







引言
操作数的类型和大小是计算机指令集架构设计的核心要素之一,它直接决定了硬件对数据类型的支持能力、计算精度以及系统效率。操作数设计需要遵循软硬件界面清晰化和执行效率最大化两大原则。本讲将结合x86、ARM、RISC-V等典型架构案例,深入解析操作数类型表示方式与访问频率分布的底层逻辑。
一、操作数类型的表示方式
1. 类型表示方法分类
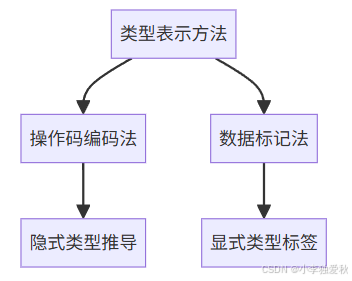
(1)操作码编码法(主流方案)
- 原理:通过指令操作码隐含数据类型
- 实现案例:
- x86架构:
ADD EAX, EBX(32位整数)、FADD ST(0), ST(1)(80位浮点数) - RISC-V架构:
ADD(整数)、FADD.S(单精度浮点)
- x86架构:
- 优势:指令密度高,硬件实现简单
(2)数据标记法(历史方案)
- 原理:在数据头部添加类型标签(如1字节标志位)
- 典型案例:Burroughs B5000的Tagged Architecture
- 缺点:存储开销增加20%,现代处理器已弃用
2. 主流数据类型表示
| 数据类型 | 位宽 | 表示方式 | 典型指令案例 |
|---|---|---|---|
| 整数 | 8/16/32/64 | 补码(Two's Complement) | x86 MOV AL, 0xFF |
| 无符号整数 | 8/16/32/64 | 原码 | ARM LDRB R0, [R1] |
| 浮点数 | 32/64/80 | IEEE 754标准 | RISC-V FADD.D FT0, FT1 |
| 字符 | 8/16 | ASCII/Unicode编码 | Java虚拟机 i2c |
| 布尔型 | 1 | 位掩码(Bit Mask) | MIPS ANDI $t0, $t1, 1 |
| 地址类型 | 32/64 | 虚拟地址(Virtual Address) | x86-64 LEA RAX, [RIP+0x100] |
二、操作数访问频率分析
1. 数据类型使用分布表
基于SPEC CPU2017测试集的统计分析:
| 数据类型 | 访问频率 | 典型应用场景 | 硬件加速方案 |
|---|---|---|---|
| 32位整数 | 58% | 逻辑运算、数组索引 | ALU整数单元 |
| 64位地址 | 22% | 指针操作、内存寻址 | AGU地址生成单元 |
| 单精度浮点 | 12% | 图形渲染、科学计算 | FPU浮点单元 |
| 双精度浮点 | 5% | 金融计算、高精度仿真 | AVX-512向量单元 |
| 8/16位数据 | 3% | 多媒体处理、嵌入式控制 | SIMD扩展指令集 |
2. 操作数位宽选择策略
(1)黄金分割原则
- 32位系统:优先支持32位操作数(占80%使用场景)
- 64位系统:兼容32位操作,扩展64位地址支持
(2)动态扩展技术
- x86架构:通过REX前缀实现64位操作数扩展
- ARMv8:AArch64模式自动扩展32位寄存器到64位
三、操作数访问的量化分析
1. 访存操作频率分布表
基于DLX架构模拟器的统计结果:
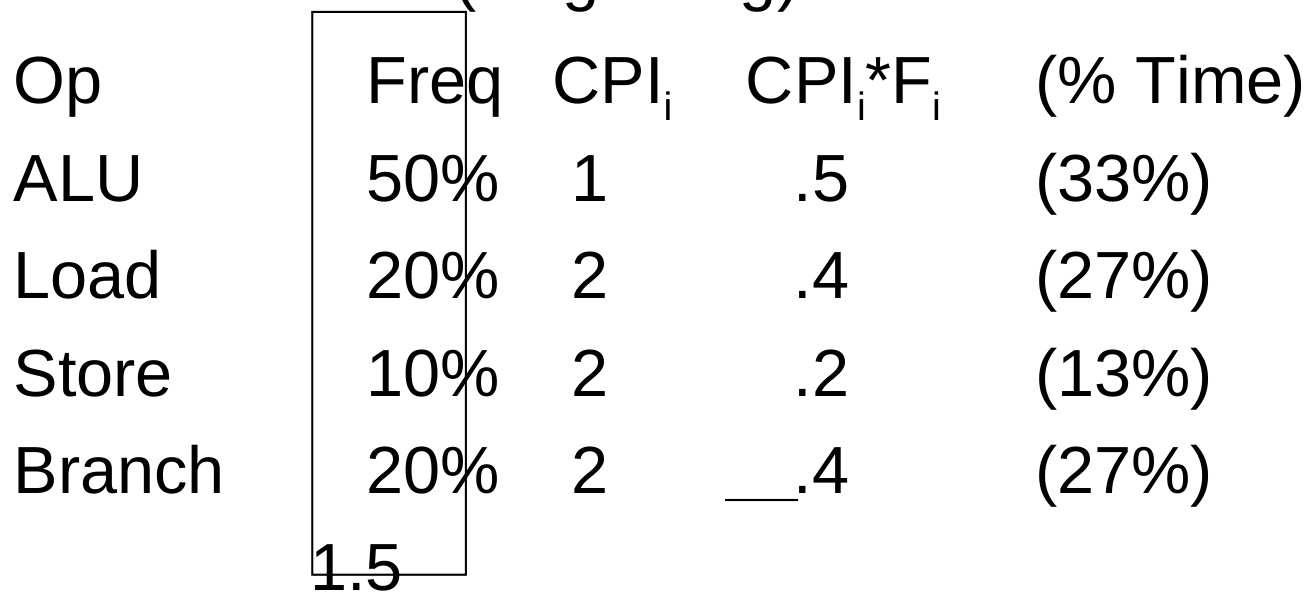
| 操作类型 | 频率 | 平均CPI | 耗时占比 |
|---|---|---|---|
| ALU运算 | 50% | 1 | 33% |
| Load操作 | 20% | 2 | 27% |
| Store操作 | 10% | 2 | 13% |
| 分支跳转 | 20% | 2 | 27% |
关键发现:
- 整型操作占据绝对主导(ALU+Load/Store占比80%)
- 浮点操作虽频率低,但单次耗时高(FPU单元CPI通常为4-6)
2. 操作数位宽对性能的影响
性能模型:
有效带宽=∑(操作数大小i×访问次数i)总执行时间有效带宽=总执行时间∑(操作数大小i×访问次数i)
案例对比:
- 32位系统处理64位数据:需拆分为两次操作,性能下降40%
- AVX-512处理512位向量:相比标量指令加速8-10倍
四、现代架构设计趋势
1. 混合精度支持
- NVIDIA Tensor Core:支持FP16/FP32/TF32混合计算
- Intel AMX:矩阵引擎支持INT8/BF16数据类型
2. 类型自适应硬件
- IBM Power10:MMA单元自动识别操作数类型
- RISC-V P扩展:动态切换整数与SIMD处理模式
3. 内存语义扩展
- 非易失内存:支持原子性256位操作(Intel Optane)
- 缓存行优化:将常用数据类型对齐到64字节边界
结语:操作数设计的哲学思辨
操作数类型与大小的设计本质上是精度、效率、通用性的三角博弈。三大设计定律:
- 80/20定律:优化20%高频数据类型可解决80%性能问题
- 兼容性优先:向下兼容旧数据类型是商业成功的基石
- 可扩展原则:预留位宽扩展空间应对未来需求
当前技术发展呈现两大趋势:
- 领域专用化:针对AI、5G等场景定制操作数类型(如Google TPU的BF16矩阵运算)
- 量子化突破:量子比特操作数正在重新定义计算范式
理解操作数设计的底层逻辑,是掌握计算机系统结构演进规律的关键钥匙。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











