






目录
一.决策树介绍
决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结节点:通常用三角形来表示
决策树是一树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下,分而治之的过程。
二.数学基础
1.信息熵
(1)基本定义
假设样本集合D共有N类,第k类样本所占比例为,则D的信息熵为:
信息熵描述的是事件在结果出来之前对可能产生的信息量的期望,描述的是不确定性。
信息熵越大,不确定性越大。H(D)的值越小,则D的纯度越高。
注:
(1)计算信息熵时约定 : 如果 p = 0,则 = 0
(2)Ent(D)的最小值是0,最大值是
(2)条件熵
(3)有关定律
🌳
🌳若X,Y相互独立,
🌳H(Y|Y)=0
2、信息增益
信息增益是一个统计量,用来描述一个属性区分数据样本的能力。信息增益越大,那么决策树就会越简洁。这里信息增益的程度用信息熵的变化程度来衡量。公式如下:
三.典型的决策树算法
ID3算法:ID3(Iterative Dichotomiser 3)算法是决策树算法中最早的一种,使用信息增益来选择最优特征。ID3算法基于贪心思想,一直选择当前最优的特征进行分割,直到数据集分割完成或没有特征可分割为止。
C4.5算法:C4.5算法是ID3算法的改进版,使用信息增益比来选择最优特征。C4.5算法对ID3算法中存在的问题进行了优化,包括处理缺失值、处理连续值等。
CART算法:CART(Classification and Regression Trees)算法是一种基于基尼不纯度的二叉树结构分类算法,用于解决二分类和回归问题。CART算法可以处理连续值和离散值的特征,能够生成二叉树结构,具有较好的可解释性。
CHAID算法:CHAID(Chi-square Automatic Interaction Detection)算法是一种基于卡方检验的决策树算法,用于处理分类问题。CHAID算法能够处理多分类问题,不需要预先对特征进行处理。
MARS算法:MARS(Multivariate Adaptive Regression Splines)算法是一种基于样条插值的决策树算法,用于回归问题。MARS算法能够处理连续值和离散值的特征,能够生成非二叉树结构,具有较好的拟合能力。
分类决策树可用于处理离散型数据,回归决策树可用于处理连续型数据。最常见的决策树算法包含ID3算法、C4.5算法以及CART算法。
四.剪枝
1、提出原因
决策树分支可能过多,以致于把训练集自身的一些特征当作所有数据都具有的一般性质而导致过拟合。决策树越复杂,过拟合的程度会越高。因此我们主动去掉一些分支来降低过拟合的风险。
2、剪枝与其处理基本策略
(1)剪枝:剪枝是指将一颗子树的子节点全部删掉,根节点作为叶子节点。
(2)基本策略:预剪枝和后剪枝
3、预剪枝
(1)做法
在决策树生成的过程中,每个决策节点原本是按照信息增益、信息增益率或者基尼指数等纯度指标,按照值越大,优先级越高来排布节点。由于预剪枝操作,所以对每个节点在划分之前要对节点进行是否剪枝判断,即:使用验证集按照该节点的划分规则得出结果。若验证集精度提升,则不进行裁剪,划分得以确定;若验证集精度不变或者下降,则进行裁剪,并将当前节点标记为叶子节点。
(2)优缺点
🎈优点:预剪枝使得决策树很多相关性不大的分支都没有展开,这不仅仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。
🎈缺点:有些分支的当前划分虽不能提升泛化能力,甚至可能导致泛化能力暂时下降,但是在其基础上进行的后续划分却有可能提高性能。预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
4、后剪枝
(1)做法
已经通过训练集生成一颗决策树,然后自底向上地对决策节点(非叶子结点)用测试集进行考察,若将该节点对应的子树替换为叶子节点能提升验证集的精确度(这个的算法与预剪枝类似),则将该子树替换成叶子节点,该决策树泛化能力提升。
(2)优缺点
🎈优点:后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化能力往往优于预剪枝决策树。
🎈缺点:后剪枝过程是在生成完决策树之后进行的,并且要自底向上地对树中的所有决策节点进行逐一考察,因此其训练时间开销比未剪枝的决策树和预剪枝决策树都要大得多。
五.python实现
1.导入库和数据集。
2.数据处理,提取属性特征和分类标签。

3.将测试集与训练集分类。

4.建立模型对象,tree.DecisionTreeClassifier()函数中,将criterion置为'entropy',表示用信息熵来计算不纯度,max_depth设置为3,表示在建立决策树时,进行预剪枝,将最大深度限制为3。

5.用训练集训练模型,使用接口为fit。
 6.导入测试集,用clf.predict()得到预测结果,用score得到预测模型的得分。
6.导入测试集,用clf.predict()得到预测结果,用score得到预测模型的得分。

7.最后输出准确度,并生成决策树可视化的dot文件
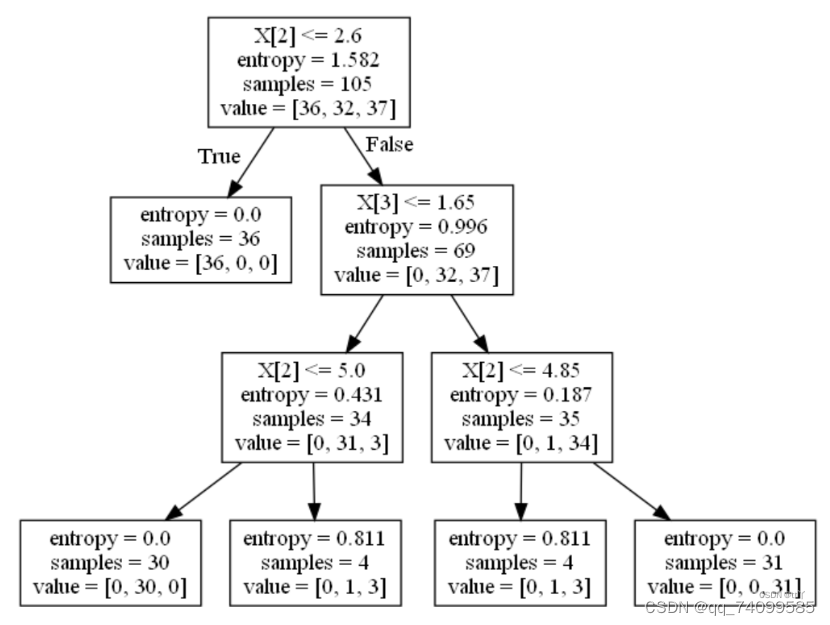
总代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
iris = load_iris()#数据集导入
features = iris.data#属性特征
labels = iris.target#分类标签
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.3, random_state=1)#训练集,测试集分类
clf = tree.DecisionTreeClassifier(criterion='entropy',max_depth=3)
clf = clf.fit(train_features, train_labels)#X,Y分别是属性特征和分类label
test_labels_predict = clf.predict(test_features)# 预测测试集的标签
score = accuracy_score(test_labels, test_labels_predict)# 将预测后的结果与实际结果进行对比
print("CART分类树的准确率 %.4lf" % score)# 输出结果
dot_data = tree.export_graphviz(clf, out_file='iris_tree.dot')#生成决策树可视化的dot文件六.问题与解决办法
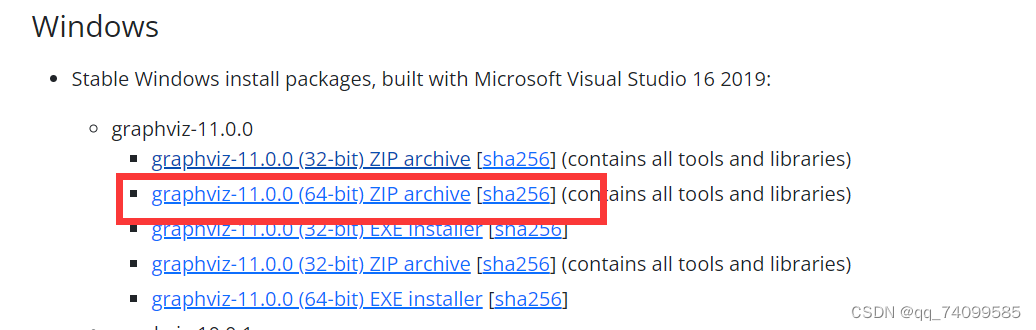
1.打不开dot文件。
解决方法:下载Graphviz,点击Graphviz
下载之后解压缩
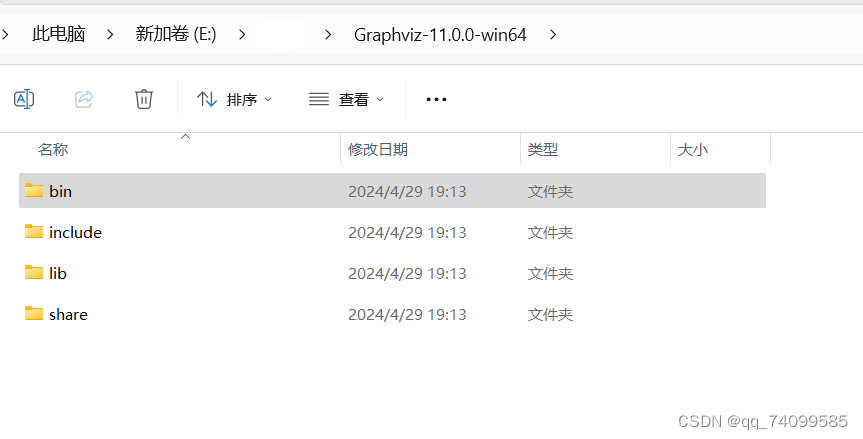
将路径到bin为止,添加到环境变量的path中
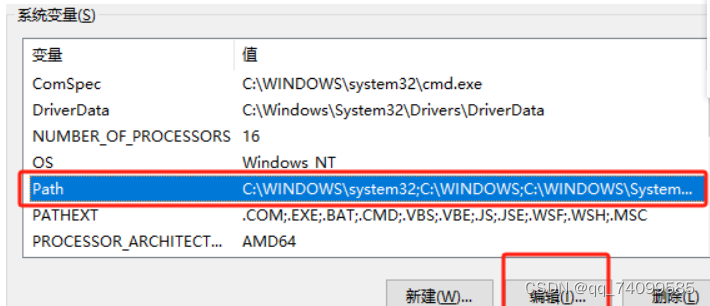
之后就可以顺利打开dot文件了。















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









