






前情提要
In [ ]
number = 0.5
age = 18
name = 'Molly'
beautiful = True
list1 = [1,'2', True]
tuple1 = (1,'2', True)
dict1 = {'name':'Molly', 'age':18, 'gender':'female'}
set1 = {1,2,3,4,5,5,5}In [ ]
my_number = 3200 # 这是真实的价格
guess_number = input('这台冰箱多少钱?')
guess_number = int(guess_number)
while True:
if guess_number<my_number:
guess_number = input('猜低了!再猜')
guess_number = int(guess_number)
elif guess_number>my_number:
guess_number = input('猜高了!再猜')
guess_number = int(guess_number)
else:
break
print('\n恭喜您,猜对了!\n')In [ ]
# continue : 跳过本轮
# 打印1-10中的偶数
for i in range(10):
num = i+1
if num%2 != 0:
# 跳过奇数
continue
print(num)
字符串进阶
字符串索引、切片
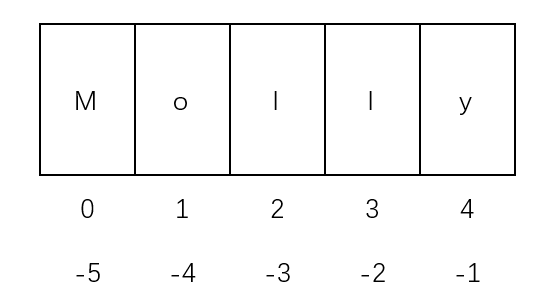
切片的语法:[起始:结束:步长] 字符串[start: end: step] 这三个参数都有默认值,默认截取方向是从左往右的 start:默认值为0; end : 默认值未字符串结尾元素; step : 默认值为1;
如果切片步长是负值,截取方向则是从右往左的
In [ ]
name = 'molly'
name[1]
name[-4]
name[1:4]
name[::-1]In [ ]
# 小练习
string = 'Hello world!'
string[2]
string[2:5]
string[3:]
string[8:2:-1]In [ ]
for s in string:
print(s)In [ ]
# 如果字符串以'p'结尾,则打印
list_string = ['apple','banana_p','orange','cherry_p']
for fruit in list_string:
if fruit[-1] == 'p':
print(fruit)In [ ]
# 如果字符串以'pr'结尾,则打印
list_string = ['apple','banana_pr','orange','cherry_pr']
for fruit in list_string:
if fruit.endswith('pr'):
print(fruit)字符串常用函数
记不住 找百度 help()
count 计数功能
显示自定字符在字符串当中的个数
In [ ]
my_string = 'hello_world'
my_string.count('o')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.count('and')In [ ]
help(my_string.count)In [ ]
my_string = 'aabcabca'
my_string.count('abca')find 查找功能
返回从左第一个指定字符的索引,找不到返回-1
index 查找
返回从左第一个指定字符的索引,找不到报错
In [ ]
my_string = 'hello_world'
my_string.find('o')In [ ]
my_string = 'hello_world'
my_string.index('o')In [ ]
my_string = 'hello_world'
my_string.find('a')In [ ]
my_string = 'hello_world'
my_string.index('a')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.find('and')In [ ]
'and' in article
In [ ]
my_string = 'hello_world'
my_string.startswith('hello') # 是否以hello开始
my_string.endswith('world') # 是否以world结尾split 字符串的拆分
按照指定的内容进行分割
In [ ]
my_string = 'hello_world'
my_string.split('_')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.split(' ')字符串的替换
从左到右替换指定的元素,可以指定替换的个数,默认全部替换
In [ ]
my_string = 'hello_world'
my_string.replace('_',' ')I wish to wish the wish you wish to wish,
but if you wish the wish the witch wishes,
I won't wish the wish you wish to wish.
In [ ]
my_string = "I wish to wish the wish you wish to wish, but if you wish the wish the witch wishes, I won't wish the wish you wish to wish."In [ ]
my_string.replace('wish','wish'.upper(), 3)字符串标准化
默认去除两边的空格、换行符之类的,去除内容可以指定
In [ ]
my_string = ' hello world\n'
my_string.strip()字符串的变形
In [ ]
my_string = 'hello_world'
my_string.upper()
my_string.lower()
my_string.capitalize()字符串的格式化输出
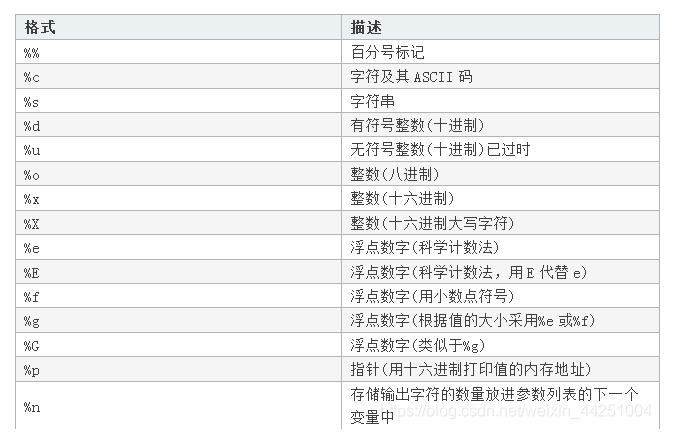
%
重点内容!
In [ ]
accuracy = 80/123
print('老板!我的模型正确率是', accuracy,'!')In [ ]
accuracy = 80/123
print('老板!我的模型正确率是%s!' % accuracy)In [ ]
accuracy = 80/123
print('老板!我的模型正确率是%.2f!' % accuracy)In [ ]
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫%s,我的身高是%d cm, 数学成绩%.2f分,英语成绩%d分' % (name, hight, score_math, score_english))format
In [ ]
"""
指定了 :s ,则只能传字符串值,如果传其他类型值不会自动转换
当你不指定类型时,你传任何类型都能成功,如无特殊必要,可以不用指定类型
"""
print('大家好!我叫{},我的身高是{:d} cm, 数学成绩{:.2f}分,英语成绩{}分'.format(name, int(hight), score_math, score_english))In [ ]
'Hello, {0}, 成绩提升了{1:.1f}分,百分比为 {2:.1f}%'\
.format('小明', 6, 17.523)In [ ]
'Hello, {name:}, 成绩提升了{score:.1f}分,百分比为 {percent:.1f}%'\
.format(name='小明',
score=6,
percent = 17.523)一种可读性更好的方法 f-string
** python3.6版本新加入的形式
In [ ]
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{name},我的身高是{hight:.3f} cm, 数学成绩{score_math}分,英语成绩{score_english}分")
list进阶
list索引、切片
In [ ]
list1 = ['a','b','c','d','e','f']
list1[2]
list1[2:5]list常用函数
添加新的元素
In [ ]
list1 = ['a','b','c','d','e','f']
list1.append('g') # 在末尾添加元素
print(list1)
list1.insert(2, 'ooo') # 在指定位置添加元素,如果指定的下标不存在,那么就是在末尾添加
print(list1)In [ ]
list2 = ['z','y','x']
list1.extend(list2) #合并两个list list2中仍有元素
print(list1)
print(list2)count 计数 和 index查找
In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.count('a')) In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.index('a')) In [ ]
print('a' in list1)删除元素
In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.pop(3))
print(list1)
list1.remove('a')
print(list1)列表生成式
Question1: 列表每一项+1
In [ ]
# 有点土但是有效的方法
list_1 = [1,2,3,4,5]
for i in range(len(list_1)):
list_1[i] += 1
list_1 In [ ]
# pythonic的方法 完全等效但是非常简洁
[n+1 for n in list_1]In [ ]
# 1-10之间所有数的平方
[(n+1)**2 for n in range(10)]In [ ]
# 1-10之间所有数的平方 构成的字符串列表
[str((n+1)**2) for n in range(10)]In [ ]
list1 = ['a','b','a','d','a','f']
['app_%s'%n for n in range(10)]In [ ]
list1 = ['a','b','a','d','a','f']
[f'app_{n}' for n in range(10)]Question2: 列表中的每一个偶数项[过滤]
In [ ]
# 有点土但是有效的方法
list_1 = [1,2,3,4,5]
list_2 = []
for i in range(len(list_1)):
if list_1[i] % 2 ==0:
list_2.append(list_1[i])
list_2In [ ]
list_1 = [1,2,3,4,5]
[n for n in list_1 if n%2==0]In [ ]
[n+1 for n in list_1 if n%2==0]In [ ]
# 小练习:0-29之间的奇数
list_1 = range(30)In [ ]
# 字符串中所有以'sv'结尾的
list_2 = ['a','b','c_sv','d','e_sv']
[s for s in list_2 if s.endswith('sv')]In [ ]
# 取两个list的交集
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]
[i for i in list_A if i in list_B]In [ ]
#小练习 在list_A 但是不在list_B中
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]In [ ]
[m + n for m in 'ABC' for n in 'XYZ']
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
In [ ]
# 第一种方法:类似列表生成式
L = [x * x for x in range(10)]
g = (x * x for x in range(10))In [ ]
next(g)In [ ]
g = (x * x for x in range(10))
for n in g:
print(n)In [ ]
# 第二种方法:基于函数
# 如何定义一个函数?
def reverse_print(string):
print(string[::-1])
return 'Successful!'In [ ]
ret = reverse_print('Molly')In [ ]
retIn [ ]
# 在IDE里面看得更清晰
def factor(max_num):
# 这是一个函数 用于输出所有小于max_num的质数
factor_list = []
n = 2
while n<max_num:
find = False
for f in factor_list:
# 先看看列表里面有没有能整除它的
if n % f == 0:
find = True
break
if not find:
factor_list.append(n)
yield n
n+=1
In [ ]
g = factor(10)In [ ]
next(g)In [ ]
g = factor(100)
for n in g:
print(n)In [ ]
# 练习 斐波那契数列
def feb(max_num):
n_1 = 1
n_2 = 1
n = 0
while n<max_num:
if n == 0 or n == 1:
yield 1
n += 1
else:
yield n_1 + n_2
new_n_2 = n_1
n_1 = n_1 + n_2
n_2 = new_n_2
n += 1
In [ ]
g = feb(20)
for n in g:
print(n)异常与错误处理

有的错误是程序编写有问题造成的,比如本来应该输出整数结果输出了字符串,这种错误我们通常称之为bug,bug是必须修复的。
有的错误是用户输入造成的,比如让用户输入email地址,结果得到一个空字符串,这种错误可以通过检查用户输入来做相应的处理。
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(list1[i])
list1[i]+=1
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在 Python 无法正常处理程序时就会发生一个异常。
异常是 Python 对象,表示一个错误。
当 Python 脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
if type(list1[i]) != int:
continue
print(list1[i])
list1[i]+=1
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'名字'异常
except <名字>,<数据>:
<语句> #如果引发了'名字'异常,获得附加的数据
else:
<语句> #如果没有异常发生
finally:
<语句> #有没有异常都会执行
try 的工作原理是,当开始一个 try 语句后,Python 就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try 子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当 try 后的语句执行时发生异常,Python 就跳回到 try 并执行第一个匹配该异常的 except 子句,异常处理完毕,控制流就通过整个 try 语句(除非在处理异常时又引发新的异常)。
如果在 try 后的语句里发生了异常,却没有匹配的 except 子句,异常将被递交到上层的 try,或者到程序的最上层(这样将结束程序,并打印缺省的出错信息)。
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except:
print('有异常发生')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except TypeError as e:
print(e)In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except IOError as e:
print(e)
print('输入输出异常')
except:
print('有异常发生')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(i)
try:
list1[i]+=1
print(list1)
except IOError as e:
print(e)
print('输入输出异常')
except:
print('有错误发生')
else:
print('正确执行')
finally:
print('我总是会被执行')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print('这是第%s次循环' % i)
try:
list1[i]+=1
print(list1[i])
except IOError as e:
print(e)
print('输入输出异常')
finally: # 有无finally
# 在离开try块之前,finally中的语句也会被执行。
print(f'一般用来做清理工作 这是我第{i}次清理')错误的层层传递
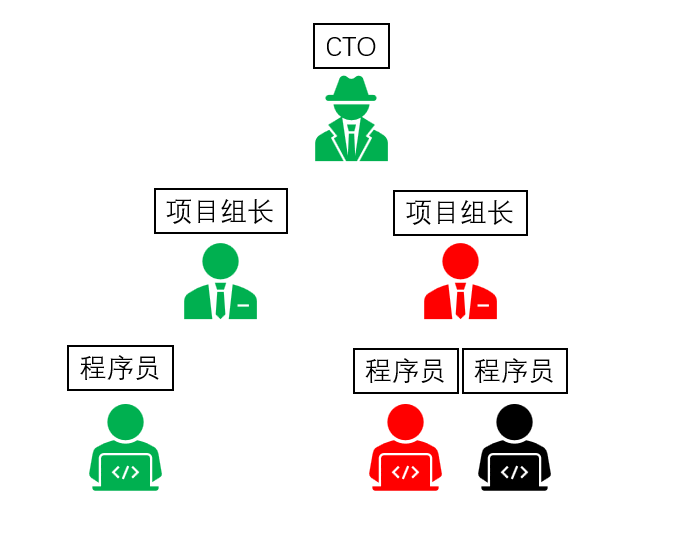
In [ ]
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数的定义和使用
return 10 / int(s)
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')In [ ]
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数如何定义的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')In [ ]
CTO('user')In [ ]
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数如何定义的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except ValueError as e:
print(e)
rst = '请修改输入'
return rst
def CTO(s):
return group_leader(s)
CTO('user')assert语句的使用
In [ ]
assert 1==2In [ ]
assert 1==1In [ ]
# 检查用户的输入
def worker(s):
assert type(s)== int
assert s!=0
rst = 10 / int(s)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except AssertionError as e:
print('数据类型错误')
rst = -1
return rst
def CTO(s):
return group_leader(s)
CTO('user')BUG的调试和记录
print大法
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print('这是第%s次循环' % i)
list1[i]+=1
print(list1[i])logging
In [ ]
In [ ]
import logging
logger = logging.getLogger()
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# Configure stream handler for the cells
chandler = logging.StreamHandler()
chandler.setLevel(logging.INFO)
chandler.setFormatter(formatter)
logger.addHandler(chandler)
logger.setLevel(logging.INFO)
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
for i in range(len(list1)):
logging.info('这是第%s次循环' % i)
list1[i]+=1
print(list1[i])IDE
小练习 列表
已知一个列表lst = [1,2,3,4,5]
- 求列表的长度
- 判断6 是否在列表中
- 列表里元素的最大值是多少
- 列表里元素的最小值是多少
- 列表里所有元素的和是多少
- 在数字1的后面新增一个的元素10
- 在列表的末尾新增一个元素20
In [ ]
lst = [1,2,3,4,5]小练习 列表生成式
In [ ]
# 要求你生成一个列表,列表里有10个元素,索引为奇数的元素值为1,索引为偶数的位置值为0。In [ ]
# [m + n for m in 'ABC' for n in 'XYZ']
# 已知lst1=[1,2,3,4,5,6],lst2=[2,4,6]
# 求两两相等时,lst1项*lst2项
# [4,16,36]
lst1=[1,2,3,4,5,6]
lst2=[2,4,6]In [ ]
def f(n):
return n*n+2*nIn [ ]
# 把f(n)应用在 lst1=[1,2,3,4,5,6] 中的每一项















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











