






今天开始写博客啦,本人非计算机专业,对一些问题的理解不够深入,还希望大家指教。
网络爬虫定义:
爬虫又称网络蜘蛛、网络机器人,主要的功能就是抓取网络数据的程序。本质就是用程序模拟人使用浏览器访问网站,并将所需要的数据抓取下来。
分为通用爬虫和聚焦爬虫,我所了解的只有聚焦爬虫,因此只对聚焦爬虫进行介绍。
聚焦爬虫:是面向特定需求的爬虫,因此它的程序具有很强的互异性(不同的网站写法不同)和灵活性。
网页的获取流程:
确定要抓取的数据:
目的很重要,可以确定一个大概的url。
分清是什么页面:
静态页面:数据在网页源码中可以找到,不是js动态生成的。

在源码的页面按ctrl+f可以打开搜索框对数据进行寻找。(浏览器自带的抓包工具是这么用的)
最经常抓的是XHR(抓取异步加载的网络数据包)。
2.动态页面:数据在网页源码中找不到,是js动态生成的。
获取到url(网址):
也叫找到接口。浏览器在向服务器发送一个请求的时候,该请求返回的结果可能会向其他url发出请求,我们要做的就是通过抓包工具进行寻找真正的url。可以通过抓包工具的network里的它对所有的包进行数据上的查找(它会对包内的数据进行匹配,只需要把数据放里面进行搜索就行了,但有可能找不到,他就这样没办法)。因为他最开始是方便前端人员用的。

最右边的
如果没找到,那就只能在XHR里一个一个翻了

iii.发送请求:
确定好url后可以通过网络中的标头确定发出请求的类型和参数。
类型主要分为两种(我就知道两种):
get:
get请求的url是可以直接在浏览器地址栏中输入访问的,get表示向浏览器发出查询的指示。我是通过requests模块里的get方法发送的,主要参数有两个,一个是url,表明要想那个url发送请求;一个是headers,表示请求头,是以字典的形式进行存储,cookie也是放在里面的。
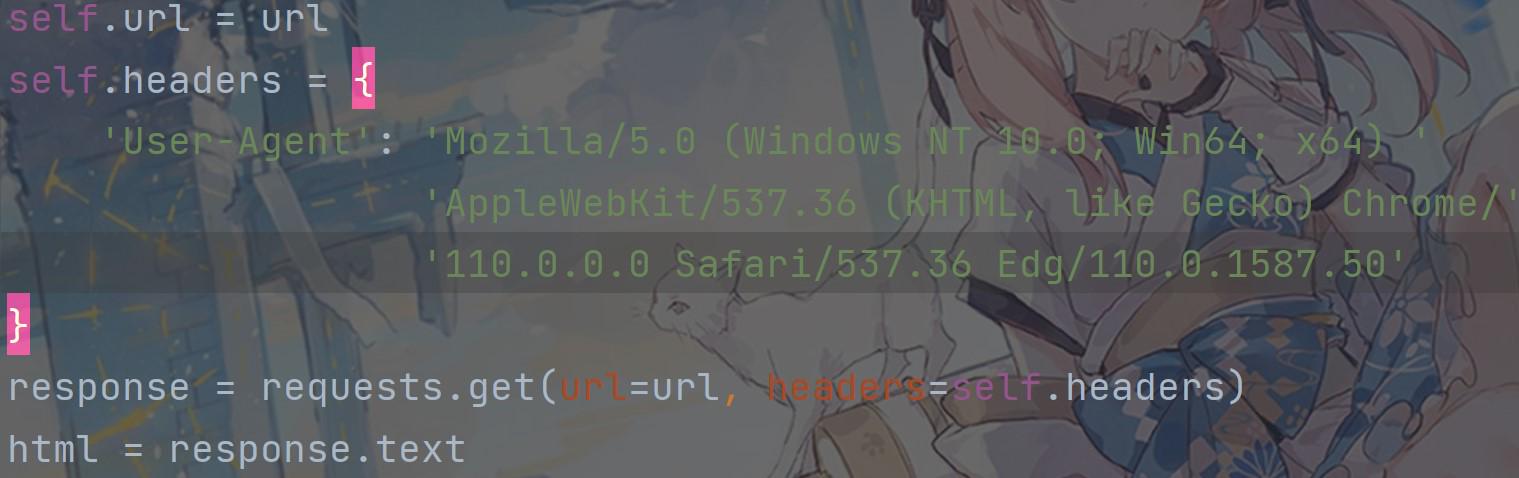
post:
post请求的url是在浏览器的地址栏里无法直接请求的,它与get的区别是get不带请求负载(请求时要传递给浏览器的参数),而post带。因此post比get多一个要传递的参数,根据数据格式的不同,选择要传递的参数也不同。数据是json,就传递给json。如果参数是json型的但传递给了data,那就需要在请求头中加入‘Content-Type’:“application/json”,说明参数形式。(注意:字典里的字符串前后不能有空格)
通过requests模块发送的请求,返回的事一个response对象,对象中有一个text属性,可以将返回的数据以字符串的形式展现;对象的json()方法可以将返回的数据以json的形式展现。根据返回数据的格式选择不同的选择合适的呈现方式有利于数据的解析。
iV.解析数据:
json形式:直接用字典取值的方式,可以利用https://www.json.cn/对数据进行脉络梳理。
html形式:可以用xpath,beautifulsoup,re等模块进行提取。
其他:re。(正则无敌,正则赛高!!!)
















 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











