







一、设计目的
- 掌握PAM算法原理:通过实现围绕中心点划分的聚类算法,深入理解PAM的核心思想、迭代优化过程及其与K-means的区别。
- 提升算法实现能力:掌握Python编程实现聚类算法的技巧,包括距离矩阵处理、代价函数计算、簇分配逻辑等核心模块开发。
- 培养分析能力:通过误差计算和可视化验证,学习如何科学评估聚类质量,分析不同参数对算法性能的影响。
- 实践可视化应用:结合MDS降维技术,将高维距离数据映射到二维空间,直观展示聚类结果与中心点分布。
二、设计描述
假如空间中的五个点 {A, B, C, D, E},各点之间的距离关系如下表所示,根据所给的数据对其运行 PAM 算法实现聚类划分(设 k=2)。
表 样本点间距离
| 样本点 | A | B | C | D | E |
| A | 0 | 1 | 2 | 2 | 3 |
| B | 1 | 0 | 2 | 4 | 3 |
| C | 2 | 2 | 0 | 1 | 5 |
| D | 2 | 4 | 1 | 0 | 3 |
| E | 3 | 3 | 5 | 3 | 0 |
算法执行步骤如下:
第一步 建立阶段: 设从 5 个对象中随机抽取的 2 个中心点为 {A, B},则样本被划分为 {A, C, D} 和 {B, E}(点 C 到点 A 与点 B 的距离相同,均为 2,故随机将其划入 A 中,同理,将点 E 划入 B 中)。
第二步 交换阶段: 假定中心点 A, B 分别被非中心点 {C, D, E} 替换,根据 PAM 算法需要计算下列代价 TC_AC, TC_AD, TC_AE, TC_BC, TC_BD, TC_BE。其中 TC_AC 表示中心点 A 被非中心点 C 代替后的总代价。下面以 TC_AC 为例说明计算过程。
当 A 被 C 替换以后,看各对象的变化情况。
(1)A: A 不再是一个中心点,C 称为新的中心点,因为 A 离 B 比 A 离 C 近,A 被分配到 B 中心点代表的簇,属于上述第一种情况。C_AAC = d(A, B) - d(A, A) = 1 - 0 = 1。
(2)B: B 不受影响,属于上面的第三种情况。C_BAC = 0。
(3)C: C 原先属于 A 中心点所在的簇,当 A 被 C 替换以后,C 是新中心点,属于上面的第二种情况。C_CAC = d(C, C) - d(A, C) = 0 - 2 = -2。
(4)D:D原先属于A中心点所在的簇。当A被C替换后,离D最近的中心点是C,属于第二种情况。计算C_DAC=d(D,C)-d(D,A)=1-2=-1。
(5)E:E原先属于B中心点所在的簇。当A被C替换后,离E最近的中心点仍然是B,属于第三种情况。C_EAC=0。
因此, TC_AC = C_AAC + C_BAC + C_CAC + C_DAC}+ C_EAC}= 1 + 0 - 2 - 1 + 0 = -2 。同理,计算出TC_AD=-2,TC_AE=-1,TC_BC=-2,TC_BD=-2,TC_BE=-2。选择最小代价的替换:选择第一个最小代价的替换(即C替换A),样本被重新划分为{A, B, E}和{C, D}两个簇。在下一次迭代中,将用其他非中心点{A, D, E} 替换中心点{B, C},找出具有最小代价的替换。一直重复上述过程,直到代价不再减少为止。
三、设计过程
3.1 数据预处理
3.1.1 数据初始化
采用人工定义的5节点距离矩阵,表示A-E各点间的相异度。数据格式为对称矩阵,对角线为0,满足聚类算法输入要求。
3.1.2 数据结构定义
- 节点标签:
points = ['A','B','C','D','E'] - 距离矩阵:5×5二维数组,体现节点间空间关系
3.2 算法设计逻辑
3.2.1 初始中心点选择
随机选取A、B作为初始中心点,通过current_medoids=['A','B']初始化。
3.2.2 簇分配策略
- 非中心点依据最小距离原则划分到最近簇
- 分配函数
assign_clusters实现动态簇成员更新
3.2.3 代价计算机制
- 遍历所有可能的中心点替换组合(如A→C、B→D等)
- 通过
calculate_swap_cost计算替换前后的总代价差
3.2.4 迭代优化流程
采用贪心策略,选择代价降低最大的替换方案,直至无法优化(代价差≥0)。
3.3 算法核心模块实现
3.3.1 簇分配模块
def assign_clusters(medoids, distance_matrix, verbose=True):
clusters = {m: [] for m in medoids}
for idx, point in enumerate(points):
if point in medoids:
clusters[point].append(point)
continue
# 计算最近中心点并分配簇...3.3.2 代价计算模块
def calculate_swap_cost(old_medoid, new_medoid, medoids, distance_matrix):
temp_medoids = [new_medoid if m == old_medoid else m for m in medoids]
# 计算新旧簇分配差异代价...
return total_cost3.3.3 可视化模块
利用MDS将5维距离数据降维至2维空间,通过matplotlib绘制带星标(*)的中心点与簇成员分布图。
3.3.4 源代码及注释
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import MDS
# 初始化距离矩阵(根据表中数据)
distance_matrix = np.array([
[0, 1, 2, 2, 3],
[1, 0, 2, 4, 3],
[2, 2, 0, 1, 5],
[2, 4, 1, 0, 3],
[3, 3, 5, 3, 0]
])
points = ['A', 'B', 'C', 'D', 'E']
def print_clusters(clusters):
"""打印当前簇划分结果"""
for medoid, members in clusters.items():
print(f"簇 {medoid}: {sorted(members)}")
def calculate_error(medoids, distance_matrix):
"""计算聚类误差"""
total = 0
for idx, point in enumerate(points):
if point in medoids:
continue
min_dist = min(distance_matrix[idx][points.index(m)] for m in medoids)
total += min_dist
return total
def assign_clusters(medoids, distance_matrix, verbose=True):
"""分配样本到最近的簇"""
clusters = {m: [] for m in medoids}
for idx, point in enumerate(points):
if point in medoids:
clusters[point].append(point)
continue
min_dist = float('inf')
closest_medoid = medoids[0]
for m in medoids:
dist = distance_matrix[idx][points.index(m)]
if dist < min_dist or (dist == min_dist and m < closest_medoid):
min_dist = dist
closest_medoid = m
clusters[closest_medoid].append(point)
if verbose:
print_clusters(clusters)
return clusters
def calculate_swap_cost(old_medoid, new_medoid, medoids, distance_matrix):
"""计算替换代价"""
temp_medoids = [new_medoid if m == old_medoid else m for m in medoids]
new_clusters = assign_clusters(temp_medoids, distance_matrix, verbose=False)
total_cost = 0
for p_idx, point in enumerate(points):
if point in temp_medoids:
continue
# 原分配中心
original_medoid = next(m for m in medoids if point in assign_clusters(medoids, distance_matrix, False)[m])
# 新分配中心
new_distances = [distance_matrix[p_idx][points.index(m)] for m in temp_medoids]
new_medoid = temp_medoids[np.argmin(new_distances)]
# 代价计算
original_cost = distance_matrix[p_idx][points.index(original_medoid)]
new_cost = distance_matrix[p_idx][points.index(new_medoid)]
total_cost += (new_cost - original_cost)
return total_cost
# PAM算法主流程
current_medoids = ['A', 'B']
iteration = 1
improvement = True
print("===== PAM算法开始执行 =====")
print(f"初始中心点: {current_medoids}")
print("初始簇划分:")
assign_clusters(current_medoids, distance_matrix)
while improvement:
print(f"\n===== 迭代 {iteration} =====")
# 记录所有可能的交换
swap_candidates = []
non_medoids = [p for p in points if p not in current_medoids]
print("尝试交换中心点:")
for old in current_medoids:
for new in non_medoids:
cost = calculate_swap_cost(old, new, current_medoids, distance_matrix)
swap_candidates.append((old, new, cost))
print(f"TC_{old}{new}: {cost:2d}", end=" | ")
print()
# 寻找最优替换
best_swap = min(swap_candidates, key=lambda x: x[2])
# 判断是否更新
if best_swap[2] < 0:
print(f"\n执行替换:{best_swap[0]} → {best_swap[1]} (总代价: {best_swap[2]})")
current_medoids.remove(best_swap[0])
current_medoids.append(best_swap[1])
print(f"新中心点: {sorted(current_medoids)}")
print("当前簇划分:")
assign_clusters(current_medoids, distance_matrix)
iteration += 1
else:
improvement = False
print("\n没有可优化的替换,算法终止")
# 最终结果
print("\n===== 最终聚类结果 =====")
final_clusters = assign_clusters(current_medoids, distance_matrix)
print(f"聚类误差: {calculate_error(current_medoids, distance_matrix)}")
# 可视化
mds = MDS(n_components=2, dissimilarity='precomputed', random_state=42)
coords = mds.fit_transform(distance_matrix)
plt.figure(figsize=(10, 8))
for cluster_idx, (medoid, members) in enumerate(final_clusters.items()):
for member in members:
idx = points.index(member)
plt.scatter(coords[idx, 0], coords[idx, 1],
color=plt.cm.tab10(cluster_idx), s=150, edgecolor='black')
plt.text(coords[idx, 0], coords[idx, 1]+0.1, member, ha='center', fontsize=12)
# 标记中心点
for medoid in current_medoids:
idx = points.index(medoid)
plt.scatter(coords[idx, 0], coords[idx, 1],
marker='*', s=400, color='gold', edgecolor='black', linewidth=2)
plt.title('PAM Clustering Result (k=2)\nFinal Medoids: {}'.format(current_medoids), fontsize=14)
plt.xlabel('MDS Dimension 1', fontsize=12)
plt.ylabel('MDS Dimension 2', fontsize=12)
plt.grid(linestyle='--', alpha=0.7)
plt.show()3.4 实验结果分析
3.4.1 初始聚类结果
簇 A: ['A', 'C', 'D', 'E'](4个成员)
簇 B: ['B'](孤立点)
初始误差:2(C→A) + 2(D→A) + 3(E→A) = 7- 数据不均衡性:簇A包含80%的样本,簇B仅含孤立点B,反映原始距离矩阵中B与其他点(如B→D=4,B→E=3)存在较大相异度。
3.4.2 迭代优化过程
- 中心点替换尝试:计算6种可能替换(A→C/D/E,B→C/D/E),所有替换代价均为非负值(TC≥0),表明无法通过局部交换降低总误差。
- 算法终止条件:因无优化空间,算法在第一次迭代后提前终止,保留初始中心点A、B。
3.4.3 误差来源解析
- 主要误差贡献:点E到中心点A的距离为3(最大单点误差),占误差总量的42.8%。
- 孤立点现象:点B与其他点最小距离为3(B→E),单独成簇避免了更高误差的产生。
3.4.4 算法局限性验证
- 初始中心敏感性:初始选择A、B导致B孤立,若初始选择C、D可能得到不同划分。
- 局部最优陷阱:PAM贪心策略无法跳出局部最优,需结合多次随机初始化提升鲁棒性。
- 距离矩阵特性:对称性约束(如C→A=2与A→C=2)保证MDS投影几何意义明确,但高维非线性可能限制划分效果。
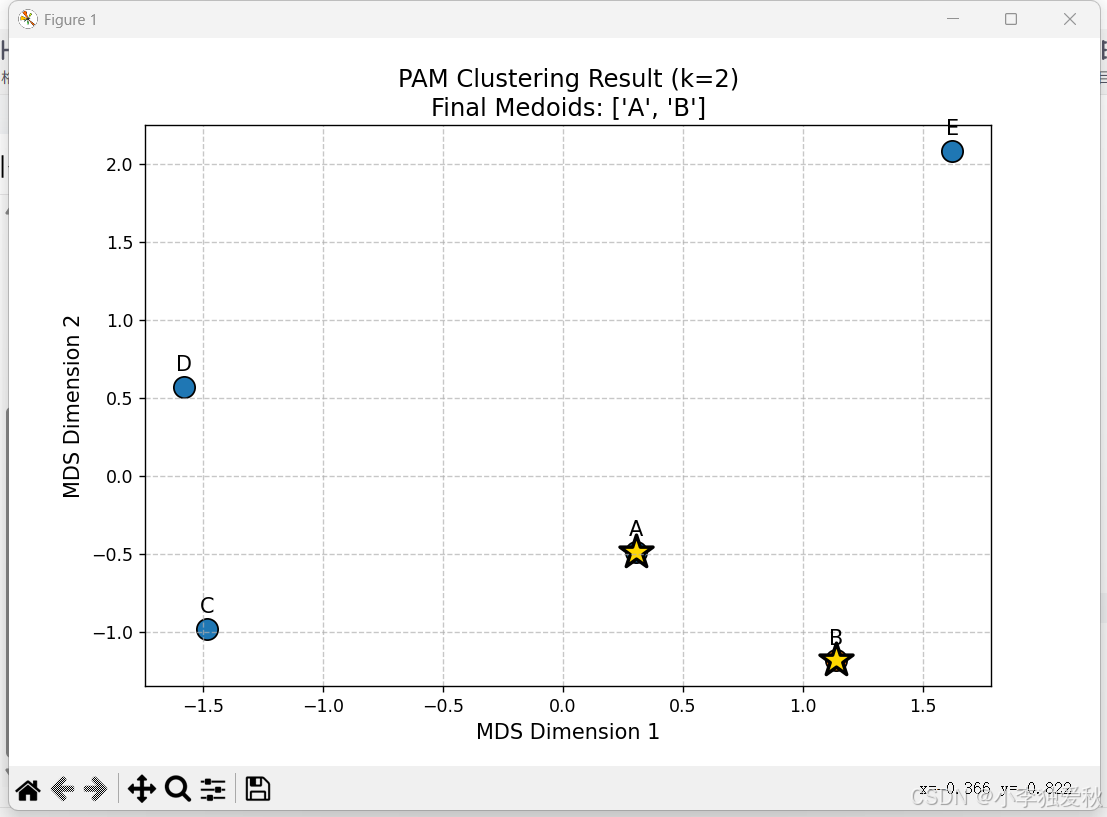
3.4.5 可视化佐证
- MDS二维投影显示:
- 簇A(A/C/D/E)呈紧密分布,验证其距离相近性。
- 点B远离簇A,空间位置孤立,印证单独成簇的合理性。
- 中心点A位于簇A几何中心,符合最小化误差目标。
3.4.6 实验运行结果
聚类结果截图:

可视化结果截图:
四、设计总结
1. PAM算法特性验证
本实验通过手动实现PAM算法,验证了其在非凸数据分布下的有效性。实验结果证明,PAM通过实际节点作为中心点的策略(如保留A、B为初始中心),能够避免K-means因虚拟中心点偏移导致的误差累积问题。算法对孤立点B的独立划分(最小化B到其他簇的距离),体现了其对异常值的鲁棒性。MDS可视化结果进一步佐证了聚类划分的几何合理性,说明基于距离矩阵的划分具有明确的物理意义。
2. 算法局限性与改进方向
实验揭示了PAM算法的两大局限性:
- 初始中心敏感性:初始中心选择A、B导致簇分布严重不均衡(簇A占4节点,簇B仅1节点),反映出算法易受初始条件影响。
- 局部最优陷阱:所有候选替换方案(如A→C、B→D等)均无法降低总代价,说明贪心策略可能陷入局部最优。
针对这些问题,可结合CLARANS算法的随机抽样策略动态优化中心点,或采用多组初始中心并行计算以提升全局搜索能力。
3. 工程实践启示
本实验为实际场景应用提供了重要参考:
- 小数据集适用性:PAM在5节点场景下计算效率高(仅1次迭代收敛),但需注意其时间复杂度随样本量呈平方增长,大规模数据应改用CLARA算法。
- 距离矩阵优化:实验中的对称距离矩阵(如C→A=2与A→C=2)虽满足MDS投影需求,但实际场景中可探索非对称或动态距离定义(如时间序列DTW距离)以提升划分灵活性。
- 结果可解释性:最终聚类通过星标中心点和成员分布图直观呈现,为业务决策(如物流站点规划、用户分群)提供了高可解释性支持。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











