







目录
集群配置
三台服务器:linux01、linux02、linux03
每台服务器均安装了zookeeper、kafka,服务器之间做了ssh免密登录(集群启停脚本用)
kafka虽然内置了zk,但是这里用的是自己安装的zk。
服务器之间加了ip映射,如hosts文件所示,这样就不需要p地址,只需要服务器名字就可以了

集群启动
注意事项
- 启动时先启动zk,再启动kafka
- 关闭时先关闭kafka,再关闭zk,因为kafka需要zk来维护数据信息,再关闭前kafka要和zk通讯。
- kafka-server-start.sh -daemon config/server.properties
- kafka-server-stop.sh
脚本启动zk集群

脚本启动kafka集群
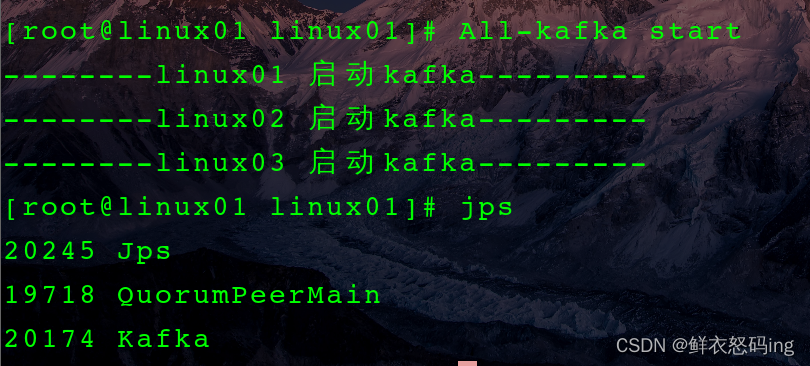
启动成功
启动成功,三台服务器均显示如下:

查看zk客户端,根节点下已经有了kafka节点
默认直接在根节点下生成admin、brokers、cluster等节点,但是不方便维护,因此在server.properties文件中改了配置,让所有节点统一生成在kafka节点。

zk集群启停脚本
#!/bin/bash
#zookeeper集群启停及状态查看脚本
ZOOKEEPER="/export/server/zookeeper"
case $1 in
"start")
for i in linux01 linux02 linux03
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "$ZOOKEEPER/bin/zkServer.sh start"
done
;;
"stop")
for i in linux01 linux02 linux03
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "$ZOOKEEPER/bin/zkServer.sh stop"
done
;;
"status")
for i in linux01 linux02 linux03
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "$ZOOKEEPER/bin/zkServer.sh status"
done
;;
esac
kafka集群启停脚本
#!/bin/bash
case $1 in
"start"){
for i in linux01 linux02 linux03
do
echo --------$i 启动kafka---------
ssh $i "source /etc/profile;/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties"
done
};;
"stop"){
for i in linux01 linux02 linux03
do
echo --------$i 停止kafka---------
ssh $i "source /etc/profile;/export/server/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
Kafka操作
--bootstrap-server是连接kafka,对于集群而言,连接任何一台服务器的kafka都是一样的
命令行创建Topic

消费者生产者联动

 先启动生产者,生产hello、hahaha,再启动消费者,生产者再生产aaaaa、bbbb。此时hello、hahaha属于历史消息,不会显示,只显示aaaaa、bbbb,若想显示历史消息,需要如下,此时消息是乱序的:
先启动生产者,生产hello、hahaha,再启动消费者,生产者再生产aaaaa、bbbb。此时hello、hahaha属于历史消息,不会显示,只显示aaaaa、bbbb,若想显示历史消息,需要如下,此时消息是乱序的:
Linux配置EFAK3.0.1
1. 配置EFAK的环境变量
ke.sh文件中引用的efak变量名是KE_HOME,所以环境变量名一定是KE_HOME,否则efak无法启动
source /etc/profile

2. 修改kafka的bin/kafka-server-start.sh的内存配置,如果不修改,可能无法启动efak
内容如下:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then #export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" #监控kafka运行的端口号9999 export JMX_PORT="9999" fi注意!修改kafka配置文件后记得重新分发给集群其他的kafka!
scp kafka-server-start.sh root@linux02:/export/server/kafka/bin
scp kafka-server-start.sh root@linux03:/export/server/kafka/bin

3. 修改EFAK的conf/system-config.properties文件,关键内容如下
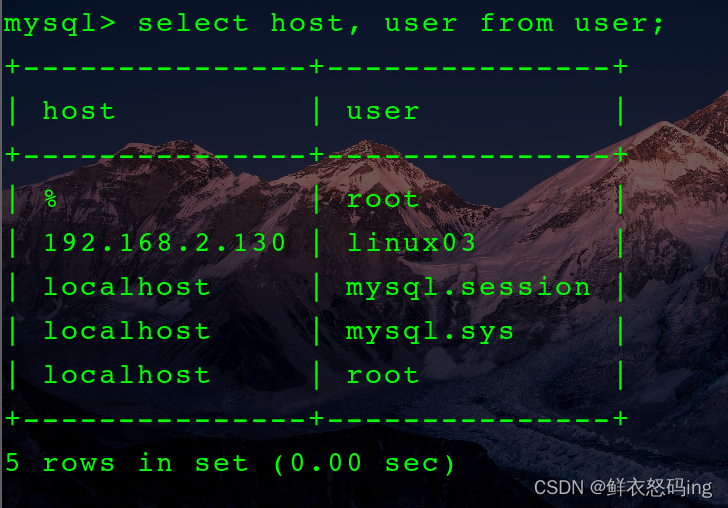
EFAK需要配置mysql的ke数据库来存储元数据,username是连接mysql的登录用户,名字随便起,和linux03服务器无关,需要提前在mysql创建好并授权访问。

我的mysql5.7 在linux01服务器,而EFAK在linux03服务器,这就需要跨服务器连接,解决方法如下。
4. 在linux01的mysql创建名为linux03的用户,并授予对ke数据库的所有权,并规定只有服务器linux03的ip地址才能访问。
CREATE USER 'linux03'@'xxx.xxx.x.xxx' IDENTIFIED BY '#252012';
GRANT ALL PRIVILEGES ON ke.* TO 'linux03'@'xxx.xxx.x.xxx';
注:这里的xxx.xxx.x.xxx是部署了EFAK的服务器ip,也就是服务器linux03的ip
如果创建用户失败,提示了创建的用户密码安全级别过低,那么可以降低密码安全级别
SET GLOBAL validate_password.policy = LOW;flush privileges;
大概意思就是允许ip为xxx.xxx.x.xxx的linux03用户访问数据库
5. 启动并登录EFAK
依次启动zk、kafka
zk和kafka集群启动脚本是我自己编写的
zk-All.sh start
All-kafka start
然后ke.sh start
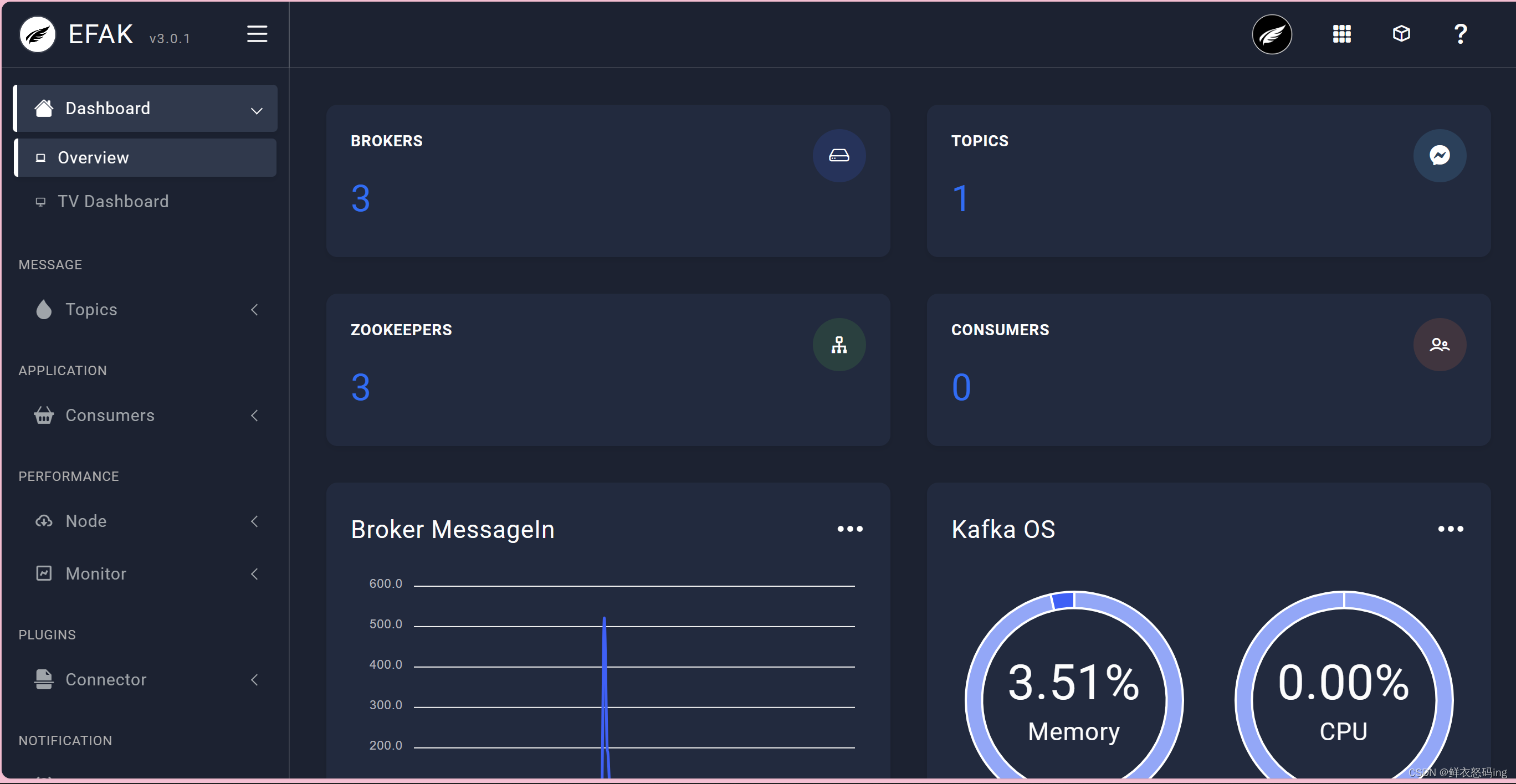
启动成功!账户是admin,密码123456
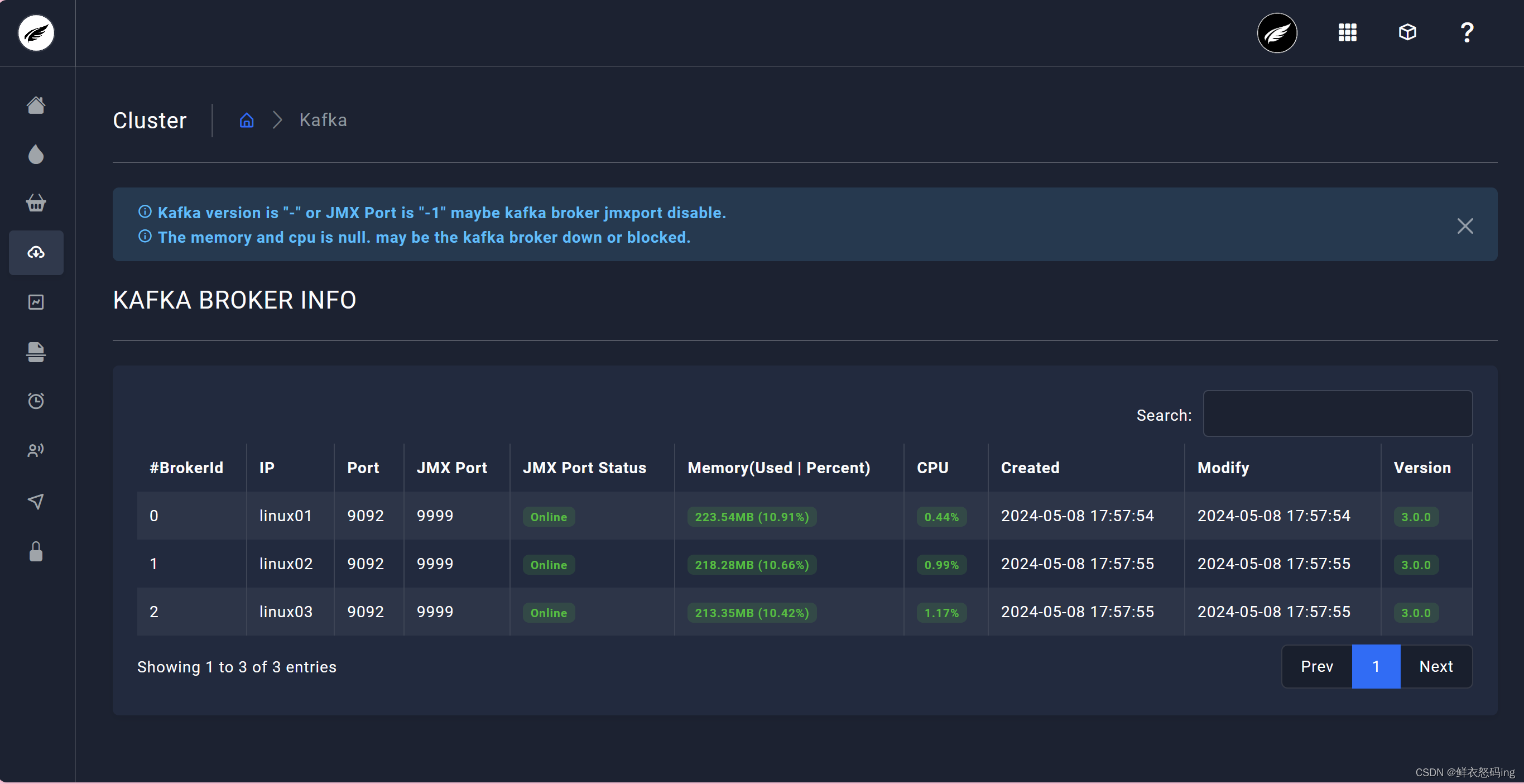
访问成功,可以看到3台broker成功运行

Kraft模式集群
在 Kafka 2.8.0 版本,移除了对 Zookeeper 的依赖,通过 Kraft模式的controller管理集群,使用 Kafka 内部的 Quorum 控制器来取代 ZooKeeper管理元数据,元数据保存在controller中,这样我们无需维护zk集群,只要维护Kafka集群就可以了,节省运算资源。
优点
- kafka不再依赖外部框架,能独立运行
- controller管理集群时不需要和zk通讯,集群性能提升
- 脱离了zk依赖,集群扩展不受zk读写能力的限制
- controller不再动态选举,而由配置文件决定,这样可以针对性的加强controller的节点配置,而不是像以前一样对随机controller节点的高负载束手无策。
配置
不在原来的kafka集群操作,这里换新的kafka集群
编辑kafka的config/kraft目录下的server.properties文件
linux01服务器配置如下:
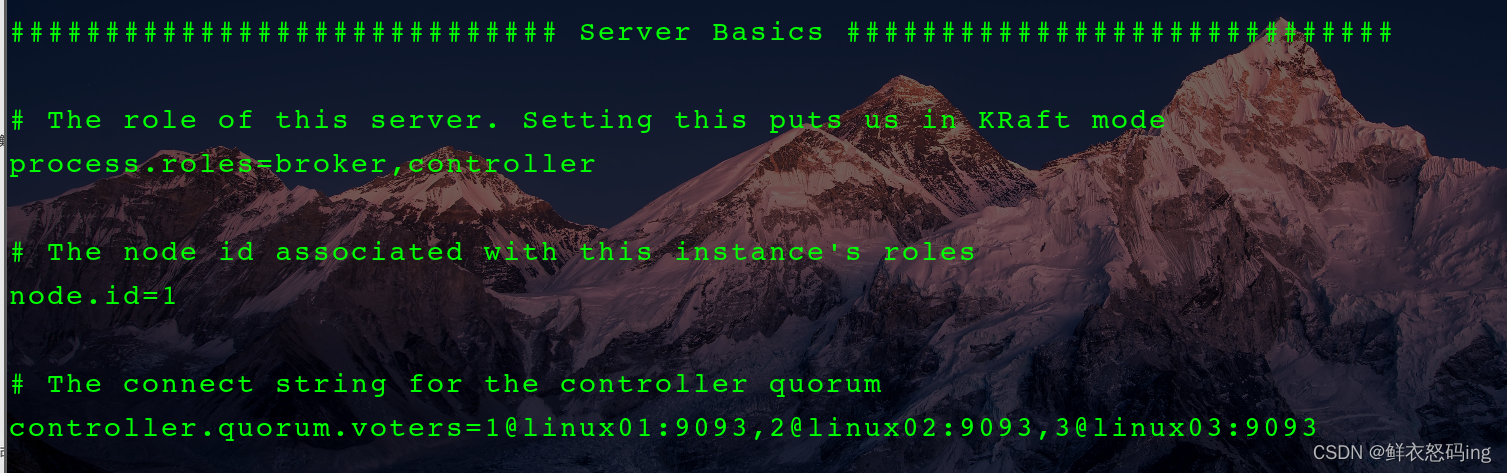


配好后分发该配置文件,并在各个服务器修改对应的参数,如node.id、advertised.listeners、log.dirs
启动前初始化集群
在linux01生成存储目录唯一ID

用该ID格式化所有服务器的kafka存储目录


启动kraft集群,这里使用自定义脚本,把脚本配置到环境变量,效果更佳
#!/bin/bash
case $1 in
"start"){
for i in linux01 linux02 linux03
do
echo --------$i 启动kraft---------
ssh $i "source /etc/profile;/export/server/kraft/bin/kafka-server-start.sh -daemon /export/server/kraft/config/kraft/server.properties"
done
};;
"stop"){
for i in linux01 linux02 linux03
do
echo --------$i 停止kraft---------
ssh $i "source /etc/profile;/export/server/kraft/bin/kafka-server-stop.sh stop"
done
};;
"status"){
for i in linux01 linux02 linux03
do
echo --------$i 查看kraft状态---------
ssh $i "source /etc/profile;jps -ml"
done
};;
esac
查看是否启动成功,这里也使用脚本一键查看集群所有jps,把脚本配置到环境变量,效果更佳
#!/bin/bash
for i in linux01 linux02 linux03
do
echo --------$i 查看jps---------
ssh $i "source /etc/profile; jps"
done
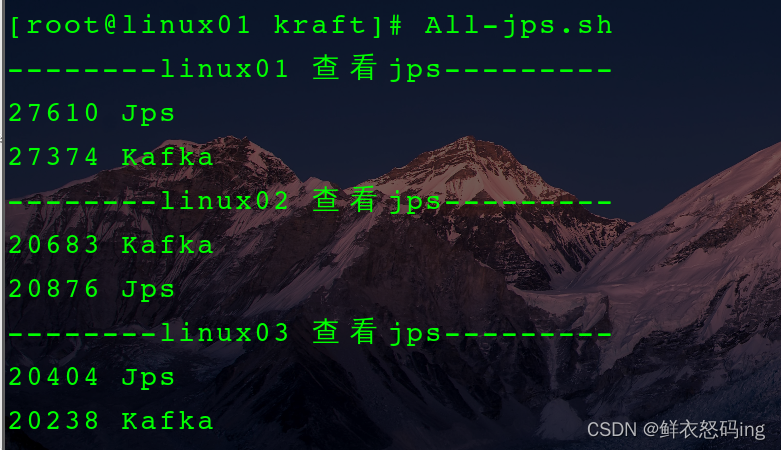
无需zk,启动成功!
浅浅把玩Kraft
创建主题first

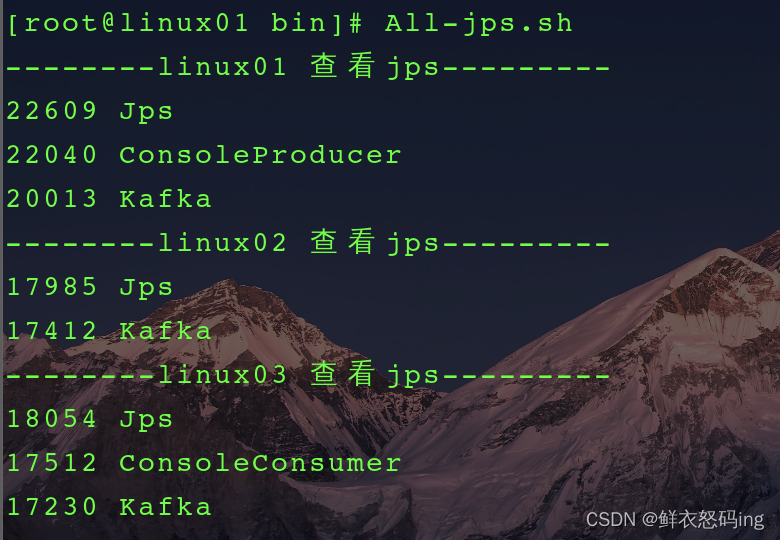
 在linux01创建生产者,在linux03创建消费者
在linux01创建生产者,在linux03创建消费者


Flume联动kafka
Flume作为生产者
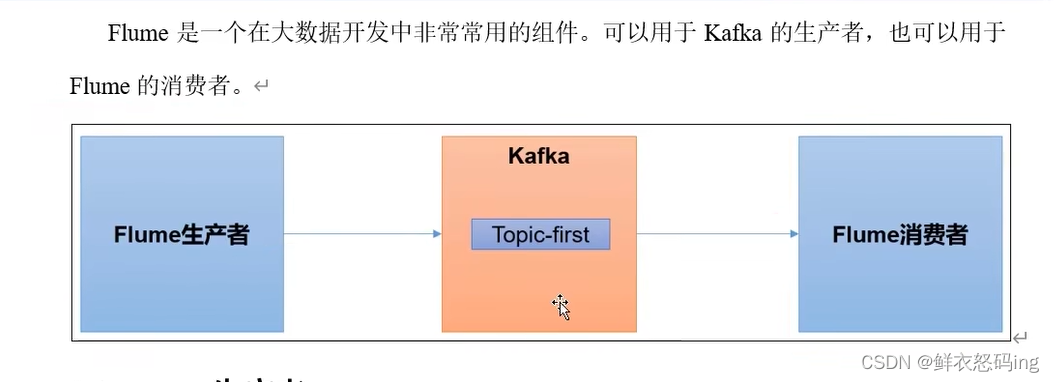
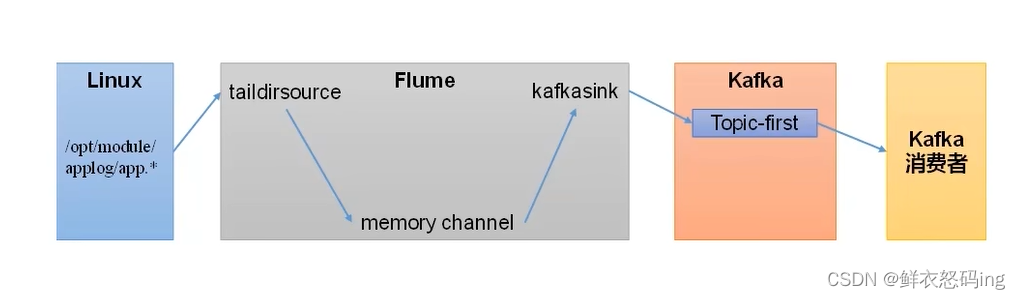
案例玩法:依次启动zk、kafka集群,在linux01编辑flume的file_to_kafka.conf任务配置,监控app.log文件内容,把监控的内容发送到kafka的first主题,然后启动flume任务作为生产者。在linux02启动kafka消费者,消费first主题,检查linux01的监控文件app.log变化时,消费者是否消费到了消息。
flume的job/group3/file_to_kafka.conf配置:
#定义source,sink,channel
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# 配置source
#
a3.sources.r3.type = TAILDIR
a3.sources.r3.filegroups=f3
#监控的目录
a3.sources.r3.filegroups.f3=/export/server/flume/job/group3/applog/app.*
#断点续传的json
a3.sources.r3.positionFile=/export/server/flume/job/group3/tail_dir2.json
# 配置 sink
a3.sinks.k3.type = org.apache.flume.sink.kafka.KafkaSink
a3.sinks.k3.kafka.bootstrap.servers=linux01:9092,linux02:9092,linux03:9092
a3.sinks.k3.kafka.topic=first
a3.sinks.k3.kafka.flumeBatchSize=20
a3.sinks.k3.kafka.producer.acks=1
a3.sinks.k3.kafka.producer.linger.ms=1
# 配置channel
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
确保zk,kafka集群已启动
- 在linux02创建kafka消费者,消费first主题
kafka-console-consumer.sh --bootstrap-server linux02:9092 --topic first- 在linux01启动flume任务
bin/flume-ng agent -c conf/ -n a3 -f job/group3/file_to_kafka.conf- 对监控的文件app.log追加内容,kafka消费者成功接收到消息


Flume作为消费者
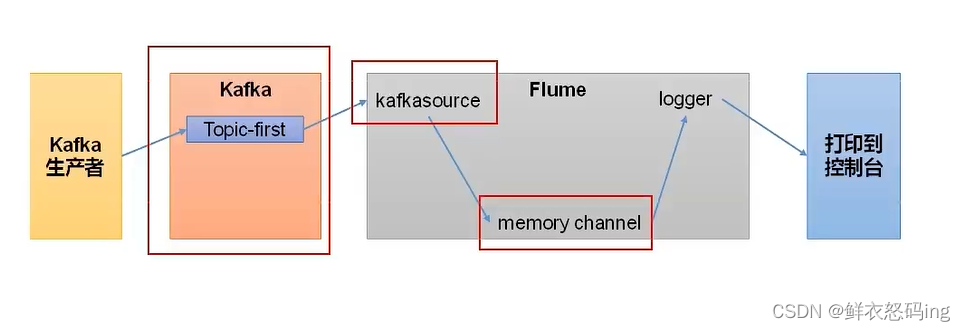
在linux01的flume的job目录下编辑kafka_to_file.conf文件,内容如下:
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r2.batchSize=50
a2.sources.r2.batchDurationMillis=200
a2.sources.r2.kafka.bootstrap.servers=linux02:9092
a2.sources.r2.kafka.topics=first
a2.sources.r2.kafka.consumer.group.id=custom.g.id
# Describe the sink
a2.sinks.k2.type = logger
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
依次启动zk、kafka集群,然后启动flume任务和kakfa生产者
- flume-ng agent -n a2 -c conf/ -f job/kafka_to_file.conf -Dflume.root.logger=INFO,console
- kafka-console-producer.sh --bootstrap-server linux03:9092 --topic first


案例成功!
SpringBoot联动kakfa
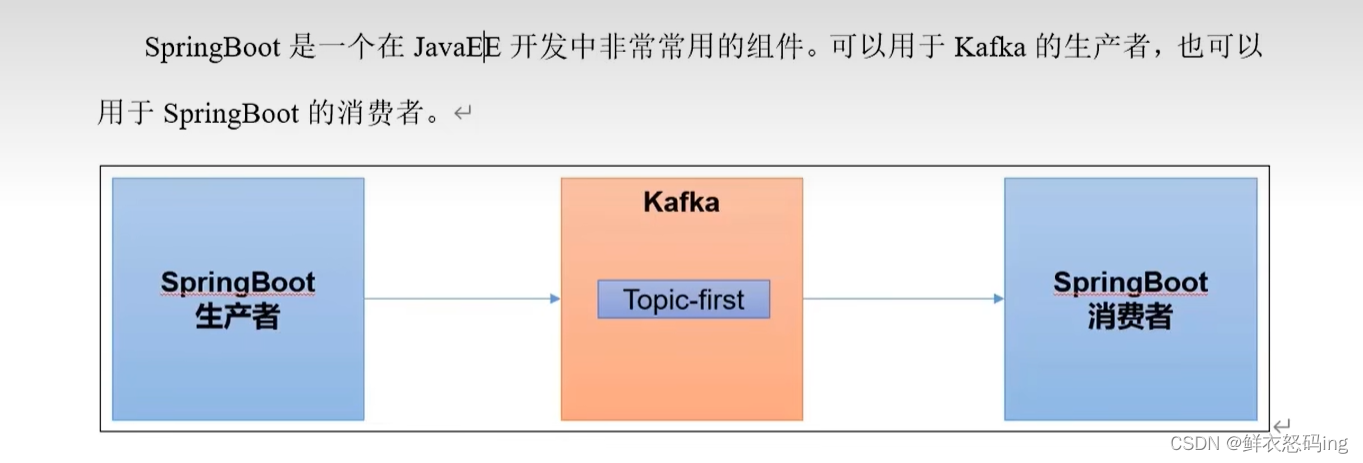
SpringBoot作为生产者
创建springboot工程
application.properties文件内容如下:
server.port=8080
#连接kafka集群
spring.kafka.bootstrap-servers=linux01:9092,linux02:9092,linux03:9092
#key-value序列化
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
pom文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.mykafka</groupId>
<artifactId>springboot_kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot_kafka</name>
<description>springboot_kafka</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>org.mykafka.springboot_kafka.SpringbootKafkaApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ProducerController代码
package org.mykafka.springboot_kafka;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author:懒大王Smile
* @Date: 2024/5/12
* @Time: 22:42
* @Description:
*/
@RestController
public class ProducerController {
@Autowired
KafkaTemplate<String,String> kafka;
@RequestMapping("/ProducerSend")
public String date(String msg){
kafka.send("first",msg);
System.out.println(msg);
return "ok";
}
}
项目展示
项目启动之后在浏览器访问,kafka消费者成功接收到数据!


SpringBoot作为消费者
application.properties文件内容如下:
server.port=8080
#key-value反序列化
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
#消费者组id
spring.kafka.consumer.group-id=mykafkaConsumerController代码如下:
package org.mykafka.springboot_kafka;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
/**
* @Author:懒大王Smile
* @Date: 2024/5/13
* @Time: 23:12
* @Description:
*/
@Configuration
public class ConsumerController {
@KafkaListener(topics = "first")
public void consumerTopic(String msg){
System.out.println("收到消息:"+msg);
}
}
Spark联动kafka
尚硅谷p73















 3303
3303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









