







列表排序的重要排序有三种,分别是快速排序、堆排序和归并排序。
这里我们来讨论堆排序:
堆排序
在开始学习这个算法前要对数据结构中的树有所学习,掌握基本的概念可以帮助更好的理解和学习堆排序。
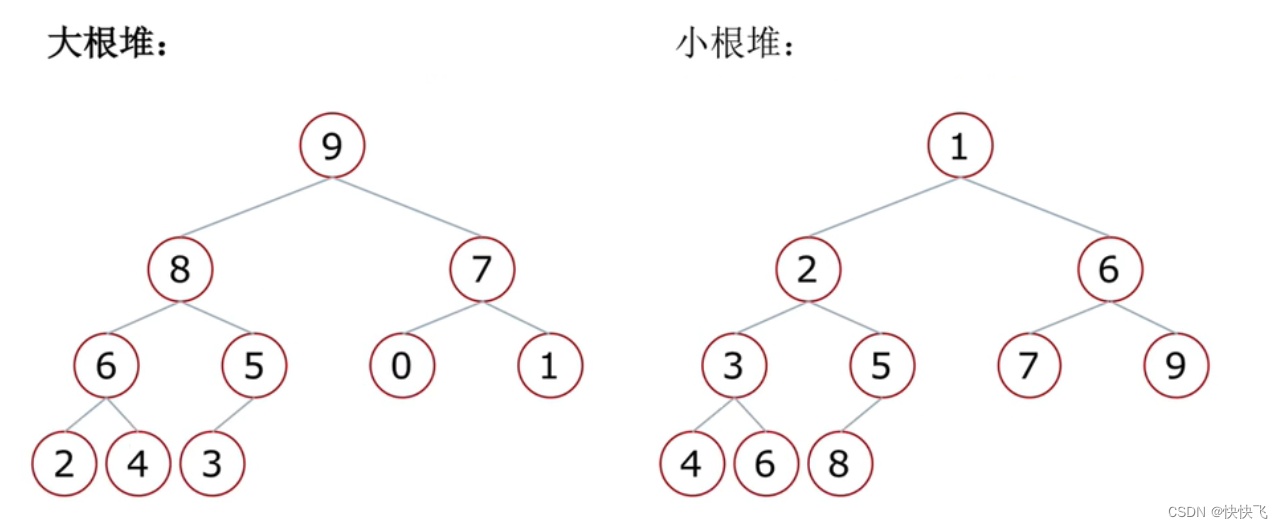
堆是一种特殊的完全二叉树结构,其又分为大根堆和小根堆,(
大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大;
小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小;如下图所示)
堆排序的向下调整性质
在了解堆之后我们就要想一想怎么完成堆排序呢?
首先,我们要理解一下堆的向下调整性质,即:
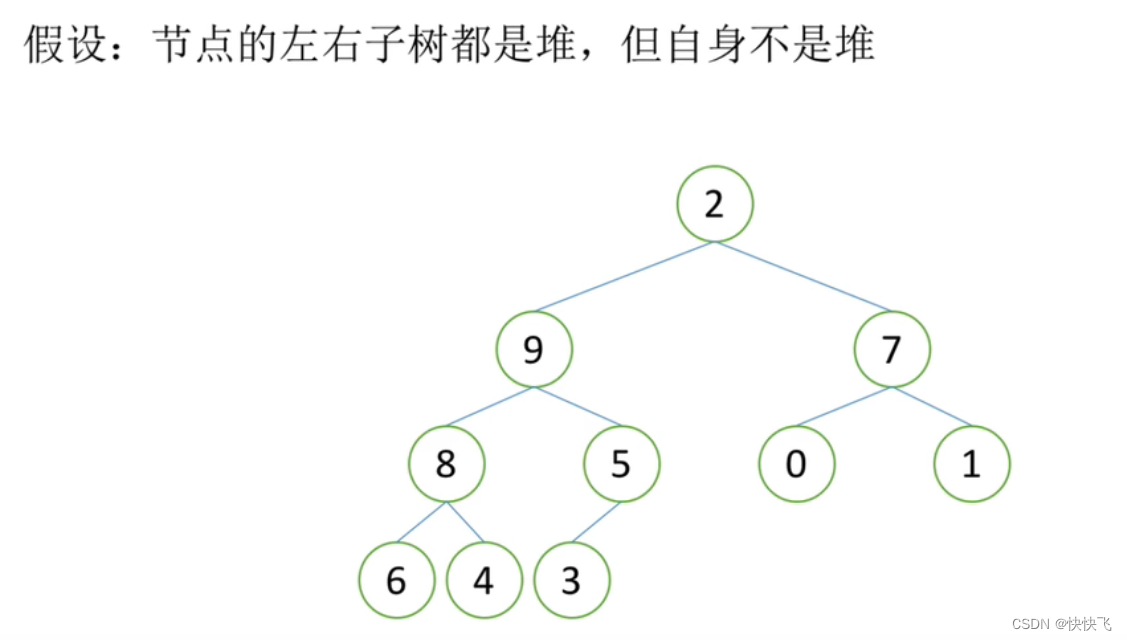
①假设根节点的左右子树都是堆,但根节点不满足堆的性质;(如下图)
②可以通过一次向下调整使其变成堆
而该次向下调整结果则如下所示:
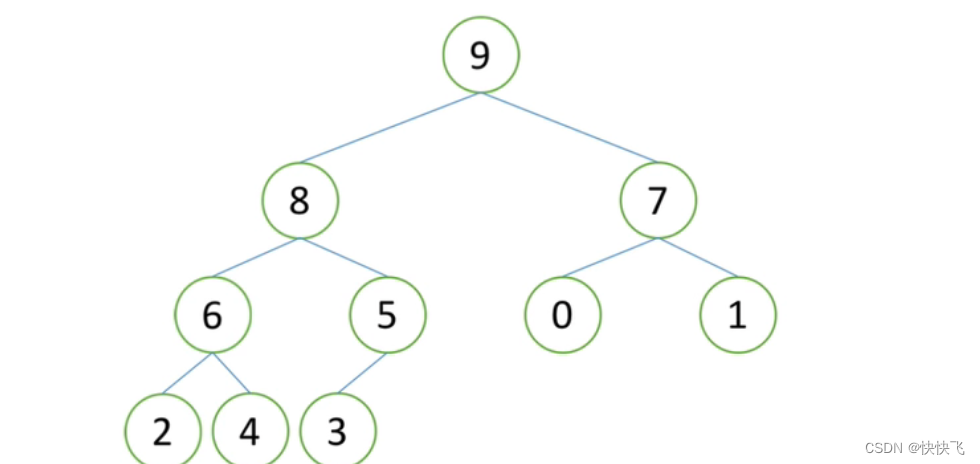
至此,堆的向下调整性质也就了解其过程了,而向下调整也是堆排序过程中很重要的步骤,其代码如下:
#向下调整函数
def sift(list,low,high):
'''
:param li: 列表
:param low: 堆的根节点
:param high: 堆的最后一个元素的位置
:return:
'''
i =low #最开始指向根节点
j=2*i+1 #开始指向i的左孩子节点
tmp =list[low] #把堆顶存起来
while j<=high: #j位置有数时一直循环
if j+1<=high and list[j]<list[j+1]:
j=j+1 #指向i的右孩子节点
if list[j]>tmp:
list[i]=list[j]
i=j #接着看下一层
j=2*i+1
else: #tmp大于孩子节点
list[i]=tmp #把tmp放在某一级根节点的位置
break
else: #当i在最后一层时,j越界,i已经没有孩子节点
list[i]=tmp #把tmp放到i的位置上(叶子结点)
堆排序的具体过程
接下来我们继续来深入学习堆排序的过程(默认排序为大根堆),大致分为以下几步:
①建立一个堆;
②得到堆顶元素为最大元素;
③去掉堆顶,将最后一个元素放到堆顶位置,此时可通过一次向下调整使堆再次有序;
④此时堆顶为第二大元素;
⑤不断重复步骤③,直到堆空。
其中去掉堆顶元素,将最后一个元素放到堆顶进行向下调整的过程可以说是堆排序的核心,我们也可以把这个过程叫做“挨个出数”。接下来我们来跟着具体的堆的变化来拆分这个过程:

我们用上图来表示①②后的结果,即一个大根堆。

上图是将堆顶元素9去掉;
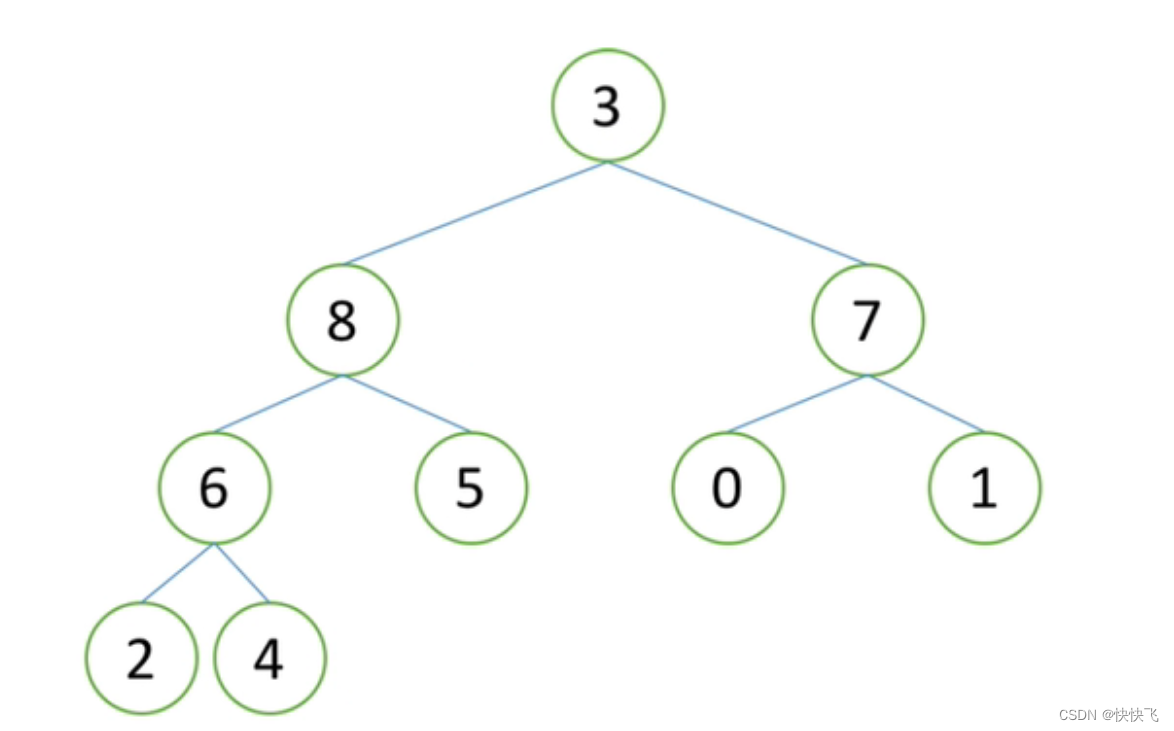
接着把最后一个元素3放到堆顶位置;
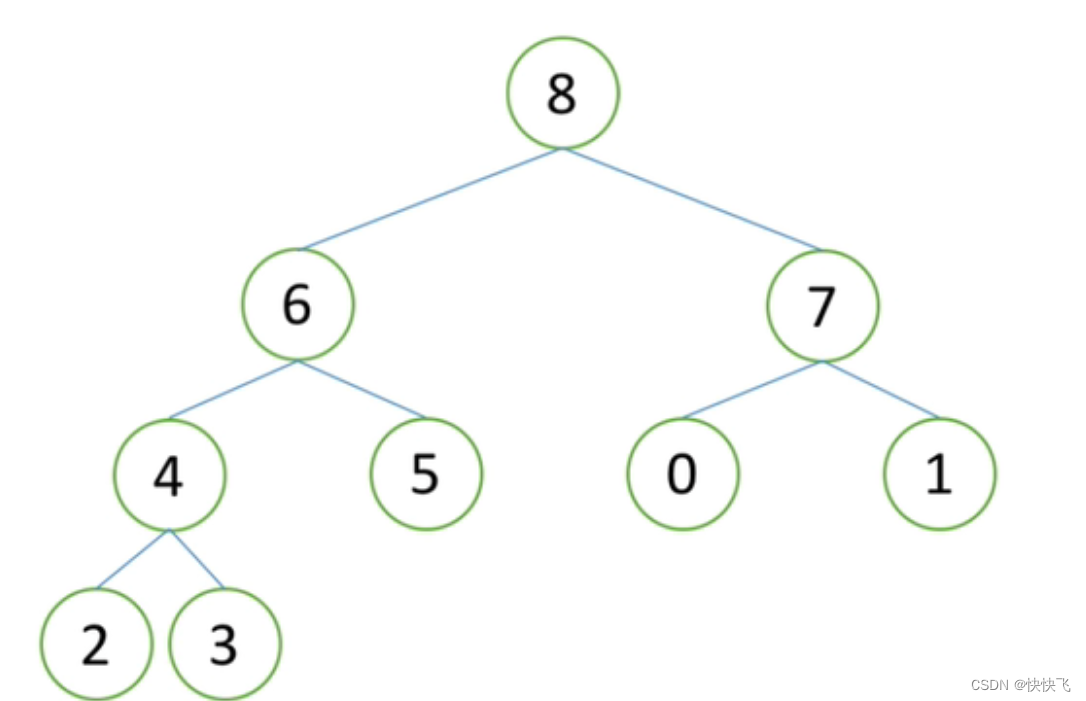
进行向下排序,使其再次成为一个大根堆(堆顶元素仍为此时堆的最大元素)
此时就完成了一次出数和堆调整,接着我们只需要不断循环以上过程便可以完成堆排序。
而堆排序的具体代码实现如下:
#堆排序函数
def heap_sort(list):
n=len(list)
#开始构建堆
for i in range((n-2)//2,-1,-1):
#从最后一个叶子节点的父节点开始调整,i表示一次调整的根节点的下标
sift(list,i,n-1)
#构建堆结束
for high in range(n-1,-1,-1):
#m一直指向堆的最后一个元素
list[0],list[high]=list[high],list[0]
sift(list,0,high-1) #high-1是一次出数后新的high
li=[i for i in range(20)]
import random
random.shuffle(li)
print(li)
heap_sort(li)
print(li)
运行结果如下:
[17, 5, 6, 10, 18, 4, 12, 8, 9, 16, 19, 2, 15, 1, 0, 3, 11, 7, 14, 13]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
堆排序和快速排序的时间复杂度是相同的,都为O(nlogn),即使两者的时间复杂度相同,但在具体运行速度上堆排序仍然比快速排序要慢一些。
堆排序的应用——topk问题
topk问题描述:
现有n个数,设计算法得到前k大的数(k<n)。
解决方法(思路):
①排序后切片——————————————O(nlogn)
②使用三种简单排序———————————O(mn)
③堆排序(小根堆)———————————O(mlogn)
我们在这里选择使用堆排序的思路来解决topk问题,
其具体代码如下:
##堆排序--topk问题
#向下调整函数(小根堆)
def sift(list,low,high):
'''
:param li: 列表
:param low: 堆的根节点
:param high: 堆的最后一个元素的位置
:return:
'''
i =low #最开始指向根节点
j=2*i+1 #开始指向i的左孩子节点
tmp =list[low] #把堆顶存起来
while j<=high: #j位置有数时一直循环
if j+1<=high and list[j]>list[j+1]:
j=j+1 #指向i的右孩子节点
if list[j]<tmp:
list[i]=list[j]
i=j #接着看下一层
j=2*i+1
else: #tmp大于孩子节点
list[i]=tmp #把tmp放在某一级根节点的位置
break
else: #当i在最后一层时,j越界,i已经没有孩子节点
list[i]=tmp #把tmp放到i的位置上(叶子结点)
#topk函数
def topk_sort(list,k):
heap=list[0:k]
#1.开始构建小根堆
for i in range((k-2)//2,-1,-1):
sift(heap,i,k-1)
#2.遍历表中所有元素
for j in range(k,len(list)):
if list[j]>heap[0]:
heap[0]=list[j]
sift(heap,0,k-1)
#3.倒序依次出数
for high in range(k-1,-1,-1):
heap[0],heap[high]=heap[high],heap[0]
sift(heap,0,high-1)
return heap
li=[12, 14, 0, 1, 6, 8, 16, 11, 3, 18, 4, 7, 10, 13, 5, 15, 9, 17, 19]
print(li)
print(topk_sort(li,5))
运行结果如下:
[12, 14, 0, 1, 6, 8, 16, 11, 3, 18, 4, 7, 10, 13, 5, 15, 9, 17, 19]
[19, 18, 17, 16, 15]
python中堆排序的内置模块——heapq
大致了解一下其中常用的函数有
①heapify(x)———建堆函数
②heappush(heap,item)————向堆内元素
③heappop(heap)————向堆外出元素
提示:下一篇为重要排序篇——归并排序
















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











