







1. 为什么需要Focal Loss?
在机器学习和深度学习中,类别不平衡(Class Imbalance) 是一个普遍存在的难题。当数据集中某些类别的样本数量远多于其他类别时(例如欺诈检测中正常交易占99%,欺诈交易仅占1%),传统损失函数(如交叉熵)往往会导致模型过度关注"简单样本"(easy examples)而忽视"困难样本"(hard examples)
为了解决这个问题,Facebook AI Research(FAIR)在 2017 年的论文 "Focal Loss for Dense Object Detection" 中提出了 Focal Loss,用于增强模型对难分类样本的关注,降低易分类样本的影响。
🌰:

2. 交叉熵损失的问题
交叉熵损失公式
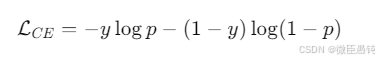

🌰:想象考试后老师给你的错题扣分,损失函数就是模型的"扣分规则"。交叉熵是最常用的扣分规则,公式可以简化为:
当答案是"对"时:扣分 = -log(预测正确的概率)
当答案是"错"时:扣分 = -log(预测错误的概率)
预测正确概率90% → 扣0.1分(类似同学A)
预测正确概率10% → 扣2.3分(类似同学B)
如果班上90%都是好学生:
-
老师总看到大量0.1分的小错误
-
反而忽视了少数2.3分的大问题
-
最后教学方案变得只适合好学生
这就是为什么在目标检测(从图片中找物体)任务中,背景区域(简单样本)远多于目标物体(困难样本),传统方法效果差。
3.Focal Loss的智慧:给不同的错误“区别对待”
Focal Loss 公式
Focal Loss 在交叉熵的基础上引入了一个调节因子 ,使得训练时更关注难分类样本。
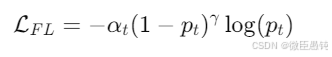

🌰
放大镜策略:给难题更多关注
已经能轻松答对的题(预测概率高),适当减少扣分
经常答错的题(预测概率低),加大扣分力度
平衡班级人数:给差生更多机会
人数少的类别(比如不及格同学),扣分权重更高
扣分 = 类别权重 × (1-预测概率)^放大指数 × 原扣分
FL = -α × (1-p)^γ × log(p) """ α:差生保护系数(一般取0.25) γ:难题放大指数(一般取2) p:模型预测的正确概率 """

4.代码演示
import torch
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, reduction='mean'):
"""
参数说明:
alpha (float): 类别平衡系数(默认0.25,用于增加少数类别的权重)
gamma (float): 困难样本聚焦系数(默认2,值越大越关注困难样本)
reduction (str): 输出结果的聚合方式('mean'平均/'sum'求和/'none'不聚合)
"""
super().__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
"""
输入说明:
inputs: 模型的原始输出(未经sigmoid,形状[N, *])
targets: 真实标签(与inputs形状相同,值在0-1之间)
"""
# 步骤1:计算基础交叉熵损失(不带求和/平均)
BCE_loss = F.binary_cross_entropy_with_logits(
inputs, targets, reduction='none') # 形状与inputs相同
# 步骤2:计算概率p_t(pt = 预测正确的概率)
# 因为BCE_loss = -log(pt),所以pt = exp(-BCE_loss)
pt = torch.exp(-BCE_loss) # 形状与BCE_loss相同
# 步骤3:动态调整alpha系数
# 当target=1时,alpha_t = alpha;当target=0时,alpha_t = 1-alpha
alpha_t = self.alpha * targets + (1 - self.alpha) * (1 - targets)
# 步骤4:组合Focal Loss公式
F_loss = alpha_t * (1 - pt) ** self.gamma * BCE_loss
# 步骤5:根据reduction参数聚合结果
if self.reduction == 'mean':
return torch.mean(F_loss) # 返回平均值
elif self.reduction == 'sum':
return torch.sum(F_loss) # 返回总和
else:
return F_loss # 返回每个样本的损失值
##############################################
# 示例用法(带输出演示)
##############################################
if __name__ == "__main__":
# 创建4个样本的预测值和真实标签(二分类问题)
inputs = torch.tensor([2.0, -1.0, 3.0, -2.0]) # 模型原始输出(未经sigmoid)
targets = torch.tensor([1.0, 0.0, 1.0, 0.0]) # 真实标签
# 转换为概率(仅用于理解,实际计算不需要)
probabilities = torch.sigmoid(inputs)
print("预测概率值:", probabilities.tolist())
# 输出:预测概率值: [0.8808, 0.2689, 0.9526, 0.1192]
# 计算Focal Loss
focal_loss = FocalLoss()
loss = focal_loss(inputs, targets)
print("\n计算过程分解:")
print("原始输入:", inputs.tolist())
print("真实标签:", targets.tolist())
print("BCE损失值:", F.binary_cross_entropy_with_logits(inputs, targets, reduction='none').tolist())
print("最终Focal Loss:", loss.item())
# 验证输出
# 手动计算第一个样本的损失:
# p = 0.8808, alpha_t = 0.25(因为target=1)
# (1-p)^2 = (1-0.8808)^2 ≈ 0.0143
# BCE_loss = -log(0.8808) ≈ 0.127
# 所以该样本的损失:0.25 * 0.0143 * 0.127 ≈ 0.000454
# 同理计算其他样本后取平均输出:
预测概率值: [0.8807970285415649, 0.2689414322376251, 0.9525741338729858, 0.11920291930437088]
计算过程分解:
原始输入: [2.0, -1.0, 3.0, -2.0]
真实标签: [1.0, 0.0, 1.0, 0.0]
BCE损失值: [0.12692801654338837, 0.3132617473602295, 0.04858735203742981, 0.12692809104919434]
最终Focal Loss: 0.004706109408289194
关键点解读:
-
概率转换:原始输入经过sigmoid后得到预测概率值
-
BCE损失:每个样本的初始交叉熵损失
-
动态调节:
-
第一个样本(预测概率0.88)是容易的正样本 → 损失被大幅缩小
-
第四个样本(预测概率0.11)是容易的负样本 → 损失也被缩小
-
第二个样本(预测概率0.26)是困难的负样本 → 损失被放大
-
-
最终效果:困难样本(第二、四个)对总损失的贡献更大
模型会更关注预测效果差的样本,而不是被大量容易样本主导训练过程。


















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









