







目录
5.3误差逆传播算法(Back-Propagation,简称BP算法),
第五章. 神经网络
5.1 神经元模型
-
神经网络的定义:神经网络是由简单单元(神经元)组成的互连网络,可以模拟生物神经系统对现实世界的反应。在机器学习中,神经网络学习是机器学习和神经网络交叉的领域。
-
神经元模型:神经网络的基本组成部分是神经元模型。生物神经元通过电信号和化学物质传递信息,如果电位超过某个阈值,神经元就会被激活,向其他神经元发送信号。
-
历史背景:1943年,McCulloch和Pitts提出了M-P神经元模型,这是一个简单的数学模型,用来描述神经元的输入输出关系,这个模型至今仍然被广泛使用。
#6机器学习(西瓜书)自学记录
-
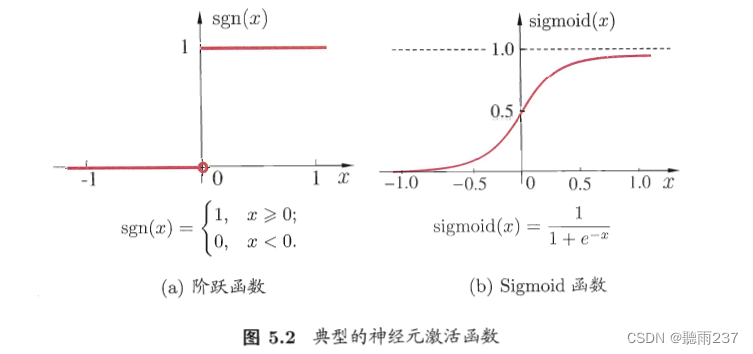
激活函数:
-
理想——阶跃函数
-
实际——sigmoid函数
-
作用:神经网络是为包含了许多参数的数学模型,这些模型就是若干个函数。

5.2感知机与多层网络
-
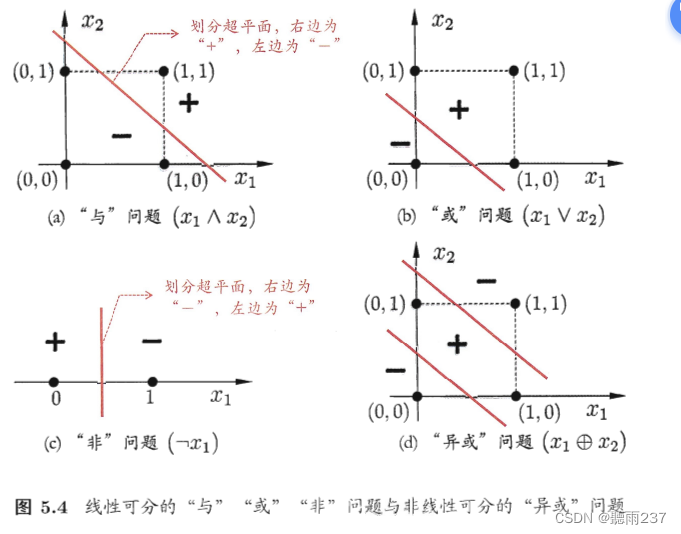
感知机定义:由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称“阈值逻辑单元”。
-
作用:实现逻辑与,或,非运算。
-
要素组成:
-
输入层:接收输入信号的层。每个输入被赋予一个权重,用来衡量其对模型的重要性。
-
加权和:输入信号与相应权重相乘后求和的过程,用来得到加权输入。
-
激活函数:加权和之后的结果通常会经过一个激活函数,用来引入非线性特性。典型的激活函数包括阶跃函数(Step Function)或Sigmoid函数。
-
输出层:激活函数的输出作为最终的输出结果。
-
-
工作原理:
-
初始化:权重通常会初始化为随机值。
-
前向传播:输入信号经过加权和和激活函数的处理后,得到输出结果。
-
误差计算:将实际输出与期望输出进行比较,计算误差。
-
反向传播:根据误差,调整权重以减小误差。这通常使用梯度下降等优化算法完成。
-
迭代:重复以上过程直至满足停止条件,如达到最大迭代次数或误差低于某个阈值。
-
-
局限性:
-
线性可分性:感知机只能解决线性可分问题,即无法处理非线性关系。
-
单层结构:感知机是单层结构,无法表示复杂的模式和特征。

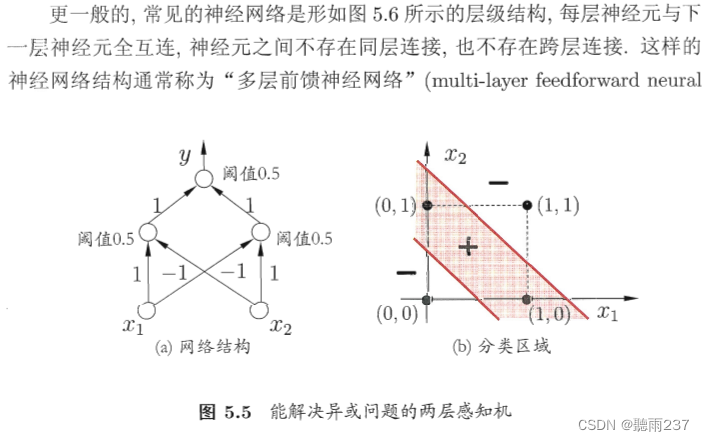
5.2.1图像解释
图5.6展示了多层前馈神经网络的结构,其中包括输入层、一个或多个隐藏层和输出层。输入层接收外部信号,隐藏层对信号进行处理,输出层给出最终结果。神经网络的学习过程包括调整连接权重和阈值,以使网络输出尽可能接近目标值。
-
多层前馈神经网络结构:
-
输入层:接收外部输入信号。
-
隐藏层:对输入信号进行处理和转换,可能有多个隐藏层。
-
输出层:输出最终的处理结果。
-
-
信号传导:
-
信号从输入层传导到隐藏层,再传导到输出层。
-
每一层的神经元只与下一层的神经元相连,不进行反馈。
-
-
学习过程:
-
通过调整连接权重和阈值,使网络输出尽可能接近目标值。
-
这种调整过程称为“连接权重”的学习。
-
-
单层与多层网络的区别:
-
单层网络只有输入层和输出层,没有隐藏层。
-
多层网络包含一个或多个隐藏层,能够处理更复杂的任务。
-
-
图5.6的两种表示:
-
左图表示单层网络。
-
右图表示多层网络。
-
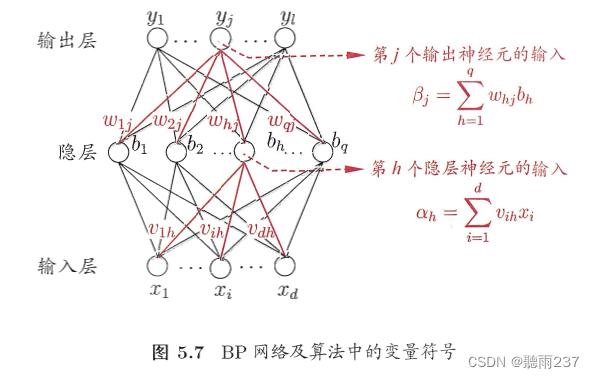
5.3误差逆传播算法(Back-Propagation,简称BP算法),
定义:这是多层前馈神经网络中最重要的学习算法。BP算法通过调整网络的连接权重和阈值,使网络输出尽可能接近目标值。该算法不仅适用于多层前馈神经网络,还可以用于其他类型的网络。BP算法的核心思想是通过计算输出误差并将其反向传播到各层,从而调整各层的权重和阈值。
-
多层网络的学习能力:
-
多层网络比单层感知机具有更强的学习能力。
-
训练多层网络需要更复杂的学习算法,BP算法是其中最重要的一种。
-
-
误差逆传播算法(BP算法):
-
BP算法通过计算输出误差,并将误差反向传播到各层,从而调整各层的权重和阈值。
-
该算法的目标是使网络输出尽可能接近目标值。
-
-
BP算法的应用:
-
BP算法不仅适用于多层前馈神经网络,还可以用于其他类型的网络。
-
该算法在实际应用中非常广泛,被认为是神经网络学习的基础算法。
-
-
BP算法的提出:
-
BP算法最早由Pineda在1987年提出,并在后续研究中得到了广泛应用和改进。
-
-
BP算法的步骤:
-
给定训练样本集$D = {(x_1, d_1), (x_2, d_2), \ldots, (x_p, d_p)}$,其中$x_i$是输入向量,$d_i$是目标输出向量。
-
通过前向传播计算网络的实际输出。
-
计算输出误差,并将误差反向传播到各层,调整各层的权重和阈值。
-
重复上述过程,直到网络输出误差达到预定的阈值或达到最大迭代次数。
-

5.3.1公式推导
误差逆传播算法(Back-Propagation,简称BP算法)是基于梯度下降的策略进行权重和阈值的更新,以最小化神经网络的输出误差。下面是BP算法的公式推导过程:
假设有一个多层前馈神经网络,包含输入层、隐藏层和输出层。网络的总误差可以定义为输出层的误差之和,即:
E=21∑k(d**k−o**k)2
其中,$d_k$是样本的目标输出值,$o_k$是网络输出层的实际输出值。输出层的误差可以表示为:
δ**k=d**k−o**k
隐藏层和输出层之间的权重调整可以通过梯度下降来实现,即在权重空间中沿着误差函数下降的方向更新权重。假设网络中的权重为$w{ji}$,误差函数对$w{ji}$的梯度可以表示为:
∂w**ji∂E=−δ**j⋅o**i
其中,δ**j是隐藏层的误差,可以通过反向传播计算得到。进行权重更新时,根据梯度的方向调整权重的大小,更新公式为:
w**ji(new)=w**ji(old)−η∂w**ji∂E
其中,η是学习率,控制权重更新的步长。通过反复迭代计算梯度并更新权重,可以最小化网络的输出误差,实现模型的训练。
总结起来,BP算法通过梯度下降的方式,利用输出误差和反向传播计算的隐藏层误差,更新多层神经网络中各层之间的连接权重和阈值,以达到最小化输出误差的目标。
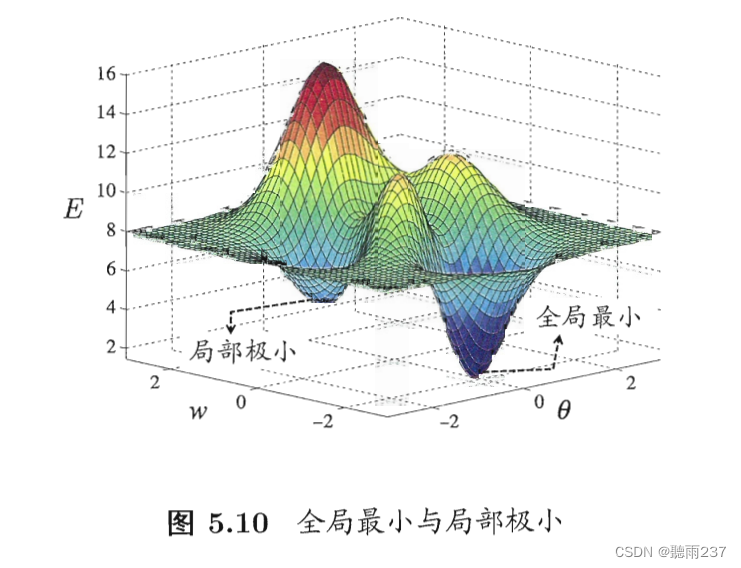
5.4全局最优与局部最优

5.4.1全局最优(Global Optimum):
全局最优指的是在整个搜索空间中找到的能够使目标函数取得最小值或最大值的解决方案。形式化地说,对于一个目标函数 f(x)f(x)f(x),全局最优解 x∗x^*x∗ 满足以下条件:
f(x∗)≤f(x)for all x in the search space
在合适的定义下,全局最优解通常是唯一的,尤其是在凸优化问题中。
5.4.2局部最优(Local Optimum):
局部最优指的是在搜索空间中找到的能够使目标函数在某个局部范围内取得最小值或最大值的解决方案。形式化地说,对于一个目标函数 f(x)f(x)f(x),局部最优解 x∗x^*x∗ 满足以下条件:
f(x∗)≤f(x)for all x in a neighborhood of x∗
局部最优解可能存在于目标函数的不同局部区域,而这些局部最优解之间的性能可能是不同的。
5.4.3全局最优与局部最优的关系:
全局最优解是整个搜索空间中性能最优的解决方案,而局部最优解是在某个局部范围内性能最优的解决方案。在许多优化问题中,寻找全局最优解可能是非常困难的,因为搜索空间可能非常大,并且目标函数可能具有复杂的结构,包括多个局部极小值点和鞍点。相比之下,局部最优解可能相对容易找到,但它们通常无法保证是全局最优解。因此,优化算法的设计旨在尽可能接近全局最优解,同时避免陷入局部最优解。
此内容是本人第一次通过看书和相关视频学习周志华《机器学习》,在此发表的一些个人的看法与见解,如有错误在里面必然是本人见识低陋,望读者朋友务必指出,我好加紧改正。本内容仅仅是本人学习的记录。想要深入了解《机器学习》的朋友务必下去看看书。谢谢。
参考说明:
相关截图:来自b站 周志华老师亲讲-西瓜书全网最详尽讲解-1080p高清原版《机器学习初步》BV1gG411f7zX
【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集 BV1Mh411e7VU















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









