







往期:
《Attention is all you Need》-transformer模型-CSDN博客----VIT的基础,建议大家先了解
论文原文:(不知道为什么一直绑定不上资源..)[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1、引言:为什么图像识别需要新的方法?
在深度学习领域,卷积神经网络(CNN)长期以来一直是计算机视觉(CV)任务的主力军。从 AlexNet 到 ResNet,CNN 的设计不断改进,使得模型在图像识别任务上表现越来越好。然而,CNN 在提取图像全局特征时仍存在一定局限性,主要依赖于卷积核的局部感受野。这就引出了一个问题:能否有一种方法像 NLP 中的 Transformer 一样,以全局视角理解图像?
答案就是 Vision Transformer (ViT)。Vision Transformer (ViT) 是首个在图像识别任务上超越传统卷积神经网络 (CNN) 性能的 Transformer 架构模型。
Transformer 模型自2017年提出以来,已经在自然语言处理(NLP)领域取得了革命性的进展。其核心机制——自注意力(Self-Attention)机制,使得模型能够处理序列数据中的长距离依赖问题。然而,Transformer 的应用并不局限于文本数据,而将其应用于视觉任务中最具代表性的就是 Vision Transformer(ViT)模型。
2、核心概念详解
2.1 预训练模型
预训练模型是指在大规模数据集上预先进行训练好的神经网络模型,通常在通用任务上学习到的特征可以被迁移到其他特定任务中。预训练模型的思想是利用大规模数据的信息来初始化模型参数,然后通过微调或迁移学习,将模型适应在特定的目标任务上。即在训练结束时结果比较好的一组权重值,研究人员分享出来供其他人使用。
“预训练模型” 可以理解为一个“已经学过一部分知识”的模型。举个例子,如果学习英语,先会通过一段时间学习基础的语法和词汇,这段时间就像是模型的“预训练”。然后,在这个基础上,你可能会学习更具体的内容,比如写作文、翻译等。这时,你可以用预训练的知识来加速你的学习过程。(在“GPT”中,P代表的是“Pre-trained”(预训练)的意思)
2. 2归纳偏差
归纳偏差(Inductive Bias)是指学习算法在学习过程中对数据的假设或偏好。它是一种先验知识,引导模型在面对有限的数据时,选择一种更可能正确的假设来进行学习和归纳。简单来说,就是模型在学习过程中存在的一种内在的倾向性,帮助模型从数据中学习到规律。
CNN 具有很强的归纳偏差。其中的平移等方差(Translation Invariance)是一种重要的归纳偏差。这意味着 CNN 假设图像中的物体无论在图像中的哪个位置出现,其特征表示应该是相似的。例如,在识别猫的图像时,猫在图像左上角和右下角应该有相似的特征表示被模型学习到。
局部性(Locality)也是 CNN 的归纳偏差。它假设图像的局部区域内的像素是相互关联的,并且物体的特征可以通过局部的像素组合来表示。比如,在识别物体的边缘时,CNN 可以通过卷积核扫描局部像素区域来捕捉边缘信息,而不是同时考虑整个图像的所有像素。

Transformer 主要基于自注意力机制(Self - Attention),它没有像 CNN 那样的平移等方差和局部性的归纳偏差。Transformer 在处理序列数据(如自然语言处理中的句子)时,会计算序列中每个元素与其他所有元素的关联程度,数据量少的时候可能效果不是很好。VIT模型中同样也没有用太多的归纳偏置,模型从0开始学,所以当数据集太小,效果可能不如cnn。
论文中提到大规模训练胜过归纳偏差,ViT 的成功在很大程度上归功于大规模训练。

2.3 自监督学习在 NLP 中的应用(BERT、GPT)
自监督学习通过设计伪标签任务(如遮挡恢复、图像旋转预测等)来帮助模型在无监督环境下学习有效的特征表达。这种方法可以显著减少对标注数据的依赖,提高模型的泛化能力。

BERT 采用了一种去噪(“去噪”指的是模型需要从部分被遮蔽的输入中恢复出原始信息)自监督预训练任务,通过对句子中的随机单词进行掩码,并训练模型根据周围上下文预测掩码单词。
GPT 则把语言建模作为其预训练任务,根据给定的前文内容预测下一个单词。语言建模简单来讲就是根据给定的前文内容,预测下一个单词是什么,是一种生成式自回归模型,专注于序列的生成过程,它的核心是基于已有的序列元素来预测下一个元素,并且这种预测是按照序列的顺序依次进行的。

3、ViT 模型架构
ViT 模型由 Dosovitskiy 等人在2021年提出,其主要思想是将图像分割成多个小块(patches),然后将这些小块作为序列输入到 Transformer 模型中进行处理。
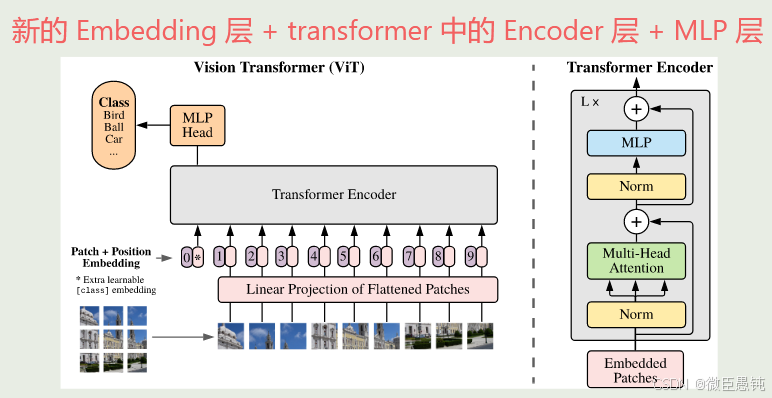
1️⃣图像分块 (Patch Embedding)
首先将图像分割成固定大小的块(patches),例如 16x16 像素。每个块被展平成一个向量,并通过一个可训练的线性投影层(全连接层)转换为维度为 768 的向量,这个过程称为 patch embedding。这样做的目的是为了将图像数据转换为 Transformer 能够处理的序列形式。

至此已经把一个Vision的问题变成了NLP问题,输入变成了1d的token而非2d的图
2️⃣类别标记(Class Token)
在Transformer模型中,输入序列通常包括一系列的token。ViT算法提出了一个可学习的嵌入向量Class Token,将它与图像块一起输入到Transformer结构中,输出的编码向量中,根据Class Token进行分类预测,做最后的输出。
与特殊字符cls token(通过学习得到,维度为[1*768])拼接contat,最终进入transformr的为197*768

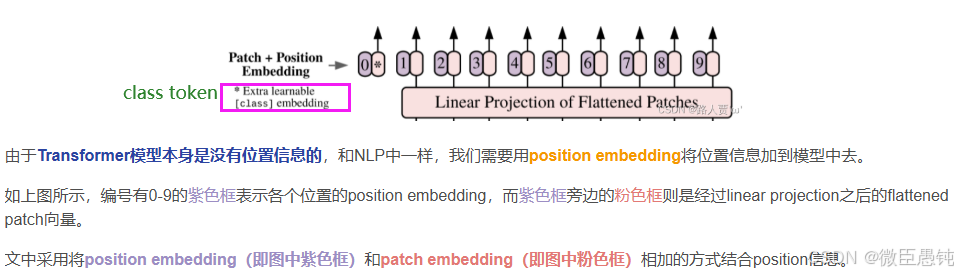
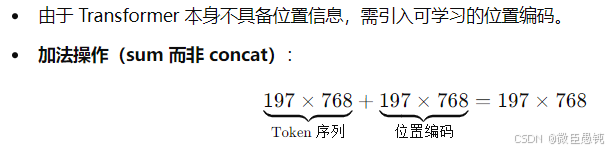
3️⃣位置嵌入(Position Embeddings)
why position embeddings: ViT 将图像划分成一系列的图像块(patches),这些图像块的序列就如同自然语言处理中句子里的单词序列一样,需要位置信息来让模型理解它们的顺序。
how: 位置嵌入向量的维度与 patch embedding 相同。与 Transformer 早期版本中通过正弦和余弦函数生成位置嵌入不同,ViT 的位置嵌入是作为模型的可学习参数存在的,可以学习到最适合数据的位置信息表示 。
4️⃣ Transformer Encoder 模块

5️⃣ MLP (前馈全连接层)
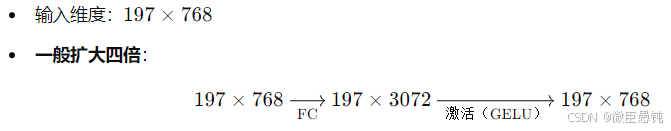
Transformer 模块堆叠多层后,最终取 [CLS] Token 对应的向量,输入至分类头 (MLP Head) 进行分类或其他任务。

6️⃣公式:

4、VIT微调的局限性:

5、总结 💡
- 图像→序列:通过分块与展平,将二维图像转为一维序列 token。
- 自注意力机制:让每个图像块与其他块建立全局依赖关系。
- 位置编码:补充 Transformer 缺乏的位置感知能力。
- [CLS] Token:为整个图像提供全局表征。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









