






这里选用了几个数据集,也用了经典的鸢尾花数据集,前面好像写过关于鸢尾花数据集的文章,机器学习案例——鸢尾花数据集分析,这一篇使用的是已经封装好的库,调用别人家的函数,还是显得云里雾里,所以这里选择自己实现。决策树定义
首先应该还是要来一点看起来那么高大上的句子来说明什么是决策树。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
举个例子,下面这段话就是用决策树预测,只不过这棵树在女儿心里已经早早的建好了。
女儿:多大年纪了?
母亲:26
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等收入。
女儿:是公务员吗?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
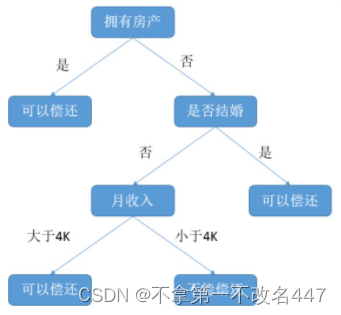
下面也是一个常见的决策树模型,预测一下能否偿还房贷,银行借钱也会先看看你能不能还的上才借给你吧。
决策树建立
我们要使用决策树做分类任务,首先第一步就是需要建立一个决策树吧,然后再用这棵决策树进行预测。步骤很简单,每一步选择一个特征,然后将数据集划分成两类。
现在问题来了,每一步应该选择什么样的特征进行划分呢?选择哪个特征才能比较好的划分数据集,如果没有一种方法来解决这个问题,那么就会发现,有的人画出来的决策树简介高效;而有的人画出来的决策树看起来很复杂,效果却很差。
所以下面要介绍一下信息熵和信息增益了。
信息熵&信息增益
我第一次接触熵这个概念是在高中化学课上,用熵来表示物质的混杂程度,熵越大说明物质越混乱,自然界的物质都是向熵增方向变化的,好像还可以利用熵来判断一个化学反应是否可以发生(如果说的不对,望指正)。
我第一次接触熵这个概念是在高中化学课上,用熵来表示物质的混杂程度,熵越大说明物质越混乱,自然界的物质都是向熵增方向变化的,好像还可以利用熵来判断一个化学反应是否可以发生(如果说的不对,望指正)。

其中 D 表示训练数据集,c 表示数据类别数,Pi 表示类别 i 样本数量占所有样本的比例。
信息增益就是在划分数据集前后信息发生的变化,也就是划分前后信息熵的差值。
决策树实例
这里选用了几个数据集,也用了经典的鸢尾花数据集,前面好像写过关于KNN鸢尾花数据集的文章,这一篇使用的是已经封装好的库,调用别人家的函数,还是显得云里雾里,所以这里选择自己实现。
下面是熵的计算函数,就是直接按上面介绍的公式去计算的。
def calc_entropy(data):
"""
计算数据集的香农熵
:param data: 数据集
:return:
"""
# 统计类别出现次数
label_count = {}
for iris in data:
cur_label = iris[-1]
if cur_label not in label_count.keys():
label_count[cur_label] = 1
label_count[cur_label] += 1
shannon_ent = 0.0
length = len(data)
for key in label_count:
prob = float(label_count[key]) / length
shannon_ent -= prob * math.log(prob, 2)
return shannon_ent构建决策树的过程如下所示,递归的划分数据集,直到决策树建立完成,这里存储为字典形式了。
def create_tree(data_set, labels):
"""
构建决策树
:param data_set: 数据集
:param labels: 特征集集
:return: 构建好的决策树
"""
# 如果数据只有一个类别,那就直接返回
class_list = [example[-1] for example in data_set]
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 如果数据只有1列,那么出现label次数最多的一类作为结果
if len(data_set[0]) == 1:
return major_cnt(class_list)
best_feat = choose_feat(data_set)
# 获取label的名称
best_feat_label = labels[best_feat]
des_tree = {best_feat_label: {}}
del (labels[best_feat])
feat_vals = [example[best_feat] for example in data_set]
unique_vals = set(feat_vals)
for value in unique_vals:
# 求出剩余的标签label
sub_labels = labels[:]
# 递归调用函数create_tree(),继续划分
des_tree[best_feat_label][value] = create_tree(split_data(data_set, best_feat, value), sub_labels)
return des_tree下面是使用自己造的数据构建的决策树,判断鱼类和非鱼类,总共只有两个特征,分别为:(1)不浮出水面是可以以生存;(2)是否有脚蹼,程序输出的决策树模型是这个样子的:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}上面的表现形式比较抽象,可以选择转化一下,把它变成人类最喜欢的图形样式,就像下面这样。
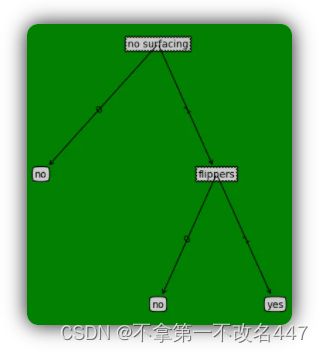
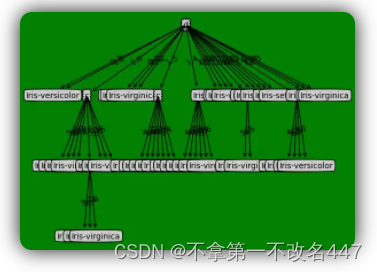
可以看到效果还是非常不错的,然后试了下鸢尾花数据集,发现得到的模型是下面这个样子的。
决策树剪枝
很明显,在鸢尾花数据集上表现的效果不是多好哈,然后就不得不涉及到决策树的剪枝操作了,这里就只做理论说明了。
决策树过拟合的风险很大,理论上是可以完全分开数据的,一个叶子节点就一个数据,不就分开了吗,但是这样的树,在训练集上面表现的效果很好,在测试集上面的表现却很差;而且这样的树又大又胖,泛化能力很弱。所以就要对决策树进行剪枝了。
一般有预剪枝和后剪枝,听名字就知道两种方式的时机了。说一下实用的预剪枝,可以通过限制叶子节点个数、树的深度、信息增益量等来实现,也不一定非要选择数据集的所有特征,选择一部分特征也是剪枝。
实际上在python中的sklearn库中都封装了常见机器学习算法,但是不懂原理就变成简单的函数调用了,所以前期还是自己写写吧,没有人家写的好,但是在写代码的过程中收获是最大的。
附源代码:decisionTreePlot.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : decisionTreePlot.py
# @Author: 刘绪光
# @Date : 2018/6/8
# @Desc :
import matplotlib.pyplot as plt
# 定义文本框 和 箭头格式 【 sawtooth 波浪方框, round4 矩形方框 , fc表示字体颜色的深浅 0.1~0.9 依次变浅,没错是变浅】
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
# 根节点开始遍历
for key in secondDict.keys():
# 判断子节点是否为dict, 不是+1
if type(secondDict[key]) is dict:
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
# 根节点开始遍历
for key in secondDict.keys():
# 判断子节点是不是dict, 求分枝的深度
if type(secondDict[key]) is dict:
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
# 记录最大的分支深度
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt,
textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
# 获取叶子节点的数量
numLeafs = getNumLeafs(myTree)
# 获取树的深度
# depth = getTreeDepth(myTree)
# 找出第1个中心点的位置,然后与 parentPt定点进行划线
# x坐标为 (numLeafs-1.)/plotTree.totalW/2+1./plotTree.totalW,化简如下
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
# print cntrPt
# 并打印输入对应的文字
plotMidText(cntrPt, parentPt, nodeTxt)
firstStr = list(myTree.keys())[0]
# 可视化Node分支点;第一次调用plotTree时,cntrPt与parentPt相同
plotNode(firstStr, cntrPt, parentPt, decisionNode)
# 根节点的值
secondDict = myTree[firstStr]
# y值 = 最高点-层数的高度[第二个节点位置];1.0相当于树的高度
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
# 判断该节点是否是Node节点
if type(secondDict[key]) is dict:
# 如果是就递归调用[recursion]
plotTree(secondDict[key], cntrPt, str(key))
else:
# 如果不是,就在原来节点一半的地方找到节点的坐标
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
# 可视化该节点位置
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
# 并打印输入对应的文字
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
# 创建一个figure的模版
fig = plt.figure(1, facecolor='green')
fig.clf()
axprops = dict(xticks=[], yticks=[])
# 表示创建一个1行,1列的图,createPlot.ax1 为第 1 个子图,
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
# 半个节点的长度;xOff表示当前plotTree未遍历到的最左的叶节点的左边一个叶节点的x坐标
# 所有叶节点中,最左的叶节点的x坐标是0.5/plotTree.totalW(因为totalW个叶节点在x轴方向是平均分布在[0, 1]区间上的)
# 因此,xOff的初始值应该是 0.5/plotTree.totalW-相邻两个叶节点的x轴方向距离
plotTree.xOff = -0.5 / plotTree.totalW
# 根节点的y坐标为1.0,树的最低点y坐标为0
plotTree.yOff = 1.0
# 第二个参数是根节点的坐标
plotTree(inTree, (0.5, 1.0), '')
plt.show()
# # 测试画图
# def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# # ticks for demo puropses
# createPlot.ax1 = plt.subplot(111, frameon=False)
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show()
# 测试数据集
def retrieveTree(i):
listOfTrees = [
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
# 用测试数据绘制树
# myTree = retrieveTree(1)
# createPlot(myTree)decision_tree.py
#!/usr/bin/python
# coding:utf-8
import operator
import math
import decisionTreePlot
def create_data():
"""
创造测试数据
:return: 测试数据
"""
data_set = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
label_set = ['no surfacing', 'flippers']
return data_set, label_set
def get_iris_data():
"""
读取鸢尾花数据
:return: 数据集和特征集
"""
fp = open('iris.csv', 'r', encoding='utf-8')
data_set = []
for line in fp:
data = line.strip().replace('\n', '').split(',')
data_set.append(data)
label_set = ['a', 'b', 'c', 'd']
return data_set, label_set
def get_lenses_data():
fp = open('lenses.csv', 'r', encoding='utf-8')
data_set = []
for line in fp:
data = line.strip().replace('\n', '').split(' ')
data_set.append(data)
label_set = ['age', 'prescript', 'astigmatic', 'tearRate']
return data_set, label_set
def calc_entropy(data):
"""
计算数据集的香农熵
:param data:
:return:
"""
# 统计类别出现次数
label_count = {}
for iris in data:
cur_label = iris[-1]
if cur_label not in label_count.keys():
label_count[cur_label] = 1
label_count[cur_label] += 1
shannon_ent = 0.0
length = len(data)
for key in label_count:
prob = float(label_count[key]) / length
shannon_ent -= prob * math.log(prob, 2)
return shannon_ent
def split_data(data, index, value):
"""
划分数据集
:param data: 待划分数据集
:return:
"""
ret_data_set = []
for feat in data:
if feat[index] == value:
reduced_feat = feat[:index]
reduced_feat.extend(feat[index + 1:])
ret_data_set.append(reduced_feat)
return ret_data_set
def choose_feat(data_set):
"""
选择最优划分特征
:param data: 数据集
:return: 最优特征的索引
"""
# 共有多少个特征,减一是因为最后一列为标签值
length = len(data_set[0]) - 1
base_ent = calc_entropy(data_set)
# 最优信息增益值、最优特征索引
best_info_gain, best_feat_index = 0.0, -1
# iterate over all the features
for i in range(length):
# 这里使用了list生成式
feat_list = [example[i] for example in data_set]
# 去重
unique_val_set = set(feat_list)
cur_entropy = 0.0
for value in unique_val_set:
sub_data = split_data(data_set, i, value)
prob = len(sub_data) / float(len(data_set))
cur_entropy += prob * calc_entropy(sub_data)
info_gain = base_ent - cur_entropy
if (info_gain > base_ent):
best_info_gain = info_gain
best_feat_index = i
return best_feat_index
def major_cnt(class_list):
"""
选择出现次数最多的结果
:param class_list:
:return:
"""
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def create_tree(data_set, labels):
"""
构建决策树
:param data_set: 数据集
:param labels: 特征集集
:return: 构建好的决策树
"""
# 如果数据只有一个类别,那就直接返回
class_list = [example[-1] for example in data_set]
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 如果数据只有1列,那么出现label次数最多的一类作为结果
if len(data_set[0]) == 1:
return major_cnt(class_list)
best_feat = choose_feat(data_set)
# 获取label的名称
best_feat_label = labels[best_feat]
des_tree = {best_feat_label: {}}
del (labels[best_feat])
feat_vals = [example[best_feat] for example in data_set]
unique_vals = set(feat_vals)
for value in unique_vals:
# 求出剩余的标签label
sub_labels = labels[:]
# 递归调用函数create_tree(),继续划分
des_tree[best_feat_label][value] = create_tree(split_data(data_set, best_feat, value), sub_labels)
return des_tree
def classify(tree, feat_labels, test):
"""
:param tree: 决策树
:param feat_labels: 特征集
:param test: 测试数据
:return: 预测结果
"""
first = list(tree.keys())[0]
# 通过key得到根节点对应的value
second_dict = tree[first]
feat_index = feat_labels.index(first)
key = test[feat_index]
val_of_feat = second_dict[key]
if isinstance(val_of_feat, dict):
res = classify(val_of_feat, feat_labels, test)
else:
res = val_of_feat
return res
def test():
# 1.创建数据和结果标签
data_set, labels = get_iris_data()
import copy
des_tree = create_tree(data_set, copy.deepcopy(labels))
print(des_tree)
# print(classify(des_tree, labels, [1, 0]))
decisionTreePlot.createPlot(des_tree)
if __name__ == "__main__":
test()
# get_lenses_data()数据集链接:machine-learning/decision_tree/iris.csv at master · Guanngxu/machine-learning · GitHub
machine-learning/decision_tree/lenses.csv at master · Guanngxu/machine-learning · GitHub
参考内容:
参考内容
决策树算法:https://github.com/apachecn/MachineLearning/blob/master/docs/3.决策树.md
决策树算法介绍及应用:https://www.ibm.com/developerworks/cn/analytics/library/ba-1507-decisiontree-algorithm/index.html















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









