中
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
m
)
\boldsymbol{x}_i=\left(x_{i1},x_{i2},\cdots, x_{im}\right)
xi=(xi1,xi2,⋯,xim) 是一个特征向量,也被称为实例,其中每个分量是一个属性,而
y
i
y_i
yi 是一个标量,指的是标签。
单标签二分类问题中, y i y_i yi 的取值有两种情况,即 y ∈ { 0 , 1 } y\in\left\{0,1\right\} y∈{0,1},这两种情况是 互斥 的,只能取其中一个值。解决该问题就是要学习一个函数,它以 x i \boldsymbol{x}_i xi 为输入,以 y ^ i \hat{y}_i y^i 为输出, y ^ i \hat{y}_i y^i 就是我们的预测结果。
在单标签多分类问题中, y i y_i yi 仍然是一个标量,只不过其取值有更多的可能,每种可能之间仍然是 互斥 的。之所以提一句多分类,是因为多标签分类容易与多分类混淆。
多标签分类
在多标签分类(MLC)中,数据集形如
D
=
{
x
i
,
y
i
}
i
=
1
n
\mathcal{D}=\left\{\boldsymbol{x}_i, \boldsymbol{y}_i\right\}_{i=1}^n
D={xi,yi}i=1n,其中
y
i
=
(
y
i
1
,
y
i
2
,
⋯
,
y
i
q
)
\boldsymbol{y}_i=\left(y_{i1},y_{i2},\cdots, y_{iq}\right)
yi=(yi1,yi2,⋯,yiq) 。就是说,在多标签中,一个实例对应的标签不是一个 标量,而是一个 向量。该向量中每一个分量代表一种标签,标签与标签之间是 不互斥 的。
值得注意的是,通常所说的 MLC,实际上更应该被称为 多标签二分类 问题,因为标签向量中的每个分量只有两种取值,即 y i ∈ { 0 , 1 } q \boldsymbol{y}_i\in\left\{0,1\right\}^q yi∈{0,1}q。
MLC 的特点
既然与单标签分类是不同的问题,那么多标签分类显然也具有与单标签所不同的问题特性,通常来说,合理的利用这些特性,是提升 MLC 模型性能的关键。
- 标签相关性: 即,标签与标签之间并非独立的,标签 l i \boldsymbol{l}_i li 可能与标签 l j \boldsymbol{l}_j lj 存在很强的 标签共现 现象,那么如果预测到 l i \boldsymbol{l}_i li 极有可能存在,则 l j \boldsymbol{l}_j lj 存在的可能性应该也不会低
- 类别不平衡: 通常来说,多标签数据集中 + 1 +1 +1 的数量要远比 − 1 -1 −1 少,这是一个客观事实。当然,这也可以被称为 稀疏性
1.2 MLC 的趋势与子领域
MLC 分类发展到现在,可以玩的花样已经被各路大佬玩得差不多了,所以这也是一个令人头疼的问题,现在要提升单纯的 MLC 模型性能已经很难了。因此,许多大佬开了新坑,将 MLC 的问题更特化,涌现了一批新的 MLC 研究方向。
2021 年发表在 TPAMI 上的综述 The Emerging Trends of Multi-Label Learning 总结了 MLC 现如今的新方向,分别是
- 极限多标签 XMLC
- 监督受限的多标签: 包括 缺失标签、偏多标签 PML、半监督多标签 等
- 深度学习多标签 (Deep Learning for MLC): 深度学习近年来是香饽饽,在多标签领域也发展出了一条线,但其实以多标签图像、文本分类为主,个人认为并没有泛化到单纯的多标签问题上
- 在线多标签学习
- 统计多标签学习
- 新的应用: 主要指 MLC 在计算机视觉、自然语言处理和数据挖掘方面的应用
这些方向的具体内容,有兴趣可以自行了解,但我不多提了(毕竟我也不太了解)
2. 方案
本节主要按几个阶段梳理一下我的各种(失败的)尝试,分清楚所做的哪些操作是有用的,哪些是无用的,从而为后续的方案设计理清思路。
2.1 最初的起点
方案思路: 邻居调整
- 针对每个标签 l i \boldsymbol{l}_i li,寻找其 k k k 近邻标签,使用邻居标签调整 l i \boldsymbol{l}_i li
- 针对每个实例 x i \boldsymbol{x}_i xi,寻找其 k k k 近邻标签,使用邻居标签的标签向量来调整该实例的标签向量 y i \boldsymbol{y}_i yi
- 融合调整后的两个矩阵,令其作为新的拟合目标 Y ~ \tilde{\mathbf{Y}} Y~,训练分类器
remark:
最开始的方案想法比较自然,也比较简单,但是很遗憾效果不好。邻居调整的动机是为了利用 标签相关性,因为将近邻标签融合进了原始标签中,理论上来说是有道理的。然而实际操作中却产生了不少问题。
- 各个邻居的权重应该占多少?
我试过了多种方案,包括各个邻居按相同权重投票( k k k-NN 的基本想法),各个邻居按相似程度决定权重等。但是最终的效果都很糟糕,而且无一例外的是,使用调整后的标签矩阵作为拟合目标效果要差于不调整标签矩阵而直接训练分类器的效果。也就是说,所进行的操作起到的是负面作用,没有能够带来好的改善。
反思:
其实利用标签相关性来提升模型性能,本质上做的事情是令分类器学习到真正有助于分类的信息,将无关信息给剔除掉(无关信息这里指的是训练集中有的,但并非与分类真正相关的信息,它会造成泛化性能的下降,因为测试集中不一定会有这些信息,学了这些东西就会造成误导)
邻居调整的思路是正确的,但问题在于 如何保证剔除掉的是无关信息?。在该方案中,我们修改了训练集的标签矩阵,使得其分布与测试集的分布大不一样了,因此,效果差也是理所当然了。根据我的实验来说,调整的力度越大,效果越差,这也证明了这一点。
因此,我认为,进行暴力的先验的调整是不可取的,因为训练集中的杂讯究竟是怎么样的,我们并不清楚,这样的调整会破坏训练集的数据分布,导致根本学习不到正确的分布。
方案思路: 在训练中调整
- 将邻居调整的权重设置为可训练参数
remark:
实验效果相比预先确定的调整方式来说,有提升,但是效果仍然可以称之为非常糟糕。
反思:
机器学习可以分为
3
3
3 个部分,即 模型,策略 与 优化算法。选定模型,就是选定了一个函数集合,所谓的学习过程就是要从这个函数集合中选出一个能较好的完成我们的任务的函数。而策略(通常以损失函数的形式出现)就是给我们一个 评价好与坏的标准,使我们能够衡量,哪个函数能够更好的完成我们的任务。优化算法,就是具体从函数集合中筛选函数的算法。
通常来说,优化算法基本是用的 Adam,SGD 等最优化算法,个人感觉这一部分更靠近数学那边,因此大多数的 MLC 论文都着重关注于模型与策略的部分(更多的还是在策略上,毕竟模型上的创新一般是大创新了)。
我认为该方案的效果不佳,在于策略的引导不够,因为我当时的损失函数只用了 均方误差,没有考虑更多的约束。
2.2 混乱期
这段时间主要是在 follow 2022 年发表在 TPAMI 上的论文 PML-NI,可以说是度过了一段混乱的日子。
反思:
这主要是由于当时没有弄清楚 MLC 各个领域之间关系所导致的。PML 是 MLC 的一个子领域,相比较而言,它比 MLC 有更多特化的限制。对于 PML-NI 这篇文章来说,我个人认为是难以 follow 的。
该算法采用线性模型,主要工作是在 策略 的方面,即设计损失函数(但其实我认为其主要的贡献是对 PML 问题的一个视角,这也是我认为其难以 follow 的原因)。其损失函数如下:
min
W
,
U
,
V
1
2
∥
Y
−
W
Φ
∥
F
2
+
λ
2
∥
W
∥
F
2
+
β
∥
U
∥
tr
+
γ
∥
V
∥
1
\underset{\mathbf{W},\mathbf{U},\mathbf{V}}{\min}\frac{1}{2}\left\Vert\mathbf{Y}-\mathbf{W\Phi}\right\Vert_F^2+\frac{\lambda}{2}\left\Vert\mathbf{W}\right\Vert_F^2+\beta\left\Vert\mathbf{U}\right\Vert_\text{tr}+\gamma\left\Vert\mathbf{V}\right\Vert_1
W,U,Vmin21∥Y−WΦ∥F2+2λ∥W∥F2+β∥U∥tr+γ∥V∥1
s
.
t
.
W
=
U
+
V
s.t.\quad\mathbf{W}=\mathbf{U}+\mathbf{V}
s.t.W=U+V
简单说,该论文作者认为,PML 问题中存在一些 模棱两可 的东西,这些东西本身是很少的。因此将分类器
W
\mathbf{W}
W 拆解成对真实标签的分类器
U
\mathbf{U}
U 和对杂讯的鉴别器
V
\mathbf{V}
V。
损失函数一共 4 4 4 项,分别是基本的损失函数,对模型的复杂度控制正则项,标签相关性正则项(认为标签之间是线性相关,因此用 tr \text{tr} tr 范数正则约束其秩,其实本来是直接约束秩,然而不好优化,作者直接给换成 tr \text{tr} tr 了),鉴别器正则项(杂讯是很少的,因此杂讯鉴别器用 ℓ 1 \ell_1 ℓ1 正则约束为稀疏)。
由于很少有 PML 的数据集,所以作者的实验中大部分是使用多标签数据集改造得来的。具体来说,作者认为,PML 数据集应该具有这样的特性,然后根据这些特性改造了多标签数据集(注意,其中的杂讯不是随机添加的,是根据作者认为 PML 应该具有的特征添加的,这个添加方法还蛮巧妙的)。然后又根据这些特性,设计了如上损失函数。。。
说起来有点自己挖坑自己填的意思,所以我虽然认为该文作者的观察非常有道理,但是却难以 follow。
2.3 线性方案时期
这一阶段主要 follow 2019 年发表在 INS 上的 LSML,2020 年发表在 IEEE Transactions on Cybernetics 上的 MSWL,以及 2018 发表在 TKDE 上的 GLOCAL。这几篇文章都是涉及到了 Missing Label 的问题,其中 LSML 直接使用标签相关性矩阵来补齐缺失标签,MSWL 则使用标签线性组合来重构缺失标签,GLOCAL 使用传统的矩阵分解来应对缺失标签问题。
此外,这些方案的着重点也都在策略上,即,设计损失函数。因此,在这一阶段,我主要也是通过弄各种正则项来试图提升模型的性能。这其中包括
- 使用 ℓ 1 \ell_1 ℓ1 范数或者 ℓ 2 , 1 \ell_{2,1} ℓ2,1 范数来进行特征选择,label-specific 特征的选取
- 流形正则的使用
- 标签相关性的几种使用方式
具体来说,有些正则项我认为对我的模型性能是有提升的,我还用得上的,在此就不细说了。
方案思路: 线性相关重构
- 使用流形正则和标签相关性进行重构来调整标签
remark:
实验效果相比之前来说,有不少的提升,在个别数据集上也能达到一个不错的效果。然而在大多数的数据集上,并不能取得 SOTA 效果,只能说是中庸。但是相较于之前阶段的版本(效果被 SOTA 吊打)来说,也还算是有提升,但是还不够。
到这里,就需要提到模型了。最开始的时候,我使用的模型是神经网络,更具体的来说,是多层感知机 MLP。但是由于有些正则手段在 MLP 上不是很好用,再加之后来 follow 的文章主要是线性模型,以设计策略为主,因而就转到了线性模型上。
然而,线性模型存在的问题在于其本身拟合能力有限,只能处理线性可分的数据,如果数据本身是线性不可分的,设计再多的正则项也无能为力。在我的实验中,Image 数据集上的效果非常不好,打印出训练集的损失函数曲线后,发现模型欠拟合。因此,使用线性模型是不够的。
但是舍弃线性模型,一些有用的手段就难以再使用,或者说效果大打折扣(例如用 ℓ 1 \ell_1 ℓ1 进行特征选择等),因此这也使我陷入了一段时间的迷茫(感觉之前的功夫白费了,心累啊)。
2.4 重回 Deep Learning
神经网络具有很强的拟合能力以及特征提取能力,但是要将神经网络应用 MLC 并没有那么容易。其中一个原因就在于广泛应用于深度学习中的卷积、池化操作不能用于 MLC 中。
我认为卷积 + + + 池化之所以能够在图像、文本分类中取得巨大的成功,在于这些数据本身具有的局部性和平移不变性。譬如说,判断一张图像中是否有“猫”这个标签,那么决定猫这个标签的属性一定是在一块较小的二维矩阵中的,这就是局部性。因此,可以用一个较小的卷积核来学习针对于这一标签的模式。此外,不论猫处于图像中的哪个位置,决定该标签的属性的模式始终是不变,因此,可以用卷积核实现参数共享,大大降低复杂度。
再以一个一维的例子来说,实例 x i = ( x i 1 , x i 2 , ⋯ , x i m ) \boldsymbol{x}_i=\left(x_{i1},x_{i2},\cdots, x_{im}\right) xi=(xi1,xi2,⋯,xim) 是一个文本分类数据的实例,其局部性就体现在决定标签的属性在位置上是相邻的。假设选择卷积核的大小为 ( 1 , 3 ) \left(1,3\right) (1,3),也即设定标签由 3 3 3 个特征所决定,那么对于 m m m 个特征,总共只有 m − 2 m-2 m−2 种可以尝试的组合。而 MLC 的数据集不具备这样的特性,如果要从 m m m 个特征中选取 3 3 3 个特征来进行特征选择,有 C m 3 C_m^3 Cm3 种可能的选择,这太大了。
因此,在 Deep Learning for MLC 的研究中,有许多用到了 CNN 的方法是直接将多标签的范围缩小了,譬如说,只讨论多标签图像分类问题或者只讨论多标签文本分类问题。但是,更广泛意义上的多标签分类问题实际上是不好使用 CNN 来处理的,所以只能采用 MLP,失去了卷积池化操作,MLP 的效果是要弱得多的,要能取得较好的效果还是需要考虑多标签本身的特点。
以 2017 年发表在 AAAI 上的 C2AE 为例,其网络架构由
3
3
3 个 DNN 构成,实际上,我认为它与传统的方法是相似的。该网络中
F
x
F_x
Fx,
F
e
F_e
Fe 负责编码,
F
d
F_d
Fd 负责解码。实际上,在非深度学习方法中,这就相当于先将标签矩阵
Y
\mathbf{Y}
Y 矩阵分解为
U
V
\mathbf{UV}
UV,然后用
X
\mathbf{X}
X 去拟合
U
\mathbf{U}
U,拟合之后使用
V
\mathbf{V}
V 进行解码即可。 C2AE 所做的就是将其中的每步操作都替换成了 DNN。
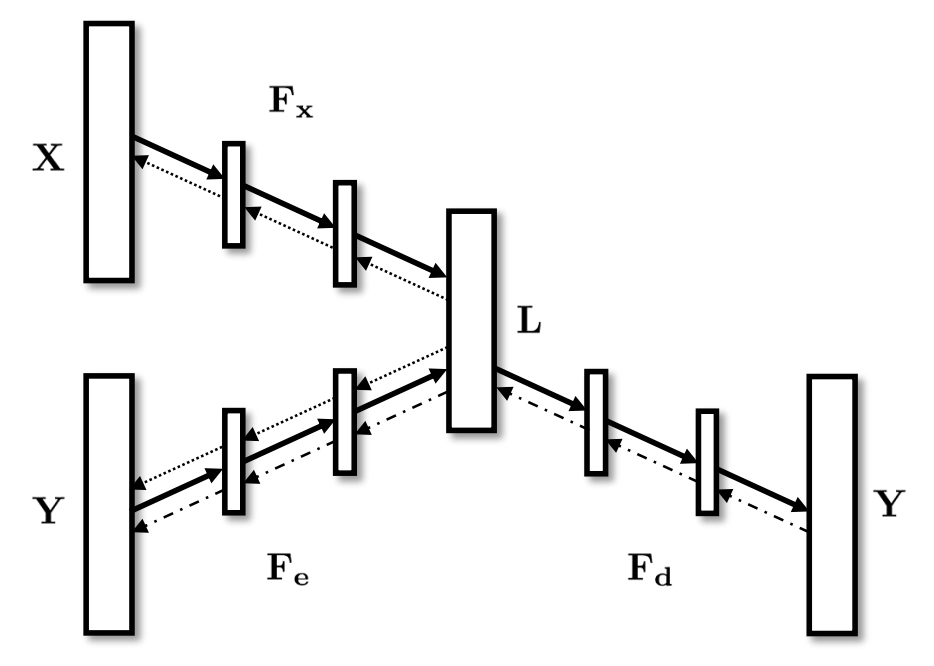
其损失函数为:
Θ
=
min
F
x
,
F
e
,
F
d
Φ
(
F
x
,
F
e
)
+
α
Γ
(
F
e
,
F
d
)
=
∥
F
x
(
X
)
−
F
e
(
Y
)
∥
F
2
+
∑
i
=
1
N
E
i
\begin{aligned}\Theta &=\underset{F_x,F_e,F_d}{\min}\Phi\left(F_x,F_e\right)+\alpha\Gamma\left(F_e,F_d\right)\\ &=\left\Vert F_x\left(\mathbf{X}\right)-F_e\left(\mathbf{Y}\right)\right\Vert_F^2+\sum\limits_{i=1}^N E_i \end{aligned}
Θ=Fx,Fe,FdminΦ(Fx,Fe)+αΓ(Fe,Fd)=∥Fx(X)−Fe(Y)∥F2+i=1∑NEi
s
.
t
.
F
x
(
X
)
F
x
(
X
)
T
=
F
e
(
Y
)
F
e
(
Y
)
T
=
I
E
i
=
1
∣
y
i
1
∣
∣
y
i
0
∣
∑
(
p
,
q
)
∈
y
i
1
×
y
i
0
exp
(
F
d
(
F
e
(
y
i
)
)
q
−
F
d
(
F
e
(
y
i
)
)
p
)
\begin{aligned} s.t.\quad\quad & F_x\left(\mathbf{X}\right)F_x\left(\mathbf{X}\right)^\mathsf{T}=F_e\left(\mathbf{Y}\right)F_e\left(\mathbf{Y}\right)^\mathsf{T}=\mathbf{I}\\ & E_i=\frac{1}{\left\vert\mathbf{y}_i^1\right\vert\left\vert\mathbf{y}_i^0\right\vert}\sum\limits_{\left(p,q\right)\in\mathbf{y}_i^1\times\mathbf{y}_i^0}\exp\left(F_d\left(F_e\left(\mathbf{y}_i\right)\right)^q-F_d\left(F_e\left(\mathbf{y}_i\right)\right)^p\right) \end{aligned}
s.t.Fx(X)Fx(X)T=Fe(Y)Fe(Y)T=IEi=∣yi1∣∣yi0∣1(p,q)∈yi1×yi0∑exp(Fd(Fe(yi))q−Fd(Fe(yi))p)
总的来说,损失函数分两部分,前一部分是通常的拟合损失,后一部分是对于
Y
\mathbf{Y}
Y 的编码解码损失(其实类似于 Ranking Loss)。注意到,由于神经网络内部是个黑盒,所以在损失函数方面的限制相较于线性方法就要宽泛得多,只能从输出的结果进行限制,而不能具体限制到分类器层面。
这也启发我,线性模型中的东西也不是全部用不上了,损失函数的部分有些东西还是能用,而另一方面对于数据集的预处理可以提现到对神经网络的架构设计上。
方案: 串并 GIN
- 将模型替换为串并 GIN
所谓 邻居调整 原来是图神经网络 GNN 领域一直在玩儿的东西,2017 年发表在 ICLR 上的图卷积神经网络 GCN 其核心就是首先进行邻居调整,然后再进行线性变换,接着使用一个激活函数来赋予非线性。而 2019 年发表在 ICLR 上的 GIN 则证明了强大的图神经网络应该具有哪些性质,并根据这些性质构造了图同构网络 GIN,它证明了这是 GNN 中最强力的一类网络,比 GCN(2017 ICLR)和 GraphSAGE(2017 NeurIPS)都要更强。
其核心如下,简单说,每一次 GIN Layer 的更新,就是融合了邻居信息之后,使用 MLP 进行非线性变换,文中还证明了单层感知机是不够的,至少也用双层。
h
v
(
k
)
=
MLP
(
k
)
(
(
1
+
ϵ
(
k
)
)
⋅
h
v
(
k
−
1
)
+
∑
u
∈
V
(
v
)
h
u
(
k
−
1
)
)
h_v^{\left(k\right)}=\text{MLP}^{\left(k\right)} \left( \left(1+\epsilon^{\left(k\right)}\right)\cdot h_v^{\left(k-1\right)} +\sum\limits_{u\in\mathcal{V}\left(v\right)}h_u^{\left(k-1\right)} \right)
hv(k)=MLP(k)
(1+ϵ(k))⋅hv(k−1)+u∈V(v)∑hu(k−1)
因此,又结合 2022 年发表在 KBS 上的 MASP,我将我的模型更改为了串并 GIN。MASP的网络结构如下图所示,简单来说,它是一个串并行的 MLP,我通过将 MLP 替换为 GIN Layer 来进行特征增强。
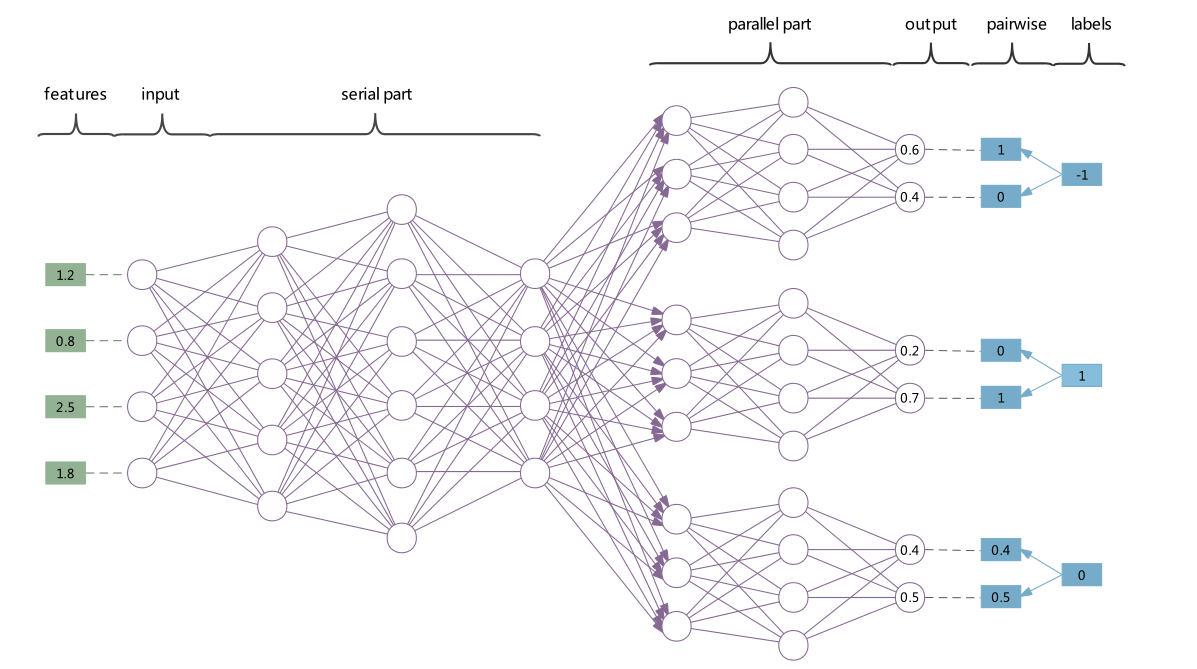
remark:
从实验结果来看,效果中庸,在 Image 和 Flags 数据集上进行了调试,不能达到 SOTA 效果,只能说是中规中矩。
反思:
一开始决定采用 MASP 的串并行结构是因为,它实际上是将多标签分类转换为了多个二分类问题,后面并行的部分从直觉上有提取 Label-Specific Features 的效果。不过从实验结果上来看,它并不能达到这样的效果。我思考了之后认为,从并行到串行的部分,仍然使用了全部的特征,同时并没有给出足够的针对于 Label-Specific 的策略引导,神经网络没有训练成想象中的样子也是合情合理。
值得一提的是,我还是用 GIN 对标签进行了非线性重构,试图以此来融合标签相关性,但是实验结果表明,加上或者不加上这个模块,对于模型性能几乎没有影响。
3. 论文阅读
这一节主要是分享 Label-Specific 的东西,实际上,通过这段时间的思考,我认为,多标签分类中标签相关性是极具代表的特性,但是仅有标签相关性是完全不够的,事实上,标签相关性能够玩的花样已经被各路大佬玩得差不多了,我弄来弄去的正则项其实思路也就那么一个思路。所以,我认为,要进一步提升模型的性能,就需要将各种操作都用上,什么特征提取啦,标签嵌入啦之类都用上。
而最近我主要在关注 Label-Specific Features 的东西,老实说,这并不应该算是多标签分类的东西,它更应该属于 特征工程 的一部分。
Label-Specific Features 的强大之处从 2014 年发表在 TPAMI 上的 LIFT 就可以看出来,即便是在 2023 年的今天,LIFT 也还是一个十分抗打的算法。而另一方面,我关注了东南大学张敏灵教授的主页,发现他们团队近年来发表的论文主要是在 PML 领域,而在纯 MLC 领域的文章相对不多了,在这些文章中 Label-Specific 和 Label Enhancement 占据了显眼的位置,也许,Label-Specific 与 LE 将是进一步提升模型性能的突破点吧。
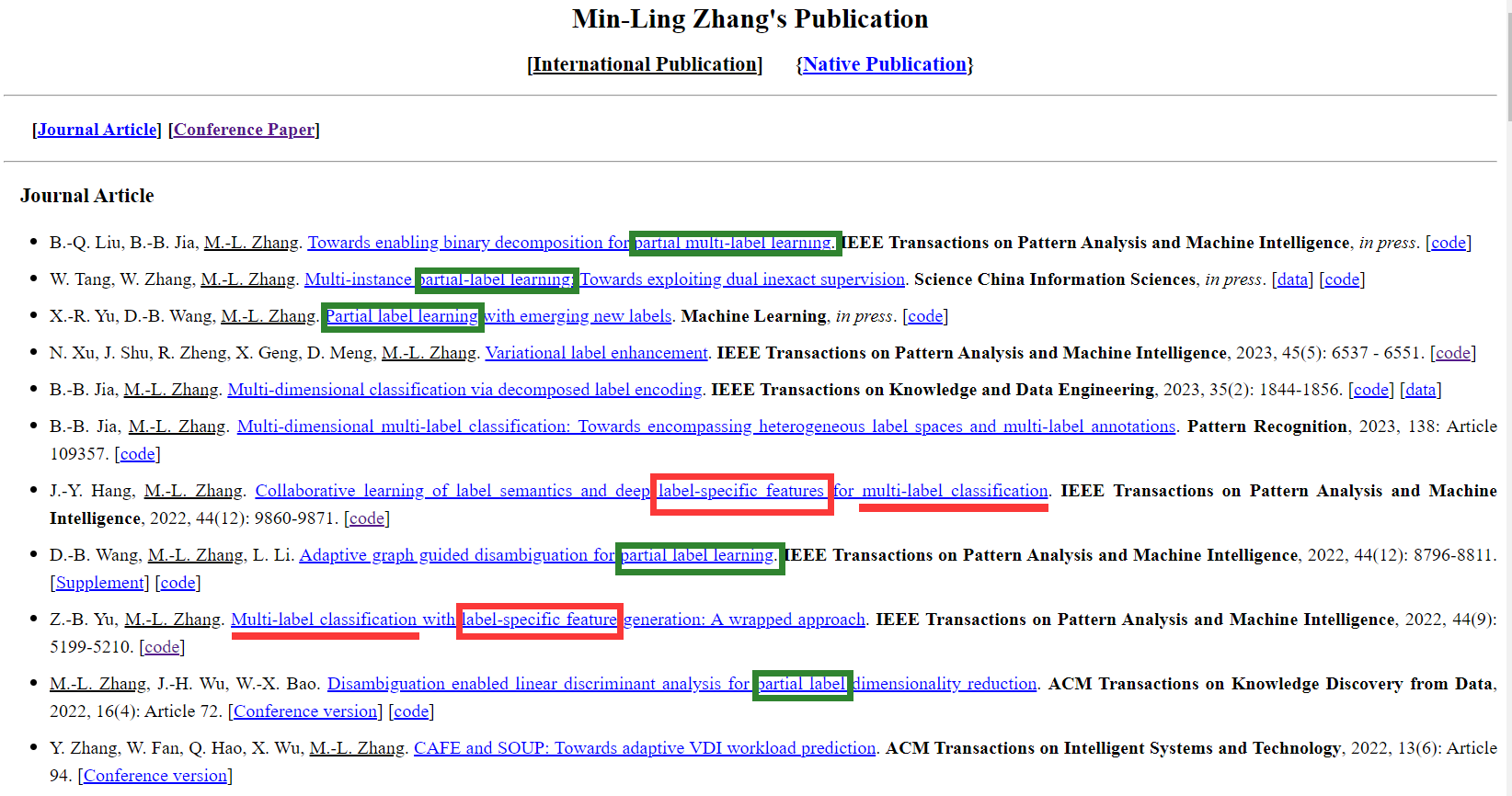
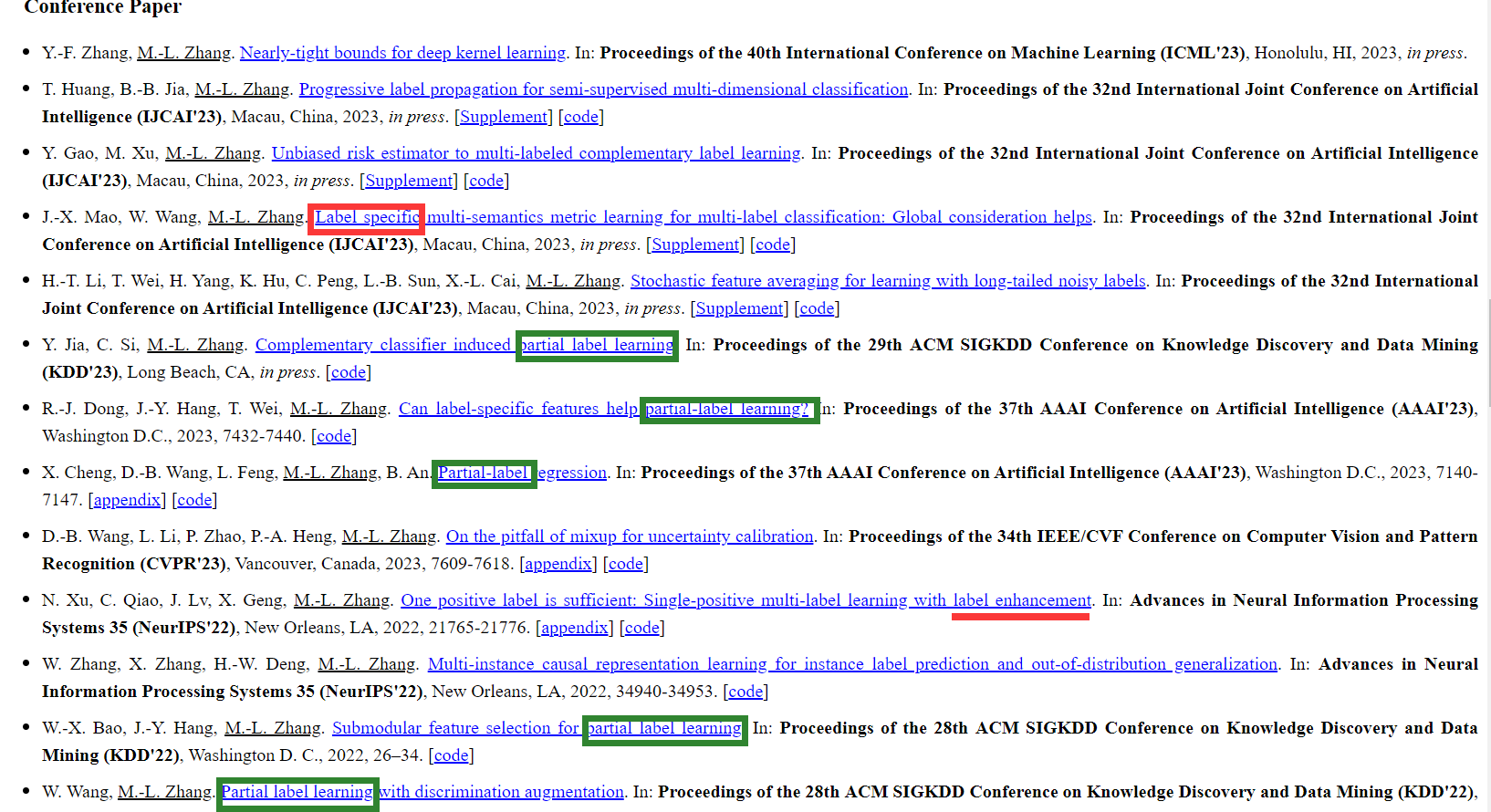
正如上图所示,绿色框框住的是 PML 的论文,在近两年已经成为了大头,红色框框住的是 MLC 的论文,大多含有 Label-Specific 与 Label Enhance 标签。
3.1 LIFT
LIFT 虽然号称多标签算法,但实际上,它并没有考虑多标签问题本身的特性,可以说,它就是一个针对单标签数据的特征工程方法。但即便如此,它却成为了最抗打的多标签算法之一,真是令人感叹。
简单说,LIFT 的想法是针对一个标签
l
k
l_k
lk,分别找出对其判定为正例的信息和将其判定为负例的信息,然后根据这些信息重构每个实例的特征。
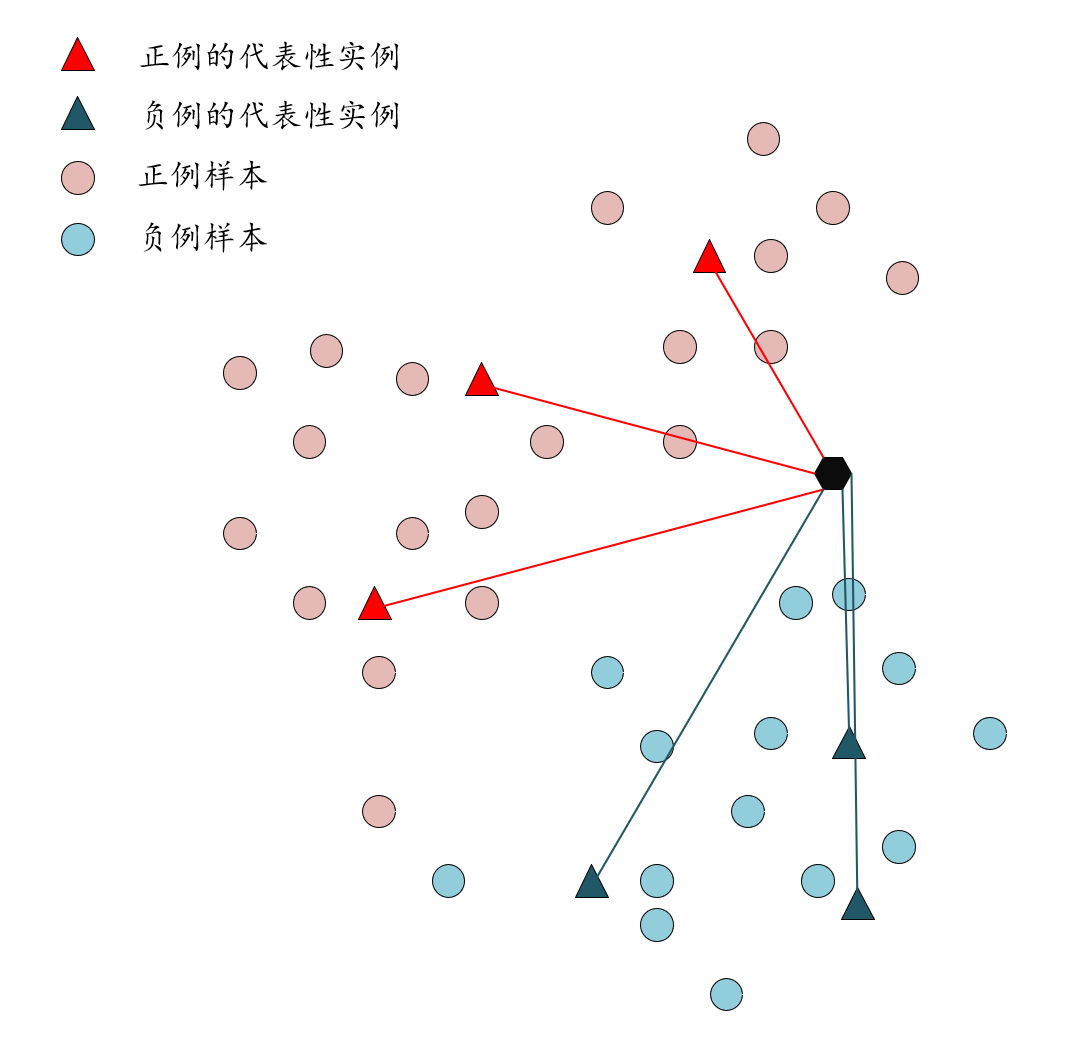
以上图为例,LIFT 所做的实际上就是从所有正例中取出代表性样本(它们含有将该标签判定为正例的属性信息),从所有负例中取出代表性样本(它们含有将该标签判定为负例的属性信息),这就是 Label-Specific 了。到这一步,其实已经可以根据 k k k-NN 这样的惰性学习算法鉴别 unseen instance 的类别了,但 LIFT 却为未知的实例构造新的属性,每个属性是其与一个代表性实例的距离,从而,新的属性就蕴含着针对该标签的丰富的判别信息了。
remark:
对于 LIFT,我只能说是天才的想法,足够简单,足够有效,足够泛化,这不仅仅是一个多标签算法,这是一个广泛适用于分类问题的特征工程的方法。但是,它不是我想要的,我想要的是一种可以在训练分类器的同时,进行构造的方法。
3.2 LSML 与 WRAP
这两个算法都号称 Label-Specific Features,但它们的手段都是一致的,即采用线性模型,对其应用 ℓ 1 \ell_1 ℓ1 正则约束 W \mathbf{W} W,使分类器稀疏,从而实现特征选择,达到 Label-Specific 的目的。但既然我已经放弃线性模型,所以这个手段用不上了(NN 中用 ℓ 1 \ell_1 ℓ1 正则并不能取得 Label-Specific 的效果
3.3 CLIF
CLIF 是于 2022 年发表在 TPAMI 上的论文,其实现 Label-Specific 的方式也是 特征选择,但不一样的是,它是通过训练一个 重要性向量 来进行特征选择。其过程图如下。
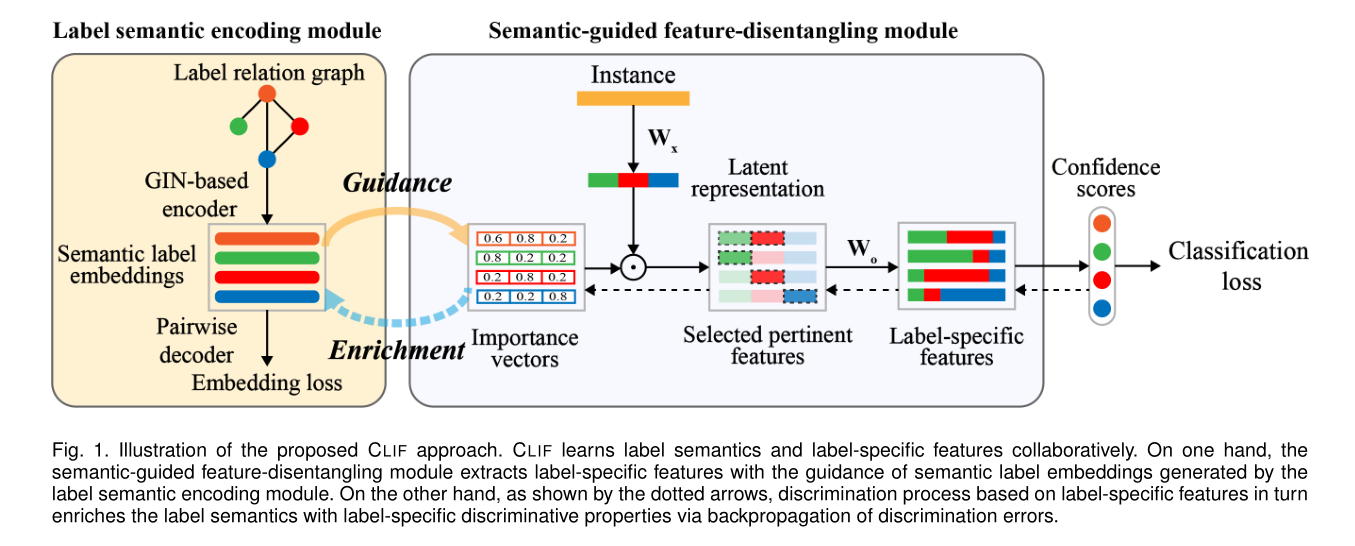
该方法大概分为两个部分
左边
- 先建立一个 标签关系图,然后用 GIN 编码解码学习 标签语义
右边 - 先用
W
x
\mathbf{W}_x
Wx 进行 特征提取,然后用 Importance vectors 和提取后的新特征逐元素相乘(相当于一个滤波器)再进行一个非线性变换,从而实现 Label-Specific 特征。用该特征作为输入,进行分类
相互作用 - 左边的标签语义指导 Importance vectors 的学习
- Importance vectors 反过来(反向传播过来的)丰富标签语义
损失函数: L = L c e + λ L l e \mathcal{L}=\mathcal{L}_{ce}+\lambda\mathcal{L}_{le} L=Lce+λLle
- 一个是分类损失,采用的是交叉熵损失
- 一个是标签嵌入的解码损失
remark:
一开始我以为标签关系图是使用标签向量
l
k
\boldsymbol{l}_k
lk 作为输入,学习标签相关性。后来发现,原来并非如此,标签关系中的每个节点一开始使用标准高斯进行初始化,得到的嵌入向量作为重要性向量输入到右边进行特征选择。
而 Pairwise Decoder 一开始我误以为它也是一个网络,后来发现它只是一个单纯的损失函数
L
l
e
=
1
q
2
∑
i
=
1
q
∑
j
=
1
q
[
cos
(
e
i
,
e
j
)
−
A
^
i
j
]
\mathcal{L}_{le}=\frac{1}{q^2}\sum\limits_{i=1}^q\sum\limits_{j=1}^q\left[\cos\left(\mathbf{e}_i,\mathbf{e}_j\right)-\hat{\mathbf{A}}_{ij}\right]
Lle=q21i=1∑qj=1∑q[cos(ei,ej)−A^ij]
,目的是对约束嵌入结果之间与标签之间的相似(相关)关系保持一致。原文的解释是,图同构网络倾向于令邻居节点之间的嵌入保持一致,但是不能将相异的地方推开,因此需要这个损失函数。
重要性向量 的想法感觉挺合情合理的,这就是特征选择的依据嘛,但是仅靠交叉熵损失和一个解码损失就能够引导神经网络往重要性向量方面进行训练了吗?
3.4 DELA
DELA 是 2022 年发表在 ICML 上的文章。其题目为 Dual Perspective of Label-Specific Feature Learning for Multi-Label Classification,包含了以下两个关键词
- 对偶视角
- 标签特定特征学习
3.4.1 摘要
- Label-Specific feature 有助于多标签分类,方式 是产生或者选择针对每个标签的 有判别力 的属性
- 现有方法是很 直接 的
- 对每个类标签,寻找 最相关 和 最有判别力 的特征
- 基于此构建 Label-Specific 特征,并诱导出分类器
- 本文给出的是一种 对偶 的视角(个人批注:感觉就像是特征选择,筛掉不相关的特征)
- 通过鉴别每个类标签的 non-informative features 来学习 Label-Specific 判别属性
- 令分类器在分类时不受这些 non-informative features 的变化的影响
- 方法 DELA 是基于 扰动 的
- 在鉴别 non-informative features 的 同时,训练具有 标签特定不变性 的分类器
- 通过优化一个宽松概率的期望风险最小化问题来完成这一任务
3.4.2 算法
概览
- 将特征
x
\mathbf{x}
x 从
d
d
d 维嵌入到
d
z
d_z
dz 维度(个人注解:这就是一个很寻常的特征提取吗)
- 嵌入后的特征记做 z \mathbf{z} z
- 嵌入方式是学习一个函数 e ϕ : R d → R d z e_\phi:\mathbb{R}^d\rightarrow\mathbb{R}^{d_z} eϕ:Rd→Rdz
- 这里没有 Label-Specific,提取的特征供所有标签使用
- 进行 选择性 的特征扰动(个人注解:如果完全随机就没有意义了,我想随机噪声的作用是为了使 non-informative features 失效,而具体在哪些特征上加入噪声,则是选择性的,需要根据一定的策略来引导该过程)
- 方式是将随机噪声注入特征 z \mathbf{z} z 中,从而针对每个类标签的 non-informative features 进行扰动
- 这是 Label-Specific
- 在最终获得的表达上构建分类器
期望风险最小化问题
E
p
(
x
,
y
)
ϕ
,
∏
,
Θ
[
∑
k
=
1
t
L
(
f
k
(
g
k
(
e
ϕ
(
x
)
;
π
k
)
;
θ
k
)
,
y
k
)
]
\underset{\phi,\prod,\Theta}{\mathbb{E}_p\left(\mathbf{x},\mathbf{y}\right)}\left[\sum_{k=1}^t\mathcal{L}\left(f_k\left(g_k\left(e_\phi\left(\mathbf{x}\right);\boldsymbol{\pi}_k\right);\boldsymbol{\theta}_k\right),y_k\right)\right]
ϕ,∏,ΘEp(x,y)[k=1∑tL(fk(gk(eϕ(x);πk);θk),yk)]
- 特征提取: e ϕ ( x ) e_\phi\left(\mathbf{x}\right) eϕ(x),特征维度从 d d d 降到 d z d_z dz
- Label-Specific features 学习: g k ( e ϕ ( x ) ; π k ) g_k\left(e_\phi\left(\mathbf{x}\right);\boldsymbol{\pi}_k\right) gk(eϕ(x);πk),特征进行一个相同维度的变换,从 d z d_z dz 到 d z d_z dz
- 构建分类器: f k ( g k ( e ϕ ( x ) ; π k ) ; θ k ) f_k\left(g_k\left(e_\phi\left(\mathbf{x}\right);\boldsymbol{\pi}_k\right);\boldsymbol{\theta}_k\right) fk(gk(eϕ(x);πk);θk),一共构建了 t t t(标签个数)个分类器,即将问题转化为多个二分类问题
- 计算所有分类器的损失: ∑ k = 1 t L ( f k ( g k ( e ϕ ( x ) ; π k ) ; θ k ) , y k ) \sum\limits_{k=1}^t\mathcal{L}\left(f_k\left(g_k\left(e_\phi\left(\mathbf{x}\right);\boldsymbol{\pi}_k\right);\boldsymbol{\theta}_k\right),y_k\right) k=1∑tL(fk(gk(eϕ(x);πk);θk),yk)
- 对损失求均值
选择性特征扰动
需要做两件事情
- 针对第
k
k
k 个标签,选择特征子集
S
k
S_k
Sk,这是对于该标签的 non-informative features
- 该问题是困难的,因为可以选择的子集数目太多了
- 其数量随着 d z d_z dz 的增长而指数级的增长
- 对该特征子集注入噪声进行扰动,使得对应标签在分类时对这些特征不敏感(相当于筛除掉了这些特征)
- 该问题也很困难,噪音加多了会崩溃,加少了会扰动不足
- 必须要有一个 策略,来指导噪音的注入,而且该策略必须得是 Label-Specific
g k ( z ; π k ) = z + i S k ⊙ ϵ , w i t h ϵ ∼ p ϑ ( ϵ ) g_k\left(\mathbf{z};\boldsymbol{\pi}_k\right)=\mathbf{z}+\mathbf{i}_{S_k}\odot\epsilon,\quad\quad with\quad\epsilon\sim p_{\vartheta}\left(\epsilon\right) gk(z;πk)=z+iSk⊙ϵ,withϵ∼pϑ(ϵ)
注意: 这里噪音的分布是预先决定的,依赖于实例的,具体来说是
p ϑ ( ϵ ) = N ( 0 , σ ϑ 2 ( x ) I ) p_{\vartheta}\left(\epsilon\right)=\mathcal{N}\left(\mathbf{0},\sigma_\vartheta^2\left(\mathbf{x}\right)\mathbf{I}\right) pϑ(ϵ)=N(0,σϑ2(x)I)
其中 ϑ {\vartheta} ϑ 用来参数化该分布,且 ϑ {\vartheta} ϑ 由所有标签共享
可微子集选择
解决方案: 用 Bernoulli gates 来代替指示向量
i
S
k
∈
{
0
,
1
}
d
z
\mathbf{i}_{S_k}\in\left\{0,1\right\}^{d_z}
iSk∈{0,1}dz,简单说就是根据一个伯努利分布来进行随机选择
P
[
b
k
i
=
1
]
=
p
k
i
,
i
∈
[
d
z
]
P\left[b_{ki}=1\right]=p_{ki},\quad\quad i \in\left[d_z\right]
P[bki=1]=pki,i∈[dz]
因此,子集选择问题被转化成了选择最优的伯努利分布参数问题
新的问题: 由于伯努利离散分布的性质,因此无法通过梯度下降等优化算法进行优化
解决方案: 使用 Gumbel-Softmax trick 平滑采样过程,具体来说,一个伯努利随机变量
b
∼
B
e
r
n
(
p
)
b\sim Bern\left(p\right)
b∼Bern(p) 可以变化如下
c
=
1
1
+
exp
[
−
(
log
α
+
l
)
/
τ
]
c=\frac{1}{1+\exp\left[-\left(\log\alpha+l\right)/\tau\right]}
c=1+exp[−(logα+l)/τ]1
- α = p 1 − p \alpha=\frac{p}{1-p} α=1−pp
- l l l 是 logistic distribution 采样
- τ > 0 \tau>0 τ>0 是温度参数, τ → 0 \tau\rightarrow 0 τ→0 时, c c c 就变化为对应的伯努利分布随机变量
由于 c c c 是连续的,因此,在前向过程,使用 c c c 的离散采样来表示不同的 b b b,而在反向传播时,则对 c c c 求梯度来优化,有 ∇ p k c k ≈ ∇ p k d k \nabla_{\mathbf{p}_k}\mathbf{c}_k\approx\nabla_{\mathbf{p}_k}\mathbf{d}_k ∇pkck≈∇pkdk,其中 d k = r o u n d ( c k ) \mathbf{d}_k=round\left(\mathbf{c}_k\right) dk=round(ck),是对 c c c 的离散采样
remark:
- 不同的伯努利分布参数决定的是 子集大小 的不同,但是决定子集中是哪些特征不还是随机的吗?
噪声分布约束
这一部分是真正扣题的部分,即 Label-Specific
思想: 学习一个条件分布,令其去拟合最佳噪声分布
- 要学习的分布
将 z k = e ϕ ( x ) + r o u n d ( c k ) ⊙ ϵ \mathbf{z}_k=e_\phi\left(\mathbf{x}\right)+round\left(\mathbf{c}_k\right)\odot\epsilon zk=eϕ(x)+round(ck)⊙ϵ 重新参数化为随机变量 z k \mathbf{z}_k zk 的形式,其服从潜在分布如下
E p ( c k ) [ p ϕ , ϑ ( z k ∣ x , c k ) ] \mathbb{E}_{p\left(\mathbf{c}_k\right)} \left[p_{\phi,\boldsymbol{\vartheta}}\left(\mathbf{z}_k|\mathbf{x},\mathbf{c}_k\right)\right] Ep(ck)[pϕ,ϑ(zk∣x,ck)]
- 条件分布
p
ϕ
,
ϑ
(
z
k
∣
x
,
c
k
)
p_{\phi,\boldsymbol{\vartheta}}\left(\mathbf{z}_k|\mathbf{x},\mathbf{c}_k\right)
pϕ,ϑ(zk∣x,ck): 代表确定了当前的噪声条件之后,所表现出的干扰程度
- 该分布是需要学习的
- 最佳噪声分布
- 先验分布
q
(
z
k
)
q\left(\mathbf{z}_k\right)
q(zk): 代表了我们所期待的最假的噪声干扰程度
- 该分布是预先设定的,具体来说设置为标准高斯
- 用 KL-divergence 来衡量两个分布的接近程度
- 即,最小化下式
E p ( c k ) [ K L ( p ϕ , ϑ ( z k ∣ x , c k ) ) ∣ ∣ q ( z k ) ] \mathbb{E}_{p\left(\mathbf{c}_k\right)} \left[KL\left(p_{\phi,\boldsymbol{\vartheta}}\left(\mathbf{z}_k|\mathbf{x},\mathbf{c}_k\right)\right)||q\left(\mathbf{z}_k\right)\right] Ep(ck)[KL(pϕ,ϑ(zk∣x,ck))∣∣q(zk)]
- 即,最小化下式
remark:
- 想法很简单,训练一个分布,用其去拟合最佳分布就行
- 问题 在于,最佳分布根本就是不知道的,而解决的办法竟然是预先选择标准高斯分布作为最佳分布,然后去拟合该分布。
- 这貌似也是常用手段,好像也在其他地方见过直接将未知的分布假定为高斯分布的?
- 但还是无法理解,这种操作有点先射箭再画靶的感觉?
4. 下周计划
要想办法设计一个 Label-Specific 的模块融入进我现在的方案中。
- 再看一看 Label-Specific 的文章(应该是沿着特征选择的这个方向走)
- 尝试新的方案















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









