







一、YARN的产生背景与核心价值
在Hadoop 1.x时代,MapReduce框架存在显著的架构瓶颈:JobTracker承担资源管理和任务调度的双重职责,导致单点故障风险高、扩展性受限,且仅支持单一计算模型。YARN(Yet Another Resource Negotiator)的诞生正是为了解决这些问题,其核心思想将资源管理与作业调度解耦,形成通用资源管理系统,支持多计算框架共存。
这种架构革新带来了三大突破性价值:
- 资源利用率提升:动态分配CPU/内存/带宽,替代静态槽位分配
- 计算框架扩展性:支持Spark、Flink、Storm等异构框架
- 系统高可用性:通过组件分布式部署规避单点故障
二、YARN架构组件深度解析
2.1 核心四层架构模型
![YARN架构示意图]
(示意图展示ResourceManager、NodeManager、ApplicationMaster与Container的交互关系)
2.1.1 ResourceManager(RM)
作为集群资源总控中心,RM通过三级调度策略实现资源管理:
- 资源收集:接收NodeManager周期性心跳上报
- 资源分配:基于Capacity/Fair调度算法分配Container
- 状态监控:跟踪ApplicationMaster生命周期
关键技术特性:
- 支持资源抢占(Preemption)应对高优先级任务
- 通过ZK实现Active/Standby高可用部署
2.1.2 NodeManager(NM)
作为节点代理,NM实现物理资源到逻辑容器的转换:
# 典型资源监控指标输出示例
NodeManager Metrics:
- Memory: 32GB Total / 8GB Used
- vCores: 16 Total / 4 Used
- Running Containers: 2
关键功能包括:
- 容器隔离(Cgroups/Docker支持)
- 本地化文件缓存管理
- 异常容器自动回收
2.1.3 ApplicationMaster(AM)
作为应用级调度器,AM实现框架特异性调度逻辑。以MapReduce为例:
// AM资源请求伪代码
List<ResourceRequest> requests = new ArrayList<>();
requests.add(ResourceRequest.newInstance(
Priority.newInstance(1),
"hadoop-node*",
Resource.newInstance(4096, 4),
10)); // 申请10个4核4G容器
AM的核心职责包含:
- 动态调整资源需求
- Task容错与推测执行
- 数据本地化优化
2.1.4 Container
作为资源抽象单元,Container规格示例:
| 资源类型 | 最小单位 | 最大限制 |
|---|---|---|
| 内存 | 512MB | 16GB |
| vCores | 1 | 8 |
| GPU | 0 | 2 |
支持资源超额订阅(Over-Subscription)策略提升利用率
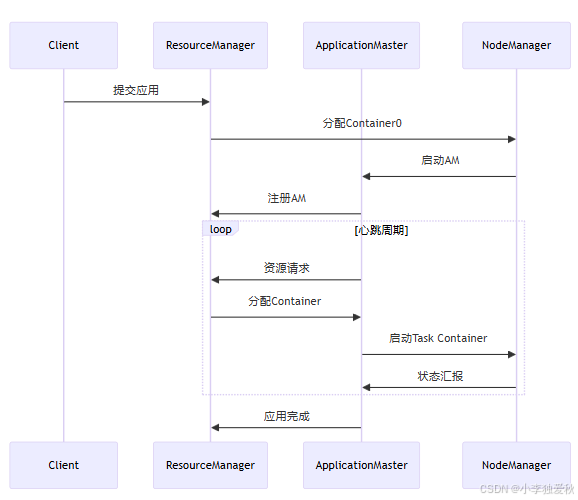
2.2 YARN工作流程
- 应用提交:Client提交AppContext到RM
- AM启动:RM分配Container0启动AM
- 资源协商:AM通过心跳机制申请资源
- 任务执行:AM与NM协作启动Task Container
- 状态监控:RM收集各组件心跳构建全局视图
三、YARN的核心技术优势
3.1 动态资源模型
对比传统静态槽位分配:
| 特性 | MapReduce1 | YARN |
|---|---|---|
| 资源类型 | 固定槽位 | 多维资源 |
| 分配粒度 | 槽位级别 | 容器级别 |
| 弹性伸缩 | 不支持 | 实时调整 |
| 异构框架支持 | 仅MR | 多框架 |
通过ReservationSystem实现资源预留,保障SLA
3.2 多租户隔离
通过层级队列实现资源隔离:
<!-- capacity-scheduler.xml配置示例 -->
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>70</value>
</property>
</configuration>
支持Linux CGroups、Docker等隔离机制
3.3 跨框架资源共享
典型应用场景:
- 流批一体:Flink流处理与Spark批处理共享集群
- 机器学习:TensorFlow on YARN与MapReduce共存
- 实时分析:Presto交互查询与Hive ETL任务并行
四、YARN的最佳实践
4.1 性能调优指南
关键配置参数:
# yarn-site.xml
yarn.nodemanager.resource.memory-mb = 物理内存*0.8
yarn.scheduler.maximum-allocation-mb = 单容器内存上限
yarn.nodemanager.vmem-pmem-ratio = 3 # 虚拟内存系数
# capacity-scheduler.xml
yarn.scheduler.capacity.resource-calculator = DominantResourceCalculator
4.2 故障排查矩阵
常见问题及解决方案:
| 故障现象 | 排查步骤 | 修复方法 |
|---|---|---|
| AM频繁重启 | 检查RM日志AMAttempt状态 | 调整AM资源请求量 |
| Container启动失败 | 查看NM的container-executor日志 | 验证cgroup配置 |
| 资源利用率低 | 分析Scheduler的Metrics | 优化调度策略参数 |
| 队列资源争抢 | 检查Preemption策略 | 配置合理的队列优先级 |
五、YARN的演进方向
随着云原生技术发展,YARN正在向以下方向演进:
- Kubernetes集成:通过YuniKorn等组件实现混合调度
- GPU/NPU支持:增强异构计算能力
- Serverless化:基于事件驱动的弹性伸缩
- 智能化调度:结合机器学习预测资源需求
总结
作为Hadoop生态的"操作系统",YARN通过创新的架构设计解决了传统MapReduce的诸多局限。其核心价值不仅在于资源管理的通用性,更在于为大数据生态的持续演进提供了坚实基础。理解YARN的运作机理,对于构建高效、稳定的大数据平台具有重要实践意义。


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











