






写在前面的总结:
1、目前分类损失函数为何多用交叉熵,而不是KL散度。
首先损失函数的功能是通过样本来计算模型分布与目标分布间的差异,在分布差异计算中,KL散度是最合适的。但在实际中,某一事件的标签是已知不变的(例如我们设置猫的label为1,那么所有关于猫的样本都要标记为1),即目标分布的熵为常数。而根据下面KL公式可以看到,KL散度 - 目标分布熵 = 交叉熵(这里的“-”表示裁剪)。所以我们不用计算KL散度,只需要计算交叉熵就可以得到模型分布与目标分布的损失值。
1.信息熵

发生概率越小的事情发生了,那么信息量就很大,比如国足夺冠(这信息量大上天了!!!)。
发生概率大的事情发生了,那么信息量就很小,比如国足没夺冠(哦)
而恰好这个函数很符合这个直观看法
所以他就是信息熵。
2.相对熵(KL散度)
对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。

凸函数

这是显而易见的,右半部分就是x,f(x)两点连线上的任意一点。
p(x)换成 lambda
jensen引理
易得:
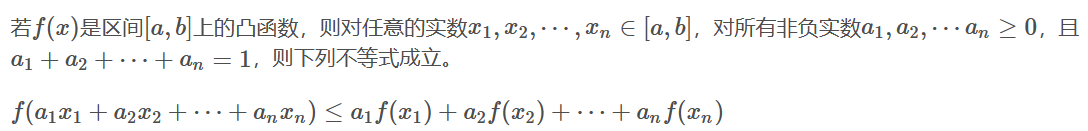

kl散度恒正得证。
相对熵,同一事物不同分布之间的差异
如果两个概率差不多,那么它们的相对熵就很小。
如果两个概率能差7,80%,那就差别很离谱了,所以相对熵非常大
而且这个相对熵必须是正的,来衡量两个分布的区别。
刚好上面这个函数符合这两条规则
kl散度来衡量p(x)和q(x)之间的差异
但是有个问题:你对我的误差和我对你的误差应该是一样的,即对称的,但kl散度显然不对称。
所以js散度就出来了:
js散度

3.交叉熵:

kl散度实际上就是p(x)的信息熵加上另一个式子
如果p(x)是已经确定的真实的结果,那么信息熵就为0
顺势出来的这个式子可以反应和真实结果的差异。我们定义为交叉熵。
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,由于KL散度中的前一部分−H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
4.Wasserstein距离
联合分布
(X,Y)是二维随机变量,x,y是任意实数,二元函数:F(x,y)=P({X≤x∩Y≤y})=P(X≤x,Y≤y),被称二维随机变量(X,Y)的分布函数,或称为X和Y的联合分布函数。
sup是supremum的简写,意思是:上确界,最小上界。
inf是infimum的简写,意思是:下确界,最大下界。
如果两个分配P,Q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。
这个常数值恰好是 (ln 2),表示它在这种情况下的稳定性。
(很好理解,完全不重叠时,原式变成了kl((p||p/2) ),也就是ln2了)
这在学习算法中是比较致命的,这就意味这这一点的梯度为0。梯度消失了。


看第一眼确实哄人,看不懂
但我发现这也不就是求|x-y|的期望的最小值嘛
看到了:
在γ这个路径规划下把土堆P1挪到土堆P2所需要的消耗。而Wasserstein距离就是在最优路径规划下的最小消耗。所以Wesserstein距离又叫Earth-Mover距离。
瞬间就觉得我理解对了。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近;而JS散度在此情况下是常量,KL散度可能无意义。
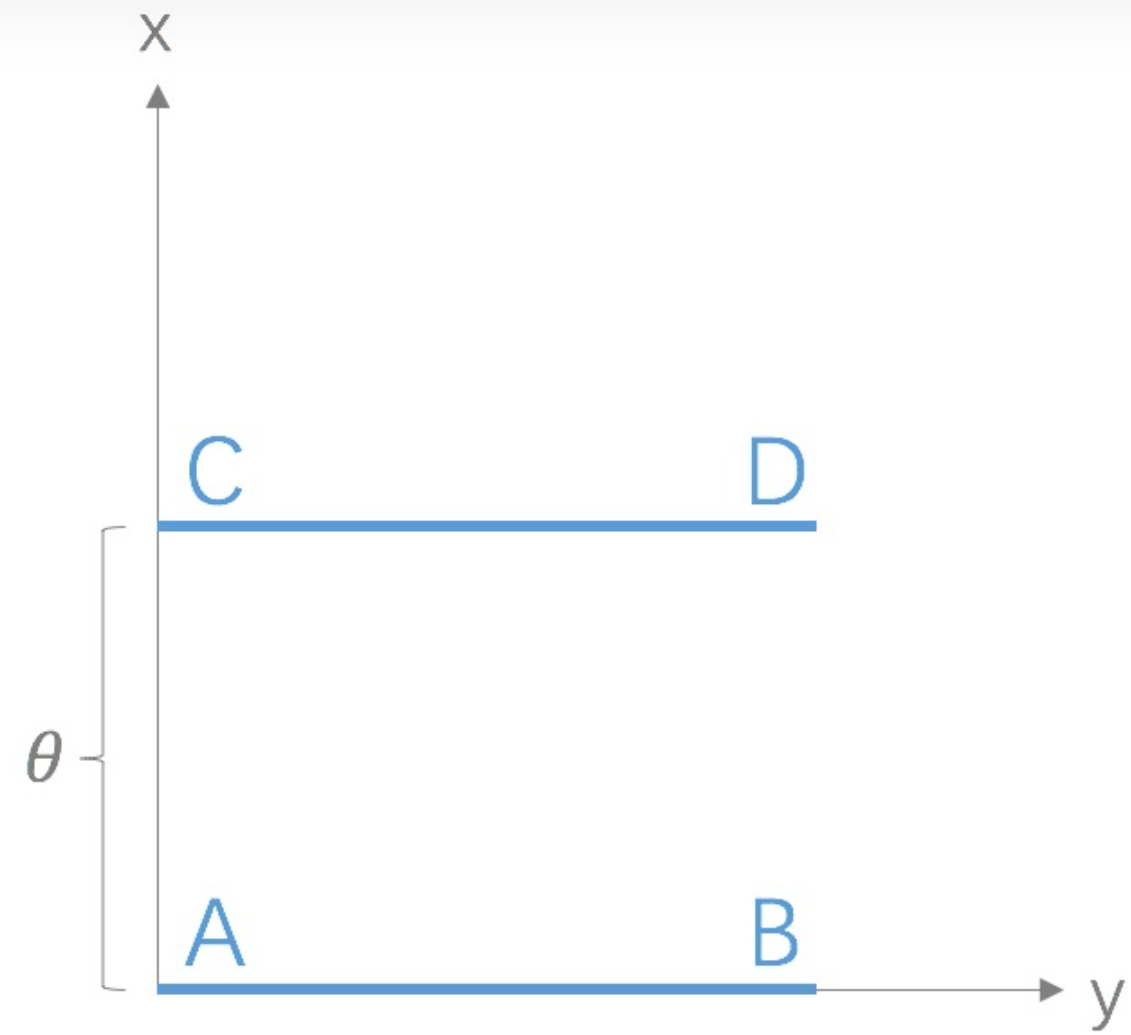
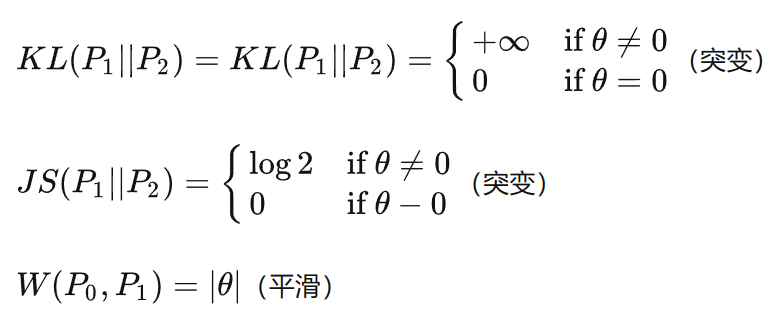
KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化therta这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









