







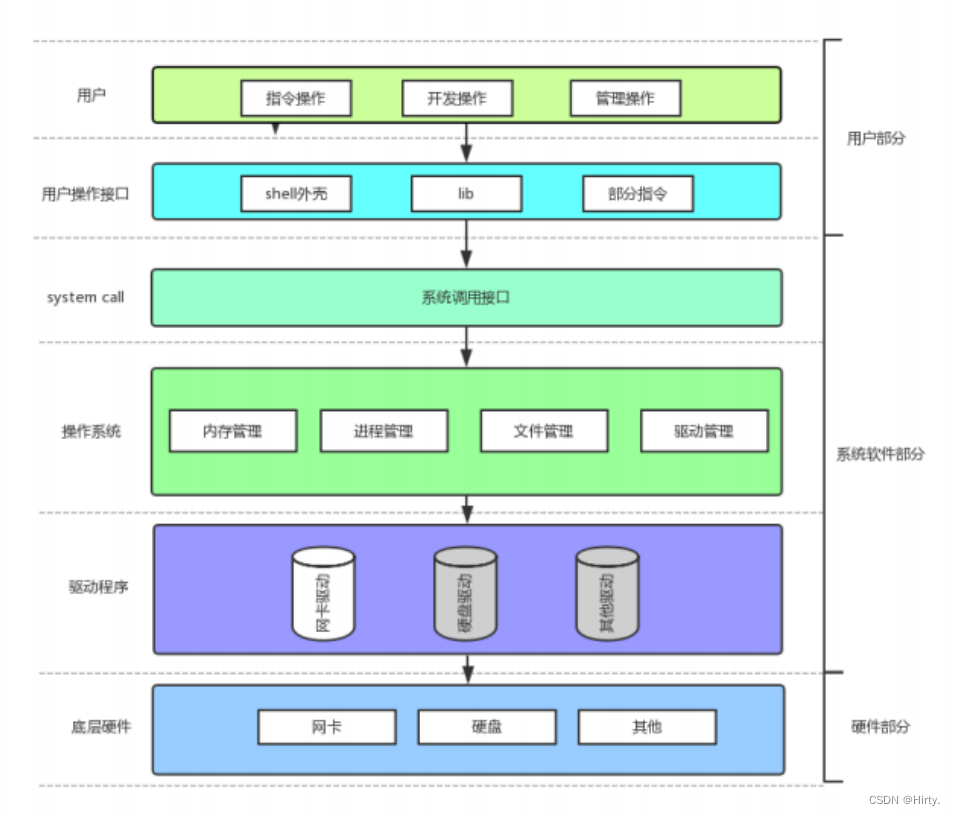
回顾C文件接口


stdin & stdout & stderr
C 默认会打开三个输入输出流,分别是 stdin, stdout, stderr仔细观察发现,这三个流的类型都是 FILE*, fopen 返回值类型,文件指针
系统文件I/O
接口介绍
open
man open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char* pathname, int flags);
int open(const char* pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags : 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数 :
O_RDONLY: 只读打开
O_WRONLY : 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND : 追加写O_TRUNC:打开文件时会清空文件内容
返回值:
成功:新打开的文件描述符
失败: - 1
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
umask(0);
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
if (fd < 0) {
perror("open");
return 1;
}
int count = 5;
const char* msg = "hello bit!\n";
int len = strlen(msg);
while (count--) {
write(fd, msg, len);//fd: 后面讲, msg:缓冲区首地址, len: 本次读取,期望写入多少个字节的数据。 返回值:实际写了多少字节数据
//默认不会清空文件内容,从头开始写
}
close(fd);
return 0;
}#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
const char* msg = "hello bit!\n";
char buf[1024];
while (1) {
ssize_t s = read(fd, buf, strlen(msg));//类比write
if (s > 0) {
printf("%s", buf);
}
else {
break;
}
}
close(fd);
return 0;
}open函数返回值
文件描述符fd
0 & 1 & 2
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
char buf[1024];
ssize_t s = read(0, buf, sizeof(buf));
if (s > 0) {
buf[s] = 0;
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
}
return 0;
}
理解stderr和标准输出重定向>
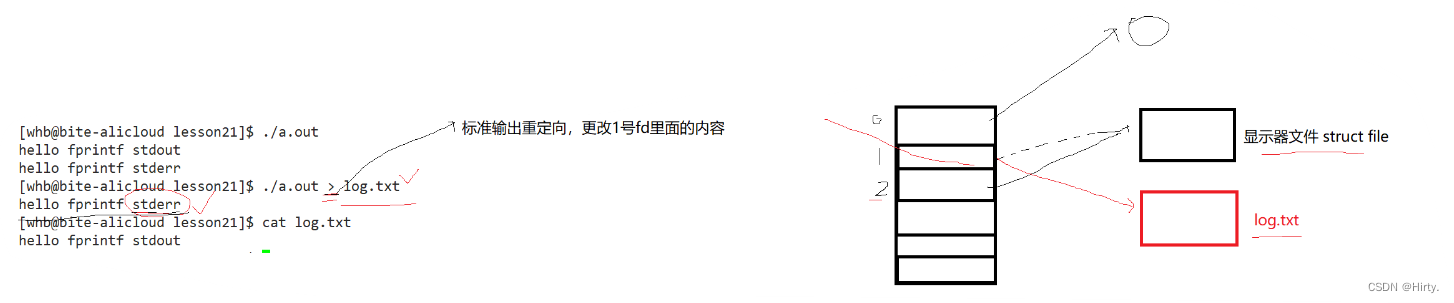
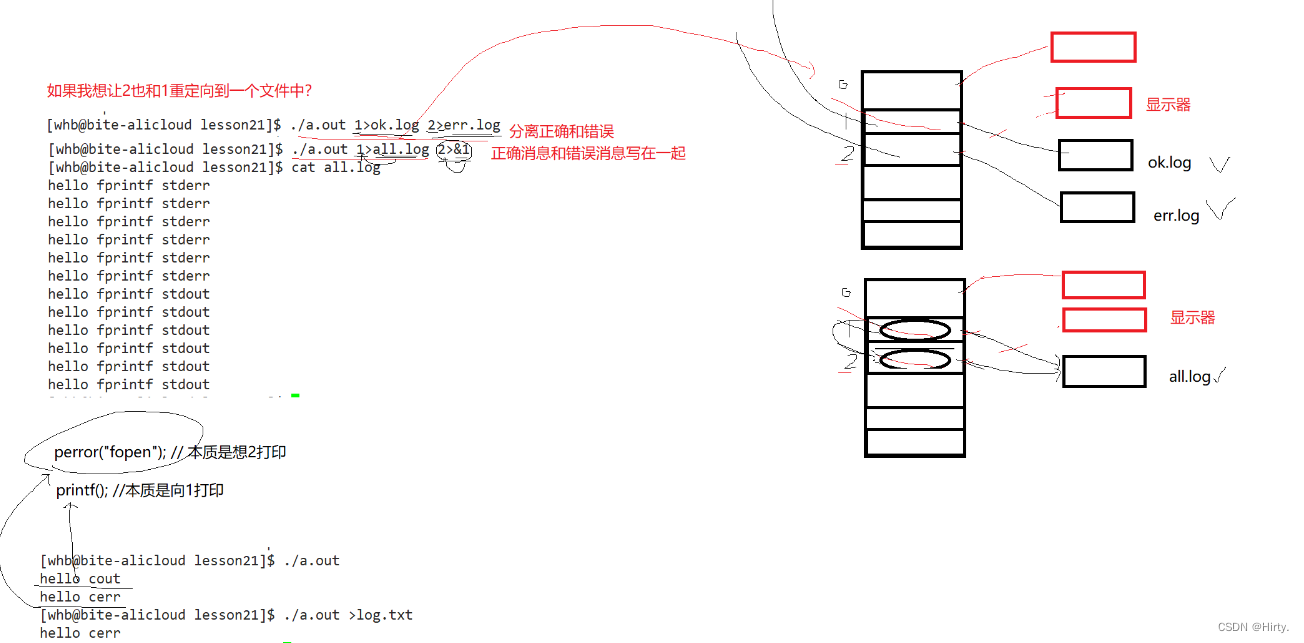
文件描述符的分配规则
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}用库函数而不用系统调用的原因
系统调用:代码不具备跨平台性

重定向
那如果关闭1呢?看代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);//刷新语言级别的文件缓冲区,将数据刷新到内核文件缓冲区中
close(fd);
return 0;
}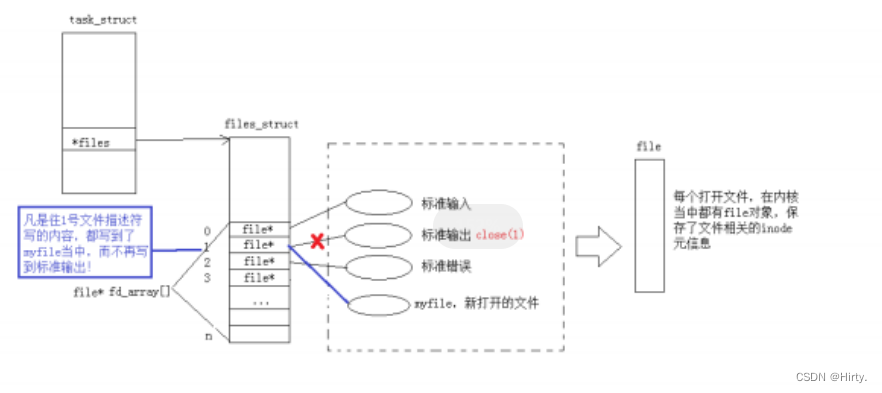


使用 dup2 系统调用
函数原型如下:
#include <unistd.h>int dup2(int oldfd, int newfd);
原理解析
dup2 函数的实现原理可以简要概括如下:
首先,检查 newfd 是否合法。如果 newfd 等于 oldfd,则直接返回 newfd。
然后,检查 newfd 是否已经打开。如果已经打开,则关闭 newfd。
调用系统调用 dup2(oldfd, newfd) 完成文件描述符的复制。该系统调用会将 newfd 关联到与 oldfd 相同的文件,使得它们指向相同的文件表项。
最后,返回 newfd。
注意事项和常见问题
在使用 dup2 函数时,需要注意以下几点:
传递给 dup2 的两个文件描述符必须是有效的。否则,函数调用将失败并返回 -1。
使用 dup2 之前,最好先关闭 newfd,以避免文件描述符泄露和资源浪费。
dup2 函数并不会关闭 oldfd,因此在复制完成后,需要根据实际需求手动关闭 oldfd。

示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
const char* filename = "log.txt";
int main()
{
//int fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);
int fd = open(filename, O_CREAT | O_WRONLY | O_APPEND, 0666);
if(fd < 0)
{
perror("open");
return 1;
}
dup2(fd, 1);
printf("hello world\n");
fprintf(stdout, "hello world\n");
fflush(stdout);
close(fd);
return 0;
}FILE
#include <stdio.h>
#include <string.h>
int main()
{
const char* msg0 = "hello printf\n";
const char* msg1 = "hello fwrite\n";
const char* msg2 = "hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}hello printf
hello fwrite
hello writehello write
hello printf
hello fwrite
hello printf
hello fwrite一般 C 库函数写入文件时是全缓冲的,而写入显示器是行缓冲。printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至 fork 之后但是进程退出之后,会统一刷新,写入文件当中。但是 fork 的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。write 没有变化,说明没有所谓的缓冲
typedef struct _IO_FILE FILE ; 在 /usr/include/stdio.h
在 /usr/include/libio.hstruct _IO_FILE {int _flags; /* High-order word is _IO_MAGIC; rest is flags. */#define _IO_file_flags _flags// 缓冲区相关/* The following pointers correspond to the C++ streambuf protocol. *//* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */char* _IO_read_ptr; /* Current read pointer */char* _IO_read_end; /* End of get area. */char* _IO_read_base; /* Start of putback+get area. */char* _IO_write_base; /* Start of put area. */char* _IO_write_ptr; /* Current put pointer. */char* _IO_write_end; /* End of put area. */char* _IO_buf_base; /* Start of reserve area. */char* _IO_buf_end; /* End of reserve area. *//* The following fields are used to support backing up and undo. */char *_IO_save_base; /* Pointer to start of non-current get area. */char *_IO_backup_base; /* Pointer to first valid character of backup area */char *_IO_save_end; /* Pointer to end of non-current get area. */struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno; // 封装的文件描述符#if 0int _blksize;#elseint _flags2;#endif_IO_off_t _old_offset; /* This used to be _offset but it's too small. */#define __HAVE_COLUMN /* temporary *//* 1+column number of pbase(); 0 is unknown. */unsigned short _cur_column;signed char _vtable_offset;char _shortbuf[1];/* char* _save_gptr; char* _save_egptr; */_IO_lock_t *_lock;#ifdef _IO_USE_OLD_IO_FILE};
简述重定向的实现原理
每个文件描述符都是一个内核中文件描述信息数组的下标,对应有一个文件的描述信息用于操作文件,而重定向就是在不改变所操作的文件描述符的情况下,通过改变描述符对应的文件描述信息进而实现改变所操作的文件。
理解文件系统
[root@localhost linux]# ls -l总用量 12-rwxr-xr-x. 1 root root 7438 "9 月 13 14:56" a.out-rw-r--r--. 1 root root 654 "9 月 13 14:56" test.c
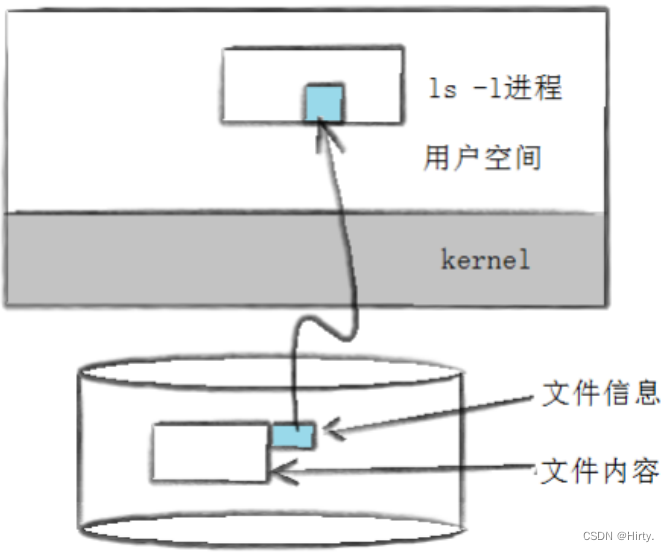
其实这个信息除了通过这种方式来读取,还有一个stat命令能够看到更多信息
[root@localhost linux]# stat test.cFile: "test.c"Size: 654 Blocks: 8 IO Block: 4096 普通文件Device: 802h/2050d Inode: 263715 Links: 1Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)Access: 2017-09-13 14:56:57.059012947 +0800Modify: 2017-09-13 14:56:40.067012944 +0800Change: 2017-09-13 14:56:40.069012948 +0800
上面的执行结果有几个信息需要解释清楚
inode
inode(Index Node,索引节点)是文件系统中的一种数据结构(结构体),用于存储文件或目录的元数据信息。每个文件或目录都与一个唯一的inode相关联,该inode包含了关于文件或目录的诸多属性,如文件大小、文件类型、权限、拥有者、创建时间、修改时间等。此外,inode还存储了文件数据的物理位置信息,例如文件数据存储在磁盘上的哪个扇区。
当我们在Linux系统中创建一个文件或目录时,操作系统会为其分配一个空闲的inode,并将文件的元数据信息写入该inode中。因此,inode在文件系统中起着非常重要的作用,它充当了文件和目录的索引,使操作系统能够快速定位和管理文件数据。

详细分析:


Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子。
[root@localhost linux]# touch abc[root@localhost linux]# ls -i abc263466 abc
为了说明问题,我们将上图简化:

创建一个新文件主要有一下4个操作:
理解硬链接
263563 -rw-r--r--. 2 root root 0 9 月 15 17:45 abc261678 lrwxrwxrwx. 1 root root 3 9 月 15 17:53 abc.s -> abc263563 -rw-r--r--. 2 root root 0 9 月 15 17:45 def



动态库和静态库
测试程序
/add.h/
#ifndef __ADD_H__
#define __ADD_H__
int add(int a, int b);
#endif // __ADD_H__
/add.c/
#include "add.h"
int add(int a, int b)
{
return a + b;
}
/sub.h/
#ifndef __SUB_H__
#define __SUB_H__
int sub(int a, int b);
#endif // __SUB_H__
/add.c/
#include "add.h"
int sub(int a, int b)
{
return a - b;
}
///main.c
#include <stdio.h>
#include "add.h"
#include "sub.h"
int main( void )
{
int a = 10;
int b = 20;
printf("add(10, 20)=%d\n", a, b, add(a, b));
a = 100;
b = 20;
printf("sub(%d,%d)=%d\n", a, b, sub(a, b));
}生成静态库
[root@localhost linux]# ls
add.c add.h main.c sub.c sub.h
[root@localhost linux]# gcc -c add.c -o add.o
[root@localhost linux]# gcc -c sub.c -o sub.o
生成静态库
[root@localhost linux]# ar -rc libmymath.a add.o sub.o
ar是gnu归档工具,rc表示(replace and create)
查看静态库中的目录列表
[root@localhost linux]# ar -tv libmymath.a
rw-r--r-- 0/0 1240 Sep 15 16:53 2017 add.o
rw-r--r-- 0/0 1240 Sep 15 16:53 2017 sub.o
t:列出静态库中的文件
v:verbose 详细信息
[root@localhost linux]# gcc main.c -L. -lmymath
-L 指定库路径
-l 指定库名
测试目标文件生成后,静态库删掉,程序照样可以运行.库搜索路径
生成动态库
使用动态库
运行动态库
[root@localhost linux]# export LD_LIBRARY_PATH=.
[root@localhost linux]# gcc main.c -lmymath
[root@localhost linux]# ./a.out
add(10, 20)=30
sub(100, 20)=80 [root@localhost linux]# cat /etc/ld.so.conf.d/bit.conf
/root/tools/linux
[root@localhost linux]# ldconfig使用外部库
#include <math.h>
#include <stdio.h>
int main(void)
{
double x = pow(2.0, 3.0);
printf("The cubed is %f\n", x);
return 0;
}
gcc -Wall calc.c -o calc -lm















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









