







一、采用转移历史表(Branch History Table, BHT)
1.1 BHT的核心原理与硬件结构
转移历史表(BHT) 是动态分支预测的基础硬件结构,其核心思想是通过记录分支指令的历史行为预测未来跳转方向。BHT通常与程序计数器(PC)配合使用,在指令取指阶段(IF)即完成预测。
(1)BHT的硬件实现
-
存储结构:BHT由若干表项组成,每个表项对应一条分支指令,包含以下字段:
| 有效位(Valid) | 分支指令地址(Tag) | 历史状态(2位饱和计数器) | 目标地址(可选) | -
访问方式:使用PC的低位地址作为索引(如PC[6:0]),支持直接映射或组相联结构。
(2)两位饱和计数器
BHT的核心预测机制基于两位饱和计数器,状态转移规则如下:
- 初始状态:弱不跳转(Weakly Not Taken,01)
- 预测逻辑:
当前状态 实际结果 下一状态 预测行为 ------------------------------------------------- 00 (SNT) 跳转(Taken) → 01 (WNT) 预测不跳转 01 (WNT) 跳转(Taken) → 11 (ST) 预测跳转 11 (ST) 不跳转 → 10 (WNT) 预测跳转 10 (WNT) 不跳转 → 00 (SNT) 预测不跳转
优势:对偶发跳转行为具有容错性,预测准确率可达85%-90%。
1.2 BHT的改进与扩展
(1)全局历史与局部历史结合
- 全局历史寄存器(GHR) :记录最近N条分支指令的整体跳转方向(如N=12)。
- 局部历史表(LHT) :为每个分支指令单独存储历史模式。
- 组合预测:通过哈希函数将GHR与PC结合,索引模式历史表(PHT)。
(2)锦标赛预测器(Tournament Predictor)
- 双预测器结构:同时运行全局预测器和局部预测器。
- 选择逻辑:根据历史表现动态选择更优的预测器,准确率可提升至95%以上。
二、采用转移目标缓冲器(Branch Target Buffer, BTB)
2.1 BTB的架构与工作流程
转移目标缓冲器(BTB) 是解决分支目标地址获取延迟的关键硬件结构,其核心功能包括:
- 缓存分支指令地址与目标地址的映射关系
- 提前提供目标地址以消除取指停顿
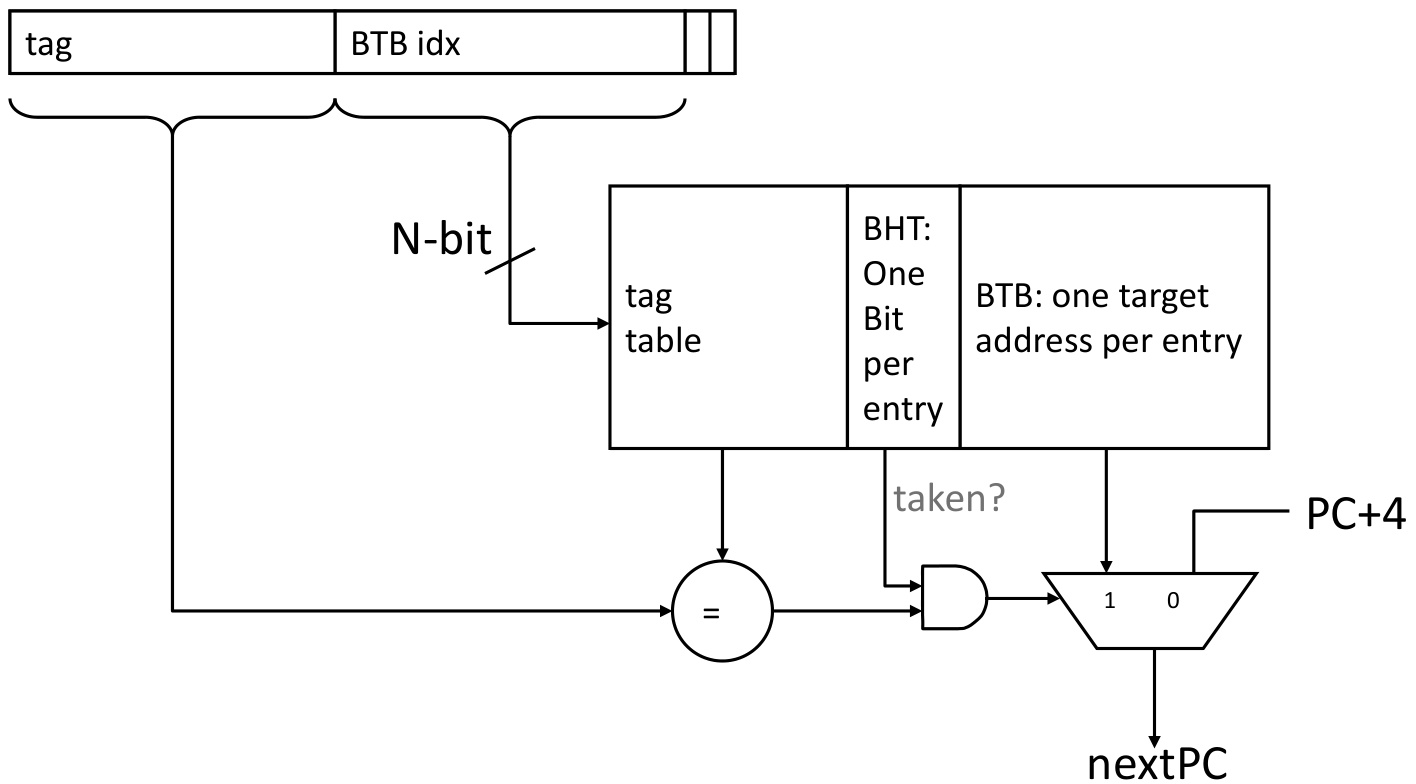
(1)BTB的硬件组成
| 字段 | 描述 |
|---|---|
| Tag | 分支指令的地址(高位部分) |
| Valid | 标记该条目是否有效 |
| Target PC | 分支目标地址 |
| History Bits | 可选字段,存储分支历史状态(与BHT集成时可省略) |
访问流程:
- 地址匹配:使用PC的低位索引BTB,比较Tag字段确认是否命中。
- 目标预取:若命中且Valid=1,立即从Target PC开始取指;否则顺序取指。
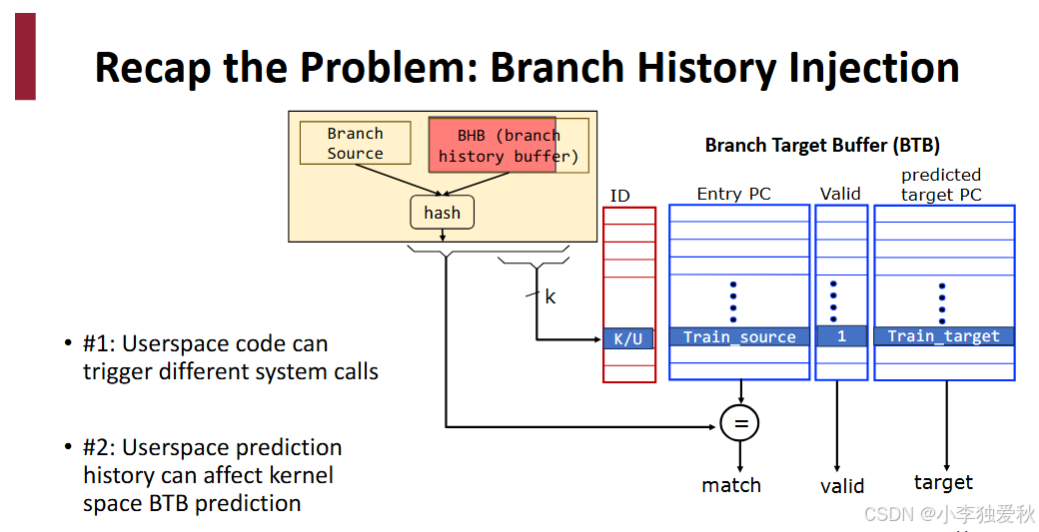
(2)BTB与BHT的协同工作
-
基础架构:
PC → BTB(获取目标地址) → BHT(预测跳转方向) → 选择下一条PC -
优化架构(现代处理器常见):
PC → 并行访问BTB和BHT → 综合预测结果与目标地址 → 输出下一PC典型实现如Intel Core系列处理器的两级预测结构。
2.2 BTB的高级特性
(1)返回地址栈(RAS)
- 功能:专用于处理函数返回指令(RET),自动保存和恢复返回地址。
- 工作流程:
- CALL指令:将返回地址压入RAS。
- RET指令:弹出RAS栈顶地址作为目标,避免BTB查询。
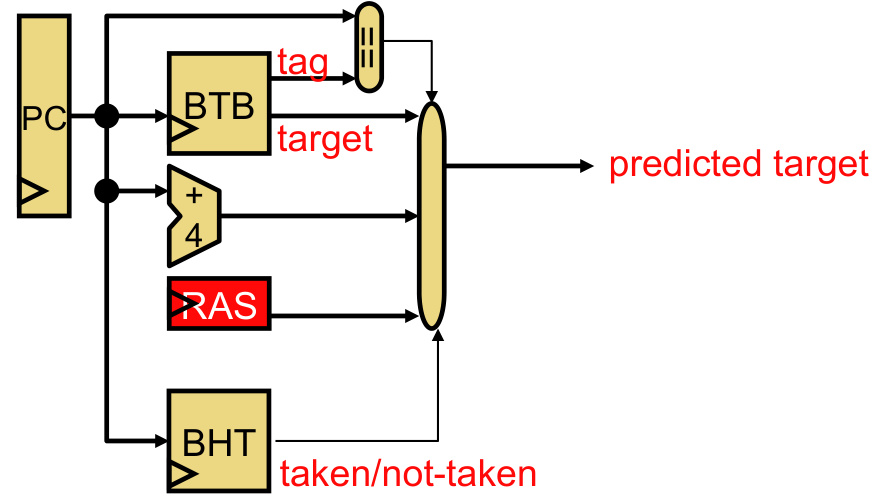
(2)间接跳转预测
- 挑战:间接跳转(如C++虚函数调用)的目标地址动态变化。
- 解决方案:在BTB中增加目标地址历史缓冲区(TAHB),记录多个可能的目标。
三、基于硬件的前瞻执行(Speculative Execution)
3.1 前瞻执行的核心机制
前瞻执行通过预测分支方向并提前执行后续指令,将控制相关转化为数据相关管理,其实现依赖以下硬件支持:
- 重排序缓冲区(ROB) :按程序顺序缓存推测执行结果。
- 寄存器重命名:消除名称相关,支持指令乱序执行。
- 分支预测器集成:BTB与BHT提供预测方向和目标地址。
(1)前瞻执行流程
- 分支预测:在取指阶段预测分支方向,并开始推测执行。
- 指令派遣:将推测指令加入ROB,标记为“未提交”状态。
- 结果暂存:执行结果写入ROB而非物理寄存器,避免污染架构状态。
- 提交或回滚:分支结果确认后,提交ROB条目或清空推测状态。
(2)异常处理机制
- 精确异常:ROB确保异常按程序顺序触发。
- 推测屏蔽:在指令提交前暂缓异常信号传递。
3.2 前瞻执行的性能优化
(1)深度推测窗口
- ROB容量:现代处理器(如Intel Core i9)的ROB可容纳224条指令,支持长流水线的深度推测。
- 资源分配:动态分配保留站和ROB条目,避免资源死锁。
(2)误预测恢复
- 快速回滚:清空ROB中推测指令,从正确地址重启取指。
- 惩罚周期:典型误预测惩罚为15-20周期,优化后可降至10周期以下。
四、动态分支预测的实践与案例分析
4.1 现代处理器实现对比
| 架构特性 | Intel Core i9-13900K | AMD Zen 4 | 龙芯3A6000 |
|---|---|---|---|
| BHT容量 | 8K条目(3级锦标赛预测) | 4K条目(感知预测器) | 2K条目(局部历史) |
| BTB容量 | 512条目(4-way组相联) | 256条目(全相联) | 128条目(直接映射) |
| 前瞻执行深度 | 224指令(ROB) | 192指令(MOB) | 64指令(简化ROB) |
4.2 性能提升效果
- IPC提升:动态分支预测可使IPC(每周期指令数)提升30%-50%。
- 误预测率:先进预测器(如TAGE-S)在SPEC CPU2017测试中误预测率低于3%。
五、总结与展望
动态分支预测技术通过硬件实时学习程序行为,显著降低了控制相关导致的流水线停顿。BHT与BTB的协同设计解决了方向预测与目标获取的双重挑战,而前瞻执行则进一步将预测转化为实际性能收益。未来发展趋势包括:
- AI驱动的预测器:利用神经网络模型学习复杂分支模式。
- 能效优化:动态关闭低利用率预测单元以降低功耗。
- 安全增强:防御Spectre类侧信道攻击,平衡性能与安全性。
代码示例:分支预测模拟器(Python伪代码)
class BHT:
def __init__(self, size):
self.entries = [{'state': 'WNT'} for _ in range(size)]
def predict(self, pc):
index = pc % len(self.entries)
return 'Taken' if self.entries[index]['state'] in ('ST', 'WT') else 'Not Taken'
def update(self, pc, actual):
index = pc % len(self.entries)
# 状态转移逻辑(略)
class BTB:
def __init__(self, size):
self.entries = [{'tag': None, 'target': None}]
def lookup(self, pc):
for entry in self.entries:
if entry['tag'] == pc:
return entry['target']
return None


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











