







1、pod节点服务的高可用
1.1 就绪探针的实现
在2-4中我们还留有一个探针没有提及就是就绪探针ReadinessProbe
就绪探针和存活探针一样,伴随整个容器的生命周期,探测pod是否有资格进入ready状态,只有进入ready状态的pod才能被流量分发,如果pod经过探测之后不是ready状态,在service中会剔除该pod,在endpoint中也会被剔除,将不会再有流量。
通过部署就绪探针,我们可以实现对于服务的动态控制,如果这个服务出现了问题,那么我们就将他从我们的转发集群中剔除出去,从而不影响客户端的访问。
就绪探针是向外请求服务的最关键的一个探针,它能精确控制流量分发,在Pod初始化、更新或出现临时故障时,只有当就绪探针检测成功,Pod才会被纳入Service的负载均衡池中,避免未就绪的Pod接收流量,防止请求失败、超时以及上游服务的重试风暴等问题,有效避免级联故障在分布式系统中的扩散。同时,就绪探针为渐进式交付策略提供了支持,在灰度发布、金丝雀发布等场景中,帮助实现流量的渐进切换。
此外,它与存活探针协同工作,存活探针关注容器是否在运行,就绪探针则聚焦容器能否正常处理请求,二者结合保障了容器的健康运行和服务能力。而且,就绪探针的状态可作为重要的监控指标,提高系统的可观测性,通过收集探针成功率、配置告警阈值以及结合日志分析,能及时发现并排查潜在问题,确保只有真正可服务的Pod接收外部请求,提升系统稳定性,降低故障恢复时间,是构建高可用、弹性云原生应用的核心组件和关键实践。
以下是就绪探针的yaml示例,要注意的一点是,因为我们需要对外提供服务,所以在就绪探针的末尾字段我们需要添加一段service字段,也可以再写一份service.yaml,但此处我们直接将两个yaml文件结合起来了。
#就绪探针字段
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest1
labels:
app: nginx1
spec:
replicas: 3
selector:
matchLabels:
app: nginx1
template:
metadata:
labels:
app: nginx1
spec:
containers:
- name: nginx
image: nginx:1.22
readinessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 1
#表示容器启动之后多少秒之内开启探测
periodSeconds: 3
#表示探针执行的间隔时间,即多少秒执行一次
failureThreshold: 3
#在pod被标记为不健康时,探测运行的失败次数
timeoutSeconds: 3
#探测的超时时间,在多少秒内必须完成探测
successThreshold: 1
#判断成功几次任务容器就已就绪
#service字段
---
apiVersion: v1
kind: Service
metadata:
name: nginx-readiness
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30001
selector:
app: nginx1
1.2 pod提供的高可用服务的验证
现在的状态:三个pod节点均在流量转发的行列
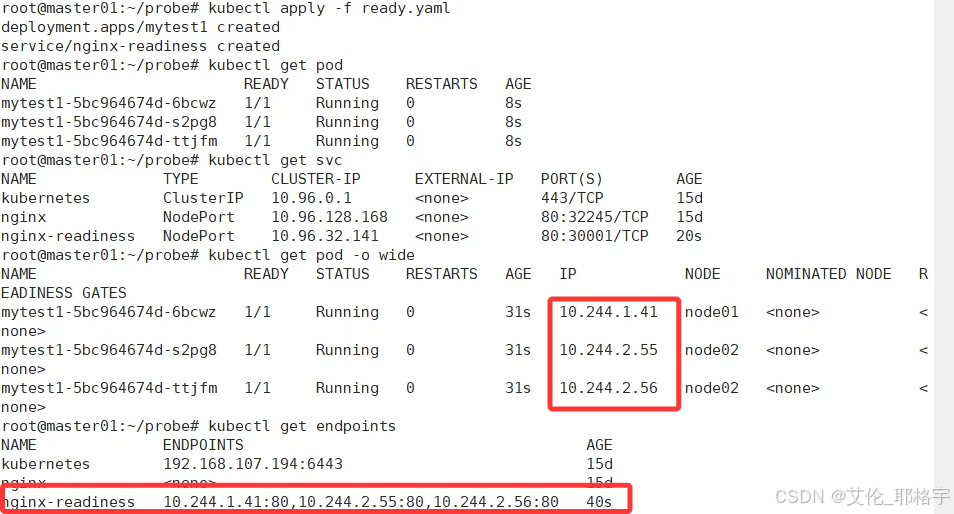
1.2.1 我们进入随机一个pod并删除其中的index.html文件,查看k8s可转发的集群
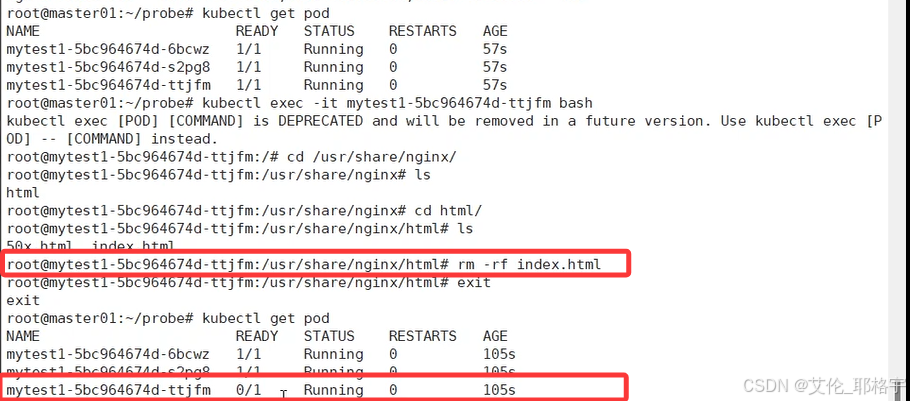
我们可以看到现在被删除的pod节点已经不是正常的状态了
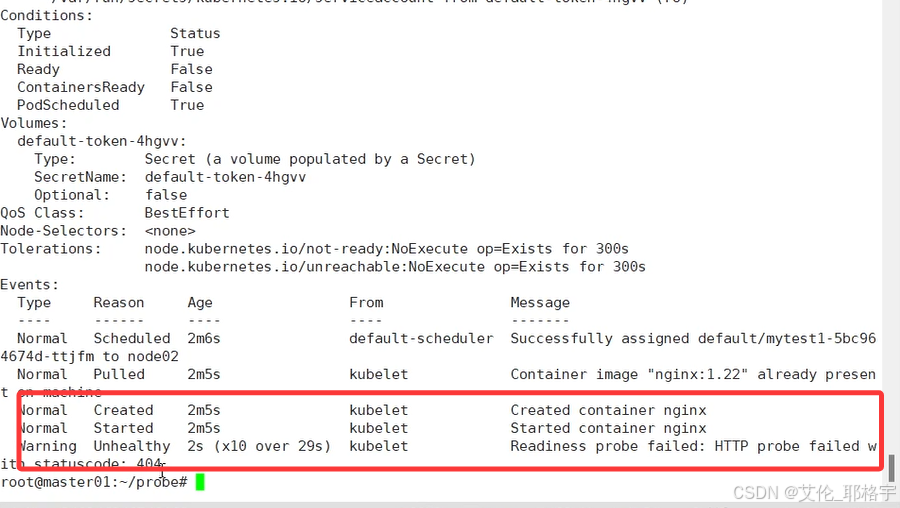
查看pod状态显示为就绪探针失败
此时的转发行列中已经没有了被我们删除index.html的IP地址
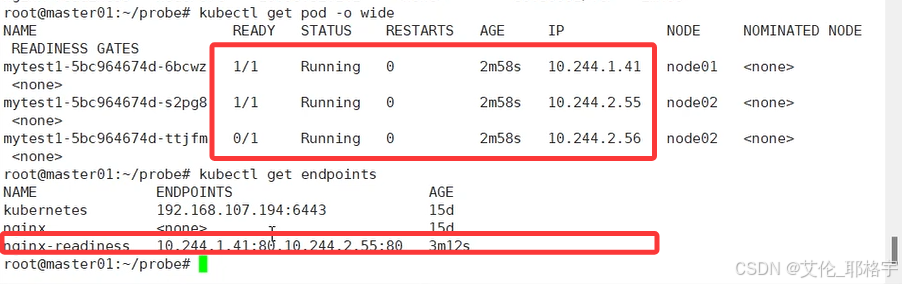
1.2.2 我们再次进入刚刚删除文件的pod中,定义一个特殊的index.html文件
可以发现,有了index.html文件,pod节点就正常运行了
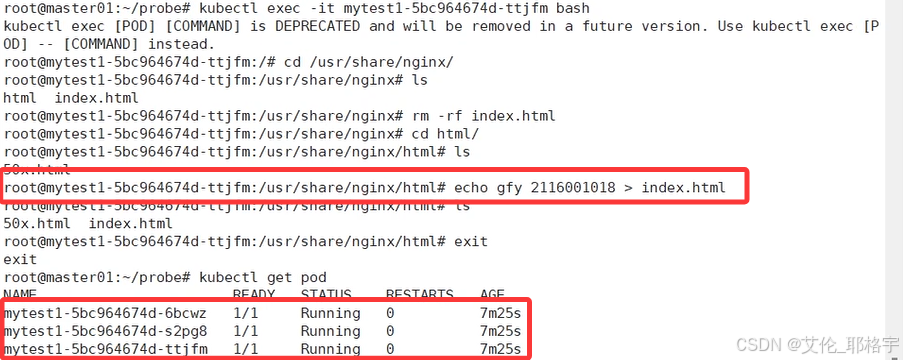
1.2.3 观察其集群的情况,用浏览器访问,看到的现象应为,两个nginx的默认网页站点+我们刚刚定义的特殊网页
验证成功
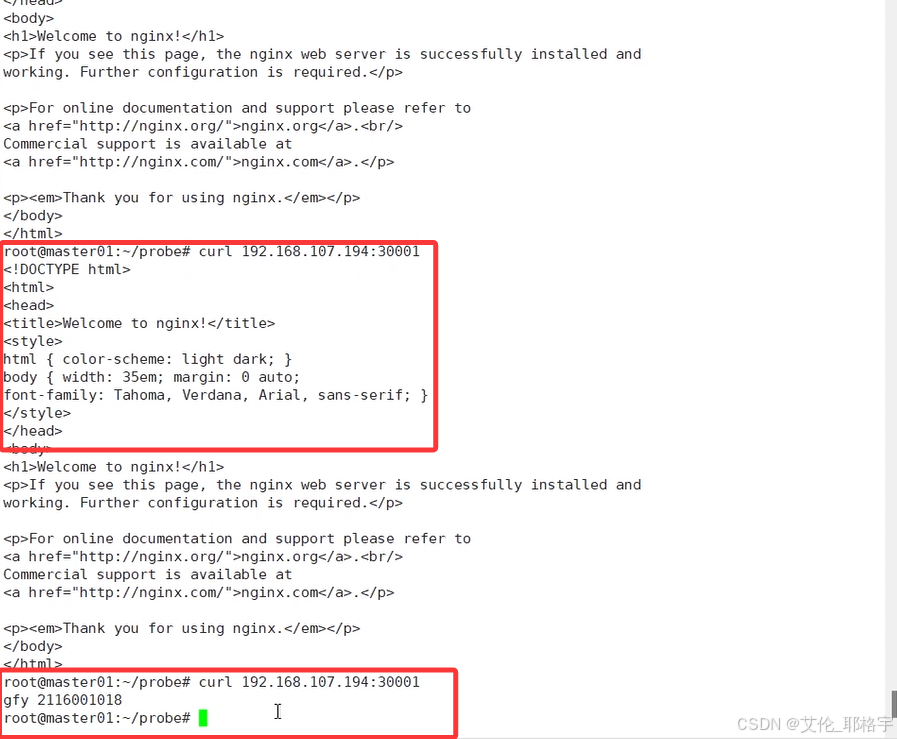
但是需要注意的点是,就绪探针并不会自动重启,我们需要人为的排错让服务变得正常之后,pod就会被自动的加入到转发行列。
2、污点相关的介绍
2.1 污点的解释
Kubernetes中的污点(Taints)是一种作用于节点的属性,它能够拒绝Pod的调度,除非这些Pod具备与之相匹配的容忍度(Tolerations)。借助污点机制,集群管理员可以对特定节点的使用进行精细控制,将一些特殊任务定向调度到指定节点,或者避免普通任务占用特殊配置的节点。当为节点添加污点之后,除非Pod明确声明能够容忍该污点,否则无法在该节点上调度运行。这种机制在多种场景下都能发挥重要作用,比如在专用硬件节点(像配备GPU的节点)上,通过设置污点可以确保只有那些真正需要GPU资源的Pod才能被调度到这些节点上运行,从而充分发挥专用硬件的性能优势;在执行节点维护操作(如升级kubelet或操作系统)之前,为节点添加污点可以使Pod自动迁移到其他节点,实现优雅排空,避免对业务造成影响;在多租户集群中,通过设置污点能够实现资源的隔离,不同租户的Pod只能调度到具有相应容忍度的节点上,保证各租户资源的独立性和安全性。需要注意的是,污点和容忍度是相辅相成的关系,它们共同构建了一种灵活的排斥策略,为Kubernetes集群提供了强大的调度控制能力,使得集群资源的分配更加合理、高效。
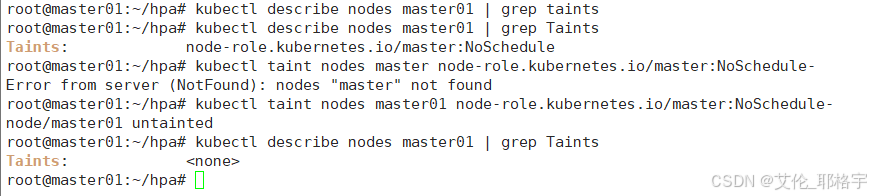
2.2 如何删除部署在节点上的污点
在后续我们部署HPA服务的时候会用得到
kubectl describe nodes master01 | grep Taints
kubectl taint nodes master01 node-role.kubernetes.io/master:NoSchedule-

2.3 污点容忍的简要介绍
污点容忍是Kubernetes中用于处理节点污点的一种机制。节点上的污点会阻止不具备相应容忍度的Pod被调度到该节点。而Pod通过设置污点容忍,来表明自己可以容忍特定的污点,从而能够被调度到带有相应污点的节点上。这样就实现了对Pod调度的精细控制,让集群管理员可以根据节点的特性和Pod的需求,合理分配资源,比如将有特殊资源需求的Pod调度到特定的节点上,同时避免普通Pod误调度到这些特殊节点,保证集群资源的有效利用和业务的稳定运行。
值得一提的是:污点容忍只能在yaml文件中实现,不能通过命令行实现
3、亲和性和反亲和性
Pod节点的亲和性和反亲和性是Kubernetes中用于控制Pod在节点上调度的重要机制。亲和性允许用户定义Pod倾向于被调度到具有特定标签的节点上,这有助于将相关的Pod部署到相近的节点,例如将相互依赖的微服务Pod调度到同一区域或同一机架的节点上,以减少网络延迟,提高服务间的通信效率。同时,亲和性还可以根据节点的资源特性,将对资源需求相似的Pod集中调度,实现资源的高效利用。而反亲和性则与亲和性相反,它规定Pod避免被调度到具有特定标签的节点上,常用于避免将有冲突或相互干扰的Pod部署到同一节点,比如不同业务线的Pod或对资源竞争激烈的Pod,通过反亲和性可以将它们分散到不同的节点,以保证各个Pod的稳定运行,提高整个集群的可靠性和稳定性。通过灵活运用Pod节点的亲和性和反亲和性,能够更好地优化集群资源分配,提升应用的性能和可靠性。
当然,亲和性和污点并不是我们这个项目主要研究的,我们以后在做进一步探讨。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









