



注:作者为初学者,有些知识不太熟悉,可能描述有误,望见谅。
Unet的讲解请看博主的这篇文章:
TransUnet简介
TransUnet是一种结合了Transformer和U-Net结构的混合网络架构,旨在解决医学图像分割任务中的长距离依赖问题。传统U-Net在局部特征提取上表现优异,但是在全局上下文建模方面存在局限。
TransUnet 通过将 Transformer 引入 U-Net 的编码器部分,使得模型既能保留 CNN 的局部特征提取能力,又能利用 Transformer 的全局建模能力,从而提升分割精度,它能够更好地处理图像中的小目标和复杂结构,减少了对大量标注数据的依赖。特别是在处理复杂、细节丰富的医学图像时表现优越。
注:具体一点来说引入transformer的作用是:
(1)把 CNN 特征图切成 1×1 的小 patch-token,把局部特征“序列化”成全局可交互的 token,从而用自注意力一次性建立任意两点间的长距离依赖,弥补纯卷积只能逐层扩大感受野的局限。
这个操作的时机是:CNN 下采样一结束,马上用 1×1 卷积把 H/16×W/16×512 特征图逐点拉成 token 序列,即刻送进 Transformer。
每个 1×1×512 的向量就是一个 patch-token。 这一步并没有真的再“切”图像,而是把已经只有 H/16×W/16 大小的特征图直接当成 H/16·W/16 个 1×1 的网格,每个网格点即为一个 token。
(2)通过多头自注意力+FFN 的堆叠,把局部 CNN 特征进一步提炼成高阶语义特征,这些特征对器官/病灶的整体形状、空间上下文更敏感,显著降低过分割或欠分割概率。
所以在正式讲TransUnet之前,可以简单看一下博主关于Transformer的讲解:
整体流程
输入医学图像(如 CT 图像),先通过 CNN 进行初步特征提取与下采样,得到局部特征;再将这些特征输入 Transformer 层,捕获长距离依赖关系;之后对 Transformer 输出的特征进行上采样,并与 CNN 不同阶段的特征融合,最后通过分割头得到分割结果。
各部分详细解析与示例
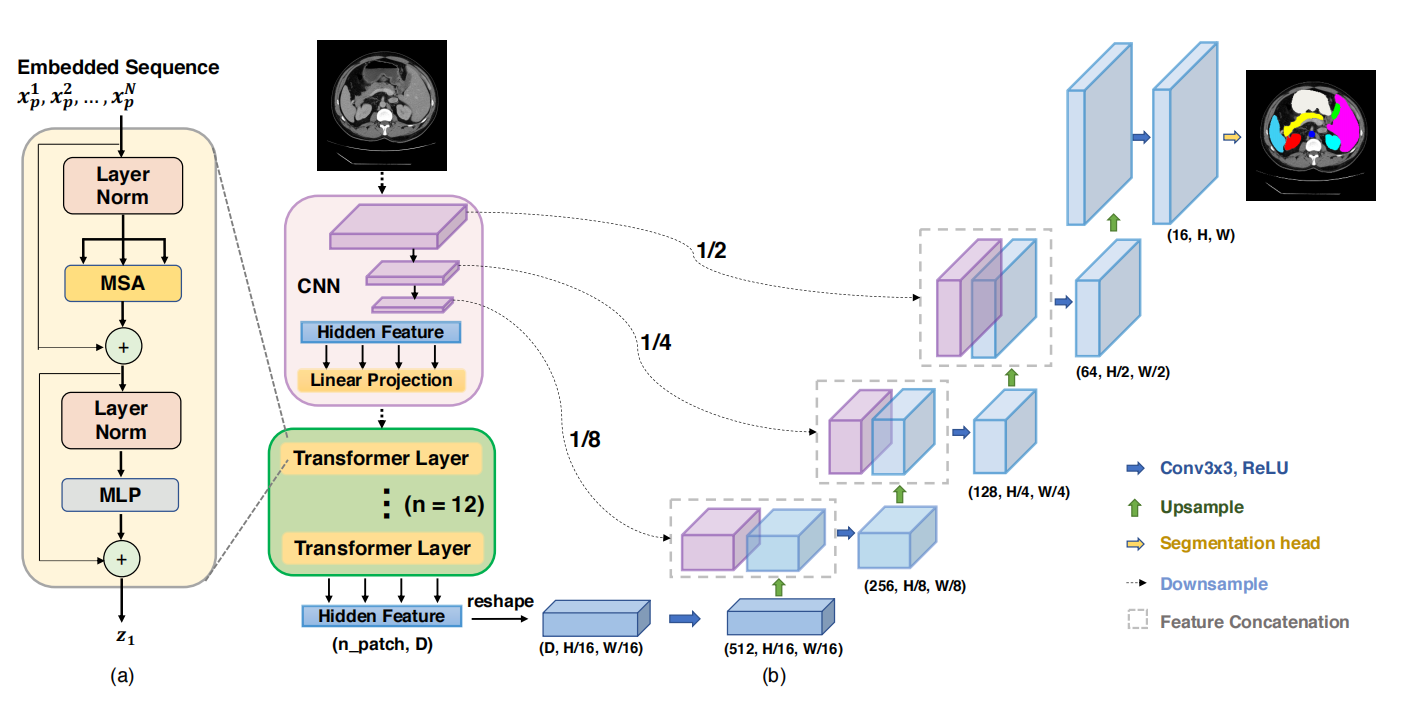
TransUnet结构图如下所示:
这里就不做代码示例了,仅作出操作的流程介绍。
(1)CNN 特征提取与下采样阶段操作
输入图像首先进入 CNN 模块。CNN 通过多层卷积(如 Conv3×3,ReLU 激活)和下采样(Downsample)操作,对图像进行特征提取并降低分辨率。经过 CNN 下采样后,得到不同尺度的隐藏特征(Hidden Feature)。同时,特征维度逐渐增加,以包含更丰富的信息。
后续处理:这些隐藏特征经过线性投影(Linear Projection),将其转换为适合 Transformer 处理的格式。
(2)Transformer 特征处理阶段
Transformer 层内部结构(对应图(a)):Layer Norm + MSA:首先对输入的嵌入序列(Embedded Sequence,即从 CNN 来的投影后特征)进行层归一化(Layer Norm),然后通过多头自注意力(MSA)模块,捕获序列中不同位置特征之间的长距离依赖关系。例如,序列中不同 patch(图像分块)的特征会通过注意力机制进行信息交互,能学习到图像中相隔较远区域的关联。
残差连接(+):MSA 输出与输入序列进行残差连接,缓解梯度消失问题,保留原始信息。
Layer Norm + MLP:接着再次进行层归一化,然后通过多层感知机(MLP)对特征进行非线性变换,增强特征表达能力。之后又进行残差连接,得到 Transformer 层的输出 (z_1)。Transform中MLP实际上是一个FFN,也就是一个两层线性变换 + ReLU 激活函数。
多Transformer 层堆叠:图中使用了 (n = 12) 层 Transformer 层(绿色 “Transformer Layer” 部分),逐步对特征进行更深入的长距离依赖建模。经过这些 Transformer 层处理后,得到形状为 (n_patch, D) 的隐藏特征(n_patch) 是 patch 数量,D 是特征维度)。
特征重塑(reshape):将 Transformer 输出的特征重塑为 (D, H/16, W/16)的形状(假设经过多次下采样后,最终空间尺寸为输入的 (1/16),进一步调整为 (512, H/16, W/16)(特征维度变为 512),使其能与后续 CNN 特征进行融合。
(3)特征融合与上采样阶段多尺度特征融合
Transformer 处理后的特征与 CNN 不同下采样阶段的特征进行融合(Feature Concatenation)。融合时,通过上采样(Upsample)操作将低分辨率特征放大到高分辨率特征的尺寸,然后进行拼接,整合不同尺度的特征信息(局部细节与长距离依赖)。上采样恢复分辨率:融合后的特征通过多次上采样操作,逐步恢复图像的空间分辨率。每次上采样后,可能会伴随卷积操作(Conv3×3,ReLU)来细化特征。
(4)分割头(Segmentation head)输出结果操作
经过上采样和特征融合后,最终的特征输入到分割头。分割头通常是一个卷积层,将特征映射到目标类别数量的通道数(比如要分割为 5 类,就输出 5 个通道)。结果:通过 softmax 等激活函数,得到每个像素属于不同类别的概率图,从而完成图像分割,得到与输入图像尺寸相同的分割结果(如图中右侧彩色标注的分割图)。


















 4912
4912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









