






第一节、数据清洗及特征处理
首先导入numpy和pandas库并且将“train.csv”文件所在位置使用绝对路径导入查看前10行的内容,结果如下图所示:

数据清洗简述
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的样子。
缺失值:
数据缺失分为两种:一种是行记录的缺失(数据记录丢失);另一种是数据列值的缺失。
不同的数据存储和环境中对于缺失值的表示结果也不同,例如,数据库中是Null,Python返回对象是None,Pandas或Numpy中是NaN。
异常值:
从数据异常的状态看分为两种:
- 一种是“伪异常”,这些异常是由于业务特定运营动作产生的,其实是正常反映业务状态,而不是数据本身的异常规律。
- 一种是“真异常”,这些异常并不是由于特定的业务动作引起的,而是客观地反映了数据本身分布异常的分布个案。
重复值:
数据集中的重复值包括以下两种情况:
- 数据值完全相同的多条数据记录。这是最常见的数据重复情况。
- 数据主体相同但匹配到的唯一属性值不同。这种情况多见于数据仓库中的变化维度表,同一个事实表的主体会匹配同一个属性的多个值。
数据转换:
数据转换(data transformation)主要是对数据进行规格化操作。数据转换包含以下处理内容(1)平滑处理,帮助除去数据中的噪声,主要技术方法有:bin方法、聚类方法和回归方法。(2)合计处理,对数据进行总结或合计操作。
(3)数据泛化处理,所谓泛化处理就是用更抽象(或更高层次)的概念来取代低层次或数据层的数据对象。
(4)规格化,规格化就是将有关属性数据按比例投射到特定小范围之中,以消除数值型属性因大小不一而造成挖掘结果的偏差。
(5)属性构造,根据已有属性集构造新的属性,以帮助数据挖掘过程。
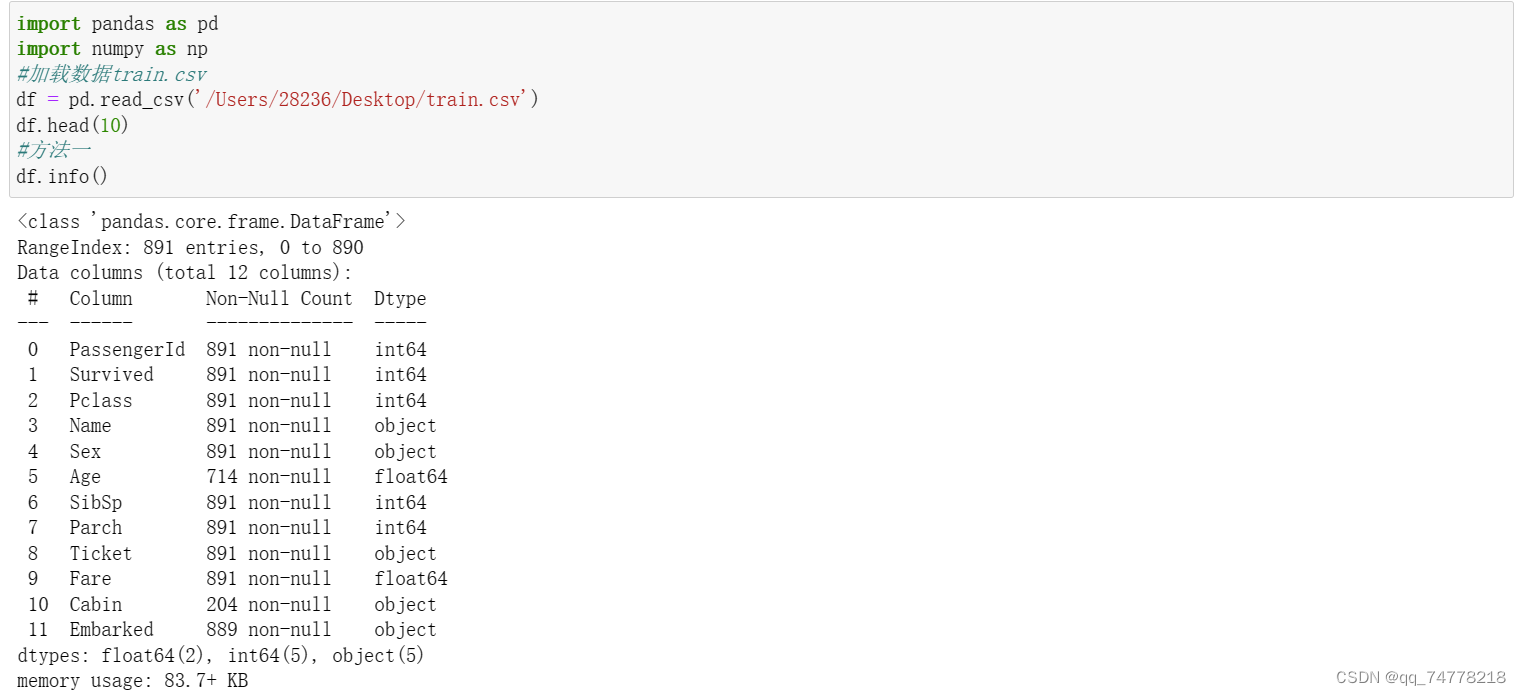
注意info()和describe()的区别:
describe()函数用于生成描述性统计信息。 描述性统计数据:数值类型的包括均值,标准差,最大值,最小值,分位数等;类别的包括个数,类别的数目,最高数量的类别及出现次数等;输出将根据提供的内容而有所不同。
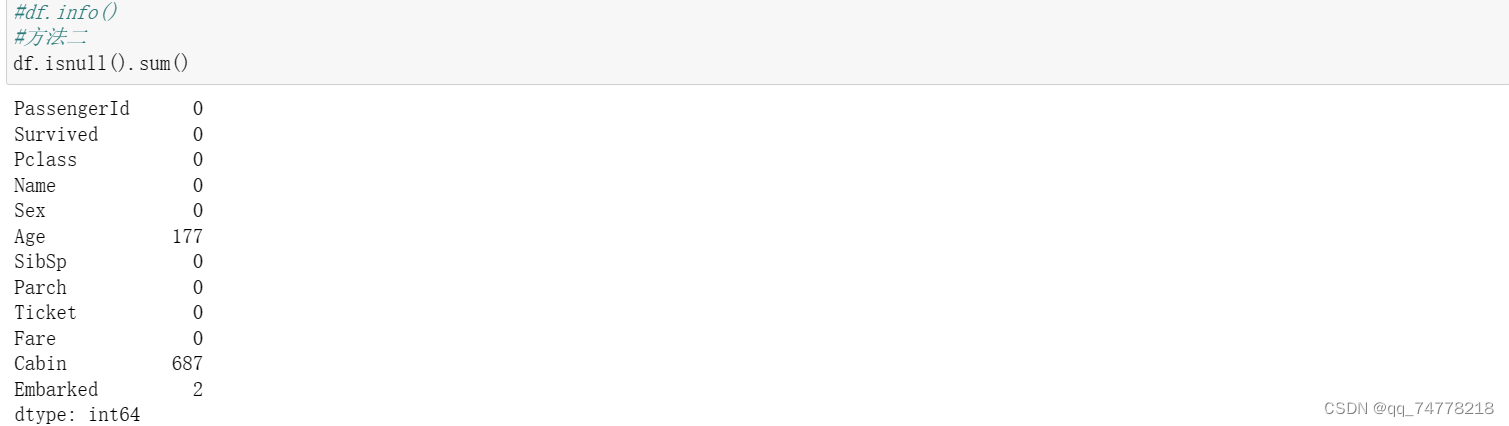

2.1.2 任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
(2) 请尝试对Age列的数据的缺失值进行处理
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
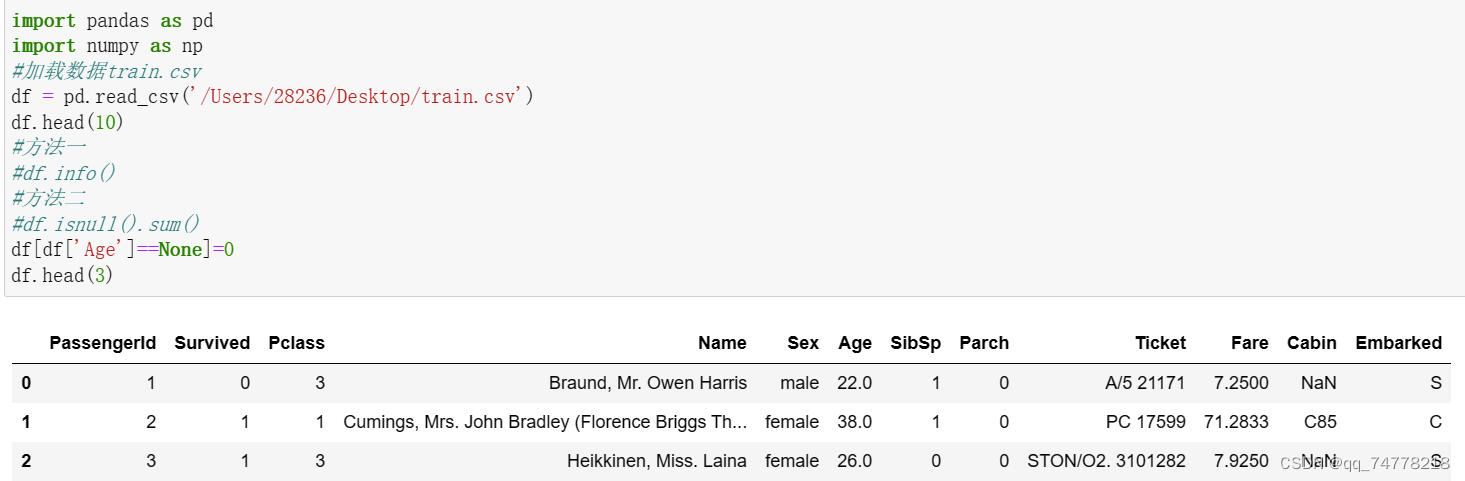
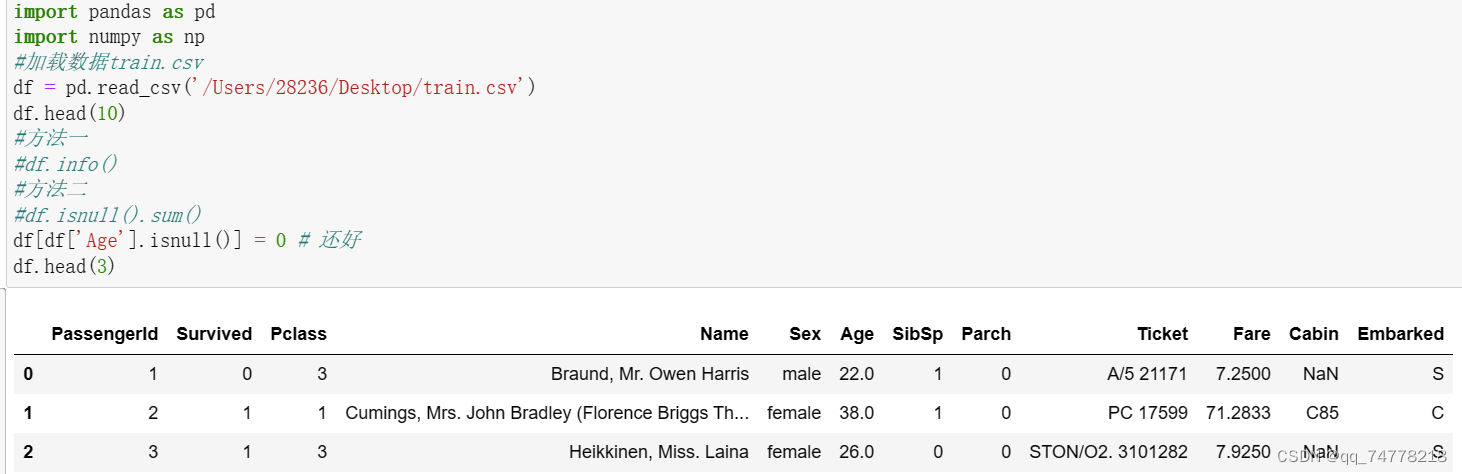
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
在Python中,通常使用`np.nan`和`.isnull()`来检索空缺值,而不是`None`。这是因为:
1. `np.nan`:`np.nan`是numpy库中用来表示缺失值的特殊值。使用`np.nan`可以更容易地在数据中标识和处理缺失值,特别是在处理数值数据时很方便。
2. `.isnull()`:`.isnull()`是pandas库中的一个方法,用来检查数据中的缺失值。这个方法可以快速检测数据中的空缺值,并返回一个布尔类型的DataFrame或Series,便于进一步处理。
相比之下,`None`在Python中通常用于表示缺失值,但在处理数据时并不方便。如果使用`None`来表示缺失值,可能会导致数据处理时出现错误或不便。
如果某个方式无法找到缺失值,可能是因为数据中的缺失值不是以该方式表示的,或者在处理数据时出现了其他问题。例如,如果数据中的缺失值被表示为空字符串而不是`np.nan`,使用`.isnull()`可能无法正确检测到这些缺失值。因此,在处理数据时,需要根据数据的实际情况选择合适的方式来检索空缺值。
对文本变量进行转换















 8372
8372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









