






文章目录
- 提前安装好 pycharm 和 Anaconda3
- 安装 CUDA 工具包
- 创建虚拟环境
- 安装 GPU 版本 PyTorch
- 下载 YOLOv5-Lite 及其权重文件
- 标注数据集
- 调整训练参数
- 开始训练
- 模型转换
- 模型部署
1、CUDA是整个并行计算软件平台和编程模型的总称,CUDA Toolkit是支持CUDA编程的软件开发工具包,而cuDNN是CUDA Toolkit中一个专门用于深度神经网络加速的库。三者之间的关系是:CUDA Toolkit包含cuDNN库,cuDNN利用CUDA来实现深度神经网络计算的加速。
要想在本地PC端训练模型,就必须得搭建好CUDA环境!!!
2、通过PyTorch或TensorFlow等深度学习框架并采用YOLO的网络结构及其实现方式进行已标注数据集的训练,可以得到支持YOLO算法进行目标检测的模型。
我们当前是使用PyTorch深度学习框架并通过YOLOV5算法来进行标注数据集的训练!!!
现在我们来一步一步安装资源包并配置好环境。
一、提前安装好pycharm(2021年版本,社区版即可)和 Anaconda3(最新版即可)。
二、安装GPU训练所需要的一些软件包。
查看自己电脑所支持的CUDA版本:
nvidia-smi

安装CUDA Tookit & CUDNN(这里选择安装12.1的版本有如下两个原因:1、任何和CUDA相关的工具包都必须小于或者等于当前的CUDA版本,也就是<=12.4;2、由于pytorch官方最新的版本只支持CUDA 12.1,因此我们选择安装12.1版本的CUDA Tookit和与之对应的CUDNN!)
(1)CUDA Toolkit下载链接:
CUDA Toolkit Archive | NVIDIA Developer
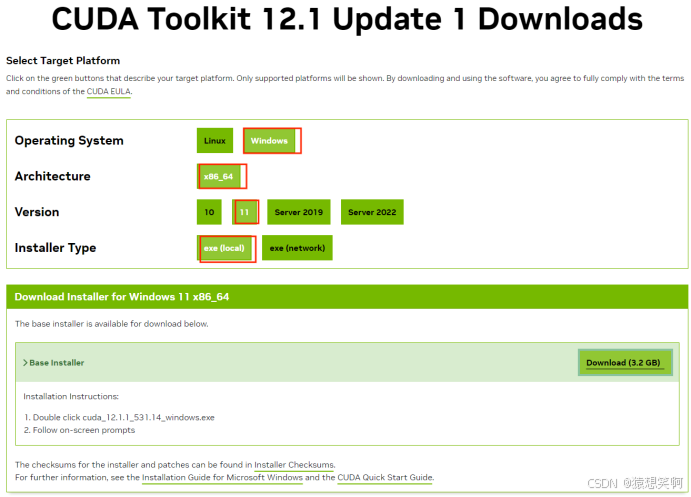
安装CUDA Tookit:
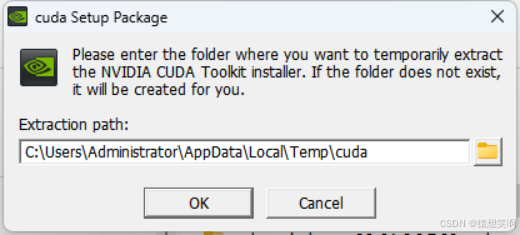
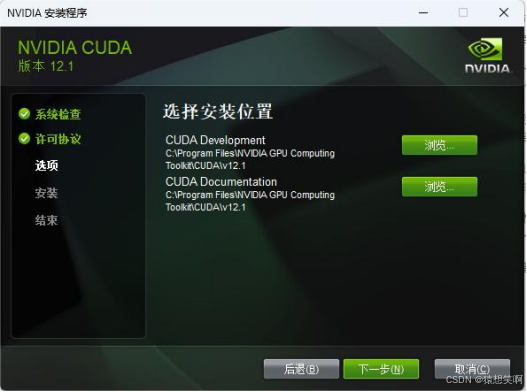
注意事项:取消勾选Visual Studio Integration(这里解释一下,这个模块是对VS编译的支持,没有安装VS无法正常工作,而需要VS辅助则是需要编译cuda程序,这种编译不建议在Windows下进行,一般Windows下能跑深度学习原生框架的代码就行),其余全部勾选。

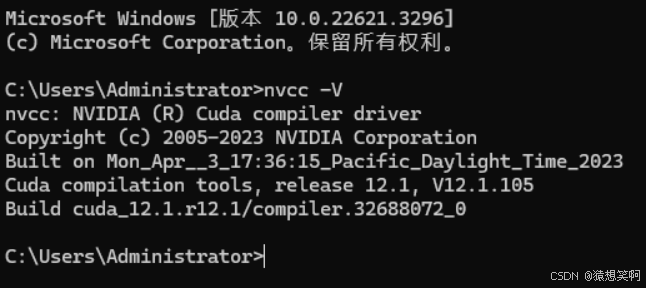
测试Tookit是否安装成功:
nvcc -V
如果没有显示没有nvcc这个命令,那就添加环境变量。具体要先查看C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin是否有nvcc.exe
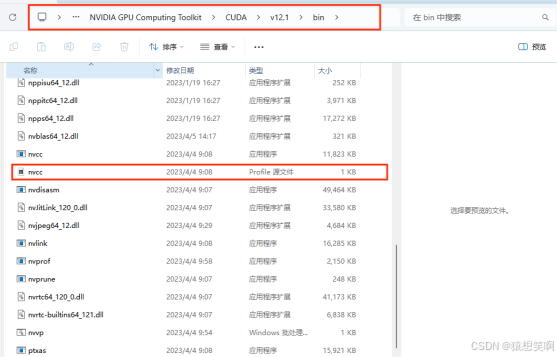
如果没有,那就需要添加环境变量。
添加如下两条:
通过右键点击此电脑——>属性——>高级系统设置——>环境变量。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp
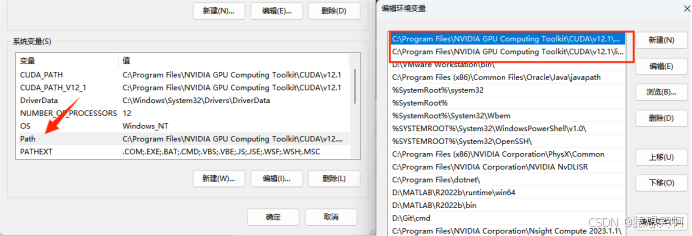
(2)cuDNN下载:
下载地址:cuDNN 9.8.0 Downloads | NVIDIA Developer
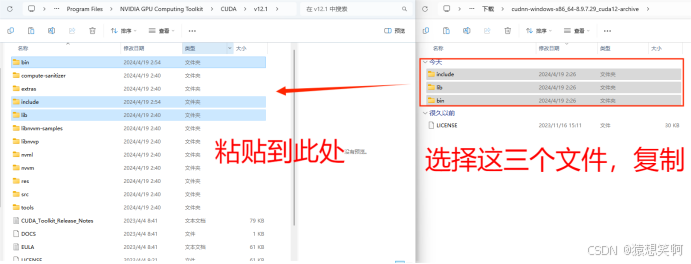
到这里与其说是安装CUDNN,还不如说是“复制替换文件”。首先,我们来解压一下刚才下载的第二个文件CUDNN,接着来到CUDA Toolkit安装的文件夹:
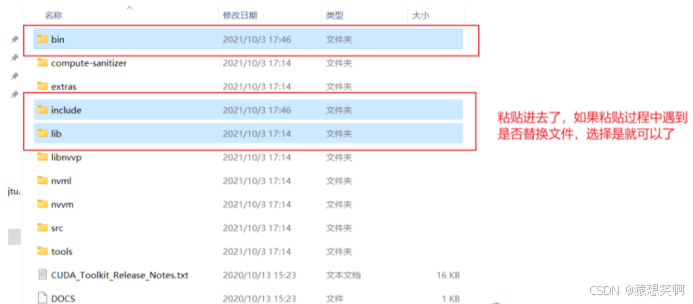
三、不同的项目可能需要不同的软件包依赖,因此我们需要创建不同的虚拟环境来支持不同的项目(也能起到隔离作用)。
创建虚拟环境:
conda create -n Pytorch_Y5_Lite python=3.8
查看虚拟环境:
conda env list
激活虚拟环境:
activate Pytorch_Y5_Lite

关闭虚拟环境:
conda deactivate
删除虚拟环境:
conda remove --name Pytorch_Y5_Lite --all
修改虚拟环境名称:
conda rename --name Pytorch_Y5_Lite yolov5_lite
四、Pip安装pytorch(这里的Compute Platform CUDA同样需要<=12.4)
进入官网:
进入早先的版本,选择CUDA 12.1(<=12.4)的安装指令:
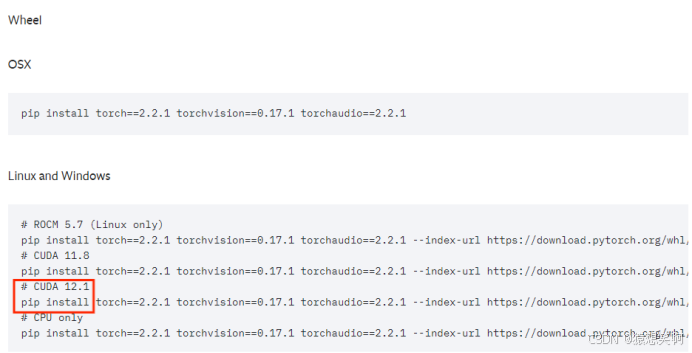
# CUDA 12.1
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
![]()
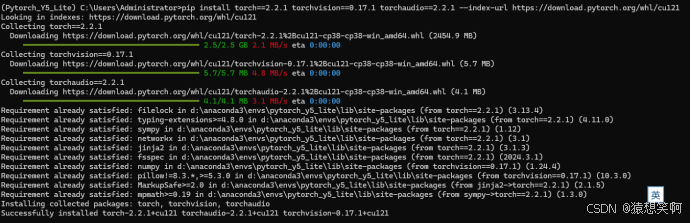
查看安装包的情况:
conda list/ pip list
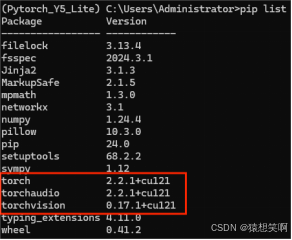
测试Pytorch GPU版本是否安装成功:
python
import torch
print(torch.cuda.is_available())
返回True表示安装成功

五、下载yolov5相关文件
本次项目采用树莓派4B(Cortex-A72)作为核心 CPU 进行部署。选择的网络模型为 YOLOv5 模型的变种 YOLOv5-Lite 模型。YOLOv5-Lite(v1.4版本) 与 YOLOv5 相比虽然牺牲了部分网络模型精度,但是却极大的提升了模型的推理速度,该模型属性将更适合实战部署使用。
下载解压然后打开requirements.txt,将torch>=1.8.0和torchvision>=0.9.0给# 注释掉(因为此前我们安装了GPU版本的Pytorch)。然后把要求的>=换成==,在终端通过pip+清华源安装该.txt,如果安装出问题了,就基于当前版本的下一个版本(+1)安装!或者后续运行的时候出现版本问题,就卸载当前版本再按照问题提到的要求的版本进行安装!

接着打开Pycharm,创建一个新项目,并添加Conda虚拟环境中的python3.8解释器:
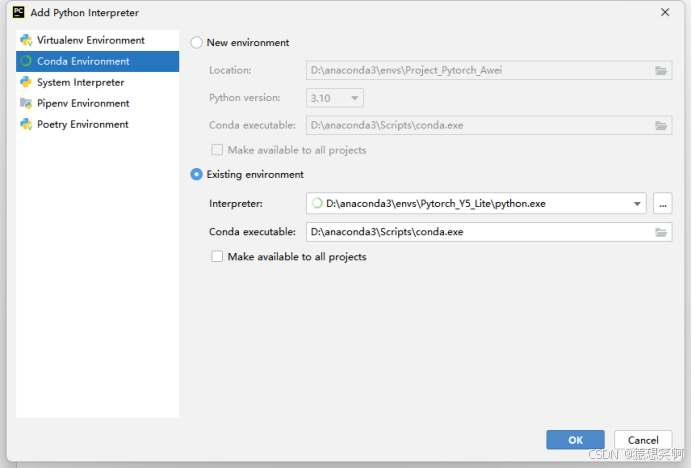
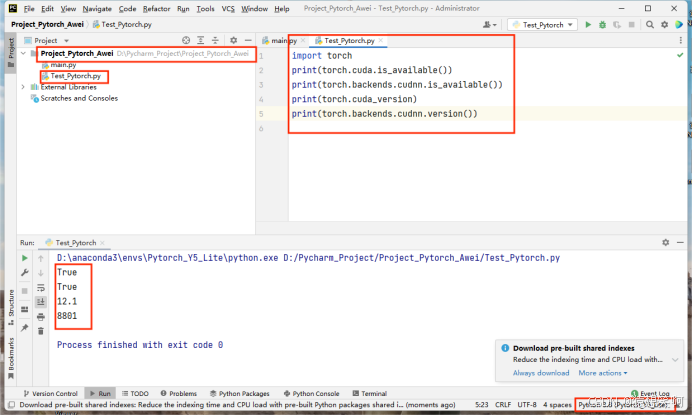
再创建一个python文件:
import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
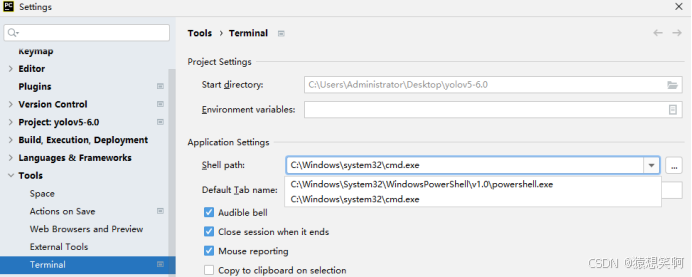
将yolov5-lite-master用pycharm打开,将解释器更改成Conda虚拟环境中的Python3.8(Pytorch_Y5_Lite),并将终端更换成Anaconda自带的:
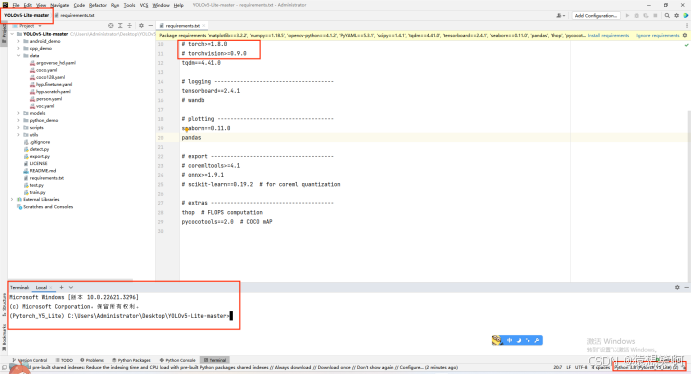
先将torch>=1.8.0和torchvision>=0.9.0给#注释掉,因为此前我们已经安装了GPU版本的PyTorch。
接着进入到yolov5-lite-master的路径
cd C:\Users\Administrator\Desktop\YOLOv5-Lite-master
最后添加清华源安装requirements.txt中要求安装的依赖:
pip install -r requirements.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --trusted-host=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
好了,现在该电脑上的:
- GPU训练的环境;
- Pytorch深度学习框架;
- yolov5模型文件等基本配置已完成!
六、准备数据集、标记数据集
准备数据集这块,因为我们是将训练好的模型部署到移动端:在树莓派、香橙派这样的开发板中运行,所以最好是通过开发板上的摄像头来采集一帧一帧的图片,具体代码这里就不展示了,一般都是通过OpenCV算法采集!
标记数据集的话,我们通过labelImg软件来进行标注:
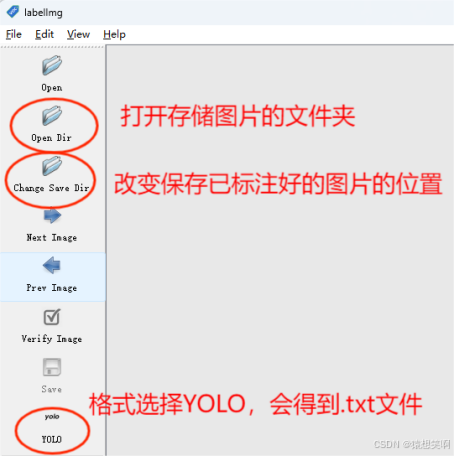
勾选自动保存:
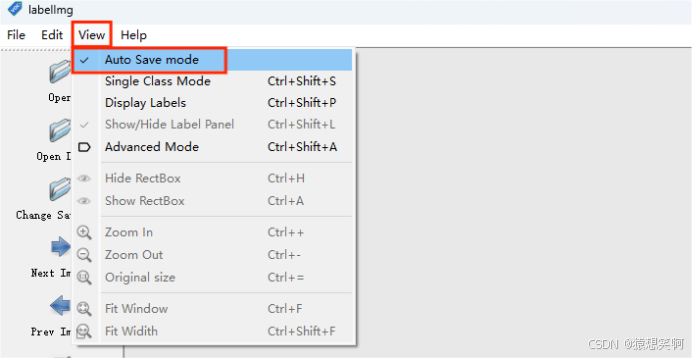
我们勾选Use default label,输入物体的标签名称(这样就不用每次给物体画完框还要确认物体标签),它会默认画完框的物体都是这个标签。

如果是YOLO格式,那么画完框后得到的是.txt文件;如果是VOC格式,那么画完框后得到的是.xml文件,根据不同的训练环境选择不同的格式!
七、运行YOLOv5-Lite进行训练前的一些操作
我们进入YOLOv5-Lite/data/ 目录,创建一个apple_data文件夹,目的是把我们的数据集放进去:
然后在data/apple_data/下创建三个文件夹:train(训练集)、valid(验证集)、test(测试集,可要可不要):
注意:验证集中的数据最好和训练集中不同,这是为了评估模型在未见过的数据上的泛化能力。如果验证集和训练集中的数据重复或者相似,模型在验证集上表现良好可能只是因为模型记住了训练集中的数据特征,而不是真正学习到了泛化的能力(也就是说训练集的数据是拿来学习的,而验证集不完全是之前学习过的数据,是验证机器学习的效果的。就像平常时上课学习后,还要考试测验,考试不可能都是原题,不然检验不出效果)。假设我的验证集中有2000张数据,那么验证集的数据大小约应该在400-600之间(大小通常在数据集的20%到30%之间),这样可以确保验证集有足够的数据量来评估模型的性能,同时又不会过大导致在训练过程中资源浪费。
这三个文件夹里面都要有images(存放所有采集的图片)和labels(存放已经标注好图片后得到的.txt文件)这两个文件夹:
这里介绍一下什么是权重文件(.pt文件):
在YOLO中,.pt文件是模型的权重文件,存储了模型在训练过程中学到的参数。在一开始的训练中,将预训练的权重文件添加进去可以帮助模型更快地收敛,提高训练的效率,并且有效避免了模型陷入局部最优解的问题。通过使用预训练的权重文件,可以更快地学习到数据集的特征,提高模型的准确性和泛化能力。
不同的权重文件对应不同的模型架构和训练过程,在训练目标检测模型时可以根据具体的需求选择合适的权重文件进行加载和使用。
YOLOv5s:这是 YOLOv5 系列中最小的模型。“s” 代表 “small”(小)。该模型在计算资源有限的设备上表现最佳,如移动设备或边缘设备。YOLOv5s 的检测速度最快,但准确度相对较低。
YOLOv5m:这是 YOLOv5 系列中一个中等大小的模型。“m” 代表 “medium”(中)。YOLOv5m 在速度和准确度之间提供了较好的平衡,适用于具有一定计算能力的设备。
YOLOv5l:这是 YOLOv5 系列中一个较大的模型。“l” 代表 “large”(大)。YOLOv5l 的准确度相对较高,但检测速度较慢。适用于需要较高准确度,且具有较强计算能力的设备。
YOLOv5x:这是 YOLOv5 系列中最大的模型。“x” 代表 “extra large”(超大)。YOLOv5x 在准确度方面表现最好,但检测速度最慢。适用于需要极高准确度的任务,且具有强大计算能力(如 GPU)的设备。
YOLOv5n:这是 YOLOv5 系列中的一个变体,专为 Nano 设备(如 NVIDIA Jetson Nano)进行优化。YOLOv5n 在保持较快速度的同时,提供适用于边缘设备的准确度。
在YOLOv5-6.0或者YOLOv5-7.0中我们使用YOLOv5s.pt文件来训练目标检测模型。
在YOLOv5-Lite中我们使用v5lite-s.pt权重文件来适配移动端的部署!!!
在YOLOv5-Lite/weights/ 目录下(如果没有文件夹就新建一个),把v5lite-s.pt权重文件放进去。
接下来我们打开pycharm,复制一份YOLOv5-Lite/data/ 目录下的coco.yaml文件:
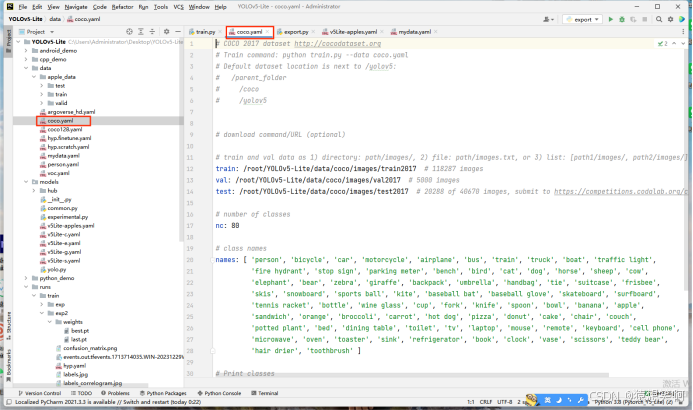
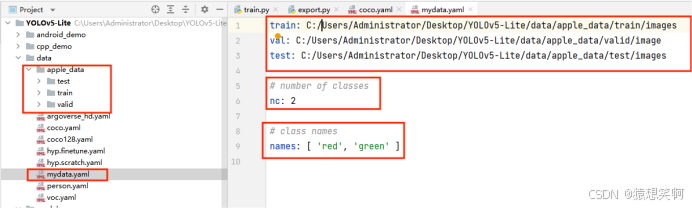
然后在YOLOv5-Lite/data/ 目录下粘贴并重命名为:mydata.yaml,接着把多余的部分删掉只留下:train、val、test、nc、names。
train是训练集的数据images的绝对路径;
val是验证集的数据images的绝对路径;
test是测试集的数据images的绝对路径(注意每个路径对应的文件夹之间要用”/”隔开,直接复制绝对路径的话是”\”);
nc是物体的种类,我这里只有’red’, ‘green’两个种类;names就是物体的标签。
接着还要复制一份YOLOv5-Lite/models/ 目录下的v5Lite-s.yaml文件:
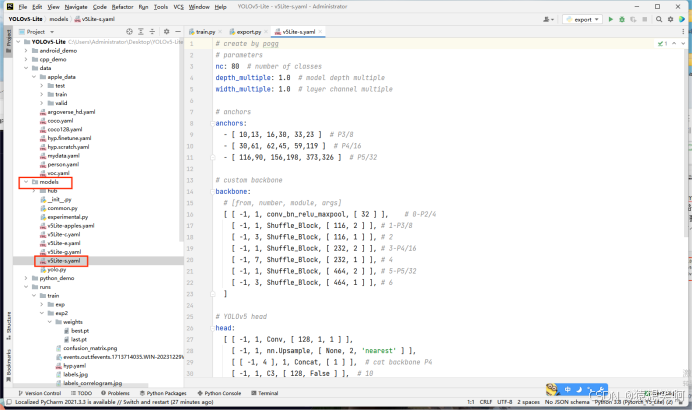
然后在YOLOv5-Lite/data/ 目录下粘贴并重命名为:v5Lite-apples.yaml,只需要把nc修改为你当前训练的物体的数量即可,我这里只有’red’, ‘green’两个种类,所以对应的值为2。

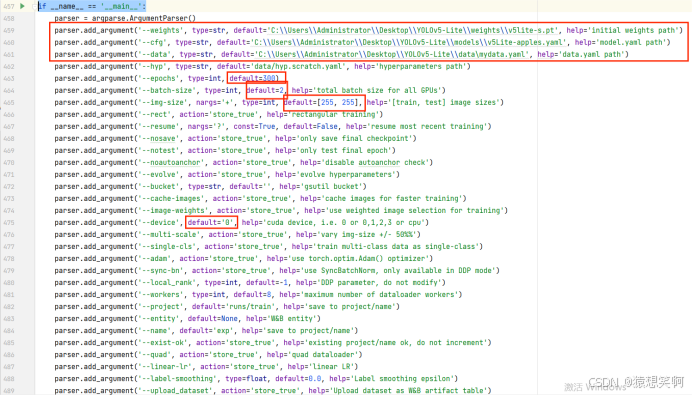
接着进入到train.py中,找到if __name__ == '__main__':
我们修改里面的
’--weights’(指定模型的初始权重文件路径)、
’--cfg’(指定模型的配置文件路径)、
’--data’(指定数据集的配置文件路径)、
’--epochs’(指定训练的轮数,即模型将会遍历整个训练集的次数)、
’--batch-size’(指定每次训练时的批量大小,即每次模型更新参数时同时处理的样本数量)、
’--img-size’(指定模型输入的图像尺寸,必须是32的整数倍)、
’--device’(指定使用的计算设备,如CPU或GPU)
对应的default为:v5Lite-s.pt权重文件的绝对路径、我们自己的v5Lite-apples.yaml的绝对路径、我们自己的mydata.yaml的绝对路径、训练300轮、批量大小为2、[256,256]、0(GPU训练)。
八、开始训练
修改完后直接run运行train.py:
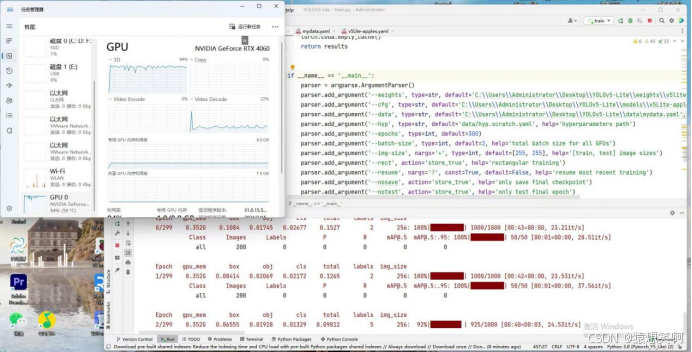
训练成功之后,可以在YOLOv5-Lite/runs/train/ 该路径下找到 expx (x代表数字),expx 则存放了第 x 次训练时候的各种数据内容,包括:历史最优权重best_weight,当前权重last_weight,训练结果result等等:
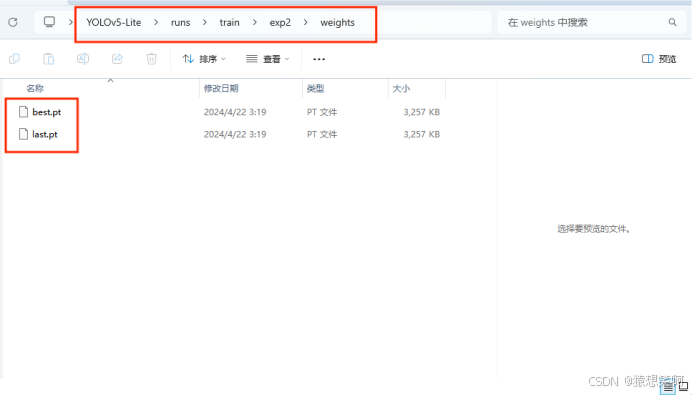
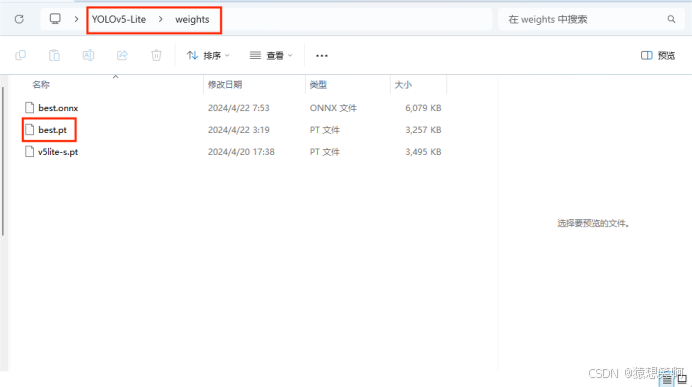
我们把历史最优权重best.pt给复制到YOLOv5-Lite/weights/ 路径中:
九、模型转换
这里介绍一下ONNX:Open Neural Network Exchange(ONNX)是一个开放的生态系统,它使人工智能开发人员在推进项目时选择合适的工具,不用被框架或者生态系统所束缚。ONNX支持不同框架之间的互操作性,简化从研究到生产之间的道路。ONNX支持许多框架(TensorFlow, Pytorch, Keras, MxNet, MATLAB等等),这些框架中的模型都可以导出或者转换为标准ONNX格式。模型采用ONNX格式后,就可在各种平台和设备上运行。
也就是说我们把在Pytorch框架下训练YOLO得到的模型导出为.ONNX格式的文件,就可以在树莓派上运行了!(在PC端安装onnx将.pt转成.onnx,在树莓派上安装onnxruntime进行模型推理,不要在树莓派上进行模型转换!!!)

开发者根据深度学习框架优劣选择某个框架,但是这些框架适应不同的开发阶段,由于必须进行转换,从而导致了研究和生产之间的重大延迟。ONNX格式是一个通用的IR,能够使得开发人员在开发或者部署的任何阶段选择最适合他们项目的框架。ONNX通过提供计算图的通用表示,帮助开发人员为他们的任务选择合适的框架。
ONNX可视化:ONNX 模型可以通过 Netron 进行可视化。
总结:
ONNX 顾名思义就是开放的神经网络模型转换,利用它可以轻松将模型更换框架,从而适配亦或是部署在各类设备上。
如今的开源 YOLO 系列神经网络模型的目录下作者都会预留 export.py 文件将该神经网络模型进行转换到 ONNX 模型,方便大家实际情况下部署使用!
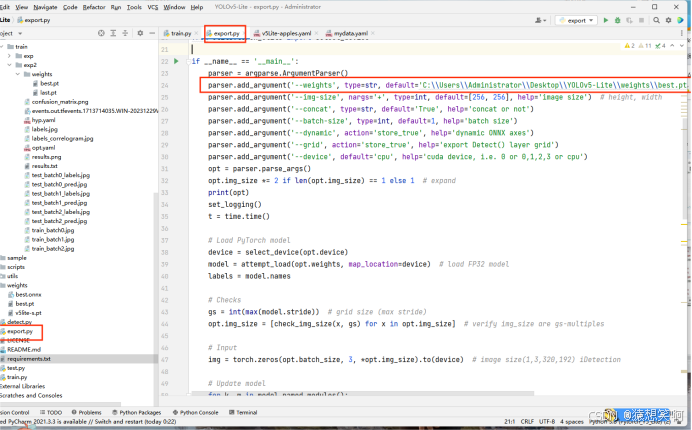
我们打开export.py文件找到if __name__ == ‘__main__’: 中的’--weights’, 将default改为我们训练的到的best.pt所在的绝对路径:
如果在安装requirements.txt文件中要求的软件包的时候没有安装onnx和onnxmltools,那么需要pip安装它俩:
![]()
运行export.py将会通过 best.pt 文件,生成 best.onnx 的 ONNX 模型的权重文件存放在YOLOv5-Lite/weights/ 路径下:
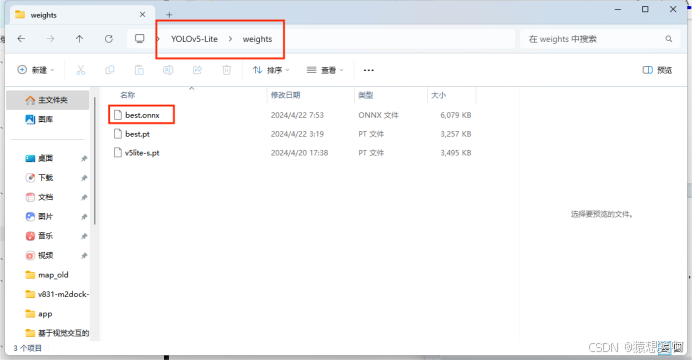
十、模型部署
在树莓派4B中安装 onnxruntime ,当然值得注意的是 onnxruntime 的安装需要依赖的 Numpy版本1.21 以上:

将转换成 ONNX 格式的权重文件导入到树莓派4B中,并于目标检测程序保持同一目录下(这里目标检测程序就不展示了):
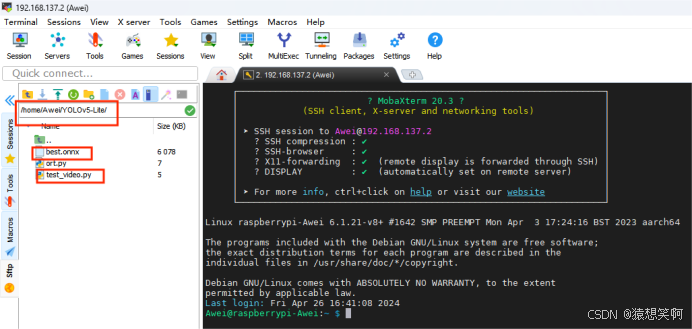
到此,电脑CUDA环境的安装、PyTorch深度学习框架的安装、通过轻量级YOLOv5-Lite训练模型、转为ONNX文件部署到树莓派上运行已全部完成!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









